
1,为什么用线程池
在学java基础的时候,就学过线程的创建方式,如继承Thread类,实现Runnable接口,实现Callable接口这三种,但是在企业级开发中,由于存在多线程以及高并发等现象,如果大量的使用以上三种方式创建线程,则在创建以及销毁线程的过程中,需要消耗大量的资源,为了避免这种现象的发生,并且更好的分配和监控线程,才有了线程池。
2,什么是线程池
线程池,也可以称为线程缓存,和字符串常量池,数据库连接池等原理一样,就是一个池子,都是为了更加高效的对项目进行开发和管理,更好的去分配和管理资源。由于线程是稀缺的资源,所以如果被无限制的创建,不仅会大量消耗系统资源,还会降低系统的稳定性,因此java中提供线程池对线程进行分配,监控调优等。如果在并发中请求的数量非常多,但是执行时间很短,那么在创建销毁时就会花费大量的时间,就可能导致系统的效率大大降低。基本思想就是提前创建线程,重复使用。
3,ThreadPoolExecutor
要明白线程池,这个类ThreadPoolExecutor 是必须要先知道的,并且可以查看类与顶层接口的关系图,(快捷键Ctrl + shift + alt + u可以快速查看)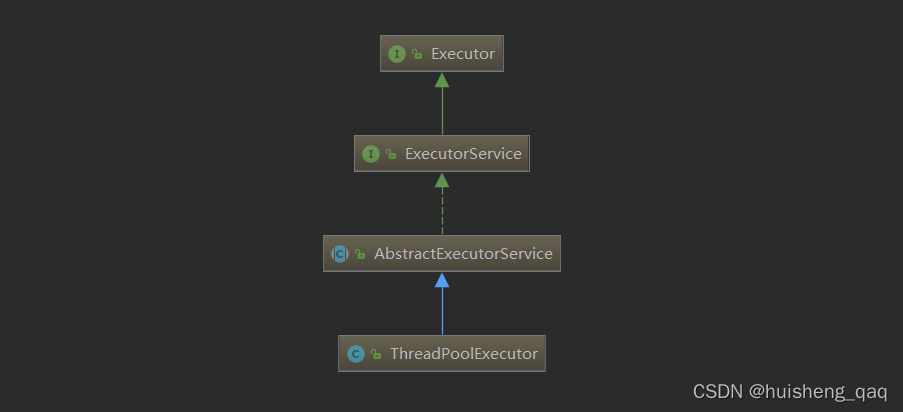
其关系图如上,主要是实现了顶层接口 Executor,在该接口中存在唯一一个抽象方法execute,主要用于提交任务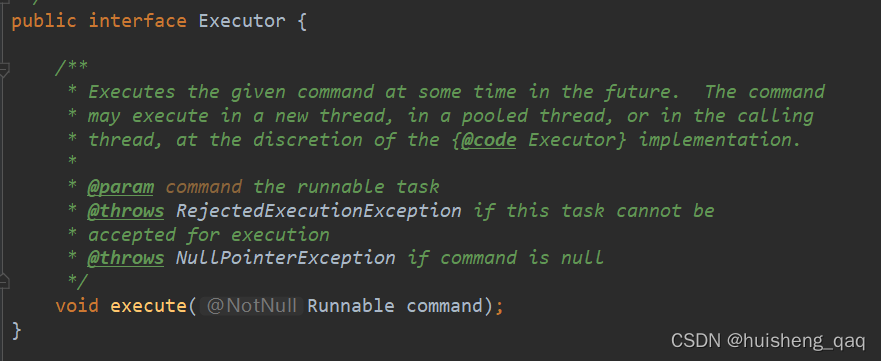
由此这个ThreadPoolExecutor类就是对Execute接口的具体的实现,所以接下来重点分析这个类以及他的实现原理。该类的构造方法如下,由于存在多态,由此挑选一个参数最多的构造方法来讲,并重点分析各个参数的意义
publicThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory,RejectedExecutionHandler handler){}
接下来对几个参数做一个初步的定义
int corePoolSize:核心线程数,默认不设置超时时间,当然可以手动设置过期超时时间
int maximumPoolSize:最大线程数 = 非核心线程 + 核心线程数,即线程池里面最多容纳的数量
long keepAliveTime:线程池维护线程所允许的空闲时间,非核心线程超时则会默认被销毁
TimeUnit unit:时间单位,有分钟,s,毫秒,微秒,纳秒等
BlockingQueue<Runnable> workQueue:存放未来得及提交的任务,其本质为一个BlockingQueue的阻塞队列,当线程池
中的核心线程满了之后就会将任务放入到阻塞队列里面
ThreadFactory threadFactory:线程工厂默认使用Executors里面的 defaultThreadFactory方法 来创建线程
RejectedExecutionHandler handler:拒绝策略,当线程池里面满了以及阻塞阻塞队列满了的情况下,会触发拒绝策略
