
目录
1. MQ的基本概念
1.1 MQ概述
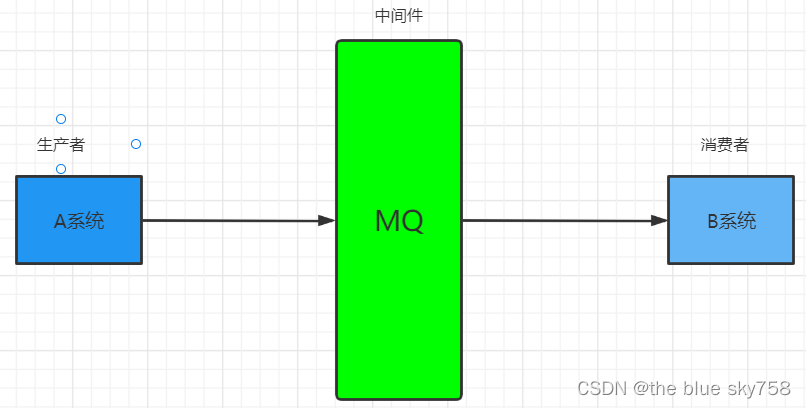
MQ全称是Message Queue(消息队列),是保存消息在传输过程中的一种容器,既是存储消息的一种中间件。多是应用在分布式系统中进行通信的第三方中间件,如下图所示,发送方成为生产者,接收方称为消费者。
1.2 MQ的优势
1. 应用解耦
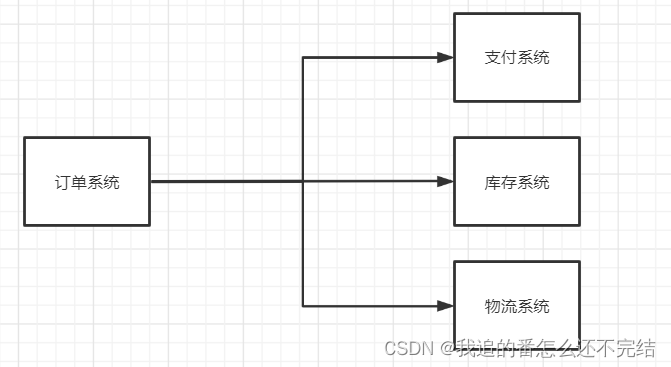
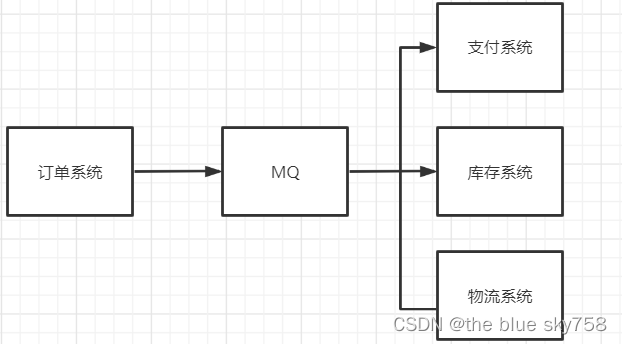
如上两图对比,订单系统直接远程调用支付系统、库存系统、物流系统进行通信,支付、库存、物流中的任何一个系统挂了,都会影响到订单系统的正常运行,所以订单系统的耦合度高;加了MQ之后,三个系统中的任何一个系统出现异常,订单系统还能够正常运行,即MQ实现了生产者和消费者之间的应用解耦。
2. 异步提速
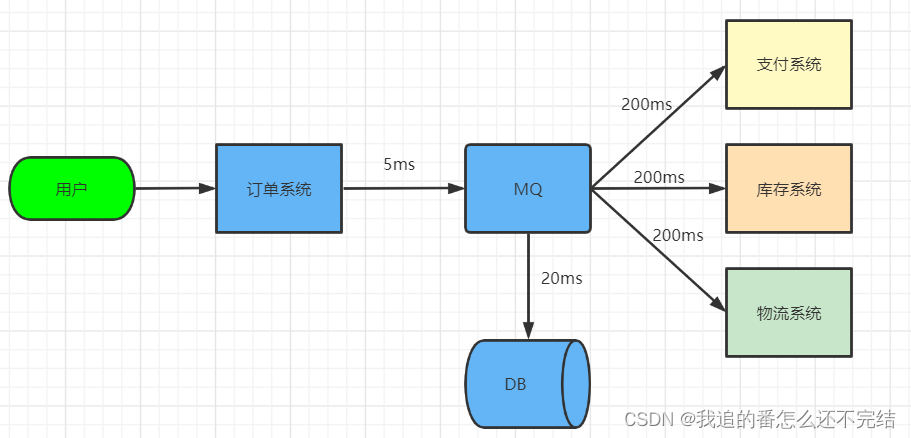
如上图所示,用户点击下单后,订单系统通过MQ可以同时调用支付系统、库存系统、物流系统,完成后再将下订单的记录保存到数据库中,总共耗时是5 + 200 + 20 = 225 (ms);如果没有MQ,虽然少了访问MQ的时间,但后面的系统是逐一顺序执行的,需要的时间为200 x 3 + 20 = 620(ms),处理完用户下单的请求时间反而变慢了。
