
利用Kafka实现延迟队列实践
一、RocketMq
阿里提供的RocketMq消息中间件是天然支持消息先延迟队列功能的,主要原理和实现方法可以参加以下链接:
https://blog.csdn.net/daimingbao/article/details/119846393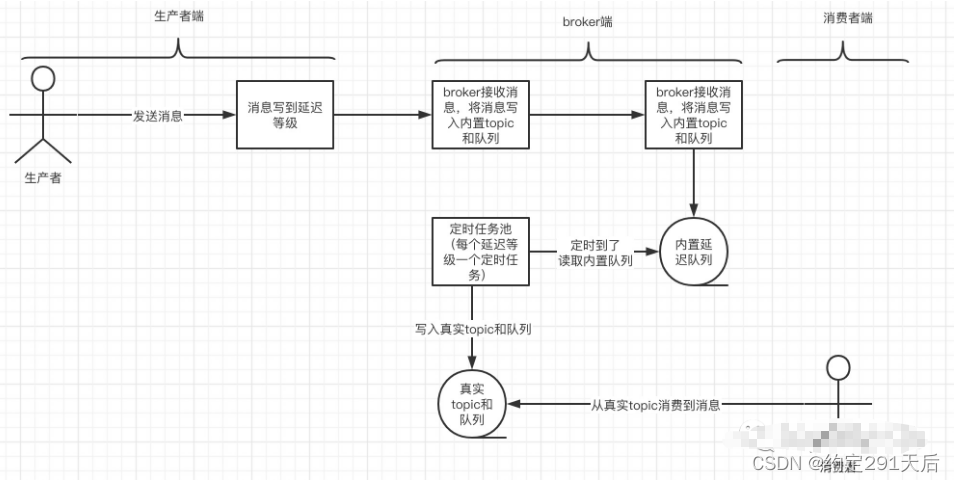
二、kafka实践
项目中采用的消息中间件是kafka,那如何在kafka上实现类似延迟队列的功能。
kafka本身是不支持延迟队列功能,我们可以通过消息延时转发新主题,曲线完成该功能。
主要实践原理是通过定阅原始主题,并判断是否满足延迟时间要求,满足要求后转发新主题,不满足则阻塞等待,同时外置一个定时器,每1秒进行唤醒锁协作。
为了避免消息长时间得不到消费使用导致kafka的rebalance,使用kafka自提供的api
consumer.pause(Collections.singletonList(topicPartition));
代码参考,详细参考代码里注释:
packagecom.zte.sdn.oscp.kafka;importcom.fasterxml.jackson.databind.JsonNode;importcom.fasterxml.jackson.databind.ObjectMapper;importorg.apache.kafka.clients.consumer.ConsumerConfig;importorg.apache.kafka.clients.consumer.ConsumerRecord;importorg.apache.kafka.clients.consumer.ConsumerRecords;importorg.apache.kafka.clients.consumer.KafkaConsumer;importorg.apache.kafka.clients.consumer.OffsetAndMetadata;importorg.apache.kafka.clients.producer.KafkaProducer;importorg.apache.kafka.clients.producer.ProducerConfig;importorg.apache.kafka.clients.producer.ProducerRecord;importorg.apache.kafka.common.TopicPartition;importorg.apache.kafka.common.serialization.StringDeserializer;importorg.apache.kafka.common.serialization.StringSerializer;importorg.junit.jupiter.api.BeforeEach;importorg.junit.jupiter.api.Test;importorg.springframework.boot.test.context.SpringBootTest;importjava.io.IOException;importjava.time.Duration;importjava.util.Collections;importjava.util.HashMap;importjava.util.List;importjava.util.Properties;importjava.util.Timer;importjava.util.TimerTask;importjava.util.concurrent.ExecutionException;@SpringBootTest(classes =TestMainApplication.class)publicclassDelayQueueTest{privateKafkaConsumer<String,String> consumer;privateKafkaProducer<String,String> producer;privatevolatileBoolean exit =false;privatefinalObject lock =newObject();privatefinalString servers ="127.0.0.1:4532";@BeforeEachvoidinitConsumer(){Properties props =newProperties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, servers);
props.put(ConsumerConfig.GROUP_ID_CONFIG,"d");
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"false");
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"earliest");
props.put(ConsumerConfig.ISOLATION_LEVEL_CONFIG,"read_committed");
props.put(ConsumerConfig.MAX_POLL_INTERVAL_MS_CONFIG,"5000");
consumer =newKafkaConsumer<>(props,newStringDeserializer(),newStringDeserializer());}@BeforeEachvoidinitProducer(){Properties props =newProperties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, servers);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
producer =newKafkaProducer<>(props);}@TestvoidtestDelayQueue()throwsIOException,InterruptedException{//主题String topic ="delay-minutes-1";List<String> topics =Collections.singletonList(topic);
consumer.subscribe(topics);//定时器,实时1s解锁Timer timer =newTimer();
timer.schedule(newTimerTask(){@Overridepublicvoidrun(){synchronized(lock){
consumer.resume(consumer.paused());
lock.notify();}}},0,1000);do{synchronized(lock){ConsumerRecords<String,String> consumerRecords = consumer.poll(Duration.ofMillis(200));//消息为空,则阻塞,等待定时器来唤醒if(consumerRecords.isEmpty()){