4,线程池底层实现流程以及原理
如下图,可能不知道为啥上面要设置这么多参数,接下来看下具体的实现流程就能知道这些参数的意思了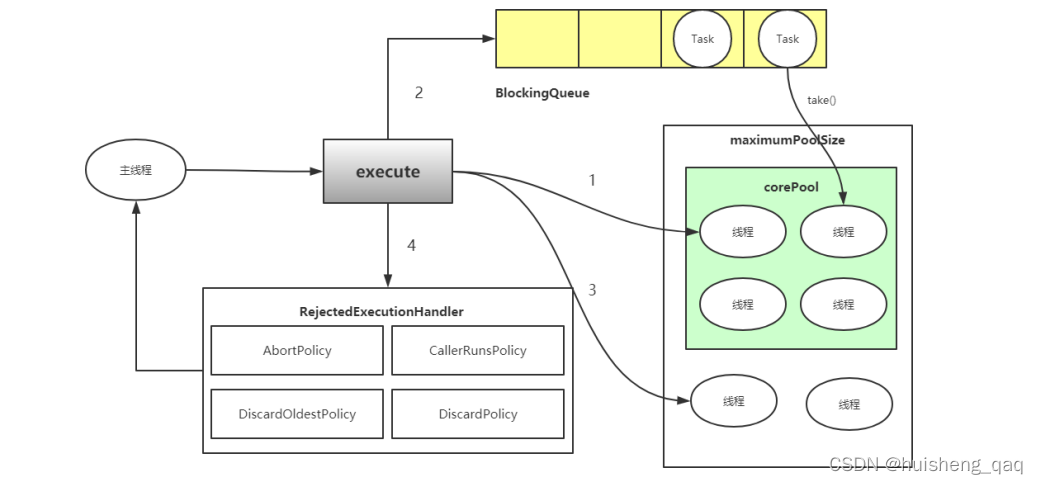
第一步,通过execute方法,将任务提交给线程池,首先,判断线程池中的线程数量,如果数量为空或者数量少于核心线程,则创建线程,并且将该线程标记为核心线程。当线程执行完,再次提交一个任务时,则会再创建一个新的线程,直到线程池中的核心线程数满为止。如上图中的 corePool 中的线程,因此参数核心线程的大小即为corepool的大小。
第二步,如果依旧有任务继续提交,线程池不会立马创建线程,而是将当前的任务放入到阻塞队列里面,当核心线程池中的线程将任务消费之后,则会监听这个阻塞队列,如果阻塞队列不为空,则消费队列里面的任务。由于队列本质是FIFO,先进先出的,所以会先消费最先进入队列的任务,即队头上面的任务。
第三步,在阻塞队列中的任务满了时,每个队列都有容量的大小,可以去了解一下 BlockingQueue 的原理。再提交一个任务,则会触发线程池中创建非核心线程,每个非核心线程来完成提交的任务,直到达到线程池中的最大线程数,并此时创建的线程设置为非核心线程
第四步,当线程池里面满了之后,会将线程丢到拒绝策略里面,即将要进来的任务进行拦截
可能对上面这个描述有一点模糊,接下来举一个具体的银行的实例来形象的描述一下这个执行流程。柜台的窗口就是代表池子里面最大允许存在的线程的数量,绿色的三个窗口代表的就是核心线程的数量,全部窗口代表的就是线程池的允许存在的最大线程的数量,下面的蓝色部分等候区,就是对应的阻塞队列 BlockingQueue,接下来具体流程如下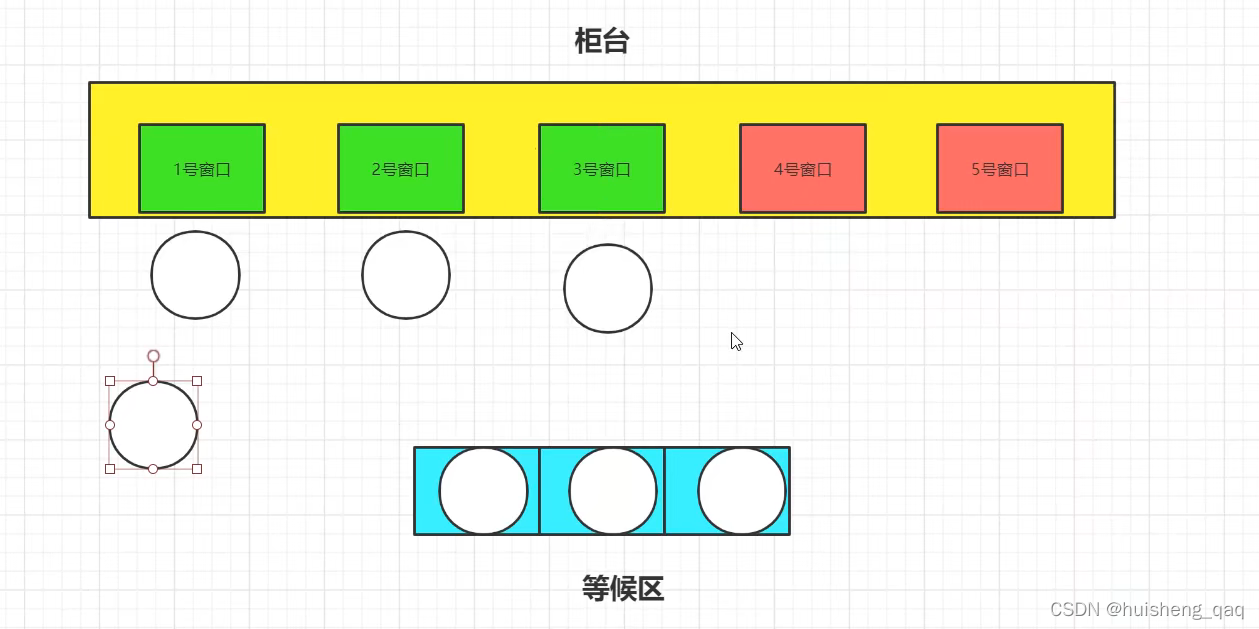
1,假设今天只开了三个窗口,对应的就是三个核心线程的数量,一个人来办理业务就对应一个窗口,即为对应的核心线程
2,如果三个窗口满了,则下一个人在等候区等待,就是对应的阻塞队列,当然等候区的座位有限,即对应队列的长度也是有 限的,不过第一个人来到等候区会第一个办理业务,即对应队列的性质,先进先出
3,等候区也满了,银行发现今天来办理业务的人多,因此就会多开窗口临时接待这些办理业务的人员,该窗口对应的就是非核心线程,当然窗口有限,因此非核心线程的数量也是有限的,又因为该窗口为临时窗口,所以在没人的时候或者人数少的时候,该窗口也会被关闭,让临时工休息或者解雇,以防止资源的浪费,因此对应的非核心线程就被设置了空闲状态下的超时时间,也是为了避免资源的浪费
4,如果柜台的人数也满了,等候区的人数也满了,即达到饱和状态,银行就会劝退接下来要来办理业务的人,让他们下午来或者明天来,当然不同人有不同的劝退方式,这就是线程池的存在的多种拒绝策略的原因
赠人玫瑰,手留余香,上面这一段例子主要是参考这位大佬的视频讲解的https://www.bilibili.com/video/BV1dt4y1i7Gt?spm_id_from=333.880.my_history.page.click