3. 削峰填谷
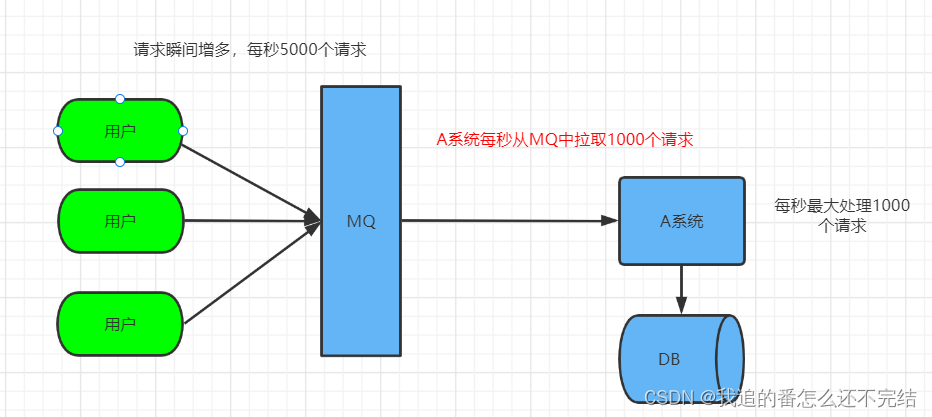
假设有一个系统,每秒只能处理1000个请求,有一个时间段,每秒有5000个请求访问A系统,如果A系统直接处理这5000个请求,系统就会崩溃。有了MQ之后,只需每秒从MQ中拉取1000个消息(请求)消费(处理)即可,没有及时处理的请求会堆积在MQ中,等访问高峰中一过,每秒可能不会有1000个请求发送过来,A系统也会从MQ中拉取1000个消息消费,直到消费完。用术语来说,MQ具有"削峰填谷"的作用。
1.3 MQ的劣势以及可能引发的问题
- 系统可用性降低
系统引用的外部依赖越多,稳定性就越差。一旦MQ宕机,整个系统就会不可用,对业务造成影响,如何保证MQ的高可用?
- 系统复杂度提高
引用了外部依赖,复杂度自然提高了。以前的系统通信方式是通过直接的同步远程调用,现在的系统的通信方式是通过MQ的异步调用。异步调用时就有了相应的问题,如何保证消息没有被重复消费,怎么处理消息丢失情况?怎么保证消息传递的顺序性?
- 数据一致性问题
既然是异步调用,有一个场景,如果A系统处理完业务之后,通过MQ给B、C系统发送消息数据,B处理成功,C处理失败,这种情况怎么处理,即如何保证消息数据处理的一致性?
