
React 作为前端使用最多的框架,必然是面试的重点。我们接下来主要从 React 的使用方式、源码层面和周边生态(如 redux, react-router 等)等几个方便来进行总结。
1. 使用方式上
这里主要考察的是,在开发使用过程中,对 React 框架的了解,如 hook 的不同调用方式得到的结果、函数组件中的 useState 和类组件的 state 的区别等等。
props 的变动,是否会引起 state hook 中数据的变动?
React 组件的 props 变动,会让组件重新执行,但并不会引起 state 的值的变动。state 值的变动,只能由 setState() 来触发。因此若想在 props 变动时,重置 state 的数据,需要监听 props 的变动,如:
const App = props => {
const [count, setCount] = useState(0);
// 监听 props 的变化,重置 count 的值
useEffect(() => {
setCount(0);
}, [props]);
return <div onClick={() => setCount(count + 1)}>{count}</div>;
};
React18 有哪些新变化?
React 的更新都是渐进式的更新,在 React18 中启用的新特性,其实在 v17 中(甚至更早)就埋下了。
- 并发渲染机制:根据用户的设备性能和网速对渲染过程进行适当的调整, 保证 React 应用在长时间的渲染过程中依旧保持可交互性,避免页面出现卡顿或无响应的情况,从而提升用户体验。
- 新的创建方式:现在是要先通过
createRoot()创建一个 root 节点,然后该 root 节点来调用render()方法; - 自动批处理优化:批处理: React 将多个状态更新分组到一个重新渲染中以获得更好的性能。(将多次 setstate 事件合并);在 v18 之前只在事件处理函数中实现了批处理,在 v18 中所有更新都将自动批处理,包括 promise 链、setTimeout 等异步代码以及原生事件处理函数;
- startTransition:主动降低优先级。比如「搜索引擎的关键词联想」,用户在输入框中的输入希望是实时的,而联想词汇可以稍稍延迟一会儿。我们可以用 startTransition 来降低联想词汇更新的优先级;
- useId:主要用于 SSR 服务端渲染的场景,方便在服务端渲染和客户端渲染时,产生唯一的 id;
并发模式是如何执行的?
React 中的
并发
,并不是指同一时刻同时在做多件事情。因为 js 本身就是单线程的(同一时间只能执行一件事情),而且还要跟 UI 渲染竞争主线程。若一个很耗时的任务占据了线程,那么后续的执行内容都会被阻塞。为了避免这种情况,React 就利用 fiber 结构和时间切片的机制,将一个大任务分解成多个小任务,然后按照任务的优先级和线程的占用情况,对任务进行调度。
- 对于每个更新,为其分配一个优先级 lane,用于区分其紧急程度。
- 通过 Fiber 结构将不紧急的更新拆分成多段更新,并通过宏任务的方式将其合理分配到浏览器的帧当中。这样就能使得紧急任务能够插入进来。
- 高优先级的更新会打断低优先级的更新,等高优先级更新完成后,再开始低优先级更新。
什么是受控组件和非受控组件?
我们稍微了解下什么是受控组件和非受控组件:
- 受控组件:只能通过 React 修改数据或状态的组件,就是受控组件;
- 非受控组件:与受控组件相反,如 input, textarea, select, checkbox 等组件,本身控件自己就能控制数据和状态的变更,而且 React 是不知道这些变更的;
那么如何将非受控组件改为受控组件呢?那就是把上面的这些纯 html 组件数据或状态的变更,交给 React 来操作:
const App = () => {
const [value, setValue] = useState('');
const [checked, setChecked] = useState(false);
return (
<>
<input value={value} onInput={event => setValue(event.target.value)} />
<input type="checkbox" checked={checked} onChange={event => setChecked(event.target.checked)} />
</>
);
};
上面代码中,输入框和 checkbox 的变化,均是经过了 React 来操作的,在数据变更时,React 是能够知道的。
高阶组件(HOC)?
高阶组件?
