
在写hivesql语句时,通常因为实现一个比较复杂的逻辑时,往往使用多层嵌套关联,首先导致代码的可读性较差,其次是代码性能比较低。因为这个原因,很多人都会想方设法去优化代码,提高代码的可读性和性能。在优化中,我们尝尝想到的是去创建临时表的方法。目前创建临时表方法有两种,一种是create temporary会话级临时表创建;另外一种是with as的方式,这种方式更偏向像是视图(子查询)。
接下来我们看看这两种方式的相同点和不同点,什么场景适用什么方式。
相同点:这两种方式对外都可以称为临时表;都可以增加代码的可读性;都可以一定程度上提升复杂代码的性能
不同点:存储方式的不同,create temporary是将生成真实的数据临时存放到hdfs上,等到结束该会话的时候,就会将这个临时数据删除掉,而with as的本质相当于一个视图或者一个子查询,是存放到内存中,如果当前sql结束对应的子查询也随之没了。
对应不同的场景会使用到不同的临时表方式,也可以穿插使用。
例如:在逻辑相对复杂程度比较低,且内存不是特别充足的情况下,可以使用create temporary,在排错的时候相对轻松点。在逻辑比较复杂且内存充足,可以使用with as的形式。如果在逻辑比较复杂,内存不是非常充足,但是想程序稍微快点,并且增加可读性和排错便捷,可以使用两种相结合形式。
下面来看一下两种临时表分别是如何实现的
创建对应的表结构
-- 需要用到的表结构
create table if not exists person
(
id int,
name string,
age int,
occupation string
)
row format serde 'org.apache.hadoop.hive.ql.io.orc.OrcSerde'
with serdeproperties('serialization.null.format' = 'null')
stored as orc;
create table if not exists diet
(
id int,
breakfast string,
lunch string,
dinner string
)
row format serde 'org.apache.hadoop.hive.ql.io.orc.OrcSerde'
with serdeproperties('serialization.null.format' = 'null')
stored as orc;
create table if not exists hobby
(
id int,
hobby string
)
row format serde 'org.apache.hadoop.hive.ql.io.orc.OrcSerde'
with serdeproperties('serialization.null.format' = 'null')
stored as orc;
-- 最终插入的结果表
create table if not exists person_diet_hobby
(
id int,
name string,
age int,
occupation string,
breakfast string,
lunch string,
dinner string,
hobby string
)
row format serde 'org.apache.hadoop.hive.ql.io.orc.OrcSerde'
with serdeproperties('serialization.null.format' = 'null')
stored as orc;
插入对应的数据,以cdh为准语法如下,如果是tdh需要在最后加上 from system.dual:
insert into table person
(id, name,age,occupation)
select 001 as id,
'踢足球' as name,
10 as age,
'学生' as occupation;
insert into table diet
(id, breakfast,lunch,dinner)
select 001 as id,
'牛奶和鸡蛋' as breakfast,
'营养午餐' as lunch,
'营养晚餐' as dinner;
insert into table hobby
(id, hobby)
select 001 as id,
'踢足球' as hobby;
create temporary
-- 将个人的运动放到个人下
create temporary table person_hobby stored as orc as
select a.id,a.name,a.age,a.occupation,b.hobby from person a
inner join hobby b
on a.id=b.id;
执行上述语句之后,在当前会话中查询这张临时表,可以看到对应的数据,使用 show create table person_hobby 语句可以查看到对应的存储位置
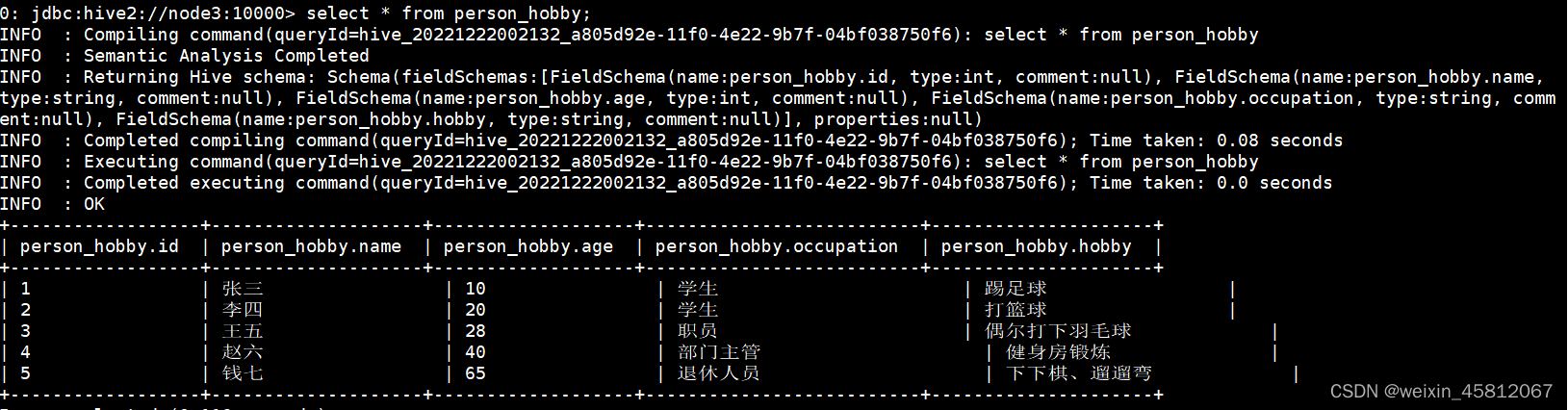
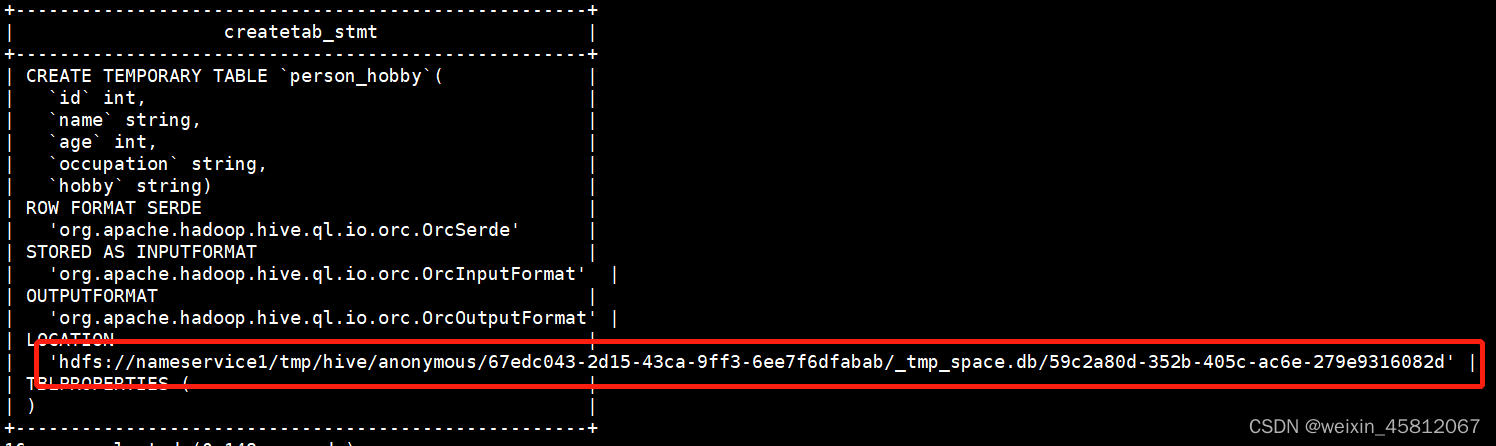
关闭会话之后,在重新打开会话,再用上述语句去找这临时表就找不到了,证明这张表已经被删掉了

根据临时表,将需要的数据全部插入到对应的表中
insert into table person_diet_hobby (id,name,age,occupation,breakfast,lunch,dinner,hobby)
select a.id,a.name,a.age,a.occupation,b.breakfast,b.lunch,b.dinner,a.hobby
from person_hobby a
inner join diet b
on a.id = b.id;

with as
with as 无法单独的去执行,需要放到一段sql中总体执行,必须要要以插入或者查询结束,前面生成的with as也可以给后面with as重复使用,并且每一段with as需要使用英文逗号做分割,按照上面插入的数据,来看下如何实现(以mr引擎实验)