5,源码初探
在整个原理流程图中,主要由execute方法来决定执行到哪一步,接下来查看一下execute方法的底层逻辑,大概在当前类的1342行左右,找不到可以直接 ctrl + f12,输入这个方法就能找到了。
具体流程英文注释已经写得很清楚了,如果懒得百度的话可以安装一个网易云有道词典,直接截屏翻译即可,对面那些不友好不能复制的bug也是可以直接截屏翻译的。其具体流程如下,对部分代码进行解释
// ctl中记录这当前线程池的运行状态以及线程的数量int c = ctl.get();//workerCountOf 用于表示当前活动的线程数if(workerCountOf(c)< corePoolSize){//addWorker():在线程池中创建一个新的线程并执行,其中第二个参数为设置成核心线程if(addWorker(command,true))return;//如果添加失败,则重新获取ctl的值
c = ctl.get();}//如果当前线程池是运行状态并且任务添加到阻塞队列成功//这个offer方法是一个阻塞队列的添加任务的方法,返回值为布尔类型//在不满足第一个if并且线程处于运行状态,则说明活动线程数应该 >= 核心线程数,此时要做的就是将任务加入到阻塞队列中if(isRunning(c)&& workQueue.offer(command)){int recheck = ctl.get();//如果不是运行状态,由于之前已经把command 添加到workQueue中了,//这时需要移除或者丢弃当前进来的这个command,并对后面的任务直接开启拒绝策略if(!isRunning(recheck)&&remove(command))//拒绝策略reject(command);//处于运行状态但是线程池的有效线程数为0elseif(workerCountOf(recheck)==0)//依旧在线程池中创建一个线程,null表示没有任务,即不去启动线程池,false代表设置成非核心线程//其主要目的是保证线程在运行状态下,存在一个执行任务的线程,因为队列里面已经添加了一个任务addWorker(null,false);}//到这里的话意思就是可能当前线程池不处于running状态//或者说此时核心线程数量已满,队列也已满,则触发创建非核心线程//当然这里是不满足上述情况,即可能超过最大的线程池的容量,则触发拒绝策略elseif(!addWorker(command,false))reject(command);
可能对上面的那个addWorker方法可能不太了解他是如何实现的,接下来继续看看他的底层源码,addWorker方法的主要工作是在线程池中创建一个新的线程并执行,firstTask参数 用于指定新增的线程执行的第一个任务,core参数为true表示在新增线程时会判断当前活动线程数是否少于corePoolSize,false表示新增线程前需要判断当前活动线程数是否少maximumPoolSize