lock.wait();continue;}boolean timed =false;for(ConsumerRecord<String,String> consumerRecord : consumerRecords){//消息体固定为{"topic": "target","key": "key1","value": "value1"}long timestamp = consumerRecord.timestamp();TopicPartition topicPartition =newTopicPartition(consumerRecord.topic(), consumerRecord.partition());//判断是否满足延迟要求,这里为1min,当然也可以设计更多延迟定义的主题if(timestamp +60*1000<System.currentTimeMillis()){String value = consumerRecord.value();ObjectMapper objectMapper =newObjectMapper();JsonNode jsonNode = objectMapper.readTree(value);JsonNode jsonNodeTopic = jsonNode.get("topic");String appTopic =null, appKey =null, appValue =null;if(jsonNodeTopic !=null){
appTopic = jsonNodeTopic.asText();}if(appTopic ==null){continue;}JsonNode jsonNodeKey = jsonNode.get("key");if(jsonNodeKey !=null){
appKey = jsonNode.asText();}JsonNode jsonNodeValue = jsonNode.get("value");if(jsonNodeValue !=null){
appValue = jsonNodeValue.asText();}// send to application topicProducerRecord<String,String> producerRecord =newProducerRecord<>(appTopic, appKey, appValue);try{
producer.send(producerRecord).get();// success. commit messageOffsetAndMetadata offsetAndMetadata =newOffsetAndMetadata(consumerRecord.offset()+1);HashMap<TopicPartition,OffsetAndMetadata> metadataHashMap =newHashMap<>();
metadataHashMap.put(topicPartition, offsetAndMetadata);
consumer.commitSync(metadataHashMap);}catch(ExecutionException e){//异步停止,并重置offset
consumer.pause(Collections.singletonList(topicPartition));
consumer.seek(topicPartition, consumerRecord.offset());
timed =true;break;}}else{//不满足延迟要求,并重置offset
consumer.pause(Collections.singletonList(topicPartition));
consumer.seek(topicPartition, consumerRecord.offset());
timed =true;break;}}if(timed){
lock.wait();}}}while(!exit);}}
三、kafka实践+
上面的实践存在什么样的问题,考虑一个场景,有一个延迟一小时的队列,这样消息发出后,实际上一个小时后在该主题上的消息拉取才有意义(之前即使拉取下来也发送不出去),但上面的实现仍然会不停阻塞唤醒,相当于在做无用功。如何避免该问题。
这边的原理是通过定阅原始主题,并判断是否满足延迟时间要求,满足要求后转发新主题,不满足则停止消费并等待。
packagecom.zte.sdn.oscp.kafka;importcom.fasterxml.jackson.databind.JsonNode;importcom.fasterxml.jackson.databind.ObjectMapper;importorg.apache.kafka.clients.consumer.ConsumerConfig;importorg.apache.kafka.clients.consumer.ConsumerRecord;importorg.apache.kafka.clients.consumer.ConsumerRecords;importorg.apache.kafka.clients.consumer.KafkaConsumer;importorg.apache.kafka.clients.consumer.OffsetAndMetadata;importorg.apache.kafka.clients.producer.KafkaProducer;importorg.apache.kafka.clients.producer.ProducerConfig;importorg.apache.kafka.clients.producer.ProducerRecord;importorg.apache.kafka.common.TopicPartition;importorg.apache.kafka.common.serialization.StringDeserializer;importorg.apache.kafka.common.serialization.StringSerializer;importorg.junit.jupiter.api.BeforeEach;importorg.junit.jupiter.api.Test;importorg.springframework.boot.test.context.SpringBootTest;importjava.io.IOException;importjava.time.Duration;importjava.util.Collections;importjava.util.HashMap;importjava.util.List;importjava.util.Properties;importjava.util.concurrent.ExecutionException;@SpringBootTest(classes =TestMainApplication.class)publicclassDelayQueueSeniorTest{privateKafkaConsumer<String,String> consumer;privateKafkaProducer<String,String> producer;privatevolatileBoolean exit =false;privatefinalString servers ="127.0.0.1:4532";@BeforeEachvoidinitConsumer(){Properties props =newProperties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, servers);
