
项目概要
对视频的标题,播放量,弹幕量以及收藏量,视频分类等数据进行分析。通过flask项目中的python代码进行数据库连接进行前后端交互功能的实现,通过layui框架进行系统前端页面的功能实现,通过knn分类算法以及k均值聚类算法对爬取的数据进行分析,最后通过前端页面对数据进行可视化展示。
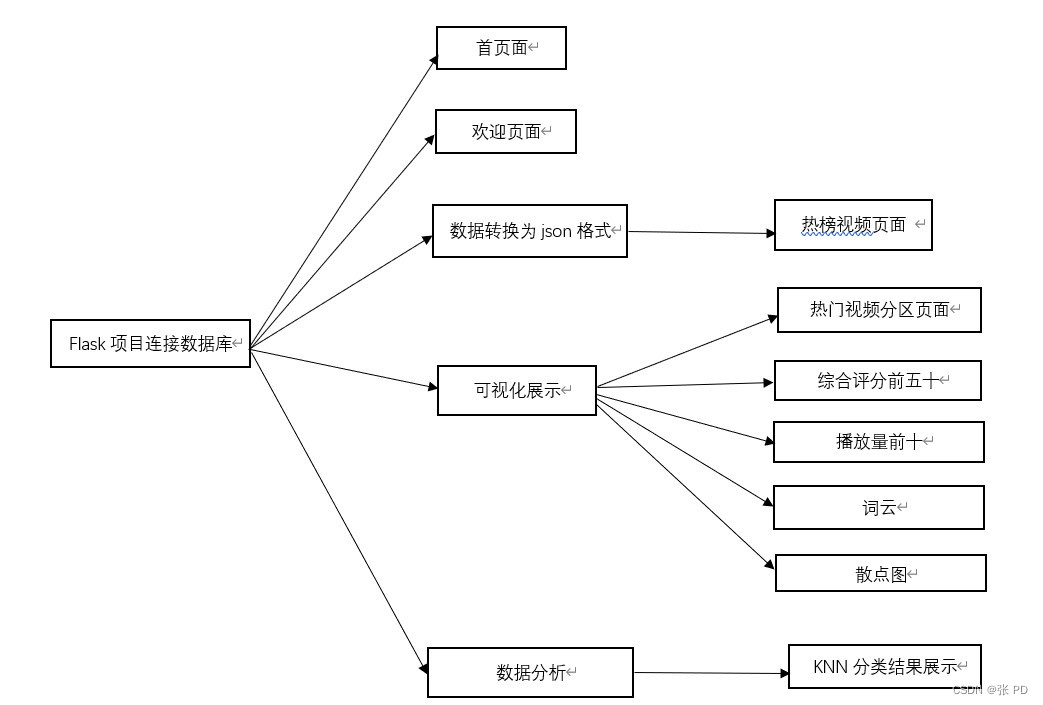
项目设计
flask整体框架
使用工具pycharm创建flask项目,文件目录整体如下:
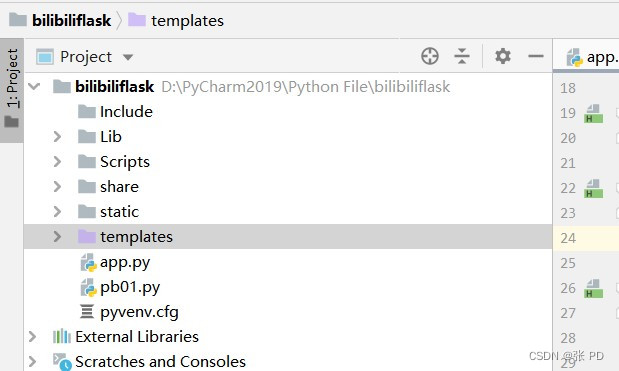
static: 存放静态文件,例如js,css,image等文件。
templates文件夹:用于放置html模板文件。
app.py: 工程主文件,用于存放配置项目,项⽬管理⽂件,通过它管理项⽬。
app.py主程序代码为
@app.route('/')
def hello_world():
return 'Hello World!'