大家可以自行看一下里面的源码,都比较简单,主要是对线程池的状态进行的一些判断,如果处于非运行状态,则直接return false。当然如果处于运行状态,就会对有效的线程数进行判断,是设置为核心线程还是非核心线程,并通过Worker方法来创建对象,下面最终也是通过调用start方法来启动线程
与此同时,可能会出现一个问题,就是如果在执行任务的过程中,如果其中一个任务出现了异常,该任务会被如何处理,以及后面的任务能否被线程池的线程执行。接下来看以下这段代码,该段代码在执行线程任务的 runWorker 方法里面,可以发现他处理异常是一只往外抛,并没有对异常做具体的捕获,因此在多任务里面,如果中途一个任务出现异常,则会直接被忽视该任务,并且该任务也会直接会丢弃,直接执行下一个任务。所以在重要的日志等重要信息中,最好手动去捕获一下异常。因此线程池不会中途一个任务出现异常而导致线程池中断运行。
try{beforeExecute(wt, task);Throwable thrown =null;try{
task.run();}catch(RuntimeException x){
thrown = x;throw x;}catch(Error x){
thrown = x;throw x;}catch(Throwable x){
thrown = x;thrownewError(x);}finally{afterExecute(task, thrown);}}
6,线程池状态
如下图,线程池的状态依旧在该类下面的300多行,以一个私有静态的final类表示。运算符有 & 按位与,|按位或,^按位异或,~取反,>>右移,<<左移等。这里采用左移,比较好解释,一个二进制 00000001 = 1,在左移两位之后,就是相当于整体左移,然后原来的被移动的空位补0即可(学校应该都会学…),最后变成 00 00000100 = 2的2次方 = 4。
再如下图,这个 COUNT_BITS = Integer.SIZE - 3,Integer.SIZE点进去可以发现他的大小为 32,即以二进制补码的关系表示整型包装类的大小。即整型的长度为32位
接下来就好办了,取其中一个数就好了,由于负数涉及到二进制的补码问题,所以取一个整数示例。如上面的STOP = 1,则它的二进制为 00000001,而在进行左移32-3=29,即左移了29位,大概就是 001(00…00),括号里面跟29位0或者1,其他的照推,运行状态为111(后面跟29个0或者1)。因此这个状态就相当于取高位的前三位,111,000,001,010,011,刚好对应这五种状态。然后下面有一个容量 CAPACITY ,为(1 << COUNT_BITS) - 1,其实我一开始也想了一下,为啥要减一,就是高三位最小的是001,所以后面的29位二进制最大值就是全为1的时候最大,就等于(001 << COUNT_BITS) - 1。刚好就是前3位高进制代表运行状态,后29位用于保存线程池的容量,大概就是 2的29次方 - 1,当然这只是理论上的容量,也是最大容量,但是现实生产环境还得考虑吞吐量,cpu等等实际环境,需要根据实际的具体情况设置线程池容量的大小。一般来讲为了避免资源的浪费,会将线程池容量大小和核心线程的数量大小设置接近或者一样。