with person_hobby as (select t1.id,t1.name,t1.age,t1.occupation,t2.hobby from person t1
inner join hobby t2
on t1.id=t2.id),
person_diet_hobby_temp as (select a.id,a.name,a.age,a.occupation,b.breakfast,b.lunch,b.dinner,a.hobby
from person_hobby a
inner join diet b
on a.id = b.id)
insert into table person_diet_hobby (id,name,age,occupation,breakfast,lunch,dinner,hobby)
select id,name,age,occupation,breakfast,lunch,dinner,hobby
from person_diet_hobby_temp;
0: jdbc:hive2://node3:10000> with person_hobby as (select t1.id,t1.name,t1.age,t1.occupation,t2.hobby from person t1
. . . . . . . . . . . . . .> inner join hobby t2
. . . . . . . . . . . . . .> on t1.id=t2.id),
. . . . . . . . . . . . . .> person_diet_hobby_temp as (select a.id,a.name,a.age,a.occupation,b.breakfast,b.lunch,b.dinner,a.hobby
. . . . . . . . . . . . . .> from person_hobby a
. . . . . . . . . . . . . .> inner join diet b
. . . . . . . . . . . . . .> on a.id = b.id)
. . . . . . . . . . . . . .> insert into table person_diet_hobby (id,name,age,occupation,breakfast,lunch,dinner,hobby)
. . . . . . . . . . . . . .> select id,name,age,occupation,breakfast,lunch,dinner,hobby
. . . . . . . . . . . . . .> from person_diet_hobby_temp;
INFO : Compiling command(queryId=hive_20221222012112_c8d6d18b-d1f7-4a46-b54b-90c440888d31): with person_hobby as (select t1.id,t1.name,t1.age,t1.occupation,t2.hobby from person t1
inner join hobby t2
on t1.id=t2.id),
person_diet_hobby_temp as (select a.id,a.name,a.age,a.occupation,b.breakfast,b.lunch,b.dinner,a.hobby
from person_hobby a
inner join diet b
on a.id = b.id)
insert into table person_diet_hobby (id,name,age,occupation,breakfast,lunch,dinner,hobby)
select id,name,age,occupation,breakfast,lunch,dinner,hobby
from person_diet_hobby_temp
INFO : Semantic Analysis Completed
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:_col0, type:int, comment:null), FieldSchema(name:_col1, type:string, comment:null), FieldSchema(name:_col2, type:int, comment:null), FieldSchema(name:_col3, type:string, comment:null), FieldSchema(name:_col4, type:string, comment:null), FieldSchema(name:_col5, type:string, comment:null), FieldSchema(name:_col6, type:string, comment:null), FieldSchema(name:_col7, type:string, comment:null)], properties:null)
INFO : Completed compiling command(queryId=hive_20221222012112_c8d6d18b-d1f7-4a46-b54b-90c440888d31); Time taken: 0.208 seconds
INFO : Executing command(queryId=hive_20221222012112_c8d6d18b-d1f7-4a46-b54b-90c440888d31): with person_hobby as (select t1.id,t1.name,t1.age,t1.occupation,t2.hobby from person t1
inner join hobby t2
on t1.id=t2.id),
person_diet_hobby_temp as (select a.id,a.name,a.age,a.occupation,b.breakfast,b.lunch,b.dinner,a.hobby
from person_hobby a
inner join diet b
