
1. 什么是Kafka
Kafka
是一个分布式流处理系统,流处理系统使它可以像消息队列一样
publish(发布)
或者
subscribe(订阅)
消息,分布式提供了容错性,并发处理消息的机制。
kafka运行在集群上,集群包含一个或多个服务器。kafka把消息存在
topic
中,每一条消息包含键值(
key
),值(
value
)和时间戳(
timestamp
)。
2. kafka基本概念
producer: 消息生产者,就是向kafka broker发消息的客户端。consumer: 消息消费者,是消息的使用方,从Kafka Broker 拉取消息,负责消费Kafka服务器上的消息。topic: 主题,由用户定义并配置在Kafka服务器,用于建立Producer和Consumer之间的订阅关系。生产者发送消息到指定的Topic下,消息者从这个Topic下消费消息。你可以把它理解为一个队列,topic将消息分类,生产者和消费者面向的是同一个 topic。partition:消息分区,一个topic可以分为多个partition,partition是相对于topic是在在物理上的概念,每个partition是一个有序的队列,partition中的每条消息都会被分配一个有序的id(offset)。broker:一台kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个topic。consumer-group:消费者分组,用于归组同类消费者。每个consumer属于一个特定的consumer group,多个消费者可以共同消息一个Topic下的消息,每个消费者消费其中的部分消息,这些消费者就组成了一个分组,拥有同一个分组名称,通常也被称为消费者集群。 消费者组内每个消费者,负责消费不同分区的数据,提高消费能力。一个分区只能由组内一个消费者消费,消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。offset:消息在partition中的偏移量。每一条消息在partition都有唯一的偏移量,消息者可以指定偏移量来指定要消费的消息。记录消费者消费的位置信息,监控数据消费到什么位置,当消费者挂掉,再重新恢复的时候,可以从消费位置继续消费。Zookeeper:Kafka集群能够正常工作,需要依赖于zookeeper,zookeeper 帮助Kafka 存储和管理集群信息。
3.安装kafka
这里我的安装环境是mac
brew install kafka
kafka使用
zookeeper
管理,安装过程会自动安装
zookeeper
以我这里的配置为说明:
kafka安装路径:
/opt/homebrew/Cellar/kafka/3.2.1
kafka属性文件:
/opt/homebrew/etc/kafka/server.properties
zookeeper属性文件:
/opt/homebrew/etc/kafka/zookeeper.properties
修改kafka启动配置文件
vi /opt/homebrew/etc/kafka/server.properties
该配置为单机版,修改kafka的监听地址和端口为localhost:9092。
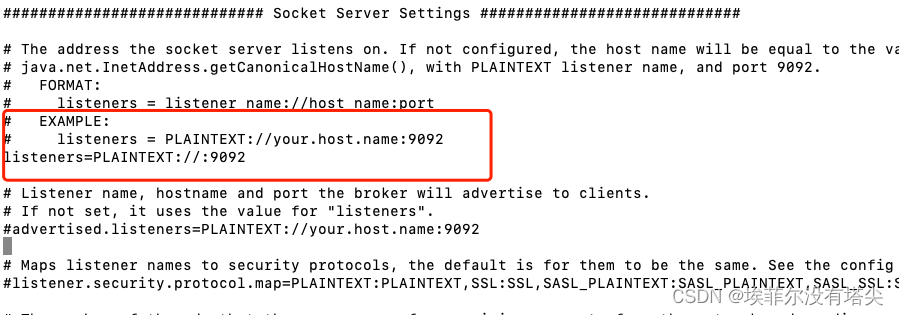
前台方式启动服务
/opt/homebrew/opt/kafka/bin/kafka-server-start /opt/homebrew/etc/kafka/server.properties