高阶组件通过包裹(wrapped)被传入的 React 组件,经过一系列处理,最终返回一个相对增强(enhanced)的 React 组件,供其他组件调用。
作用:
- 复用逻辑:高阶组件更像是一个加工 react 组件的工厂,批量对原有组件进行加工,包装处理。我们可以根据业务需求定制化专属的 HOC,这样可以解决复用逻辑。
- 强化 props:这个是 HOC 最常用的用法之一,高阶组件返回的组件,可以劫持上一层传过来的 props,然后混入新的 props,来增强组件的功能。代表作 react-router 中的 withRouter。
- 赋能组件:HOC 有一项独特的特性,就是可以给被 HOC 包裹的业务组件,提供一些拓展功能,比如说额外的生命周期,额外的事件,但是这种 HOC,可能需要和业务组件紧密结合。典型案例 react-keepalive-router 中的 keepaliveLifeCycle 就是通过 HOC 方式,给业务组件增加了额外的生命周期。
- 控制渲染:劫持渲染是 hoc 一个特性,在 wrapComponent 包装组件中,可以对原来的组件,进行条件渲染,节流渲染,懒加载等功能,后面会详细讲解,典型代表做 react-redux 中 connect 和 dva 中 dynamic 组件懒加载。
参考:react 进阶」一文吃透 React 高阶组件(HOC)
React 中为什么要使用 Hook?
官方网站有介绍该原因:使用 Hook 的动机。
这里我们简要的提炼下:
- 在组件之间复用状态逻辑很难:在类组件中,可能需要 render props 和 高阶组件等方式,但会形成“嵌套地域”;而使用 Hook,则可以从组件中提取状态逻辑,是的这些逻辑可以单独测试并复用;
- 复杂组件变得难以理解:在类组件中,每个生命周期常常包含一些不相关的逻辑。如不同的执行逻辑,都要放在
componentDidMount中执行和获取数据,而之后需在componentWillUnmount中清除;但在函数组件中,不同的逻辑可以放在不同的 Hook 中执行,互不干扰; - 难以理解的 class:类组件中,充斥着各种对
this的使用,如this.onClick.bind(this),this.state,this.setState()等,同时,class 不能很好的压缩,并且会使热重载出现不稳定的情况;Hook 使你在非 class 的情况下可以使用更多的 React 特性;
useCallback 和 useMemo 的使用场景
useCallback 和 useMemo 可以用来缓存函数和变量,提高性能,减少资源浪费。但并不是所有的函数和变量都需要用这两者来实现,他也有对应的使用场景。
我们知道 useCallback 可以缓存函数体,在依赖项没有变化时,前后两次渲染时,使用的函数体是一样的。它的使用场景是:
- 函数作为其他 hook 的依赖项时(如在 useEffect()中);
- 函数作为 React.memo()(或 shouldComponentUpdate )中的组件的 props;
主要是为了避免重新生成的函数,会导致其他 hook 或组件的不必要刷新。
useMemo 用来缓存函数执行的结果。如每次渲染时都要执行一段很复杂的运算,或者一个变量需要依赖另一个变量的运算结果,就都可以使用 useMemo()。
参考文章:React18 源码解析之 useCallback 和 useMemo。
useState 的传参方式,有什么区别?
useState()的传参有两种方式:纯数据和回调函数。这两者在初始化时,除了传入方式不同,没啥区别。但在调用时,不同的调用方式和所在环境,输出的结果也是不一样的。
如:
const App = () => {
const [count, setCount] = useState(0);
const handleParamClick = () => {
setCount(count + 1);
setCount(count + 1);
setCount(count + 1);
};
const handleCbClick = () => {
setCount(count => count + 1);
setCount(count => count + 1);
setCount(count => count + 1);
};
};
上面的两种传入方式,最后得到的 count 结果是不一样的。为什么呢?因为在以数据的格式传参时,这 3 个使用的是同一个 count 变量,数值是一样的。相当于
setCount(0 + 1)
,调用了 3 次;但以回调函数的传参方式,React 则一般地会直接该回调函数,然后得到最新结果并存储到 React 内部,下次使用时就是最新的了。注意:这个最新值是保存在 React 内部的,外部的 count 并不会马上更新,只有在下次渲染后才会更新。
还有,在定时器中,两者得到的结果也是不一样的:
const App = () => {
const [count, setCount] = useState(0);
useEffect(() => {
const timer = setInterval(() => {
setCount(count + 1);
}, 500);
return () => clearInterval(timer);
}, []);
useEffect(() => {
const timer = setInterval(() => {
setCount(count => count + 1);
}, 500);
return () => clearInterval(timer);
}, []);
};
为什么在本地开发时,组件会渲染两次?