1.4 常见的MQ产品

名词解释:
吞吐量:每秒处理的消息条数
ActiveMQ已经淘汰了,其他三种各有千秋。
追求吞吐能力:RocketMQ、Kafka
追求消息低延迟:RabbitMQ、Kafka
追求消息可靠性:RabbitMQ、RocketMQ、
2. RabbitMQ的知识点
2.1 RabbitMQ的工作模式
1. 简单模式
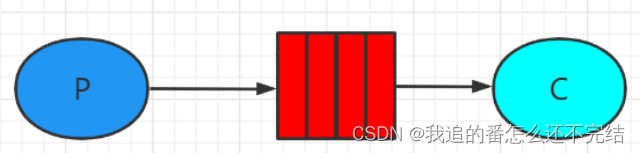
一个生产者、一个消费者,不需要设置交换机(使用默认的交换机)即可。
2. 工作队列模式 Work Queue
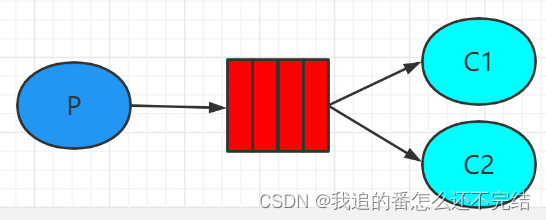
一个生产者、多个消费者,对同一个消息是竞争关系,不需要设置交换机(使用默认的交换机)
3. 发布订阅模式 Publish/subscribe
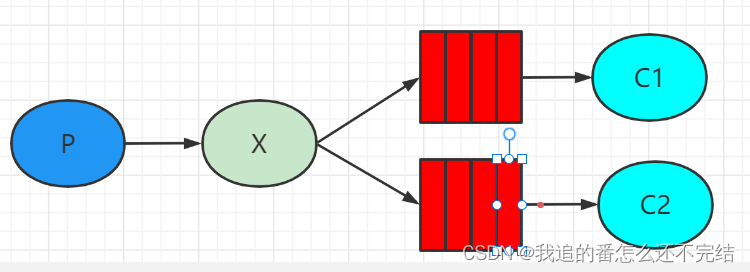
在订阅模型中,多了一个Exchange角色,上图中各个部分的含义
P: 生产者,要发送消息的程序,不是直接发送到队列中,而是发送到交换机中。
C: 消费者,接收消息的程序,会一直等待消息到来。
Queue(红色部分): 消息队列,接收消息,缓存消息。
X: 交换机,即Exchange。一方面,接收生产者发送的消息。另一方面,知道如何处理消息,例如递交给某个特别队列、递交给所有队列、或是将消息丢弃。具体是如何操作的,取决于Exchange的类型。Exchange有常见以下3种类型。
Fanout: 广播模式,将消息交给所有绑定到交换机的队列, Direct: 路由模式,把消息交给符合指定routing key的队列 Topic: 主题模式,与路由模式的区别是用通配符匹配,把消息交给符合routing pattern的队列
注意:交换机只负责转发消息,不具备存储消息能力,所以,如果没有符合规则的队列,那么消息就会丢失!
总结:RabbitMQ工作模式总结:我的概括为RabbitMQ的工作模式有三种,分别是简单模式、工作队列模式,发布订阅模式。其中,发布订阅模式根据设置Exchange(交换机)的类型又可分为Fanout模式、Direct模式、和Topic模式。
2.2 RabbitMQ的高级特性(有些概念需要结合视频讲解)
1. 消息的可靠投递
RabbitMQ提供了两种方式用来控制消息投递的可靠性
- Confirm 确认模式
- Return 退回模式
要理解这两种模式的作用,要知道RabbitMQ消息投递的大致流程:

Producer(生产者)--->Exchange ---> Queue --->Consumer(消费者)
- 消息从producer 到 exchange 则会返回一个 confirmCallback.