后台方式服务
brew services start zookeeper
brew services start kafka
查看服务启动没:
4.可视化工具Offset Explorer使用
下载地址:https://www.kafkatool.com/download.html
下载对应的版本:
测试链接:
每个message默认是以二进制形式展示的, 设置为string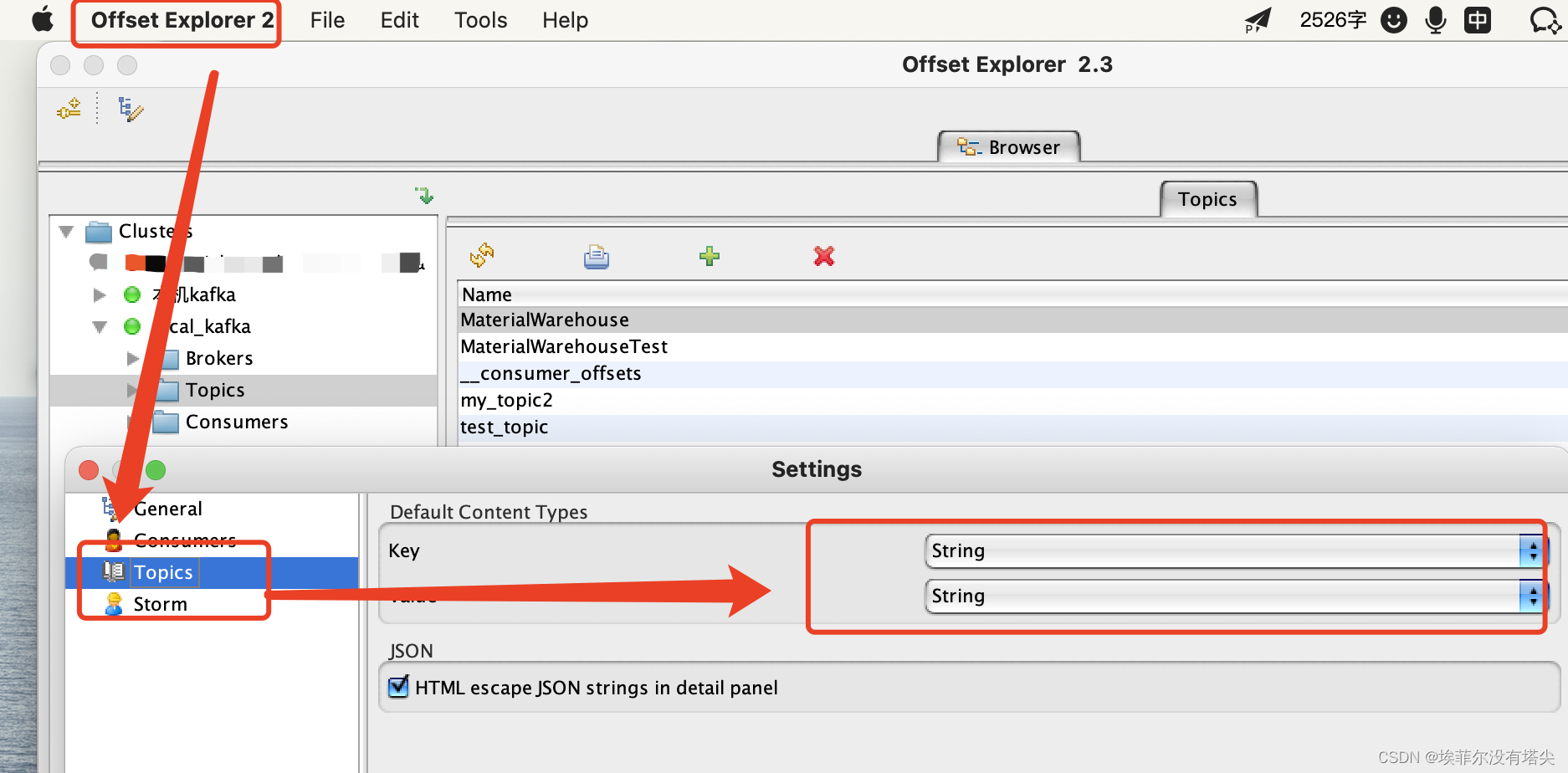
5.python操作kafka
用Python读写Kafka,我们要使用的一个第三方库叫做
kafka-python
。
pip install kafka-python
kafka-python是一个python的Kafka客户端,可以用来向
kafka的topic
发送消息、消费消息。
5.1消息生产者
代码如下:
第一种写法:
from kafka import KafkaProducer
producer =KafkaProducer(
bootstrap_servers=['127.0.0.1:9092'],
value_serializer=lambda m: json.dumps(m, ensure_ascii=False).encode(),)for _id in range(1,5):
content ={"title":"生命不息,运动不止!","index": _id}
future = producer.send(topic='test_topic', value=content)
result = future.get(timeout=10)print("kafka生产数据:", result)
参数解释:
topic: topic的名称,指定向那个topic发送下消息。如果不手动创建topic的话,发送数据的时候会自动创建。bootstrap_servers:指定kafka服务器,接受的类型是数组,如果是多台服务器,就在数组里面多写几个服务器地址,比如:['127.0.0.1:9092', '127.0.0.1:9093', '127.0.0.1:9094']value_serializer:用来指定序列化的方式,这里使用json来序列化数据,从而实现向Kafka传入一个字典,Kafka 会自动把value自动转为json格式。
第二种写法:
from kafka import KafkaProducer
producer =KafkaProducer(
bootstrap_servers=['127.0.0.1:9092'])for _id in range(1,5):
content ={"title":"生命不息,运动不止!","index": _id}
future = producer.send(
topic="test_topic",
value=json.dumps(content, ensure_ascii=False).encode("utf-8"),)
result = future.get(timeout=10)print("kafka生产消息:", result)
这里也可以在发送消息的直接对value用
json.dumps()
方法。
运行结果如下:

然后在kafka客户端工具
offset explorer2
看看效果:
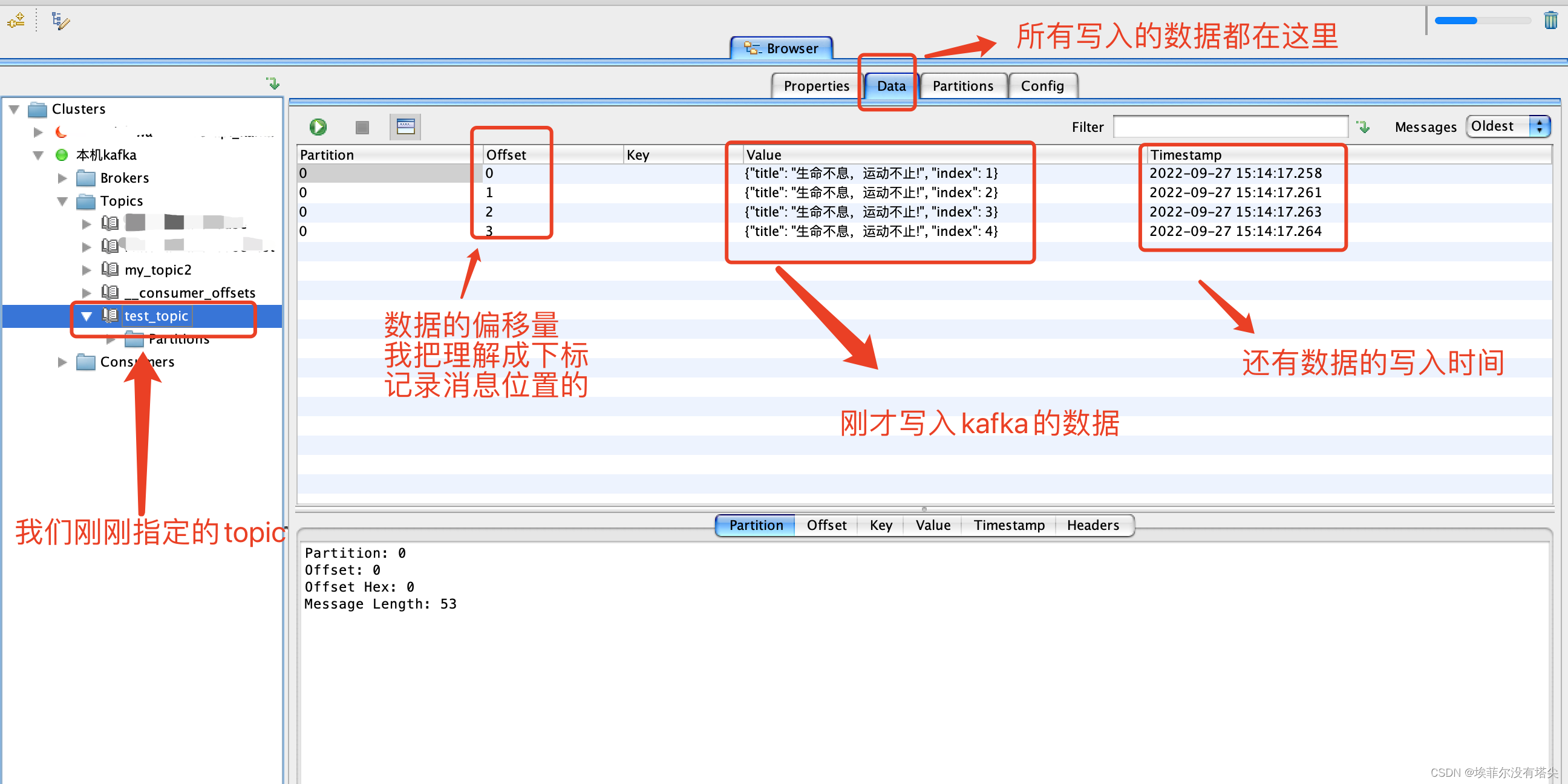