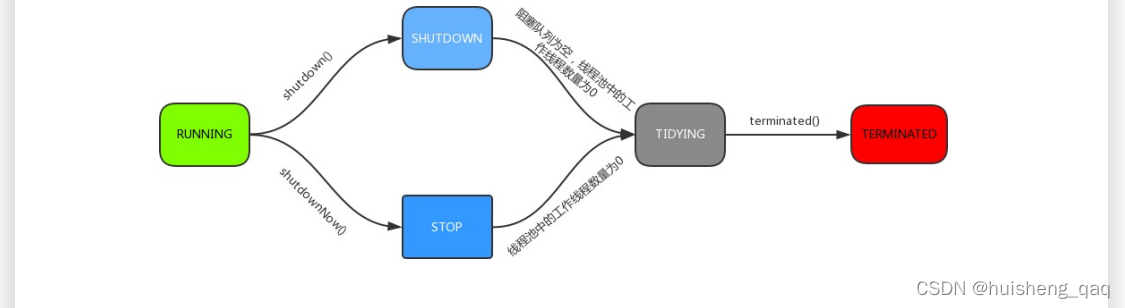
在上图中,就是五种状态的关系。接下来简单的描述一下这五种状态
1、RUNNING运行状态时
能够接收新任务,以及对已添加的任务进行处理,线程池被一旦被创建,就处于RUNNING状态,并且线程池中此时的任务数为0,其对应的高三位为 111。011
2、 SHUTDOWN
不可以接收新任务,但能处理已添加的任务,如阻塞队列里面的任务,调用线程池的shutdown()接口时,线程池由RUNNING -> SHUTDOWN,其对应的高三位为000。
3、STOP
不接收新任务,不处理已添加的任务,并且会中断正在处理的任务,在调用线程池的shutdownNow()接口时,线程池由(RUNNING or SHUTDOWN ) -> STOP,其对应的高三位为001。
4、TIDYING
当所有的任务已终止,ctl记录的”任务数量”为0,线程池会变为TIDYING 状态。当线程池在SHUTDOWN状态下,阻塞队列为空并且线程池中执行的任务也为空时,就会由 SHUTDOWN -> TIDYING。 当线程池在STOP状态下,线程池中执行的任务为空时,就会由STOP -> TIDYING,其对应的高三位为010。
5、 TERMINATED
线程池彻底终止,就变成TERMINATED状态。线程池处在TIDYING状态时,执行完terminated()之后,就会由 TIDYING 转化为TERMINATED。其对应的高三位为010
7,常用线程池创建方式
jdk1.8之前,自带了如下4种创建线程池的方式,主要是在Executors类下的,主要有newSingleThreadExecutor,newCachedThreadPool,newFixedThreadPool,newScheduledThreadPool四种方式,通过源码可以发现该四种都是使用了 ThreadPoolExecutor 来实现,因此接下来可以通过底层分析四种常用线程池的工作原理
1,newSingleThreadExecutor
single,熟悉的单例模式。顾名思义,即只创建只有一个线程的线程池。一般在单线程的情景才会使用,因此用处不多。通过上述线程池的原理讲解也可知,该线程池的核心线程和最大线程都是固定为1,所以只能排队进入队列一个个执行,再根据FIFO,顺序执行。
2,newFixedThreadPool