props.put(ConsumerConfig.GROUP_ID_CONFIG,"d");
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"false");
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"earliest");
props.put(ConsumerConfig.ISOLATION_LEVEL_CONFIG,"read_committed");
props.put(ConsumerConfig.MAX_POLL_INTERVAL_MS_CONFIG,"5000");
consumer =newKafkaConsumer<>(props,newStringDeserializer(),newStringDeserializer());}@BeforeEachvoidinitProducer(){Properties props =newProperties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, servers);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
producer =newKafkaProducer<>(props);}@TestvoidtestDelayQueue()throwsIOException,InterruptedException{String topic ="delay-minutes-1";List<String> topics =Collections.singletonList(topic);
consumer.subscribe(topics);do{ConsumerRecords<String,String> consumerRecords = consumer.poll(Duration.ofMillis(200));if(consumerRecords.isEmpty()){continue;}for(ConsumerRecord<String,String> consumerRecord : consumerRecords){long timestamp = consumerRecord.timestamp();TopicPartition topicPartition =newTopicPartition(consumerRecord.topic(), consumerRecord.partition());//超时一分钟long span = timestamp +60*1000-System.currentTimeMillis();if(span <=0){String value = consumerRecord.value();ObjectMapper objectMapper =newObjectMapper();JsonNode jsonNode = objectMapper.readTree(value);JsonNode jsonNodeTopic = jsonNode.get("topic");String appTopic =null, appKey =null, appValue =null;if(jsonNodeTopic !=null){
appTopic = jsonNodeTopic.asText();}if(appTopic ==null){continue;}JsonNode jsonNodeKey = jsonNode.get("key");if(jsonNodeKey !=null){
appKey = jsonNode.asText();}JsonNode jsonNodeValue = jsonNode.get("value");if(jsonNodeValue !=null){
appValue = jsonNodeValue.asText();}// send to application topicProducerRecord<String,String> producerRecord =newProducerRecord<>(appTopic, appKey, appValue);try{
producer.send(producerRecord).get();// success. commit messageOffsetAndMetadata offsetAndMetadata =newOffsetAndMetadata(consumerRecord.offset()+1);HashMap<TopicPartition,OffsetAndMetadata> metadataHashMap =newHashMap<>();
metadataHashMap.put(topicPartition, offsetAndMetadata);
consumer.commitSync(metadataHashMap);}catch(ExecutionException e){
consumer.pause(Collections.singletonList(topicPartition));
consumer.seek(topicPartition, consumerRecord.offset());Thread.sleep(span);
consumer.resume(consumer.paused());break;}}else{
consumer.pause(Collections.singletonList(topicPartition));
consumer.seek(topicPartition, consumerRecord.offset());//通过计算延迟时间差值,然后等待,避免空转Thread.sleep(span);
consumer.resume(consumer.paused());break;}}}while(!exit);}}
四、更多
当然还有一个更简单的方式,即利用定时器循环检测,可能会有一点时间上的误差,主要还是取决你的业务场景能否接受。
更高级一点则是使用时间轮机制。
本文转载自: https://blog.csdn.net/sunquan291/article/details/127021608
版权归原作者 加权不下平权 所有, 如有侵权,请联系我们删除。
版权归原作者 加权不下平权 所有, 如有侵权,请联系我们删除。