5.2消息消费者
此时开另一个程序运行生产者代码,即会有输出显示;即监听生产者发布的消息,只要生产者新产生了一条消息,消费端就会接受到一条消息。
代码如下:
消费方式1 默认消费所有分区的消息
import time
from kafka import KafkaConsumer
bootstrap_servers =['127.0.0.1:9092']
consumer =KafkaConsumer(group_id='test_consumer_group', bootstrap_servers=bootstrap_servers)
consumer.subscribe(topics=['test_topic'])for msg in consumer:
time.sleep(2)print("-----------------------------------------")print("接受到消息:", msg)print(f"topic = {msg.topic}") # topic default is string
print(f"partition = {msg.partition}")print(f"value = {msg.value.decode()}") # bytes to string
print(f"timestamp = {msg.timestamp}")print("time = ", time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(msg.timestamp /1000)))print("offset偏移量:", msg.offset)
运行结果:
参数解释:
topic:topic的名称,表示当前消费者从那个topic监听并读取消息。group_id:指定此消费者实例属于的组名,group_id这个参数后面的字符串可以任意填写;如果两个程序的Topic与group_id相同,那么他们读取的数据不会重复,两个程序的Topic相同,但是group_id不同,那么他们各自消费全部数据,互不影响auto_offset_rest这个参数有两个值,earliest和latest,如果省略这个参数,那么默认就是latest;auto_offset_reset的作用,是在你的 group 第一次运行,还没有 offset 的时候,给你设定初始的 offset。而一旦你这个group已经有offset了,那么auto_offset_reset这个参数就不会再起作用了
消费方式2, 指定消费分区
import time
from kafka import KafkaConsumer
from kafka import TopicPartition
bootstrap_servers =['127.0.0.1:9092']
consumer =KafkaConsumer(group_id='test_consumer_group', bootstrap_servers=bootstrap_servers)
consumer.assign([TopicPartition('test_topic',0)])for msg in consumer:
time.sleep(2)print("接受到消息:", msg)
消费方式3,手动commit,生产中建议使用这种方式
import time
from kafka import KafkaConsumer
