
文章目录

什么是 Spark?
Spark 是一个基于内存的分布式计算框架,最初由加州大学伯克利分校的 AMPLab 开发,后来捐赠给了 Apache 软件基金会。它提供了一个高效、通用、可扩展且易用的大数据处理平台,支持各种类型的应用,包括批处理、实时流处理、机器学习和图处理等。
核心特点
- 快:Spark 使用内存计算来加速数据处理。相比于传统的基于磁盘的数据处理框架(如:MapReduce),Spark 将数据存储在内存中,可以显著减少数据读写的开销,从而加快计算速度。
- 分布式:Spark 可以在多个节点上并行运行,通过将任务分配给集群中的多个计算节点来实现横向扩展,实现任务的并行处理,加速数据处理的速度。它还支持在内存中缓存数据,以加速迭代算法和交互式查询。
- 全面:Spark 提供了统一的编程模型,可以用于批处理、交互式查询、流处理和机器学习等各种类型的任务。这种通用性让开发人员可以在同一个框架下处理各种不同类型的数据处理需求。
- 易用:Spark 提供了丰富的高级API(如 RDD、DataFrame 和 Dataset),以及支持多种编程语言(如 Scala、Java、Python)。
- 生态系统丰富:Spark 生态系统丰富多样,如 Spark SQL(用于结构化数据处理)、Spark Streaming(用于实时数据处理)、MLlib(用于机器学习)、GraphX(用于图处理)等,以及与其他大数据技术的集成,如Hadoop、Hive、Kafka 等。
Spark 对比 MapReduce
处理速度
- Spark 使用内存计算和基于 DAG(Directed Acyclic Graph)的执行计划,在处理迭代算法和交互式查询时通常比 MapReduce 快数倍。
- MapReduce 是基于磁盘读写的模型,在每次任务完成后需要将中间结果写入磁盘,因此速度相对较慢,适用于批处理任务。
编程模型
- Spark 提供了丰富的高级 API,如 RDD、DataFrame 和 Dataset,以及支持多种编程语言,编程模型更灵活,易于使用和学习。
- MapReduce 的编程模型相对简单,主要是 Map 和 Reduce 两个阶段,需要手动处理数据的分割和中间结果的写入。
计算方式
- Spark 支持内存计算,将数据存储在内存中进行处理,以加速数据处理和计算,适用于迭代算法和实时数据处理。
- MapReduce 主要是基于磁盘的计算模型,每次任务都会将中间结果写入磁盘,造成了额外的 IO 开销。
容错性
- Spark 使用 RDD 的血统来记录每个 RDD 的来源和依赖关系,在数据丢失或计算节点失败时可以重新计算丢失的数据分区,保证计算结果的正确性。
- MapReduce 也具有容错性,但是在任务失败时需要重新启动整个任务,造成了额外的开销和时间延迟。
Spark 相对于 MapReduce 具有更快的处理速度、更灵活的编程模型、支持内存计算和更好的容错性等优势,适用于迭代算法、实时数据处理等场景,而 MapReduce 则更适用于传统的批处理任务。
Spark 编程模型
Spark 的编程模型是指开发者用来编写 Spark 应用程序的抽象接口和概念,共有三种核心的编程模型,包括 RDD、DataFrame 和 Dataset。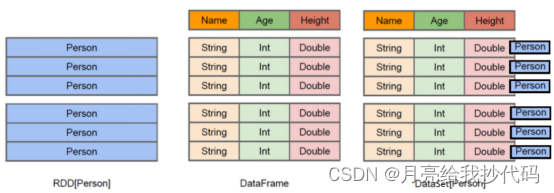
RDD
- RDD 称为弹性分布式数据集,是 Spark 最早引入的数据抽象概念,代表着分布式的只读数据集合。
- RDD 是一个分区的、不可变的、可并行计算的数据集,可以从外部数据源创建,也可以通过在其他 RDD 上进行转换操作生成。
- RDD 提供了一系列的转换操作(如
map、filter、reduceByKey等)和行动操作(如collect、count、saveAsTextFile等),可以进行数据的转换和计算。 - RDD 具有容错性,如果某个分区的数据丢失或出错,Spark 可以根据 RDD 的血统重新计算丢失的数据分区,保证计算结果的正确性。
DataFrame
- DataFrame 是一个分布式的、带有命名列的数据集,类似于关系型数据库中的表。
- DataFrame 提供了结构化的数据处理功能,支持类似 SQL 的查询操作和列操作,如
select、filter、groupBy等。 - DataFrame 是基于 RDD 构建的,但是相比于 RDD,DataFrame 提供了更高层次的抽象,更适合于处理结构化数据。