issues#2
在 React.StrictMode 模式下,如果用了 useState,usesMemo,useReducer 之类的 Hook,React 会故意渲染两次,为的就是将一些不容易发现的错误容易暴露出来,同时 React.StrictMode 在正式环境中不会重复渲染。
也就是在测试环境的严格模式下,才会渲染两次。
如何实现组件的懒加载
从 16.6.0 开始,React 提供了 lazy 和 Suspense 来实现懒加载。
import React, { lazy, Suspense } from 'react';
const OtherComponent = lazy(() => import('./OtherComponent'));
function MyComponent() {
return (
<Suspense fallback={<div>Loading...</div>}>
<OtherComponent />
</Suspense>
);
}
属性
fallback
表示在加载组件前,渲染的内容。
如何实现一个定时器的 hook
若在定时器内直接使用 React 的代码,可能会收到意想不到的结果。如我们想实现一个每 1 秒加 1 的定时器:
const App = () => {
const [count, setCount] = useState(0);
useEffect(() => {
const timer = setInterval(() => {
setCount(count + 1);
}, 1000);
return () => clearInterval(timer);
}, []);
return <div className="App">{count}</div>;
};
可以看到,coun 从 0 变成 1 以后,就再也不变了。为什么会这样?
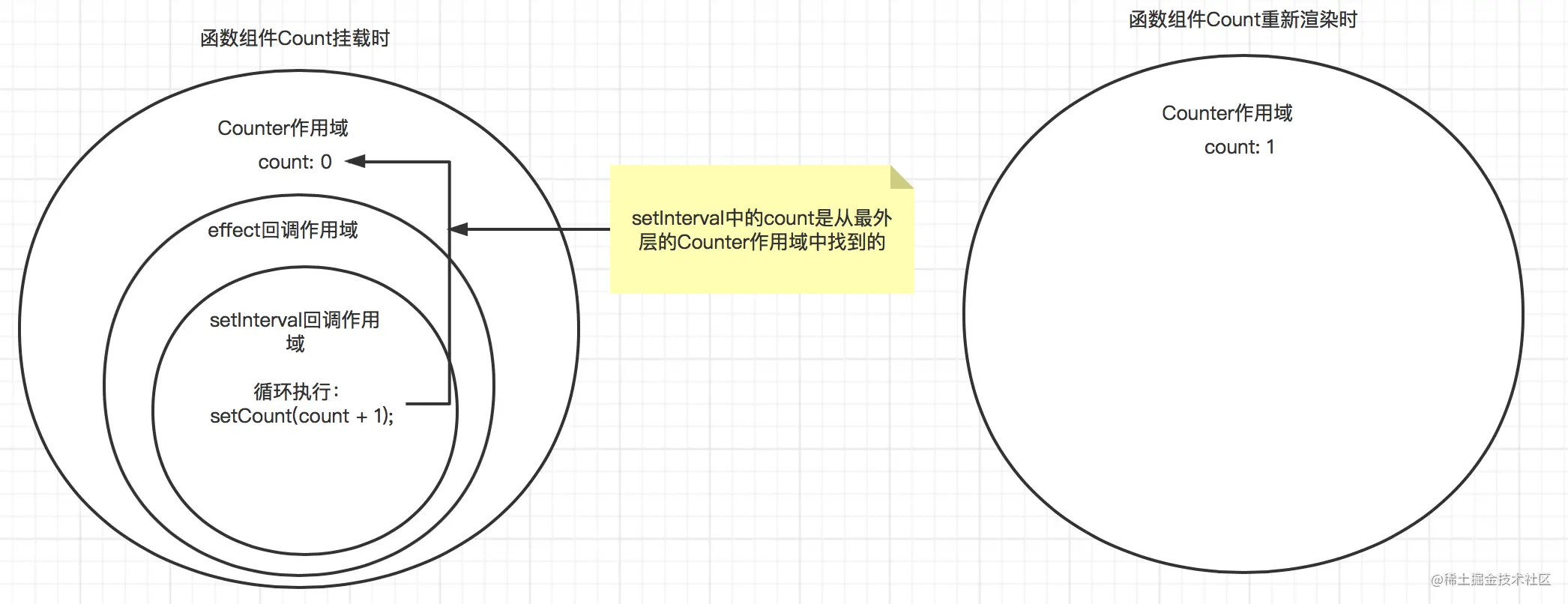
尽管由于定时器的存在,组件始终会一直重新渲染,但定时器的回调函数是挂载期间定义的,所以它的闭包永远是对挂载时 Counter 作用域的引用,故 count 永远不会超过 1。
针对这个单一的 hook 调用,还比较好解决,例如可以监听 count 的变化,或者通过 useState 的 callback 传参方式。
const App = () => {
const [count, setCount] = useState(0);
// 监听 count 的变化,不过这里将定时器改成了 setTimeout
// 即使不修改,setInterval()的timer也会在每次渲染时被清除掉,
// 然后重新启动一个新的定时器
useEffect(() => {
const timer = setTimeout(() => {
setCount(count + 1);
}, 1000);
return () => clearInterval(timer);
}, [count]);
// 以回调的方式
// 回调的方式,会计算回调的结果,然后作为下次更新的初始值
// 详情可见: https://www.xiabingbao.com/post/react/react-usestate-rn5bc0.html#5.+updateReducer
useEffect(() => {