from kafka import TopicPartition
bootstrap_servers =["127.0.0.1:9092"]
consumer =KafkaConsumer(
bootstrap_servers=bootstrap_servers,
consumer_timeout_ms=1000,
group_id="test_consumer_group",
enable_auto_commit=False,)
consumer.assign([TopicPartition("test_topic",0)])for msg in consumer:
time.sleep(2)print("接受到消息:", msg)
consumer.commit()
6.获取所有的topic
kafka-python
获取所有的topic接口是在
KafkaConsumer
类中实现的
from kafka import KafkaConsumer
# 获取topic列表以及topic的分区列表defretrieve_topics():
consumer = KafkaConsumer(bootstrap_servers=servers)print(consumer.topics())# 获取topic的分区列表defretrieve_partitions(topic):
consumer = KafkaConsumer(bootstrap_servers=servers)print(consumer.partitions_for_topic(topic))# 获取Consumer Group对应的分区的当前偏移量defretrieve_partition_offset():
consumer = KafkaConsumer(bootstrap_servers=servers,
group_id='kafka-group-id')
tp = TopicPartition('kafka-topic',0)
consumer.assign([tp])print("starting offset is ", consumer.position(tp))
7. 创建、删除topic
from kafka import KafkaAdminClient
from kafka.admin import NewTopic
from kafka.errors import TopicAlreadyExistsError
admin = KafkaAdminClient(bootstrap_servers=servers)# 创建topicdefcreate_topic():try:
new_topic = NewTopic("create-topic",8,3)
admin.create_topics([new_topic])except TopicAlreadyExistsError as e:print(e.message)# 删除topicdefdelete_topic():
admin.delete_topics(["create-topic"])
8.获取消费组信息
from kafka import KafkaAdminClient
admin = KafkaAdminClient(bootstrap_servers=servers)# 获取消费组信息 defget_consumer_group():# 显示所有的消费组print(admin.list_consumer_groups())# 显示消费组的offsetsprint(admin.list_consumer_group_offsets("kafka-group-id"))