- 消息从 exchange到queue投递失败则会返回一个returnCallback.
可以简单理解成告知Producer是否发送消息成功。
2. Consumer ack
ack即Acknowledge的前三个字母缩写,确认的意思。表示消费端收到消息后的确认方式。默认是自动确认,可以改为手动确认和根据异常情况确认(一般不用)。
自动确认是指,消息一旦被Consumer接收到,就自动确认收到,将相应的message从RabbitMQ的消息缓存中移除。实际情况下,很可能消息接收到了,但业务处理出现异常,那么该消息就会消失。
手动确认是指,消费者端的业务处理成功后,调用basicAck()手动签收,然后才调用相关方法从RabbitMQ缓存中移除消息,出现业务异常时就调用basicNack()拒绝签收消息让RabbitMQ重新发送消息。
小结:RabbitMQ为了确保消息的可靠性,即保证消息不丢失,生产者是否发送成功、消费者是否消费成功都有对应的确认机制,其实为了保证消息的可靠性还要对RabbitMQ的一些消息组件进行持久化,message、queue(不看源码或者不重写RabbitMQ的一些方法验证会不能理解)等。
所以,RabbitMQ提供了三种方式保证消息丢失。
- 保证生产者已发送消息,开启confirm模式,如果生产者端发送的消息写入了RabbitMQ中就会返回 confirmCallback,告诉你说这个消息已经ok了;如果没有写入,就返回一个returnCallback,告诉这个消息没有接收到,需要重发。
- RabbitMQ持久化,消息写入之后会持久化到磁盘中,假如RabbitMQ挂了,恢复之后会自动读取之前的存储的数据。
- 保证消费者已接收到消息并且该消息对应的业务逻辑处理能成功,开启手动确认模式(手动ack)。
3. 死信队列
死信队列 DLX (Dead Letter Exchanges) 本身也是一个普通的消息队列,在创建队列的时候可以设置一些参数 x - dead - letter - exchange,可以将一个普通的消息队列设置为一个死信队列。
那么,什么样的消息才能被添加到死信队列中去呢?本质上没有被Consumer消费却没有丢失的消息都可以添加到死信队列中,一般是三种情况下出现死信消息(自我创造的名词)。
(1)consumer拒绝接收并且不重新放入到原目标队列的消息,设置requeue = false;
(2)原队列设置了消息过期时间,消息到达过期时间时还没被消费
(3)队列消息长度达到限制时再试图添加到队列中的消息。
2.3 RabbitMQ的应用问题
1. 幂等性保障
幂等性概述,在MQ中,幂等性是指消费多条相同的消息时,得到与消费该消息一次相同的结果。
解决方案根据具体的业务应用场景来设计。
如在进行insert的业务操作时,可以先根据主键查一下数据库有没有该条记录,有就不insert,变为update;
在进行update的业务操作时,可以用乐观锁的机制,用版本控制更新的语句,如更新时执行的SQL语句操作是update 表名 set 字段名 = ? ,version = version + 1 where ? and version = 1。由于发送的是version = 1的请求,第一次执行后,存入数据库的version变为了2, 往后还多次发送version = 1的请求,发现找不到了version = 1 的记录,就不会执行更新操作了。
2. 如何保证消息消费的顺序性
会造成消息消费顺序错乱的两种情况:
- 一个queue,有多个consumer去消费,不同消费者处理数据的速度不一样,在数据库保存的记录可能就不是按顺序的。
- 一个queue对应一个consumer,但是consumer里面进行了多线程消费。
解决方式:
(1)一个queue对应一个consumer,不使用多线程。
(2)对于一个queue对应一个consumer,消费者用了多线程:消费者不直接去消费消息,而是先在consumer内部用内存队列给消息排队,将关键字相同的数据放到相同的内存队列中,每个线程只消费对应的内存队列。
版权归原作者 我追的番怎么还不完结 所有, 如有侵权,请联系我们删除。