const timer = setInterval(() => {
setCount(count => count + 1);
}, 1000);
return () => clearInterval(timer);
}, []);
return <div className="App">{count}</div>;
};
当然还有别的方式也可以实现 count 的更新。那要是调用更多的 hook,或者更复杂的代码,该怎么办呢?这里我们可以封装一个新的 hook 来使用:
// https://overreacted.io/zh-hans/making-setinterval-declarative-with-react-hooks/
const useInterval = (callback: () => void, delay: number | null): void => {
const savedCallback = useRef(callback);
useEffect(() => {
savedCallback.current = callback;
});
useEffect(() => {
function tick() {
savedCallback.current();
}
if (delay !== null) {
const id = setInterval(tick, delay);
return () => clearInterval(id);
}
}, [delay]);
};
useEffect()的清除机制是什么?在什么时候执行?
useEffect(callback)的回调函数里,若有返回的函数,这是 effect 可选的清除机制。每个 effect 都可以返回一个清除函数。
React 何时清除 effect? React 会在组件卸载的时候执行清除操作。同时,若组件产生了更新,会先执行上一个的清除函数,然后再运行下一个 effect。如
// 运行第一个 effect
// 产生更新时
// 清除上一个 effect
// 运行下一个 effect
// 产生更新时
// 清除上一个 effect
// 运行下一个 effect
// 组件卸载时
// 清除最后一个 effect
参考:为什么每次更新的时候都要运行 Effect
2. 源码层面上
这部分考察的就更有深度一些了,多多少少得了解一些源码,才能明白其中的缘由,比如 React 的 diff 对比,循环中 key 的作用等。
虚拟 dom 有什么优点?真实 dom 和虚拟 dom,谁快?
Virtual DOM 是以对象的方式来描述真实 dom 对象的,那么在做一些 update 的时候,可以在内存中进行数据比对,减少对真实 dom 的操作减少浏览器重排重绘的次数,减少浏览器的压力,提高程序的性能,并且因为 diff 算法的差异比较,记录了差异部分,那么在开发中就会帮助程序员减少对差异部分心智负担,提高了开发效率。
虚拟 dom 好多这么多,渲染速度上是不是比直接操作真实 dom 快呢?并不是。虚拟 dom 增加了一层内存运算,然后才操作真实 dom,将数据渲染到页面上。渲染上肯定会慢上一些。虽然虚拟 dom 的缺点在初始化时增加了内存运算,增加了首页的渲染时间,但是运算时间是以毫秒级别或微秒级别算出的,对用户体验影响并不是很大。
什么是合成事件,与原生事件有什么区别?
