
前言:
group by函数后取到的是分组中的第一条数据,但是我们有时候需要取出各分组的最新一条,该怎么实现呢?
本文提供两种实现方式。
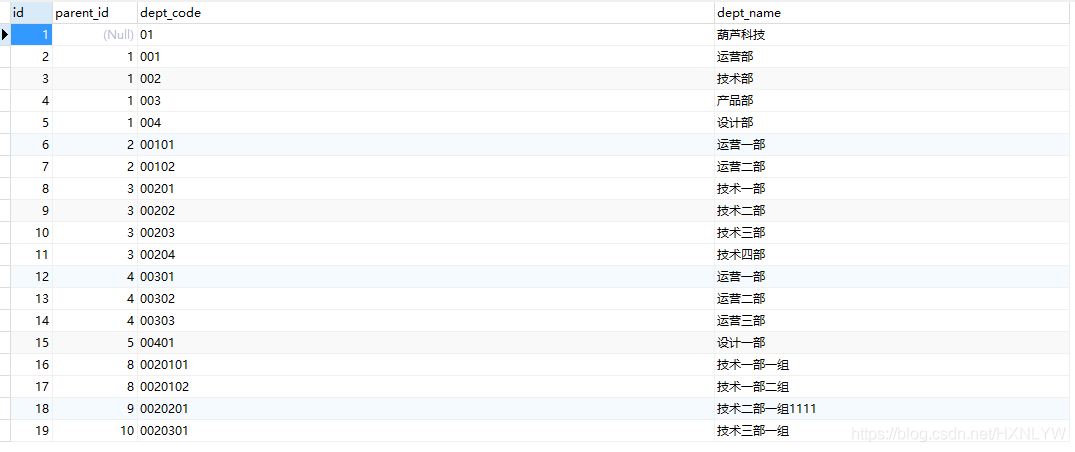
一、准备数据
DROP TABLE IF EXISTS `tb_dept`;
CREATE TABLE `tb_dept` (
`id` bigint(20) UNSIGNED NOT NULL,
`parent_id` bigint(20) NULL DEFAULT NULL,
`dept_code` char(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`dept_name` varchar(10) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
INDEX `idx_parent_id_code`(`parent_id`, `dept_code`) USING BTREE,
INDEX `idx_code_parent_id`(`dept_code`, `parent_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci COMMENT = '部门表' ROW_FORMAT = Dynamic;
INSERT INTO `tb_dept` VALUES (1, NULL, '01', '葫芦科技');
INSERT INTO `tb_dept` VALUES (2, 1, '001', '运营部');
INSERT INTO `tb_dept` VALUES (3, 1, '002', '技术部');
INSERT INTO `tb_dept` VALUES (4, 1, '003', '产品部');
INSERT INTO `tb_dept` VALUES (5, 1, '004', '设计部');
INSERT INTO `tb_dept` VALUES (6, 2, '00101', '运营一部');
INSERT INTO `tb_dept` VALUES (7, 2, '00102', '运营二部');
INSERT INTO `tb_dept` VALUES (8, 3, '00201', '技术一部');
INSERT INTO `tb_dept` VALUES (9, 3, '00202', '技术二部');
INSERT INTO `tb_dept` VALUES (10, 3, '00203', '技术三部');
INSERT INTO `tb_dept` VALUES (11, 3, '00204', '技术四部');
INSERT INTO `tb_dept` VALUES (12, 4, '00301', '运营一部');
INSERT INTO `tb_dept` VALUES (13, 4, '00302', '运营二部');
INSERT INTO `tb_dept` VALUES (14, 4, '00303', '运营三部');
INSERT INTO `tb_dept` VALUES (15, 5, '00401', '设计一部');
INSERT INTO `tb_dept` VALUES (16, 8, '0020101', '技术一部一组');
INSERT INTO `tb_dept` VALUES (17, 8, '0020102', '技术一部二组');
INSERT INTO `tb_dept` VALUES (18, 9, '0020201', '技术二部一组1111');
INSERT INTO `tb_dept` VALUES (19, 10, '0020301', '技术三部一组');
二、三种实现方式
1)先order by之后再分组:
SELECT * FROM (SELECT * from tb_dept ORDER BY id descLIMIT 10000) a GROUP BY parent_id;
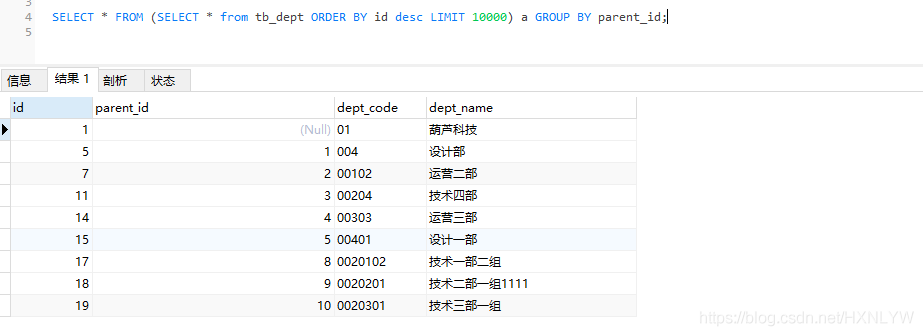
不加LIMIT可能会无效,由于mysql的版本问题。但是总觉得这种写法不太正经,因为如果数据量大于Limit 的值后,结果就不准确了。所以就有了第二种写法。
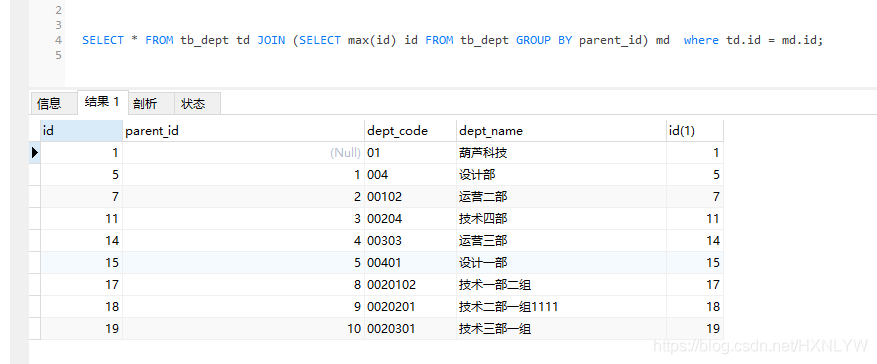
2)利用max() 函数:
SELECT * FROM tb_dept td,(SELECT max(id) id FROM tb_dept GROUP BY parent_id) md where td.id = md.id;
3)利用 where 字段名称 in (...) 函数:
SELECT * FROM tb_dept WHERE id IN (SELECT MAX(id) FROM tb_dept GROUP BY parent_id);
-- 查找所有用户的最近失效订单
SELECT A.* from
(
SELECT s.subId,userId,expiredTime from open_orderinfo_sub s
where expiredTime is not null and s.eaId=82 and s.status=0
ORDER BY expiredTime desc LIMIT 100000000
)A GROUP BY A.userId;
还有方式二:(查询create_time 最新的产品记录)
select * from table1 a where not exists (select 1 from table1 where product_id = a.product_id and create_time > a.create_time);
方式三:
select
a.product_id, a.task_id, a.user_id, a.type, a.status, a.content, a.create_time, a.update_time
from table_123 a
where create_time = (select max(create_time) from table_123 where product_id = a.product_id and type=a.type)
版权归原作者 瓦哥架构实战 所有, 如有侵权,请联系我们删除。