on a.id = b.id)
insert into table person_diet_hobby (id,name,age,occupation,breakfast,lunch,dinner,hobby)
select id,name,age,occupation,breakfast,lunch,dinner,hobby
from person_diet_hobby_temp
WARN :
INFO : Query ID = hive_20221222012112_c8d6d18b-d1f7-4a46-b54b-90c440888d31
INFO : Total jobs = 1
INFO : Starting task [Stage-13:MAPREDLOCAL] in serial mode
INFO : Execution completed successfully
INFO : MapredLocal task succeeded
INFO : Launching Job 1 out of 1
INFO : Starting task [Stage-11:MAPRED] in serial mode
INFO : Number of reduce tasks is set to 0 since there's no reduce operator
INFO : number of splits:1
INFO : Submitting tokens for job: job_1668791143457_0511
INFO : Executing with tokens: []
INFO : The url to track the job: http://node2:8088/proxy/application_1668791143457_0511/
INFO : Starting Job = job_1668791143457_0511, Tracking URL = http://node2:8088/proxy/application_1668791143457_0511/
INFO : Kill Command = /opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/hadoop/bin/hadoop job -kill job_1668791143457_0511
INFO : Hadoop job information for Stage-11: number of mappers: 1; number of reducers: 0
INFO : 2022-12-22 01:21:28,400 Stage-11 map = 0%, reduce = 0%
INFO : 2022-12-22 01:21:35,588 Stage-11 map = 100%, reduce = 0%, Cumulative CPU 3.03 sec
INFO : MapReduce Total cumulative CPU time: 3 seconds 30 msec
INFO : Ended Job = job_1668791143457_0511
INFO : Starting task [Stage-8:CONDITIONAL] in serial mode
INFO : Stage-5 is selected by condition resolver.
INFO : Stage-4 is filtered out by condition resolver.
INFO : Stage-6 is filtered out by condition resolver.
INFO : Starting task [Stage-5:MOVE] in serial mode
INFO : Moving data to directory hdfs://nameservice1/user/hive/warehouse/hs_huangbin.db/person_diet_hobby/.hive-staging_hive_2022-12-22_01-21-12_151_5361479725871257975-20/-ext-10000 from hdfs://nameservice1/user/hive/warehouse/hs_huangbin.db/person_diet_hobby/.hive-staging_hive_2022-12-22_01-21-12_151_5361479725871257975-20/-ext-10003
INFO : Starting task [Stage-0:MOVE] in serial mode
INFO : Loading data to table hs_huangbin.person_diet_hobby from hdfs://nameservice1/user/hive/warehouse/hs_huangbin.db/person_diet_hobby/.hive-staging_hive_2022-12-22_01-21-12_151_5361479725871257975-20/-ext-10000
INFO : Starting task [Stage-3:STATS] in serial mode
INFO : MapReduce Jobs Launched:
INFO : Stage-Stage-11: Map: 1 Cumulative CPU: 3.03 sec HDFS Read: 13810 HDFS Write: 1562 HDFS EC Read: 0 SUCCESS
INFO : Total MapReduce CPU Time Spent: 3 seconds 30 msec
INFO : Completed executing command(queryId=hive_20221222012112_c8d6d18b-d1f7-4a46-b54b-90c440888d31); Time taken: 25.558 seconds
INFO : OK
5 rows affected (25.798 seconds)
版权归原作者 玩数据的小彬 所有, 如有侵权,请联系我们删除。