该线程池被称为固定大小线程池,看ThreadPoolExecutor 前面两个参数都是 nThreads,并且是外部传进来的,即核心线程和最大线程一样,整个池子里面的线程都是核心线程。那就相当于传10000个任务进来,可以直接被线程池全部执行,与此同时,线程池需要创建10000个线程,这样子比单例快,但是可能执行一次需要占用大量的CPU,并且线程池里面的线程不能实现复用。当然,假设有10000个任务过来,设置的核心和最大线程数量为100,多余的进入阻塞队列,假设阻塞队列足够长的话,可以将任务存储到队列中,这样子虽然可以实现核心线程的复用,但是由于线程池容量的大小有限,需要经过大量时间排队等在,也会降低该线程池的效率
3,newCachedThreadPool
缓存线程池,带有缓存功能的线程池,这种线程池具有线程复用的功能。根据参数可知核心线程的数量为0,但是最大线程数为2的32次方-1,即线程池的容量大小相对于是比较大的,并且允许闲置 60再销毁该线程 。而线程池里面的线程都是非核心线程,相当于里面的线程都是临时工,有任务就干,没任务再见这种,对资源相对保障。但是这个非核心线程只有超过最大的空闲时间才会被销毁,只要在这段时间有任务进来,就开通过该线程去执行任务,而不需要重新创建线程,大大提高了线程的复用率,同时也减少了资源的开销,该线程池运行速率相对较快,效率相对较高
4,newScheduledThreadPool
顾名思义,就是延迟后运行命令或者定期地执行任务。这里没什么好说的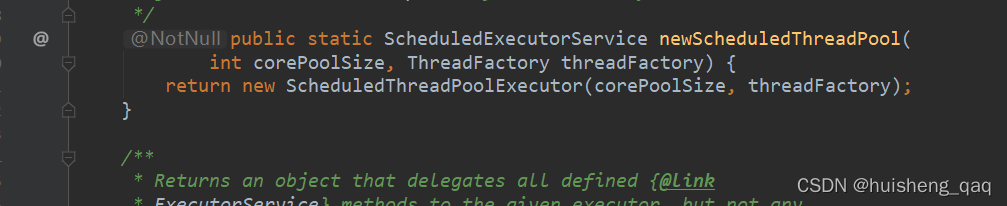
通过分析就发现这四种创建线程的方式,发现其底层只是通过改变了ThreadPoolExecutor 的核心线程数以及最大线程数这个两个参数的值,通过改变参数而实现不同场景下的不同功能,从而实现了这四种线程池。当然并不能说这四种线程池方式哪种好哪种坏,还需要根据实际的业务情况还选取具体的线程池,合适才是最好的。
8,线程池饱和拒绝策略
通过源码分析,其最顶端的父接口是RejectedExecutionHandler接口,其中存在rejectedExecution抽象方法,接下来通过该接口的具体实现类来了解对应的策略
1,CallerRunsPolicy
其为ThreadPoolExecutor 类里面的一个静态内部类,英文注释也说的很明白了,用调用者所在的线程来执行任务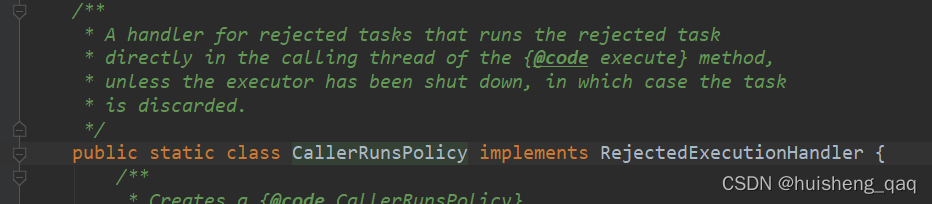
2,AbortPolicy,直接抛出异常,该策略为默认策略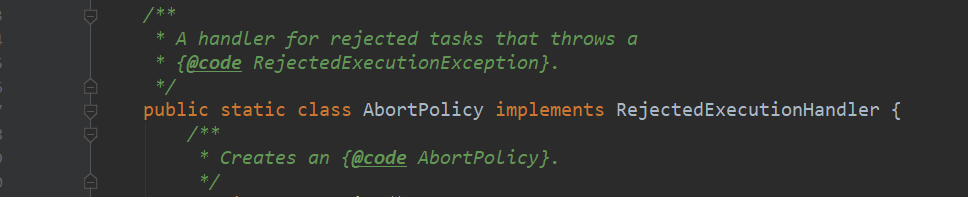
3,DiscardPolicy,直接丢弃任务
4,DiscardOldestPolicy,丢弃阻塞队列中靠最前的任务,并执行当前任务
5,当然我们也可以根据具体的业务场景,自定义一个实现RejectedExecutionHandler接口的类,重写里面的抽象方法即可
9,总结
在限流,响应式编程,redis-分布式锁,定时任务底层等等都是基于线程池来实现的,本篇主要探讨线程池的原理以及一些底层实现。当然线程以及线程池都是稀缺资源,因此线程池和其他的数据库连接池一样,在不使用的情况下,需要及时的进行shutdown关闭,避免造成资源浪费。
版权归原作者 huisheng_qaq 所有, 如有侵权,请联系我们删除。