运行app.py程序运行项目,程序访问默认路径” http://127.0.0.1:5000/”,返回函数运行结果。
数据库设计
包括视频标题、视频播放量、投币量、收藏量、综合得分等基本信息,爬虫代码主要基于beautifulsoup技术编写实现。
名
类型
长度
小数点
不是null
标题
Varchar
255
0
是
播放量
Varchar
34
0
是
弹幕量
Varchar
34
0
是
收藏量
Varchar
34
0
是
综合得分
Bigint
20
0
是
视频地址
Varchar
73
0
是
分类
Varchar
34
0
是
模块设计
首页设计
首页index.html使用layui框架实现前端页面的设置,使用flask框架语法将每个模块页面路径导入,运行程序时点击页面会直接跳转到对应的html页面,欢迎界面部分代码如下:
<li class="layui-col-xs3">
<a href="https://www.bilibili.com/v/popular/all?spm_id_from=333.851.b_7072696d61727950616765546162.3" target="_blank">
<cite class="c1">综合热门</cite>
<p><span>各个领域中新奇好玩的优质内容都在这里~</span></p>
</a>
</li>
数据搜索模块
在flask的py文件中连接数据库并读取数据库中college_score数据表返回json数据文件,在热榜视频.html页面送使用ajax读取json文件中json数据,并返回到前端,使用bootstrap table中的表格元素将数据以表格形式返回在前端中,同时设置添加查询功能,对视频进行查询。
读取数据表中每个字段的值,使用json.dumps方法将获取的数据转换为json数据格式,写入json文件中,主函数代码如下:
if __name__ == '__main__':
# 调用函数
jsonData = TableToJson()
print(u'转换为json格式的数据:', jsonData)
# 以读写方式w+打开文件,路径前加r,防止字符转义
f = open(r'D:/Bdatas/data01.json', 'w+',encoding="utf-8")
f.write(jsonData) # 写数据
f.close() # 关闭文件
在html页面中读取json数据展示到前端页面中,其中使用bootstrap table表格元素使数据以表格形式展示,需要引用js文件,引用代码如下:
<link rel="stylesheet" href="../static/layui/css/layui.css"/>
<link rel="stylesheet" href="../static/css/admin.css"/>
<link rel="stylesheet" href="../static/layui/css/bootstrap.css">
<link rel="stylesheet" href="../static/layui/css/bootstrap-table.min.css">
<script type="text/javascript" src="../static/layui/jquery-3.5.1.js"></script>
对于ajax的实现需要引入jquery.js文件,jQuery是一个JavaScript库,有助于简化和标准化JavaScript代码和HTML元素之间的交互。
ajax实现页面与web服务器之间的数据传输,代码如下:
<script>
$('#mytab03').bootstrapTable({
method: 'get',
url: "../static/json/data01.json", // 请求路径
striped: true, // 是否显示行间隔色
search: true, //是否显示表格搜索
pageNumber: 1, // 初始化加载第一页
pagination: true, // 是否分页
sidePagination: 'client', // server:服务器端分页|client:前端分页
pageSize: 20, // 单页记录数
pageList: [5, 10, 20, 30],
columns: [{
title: '标题',
field: 'title',
}]
})
</script>
数据可视化模块
数据可视化模块中基于echarts设计饼图、折线图、条形图、散点图以及绘制词云来实现数据的可视化展示。在数据清理阶段将干净的数据直接存储在csv文件中,编写Python代码读取csv数据集,创建DataFrame,首先创建SparkSession对象,代码如下:
#创建SparkSession对象
sc = SparkContext('local', 'spark_project')
sc.setLogLevel('WARN')
spark = SparkSession.builder.getOrCreate()
#创建DataFrame
df = spark.read.format('com.databricks.spark.csv')
.options(header='true', inferschema='true').load(
'D:/SPARKFiles/listdata0012.csv')
之后可以进行函数模块定义进行数据提取。同时DataFrame数据也可以通过show()、drop()、withColumn()等方法实现数据展示、删除或转换数据类型等操作达到数据清理的目的,代码如下:
#删除不需要的字段
df = df.drop('types', 'bv', 'date', 'url', 'title', 'danmu', 'favorite', 'likes', 'replay', 'share', 'view')
#将字符串字段转换为整型
df = df.withColumn("coins", df["coins"].cast(IntegerType()))
#去除选择字段为空值记录
df = df.dropna(subset = ["author","mid","coins"])
#打印默认的字段类型信息
df.printSchema()
#打印前20条数据
df.show()
#打印总行数
print(df.count())
最后将清理后的数据存储在本地文件中,代码如下:
df.coalesce(1).write.option("header", "true").csv("D:/Bdatas/technology04")
该代码将数据存储到本地文件夹中,数据太多自动在文件夹中存储到分区文件中,coalesce(1)将分区合并为一个分区。
使用SQL语句根据指定字段对需要获取的数据信息进行整合,示例如下:
#播放量最高的10个视频
def maxplay():
maxplayDF = spark.sql("SELECT title,MAX(replay) AS maxreplay FROM data GROUP BY title ORDER BY maxreplay DESC LIMIT 10")
return maxplayDF.collect()
定义主函数,将各函数块提取出的数据存储到json文件中,部分代码如下:
def save(path, data):
with open(path, 'w') as f:
f.write(data)
if __name__ == "__main__":
base = "static/json/"
if not os.path.exists(base):
os.mkdir(base)
m = {
"typeCount": {
"method": typeCount,
"path": "typeCount.json"
} }
for k in m:
p = m[k]
f = p["method"]
save(base + m[k]["path"],
json.dumps(f(),ensure_ascii=False))
print ("done -> " + k + " , save to -> " + base + m[k]["path"])
绘制词云图,读取json文件,基于base64绘制词云图片并嵌入html页面中,部分代码如下:
<script>
var base64image = "data:image/png;base64,iVBORw0KGgo……Jggg=="
var myChart = echarts.init(document.getElementById('chart'));
myChart.showLoading();
var maskImage = new Image();
maskImage.src = base64image
maskImage.onload = function () {
$.getJSON("../static/json/authorCount.json", data => {
var wc = [];
data = data.map(v => ({
author: v[0],
count: parseInt(v[1]),
}))
for (var i = 0; i < 300; i++) {
wc.push({
"name": data[i].author,
"value": data[i].count,
});
}
myChart.setOption({
backgroundColor: '#fff',
title:{
text: '视频热词'
},
tooltip: {
show: true
},
series: [{
type: 'wordCloud',
gridSize: 1,
sizeRange: [12, 55],
rotationRange: [-45, 0, 45, 90],
maskImage: maskImage,
textStyle: {
normal: {
color: function () {
return 'rgb(' +
Math.round(Math.random() * 255) +
', ' + Math.round(Math.random() * 255) +
', ' + Math.round(Math.random() * 255) + ')'
}
}
},
left: 'center',
top: 'center',
right: null,
bottom: null,
data: wc
}]
});
myChart.hideLoading();
})
}
</script>
绘制散点图
为了更方便的可视化,选择两个维度分别是分享量和投币量,基于matplotlib画图,代码如下:
plt.figure(figsize=(10,8)) #画布大小
#绘制训练集数据
plt.scatter(x=t0["share"][:300],y=t0["coins"][:300],color="r",label="types")
plt.scatter(x=t1["share"][:300],y=t1["coins"][:300],color="g",label="types")
#绘制测试集数据
right = test_X[result == test_y]
wrong = test_X[result != test_y]
plt.scatter(x = right["share"],y=right["coins"],color="c",marker="x",label="right")
plt.scatter(x = wrong["share"],y=wrong["coins"],color="m",marker=">",label="wrong")
plt.xlabel("分享数")
plt.ylabel("投币数")
plt.title("KNN分类结果显示")
plt.legend(loc="best")
将绘制图形嵌入HTML页面,有方法:
html可以以base64代码的形式内嵌图片。具体形式为 <img src="data:image/png; base64, iVBORw...。后面的 iVBORw…即为图像的 Base64 编码信息。故而只需将图像转为 base64 代码即可将图像嵌入 HTML 代码字符串中。
matplotlib 的 pyplot.savefig() 函数可以将绘图窗口保存为二进制文件格式。
lxml 库的 etree 模块可以实现解析 HTML 代码并写入 html 文件
# figure 保存为二进制文件
buffer = BytesIO()
plt.savefig(buffer)
plot_data = buffer.getvalue()
#plt.show() # 显示绘制出的图
# 图像数据转化为 HTML 格式
imb = base64.b64encode(plot_data)
ims = imb.decode()
imd = "data:image/png;base64,"+ims
test_im = """<h1>Demo Figure</h1> """ + """<img src="%s">""" % imd
# lxml 库的 etree 解析字符串为 html 代码,并写入文件
html = etree.HTML(test_im)
tree = etree.ElementTree(html)
tree.write('demo.html')
项目地址:https://download.csdn.net/download/weixin_44355584/86733256
版权归原作者 张 PD 所有, 如有侵权,请联系我们删除。