React 中所有触发的事件,都是自己在其内部封装了一套事件机制。目的是为了实现全浏览器的一致性,抹平不同浏览器之间的差异性。
在 React17 之前,React 是把事件委托在 document 上的,React17 及以后版本不再把事件委托在 document 上,而是委托在挂载的容器上。React 合成事件采用的是事件冒泡机制,当在某具体元素上触发事件时,等冒泡到顶部被挂载事件的那个元素时,才会真正地执行事件。
而原生事件,当某具体元素触发事件时,会立刻执行该事件。因此若要比较事件触发的先后时机时,原生事件会先执行,React 合成事件会后执行。
key 的作用是什么?
key 帮助 React 识别哪些元素改变了,比如被添加或删除。因此你应当给数组中的每一个元素赋予一个确定的标识。
当组件刷新时,React 内部会根据 key 和元素的 type,来对比元素是否发生了变化。若选做 key 的数据有问题,可能会在更新的过程中产生异常。
参考:React18 源码解析之 key 的作用。
多次执行 useState(),会触发多次更新吗?
在 React18 中,无论是多个 useState()的 hook,还是操作(dispatch)多次的数据。只要他们在同一优先级,React 就会将他们合并到一起操作,最后再更新数据。
这是基于 React18 的批处理机制。React 将多个状态更新分组到一个重新渲染中以获得更好的性能。(将多次 setstate 事件合并);在 v18 之前只在事件处理函数中实现了批处理,在 v18 中所有更新都将自动批处理,包括 promise 链、setTimeout 等异步代码以及原生事件处理函数;
参考:多次调用 useState() 中的 dispatch 方法,会产生多次渲染吗?
useState()的 state 是否可以直接修改?是否可以引起组件渲染?
首先声明,我们不应当直接修改 state 的值,一方面是无法刷新组件(无法将新数据渲染到页面中),再有可能会对下次的更新产生影响。
唯一有影响的,就是后续要使用该变量的地方,会使用到新数据。但若其他 useState() 导致了组件的刷新,刚才变量的值,若是基本类型(比如数字、字符串等),会重置为修改之前的值;若是复杂类型,基于 js 的 对象引用 特性,也会同步修改 React 内部存储的数据,但不会引起视图的变化。
参考:直接修改 state 的值,会怎样?
React 的 diff 过程
- React 只对比当前层级的节点,不跨层级进行比较;
- 根据不同的节点类型,如函数组件节点、类组件节点、普通 fiber 节点、数组节点等,进入不同的处理函数;
- 前后两个 fiber 节点进行对比,若 type 不一样,直接舍弃掉旧的 fiber 节点,创建新的 fiber 节点;若 key 不一样,则需要根据情况判断,若是单个元素,则直接舍弃掉,创建新的 fiber 节点;若是数字型的元素,则查找是否移动了位置,若没找到,则创建新的节点;若 key 和 type 都一样,则接着往下递归;
- 若是单个 fiber 节点,则直接返回;若是并列多个元素的 fiber 节点,这里会形成单向链表,然后返回头指针(该链表最前面的那个 fiber 节点);
通过上面的 diff 对比过程,我们也可以看到,当组件产生比较大的变更时,React 需要做更多的动作,来构建出新的 fiber 树,因此我们在开发过程中,若从性能优化的角度考虑,尤其要注意的是:
- 节点不要产生大量的越级操作:因为 React 是只进行同层节点的对比,若同一个位置的子节点产生了比较大的变动,则只会舍弃掉之前的 fiber 节点,从而执行创建新 fiber 节点的操作;React 并不会把之前的 fiber 节点移动到另一个位置;相应的,之前的 jsx 节点移动到另一个位置后,在进行前后对比后,同样会执行更多的创建操作;
- 不修改节点的 key 和 type 类型,如使用随机数做为列表的 key,或从 div 标签改成 p 标签等操作,在 diff 对比过程中,都会直接舍弃掉之前的 fiber 节点及所有的子节点(即使子节点没有变动),然后重新创建出新的 fiber 节点;
参考:React18 源码解析之 reconcileChildren 生成 fiber 的过程
基于 React 框架的特点,可以有哪些优化措施?
