
1.Zookeeper

Zookeeper 是 Apache Hadoop 的子项目,是一个树型的目录服务,支持变更推送,适合作为 Dubbo 服务的注册中心,工业强度较高。
Zookeeper的功能主要是它的树形节点来实现的。当有数据变化的时候或者节点过期的时候,会通过事件触发通知对应的客户端数据变化了,然后客户端再请求zookeeper获取最新数据,采用push-pull来做数据更新。服务注册和消费信息直接存储在zk树形节点上,集群下采用过半机制保证服务节点间一致性。
2.Nacos

Nacos 是 Alibaba 公司推出的开源工具,用于实现分布式系统的服务发现与配置管理。Nacos 是 Dubbo 生态系统中重要的注册中心实现。
Nacos的配置中心和注册中心实现的是两套代码。Nacos依赖Mysql数据库做数据存储,当有数据更新的时候,直接更新数据库的数据,然后将数据更新的信息异步广播给Nacos集群中所有服务节点数据变更,在由Nacos服务节点更新本地缓存,然后将通知客户端节点数据变化。
3.Dubbo

Dubbo 是阿里巴巴公司开源的一个Java高性能优秀的服务框架,使得应用可通过高性能的 RPC 实现服务的输出和输入功能,可以和 Spring框架无缝集成。
dubbo能做什么?
- 透明化的远程方法调用,就像调用本地方法一样调用远程方法,只需简单配置,没有任何API侵入。
- 软负载均衡及容错机制,可在内网替代F5等硬件负载均衡器,降低成本,减少单点。
服务自动注册与发现,不再需要写死服务提供方地址,注册中心基于接口名查询服务提供者的IP地址,并且能够平滑添加或删除服务提供者。
4.Kafka

Kafka是最初由Linkedin公司开发,是一个分布式、支持分区的(partition)、多副本的(replica),基于Zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景:比如基于hadoop的批处理系统、低延迟的实时系统、storm/Spark流式处理引擎,web/nginx日志、访问日志,消息服务等等,用scala语言编写,Linkedin于2010年贡献给了Apache基金会并成为顶级开源 项目。
Zookeeper与Nacos
1.配置中心
Nacos和Zookeeper都可以作为配置中心,做一些可以实时变化的配置数据存储,然后实时更新线上数据。
区别:存储和数据更新
- Nacos:依赖Mysql数据库做数据存储,当有数据更新的时候,直接更新数据库的数据,然后将数据更新的信息异步广播给Nacos集群中所有服务节点数据变更,在由Nacos服务节点更新本地缓存,然后将通知客户端节点数据变化。
- Zookeeper:利用zk的树型结构做数据存储,当有数据更新的时候使用过半机制保证各个节点的数据一致性;然后通过zk的事件机制通知客户端。
这里可以明显发现差异:
服务器存储位置不同,分别采用mysql和zk本身存储
消息发送,一个有采用过半机制保持一致性,另外一个异步广播,通过后台线程重试保证。
2.注册中心
Nacos:nacos支持两种方式的注册中心,持久化和非持久化存储服务信息。
非持久直接存储在nacos服务节点的内存中,并且服务节点间采用去中心化的思想,服务节点采用hash分片存储注册信息
持久化使用Raft协议选举master节点,同样采用过半机制将数据存储在leader节点上
Zookeeper:利用zk的树型结构做数据存储,服务注册和消费信息直接存储在zk树形节点上,集群下同样采用过半机制保证服务节点间一致性
Zookeeper与kafka
1)Kafka把它的meta数据都存储在ZK上,所以说ZK是必要存在的,没有ZK没法运行Kafka;在老版本(0.8.1以前)里面消费段(consumer)也是依赖ZK的,在新版本中移除了客户端对ZK的依赖,但是broker依然依赖于ZK。
2)kafka是消息队列,Zookeeper是服务的控制中心;消费者要访问服务,需要知道现在哪些生产者(对于消费者而言,kafka就是生产者)是可用的,就需要zk的调度。
Zookeeper与dubbo的关系
Dubbo建议使用Zookeeper作为服务的注册中心。
Dbbo是一个框架,用于服务间的调度,服务程序编写使用dubbo做接口,利用dubbo是实现服务服务之间还有Zookeeper之间的通讯。
1) Zookeeper的作用:
Zookeeper用来注册服务和进行负载均衡,哪一个服务由哪一个机器来提供必需让调用者知道,简单来说就是ip地址和服务名称的对应关系。当然也可以 通过硬编码的方式把这种对应关系在调用方业务代码中实现,但是如果提供服务的机器挂掉调用者无法知晓,如果不更改代码会继续请求挂掉的机器提供服务。 Zookeeper通过心跳机制可以检测挂掉的机器并将挂掉机器的ip和服务对应关系从列表中删除。至于支持高并发,简单来说就是横向扩展,在不更改代码 的情况通过添加机器来提高运算能力。通过添加新的机器向Zookeeper注册服务,服务的提供者多了能服务的客户就多了。
2) dubbo:
是管理中间层的工具,在业务层到数据仓库间有非常多服务的接入和服务提供者需要调度,dubbo提供一个框架解决这个问题。
注意这里的dubbo只是一个框架,至于你架子上放什么是完全取决于你的,就像一个汽车骨架,你需要配你的轮子引擎。这个框架中要完成调度必须要有一个分布式的注册中心,储存所有服务的元数据,你可以用zk,也可以用别的,只是大家都用zk。
总而言之,Zookeeper与nacos功能差不多(都是注册中心和配置中心)就是实现方式不一样。而dubbo就是一个RPC调用框架,就想一个汽车骨架,需要配置轮子引擎(分布式注册中心Zookeeper或nacos)。而kafka就是依赖一Zookeeper来运行的。
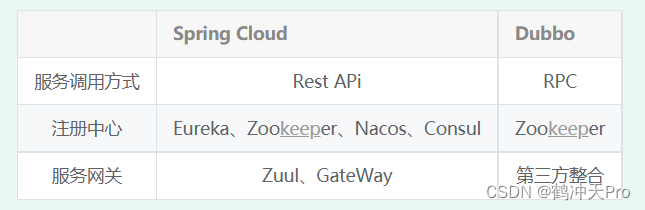
Spring Cloud 和Dubbo区别
版权归原作者 鹤冲天Pro 所有, 如有侵权,请联系我们删除。