- DataFrame 可以从多种数据源创建,如文本文件、JSON 文件、Parquet 文件、数据库表等。
Dataset
- Dataset 是 Spark 2.0 引入的新的抽象概念,结合了 RDD 和 DataFrame 的特点,提供了类型安全的分布式数据集。
- Dataset 可以包含任意类型的数据,但是在运行时会将其转换为 JVM 的对象类型。
- Dataset 提供了强类型的 API,可以在编译时进行类型检查,避免了在运行时出现类型错误。
- Dataset 通常用于需要更严格的类型控制和性能优化的场景,如机器学习等。
Spark 运行模式
Spark 可以在多种不同的运行模式下进行部署和执行,包括以下几种常见的模式:
本地模式(local)
- 在本地模式下,Spark 只在单个 JVM 进程中运行,不需要启动集群,适用于开发和测试环境。
- 本地模式通常用于在开发阶段快速验证代码逻辑和功能。
独立部署模式(Standalone)
- 在独立部署模式下,Spark 使用自己的集群管理器启动和管理 Spark 应用程序,无需依赖于其他的集群管理系统。
- 独立部署模式适用于对资源管理有一定需求,但规模不太大的环境。
YARN 模式
- 在 YARN 模式下,Spark 作为 YARN 的一个应用程序运行在 Hadoop 集群上,由 YARN 负责资源管理和作业调度。
- YARN 模式是最常见的 Spark 部署模式之一,可以与 Hadoop 生态系统无缝集成,充分利用 Hadoop 集群的资源。
Mesos 模式
- 在 Mesos 模式下,Spark 作为 Mesos 的一个框架运行在 Mesos 集群上,由 Mesos 负责资源管理和作业调度。
- Mesos 模式也是一种常见的 Spark 部署模式,适用于需要动态资源分配和调度的环境。
Kubernetes 模式
- 在 Kubernetes 模式下,Spark 作为一个 Kubernetes 的应用程序运行在 Kubernetes 集群上,由 Kubernetes 负责资源管理和作业调度。
- Kubernetes 模式是一种新兴的 Spark 部署模式,具有弹性、可伸缩的特点,适用于容器化的环境和微服务架构。
Spark 生态
- Spark Core:Spark Core 是 Spark 生态系统的核心组件,提供了分布式数据集(RDD)、任务调度和执行引擎、内存计算和优化以及容错性和恢复机制等功能,是构建大数据处理应用程序的基础。
- Spark SQL:Spark SQL 是 Spark 提供的用于结构化数据处理和查询的模块,它提供了类似于 SQL 的查询语言和 DataFrame API,可以方便地对结构化数据进行查询、过滤、聚合等操作。
- Spark Streaming:Spark Streaming 是 Spark 提供的用于实时数据处理的模块,它可以将实时数据流分成小批次,并使用 Spark 引擎进行处理,支持复杂的流处理逻辑,如窗口操作、状态管理等。
- MLlib:MLlib 是 Spark 提供的用于机器学习的库,包括常见的机器学习算法和工具,如分类、回归、聚类、推荐等,可以在分布式环境下进行大规模的机器学习任务。
- GraphX:GraphX 是 Spark 提供的用于图计算的库,支持图的创建、转换、遍历和计算,可以用于社交网络分析、推荐系统、网络安全等领域。
- SparkR:SparkR 是 Spark 提供的用于 R 语言的接口,可以在 R 中使用 Spark,利用 Spark 引擎进行大规模数据处理和分析。
- Spark on YARN:Spark 可以在 Hadoop YARN 上运行,利用 YARN 的资源管理和调度功能来管理 Spark 应用程序的资源,实现在 Hadoop 集群上的分布式计算。
除了以上列举的组件外,还有许多其他与 Spark 相关的工具和技术,如 Spark On Hive、Kafka等,都可以用于扩展和增强 Spark 的功能和性能。整个 Spark 生态系统是一个丰富多样、不断发展的生态系统,为用户提供了灵活、强大的大数据处理解决方案。
本文转载自: https://blog.csdn.net/weixin_46389691/article/details/139271446
版权归原作者 月亮给我抄代码 所有, 如有侵权,请联系我们删除。
版权归原作者 月亮给我抄代码 所有, 如有侵权,请联系我们删除。