9.获取topic配置信息
from kafka import KafkaAdminClient
from kafka.admin import ConfigResource, ConfigResourceType
admin = KafkaAdminClient(bootstrap_servers=servers)# 获取topic的配置信息defget_topic_config():
resource_config = ConfigResource(ConfigResourceType.TOPIC,"create-topic")
config_entries = admin.describe_configs([resource_config])print(config_entries.resources)
10.offset 和 groupID详解
10.1consumer消费者
kafka消费者可以从多个
broker
中读取数据,也可以消费多个
topic
中的数据。
因为Kafka的broker是无状态的,所以
consumer
必须使用
partition offse
t来记录消费了多少数据。如果一个
consumer
指定了一个topic的
offset
,意味着该
consumer
已经消费了该offset之前的所有数据。
consumer
可以通过指定
offset
,从topic的指定位置开始消费数据。
consumer
的offset存储在
Zookeeper
中。
10.2 offset偏移量
用来保存消费进度。
offset
表示在当前
topic
,当前
groupID
下消费到的位置。offset为earliest并不代表offset=1.在不进行过期配置的情况下,
kafka消息默认7天时间就会过期
。过期后其
offset
也就随之发生变化,使得用数字进行配置的消费进度并不准确。
earliest:自动重置到最早的offset。latest:看上去重置到最晚的offset。none:如果边更早的offset也没有的话,就抛出异常给consumer,告诉consumer在整个consumer group中都没有发现有这样的offset。
10.3 groupID
一个字符串用来指示一组consumer所在的组。相同的
groupID
表示在一个组里。相同的groupID消费记录offset时,记录的是同一个offset
。
所以,此处需要注意,
(1)如果多个地方都使用相同的
groupid
,可能造成个别消费者消费不到的情况
(2)如果单个消费者消费能力不足的话,可以启动多个相同
groupid的consumer
消费,处理相同的逻辑。
但是,
多线程
的时候,需要增加每个
groupid下的partition
分区数量,便于每个线程稳定读取固定的partition,提高消费能力。
参考文献:
https://blog.csdn.net/weixin_43411585/article/details/124774360
https://www.cnblogs.com/ExMan/p/14884681.html
https://www.jianshu.com/p/76d4e1eb4882
版权归原作者 埃菲尔没有塔尖 所有, 如有侵权,请联系我们删除。