- 使用 React.lazy 和 Suspense 将页面设置为懒加载,避免 js 文件过大;
- 使用 SSR 同构直出技术,提高首屏的渲染速度;
- 使用 useCallback 和 useMemo 缓存函数或变量;使用 React.memo 缓存组件;
- 尽量调整样式或 className 的变动,减少 jsx 元素上的变动,尽量使用与元素相关的字段作为 key,可以减少 diff 的时间(React 会尽量复用之前的节点,若 jsx 元素发生变动,就需要重新创建节点);
- 对于不需要产生页面变动的数据,可以放到 useRef()中;
React.Children.map 和 js 的 map 有什么区别?
JavaScript 中的 map 不会对为 null 或者 undefined 的数据进行处理,而 React.Children.map 中的 map 可以处理 React.Children 为 null 或者 undefined 的情况。
3. 周边生态
这部分主要考察 React 周边生态配套的了解,如状态管理库 redux、mobx,路由组件 react-router-dom 等。
react-router 和 react-router-dom 的有什么区别?
api 方面
React-router: 提供了路由的核心 api。如 Router、Route、Switch 等,但没有提供有关 dom 操作进行路由跳转的 api;
React-router-dom: 提供了 BrowserRouter、Route、Link 等 api,可以通过 dom 操作触发事件控制路由。
Link 组件,会渲染一个 a 标签;BrowserRouter 和 HashRouter 组件,前者使用 pushState 和 popState 事件构建路由,后者使用 hash 和 hashchange 事件构建路由。
使用区别
react-router-dom 在 react-router 的基础上扩展了可操作 dom 的 api。 Swtich 和 Route 都是从 react-router 中导入了相应的组件并重新导出,没做什么特殊处理。
react-router-dom 中 package.json 依赖中存在对 react-router 的依赖,故此,不需要额外安装 react-router。
Redux 遵循的三个原则是什么?
- 单一事实来源:整个应用的状态存储在单个 store 中的对象/状态树里。单一状态树可以更容易地跟踪随时间的变化,并调试或检查应用程序。
- 状态是只读的:改变状态的唯一方法是去触发一个动作。动作是描述变化的普通 JS 对象。就像 state 是数据的最小表示一样,该操作是对数据更改的最小表示。
- 使用纯函数进行更改:为了指定状态树如何通过操作进行转换,你需要纯函数。纯函数是那些返回值仅取决于其参数值的函数。
你对“单一事实来源”有什么理解?
Redux 使用 “Store” 将程序的整个状态存储在同一个地方。因此所有组件的状态都存储在 Store 中,并且它们从 Store 本身接收更新。单一状态树可以更容易地跟踪随时间的变化,并调试或检查程序。
Redux 有哪些优点?
Redux 的优点如下:
- 结果的可预测性 - 由于总是存在一个真实来源,即 store ,因此不存在如何将当前状态与动作和应用的其他部分同步的问题。
- 可维护性 - 代码变得更容易维护,具有可预测的结果和严格的结构。
- 服务器端渲染 - 你只需将服务器上创建的 store 传到客户端即可。这对初始渲染非常有用,并且可以优化应用性能,从而提供更好的用户体验。
- 开发人员工具 - 从操作到状态更改,开发人员可以实时跟踪应用中发生的所有事情。
- 社区和生态系统 - Redux 背后有一个巨大的社区,这使得它更加迷人。一个由才华横溢的人组成的大型社区为库的改进做出了贡献,并开发了各种应用。
- 易于测试 - Redux 的代码主要是小巧、纯粹和独立的功能。这使代码可测试且独立。
- 组织 - Redux 准确地说明了代码的组织方式,这使得代码在团队使用时更加一致和简单。
4. 总结
React 涉及到的相关知识点非常多,我也会经常更新的。
版权归原作者 LinkSLA 所有, 如有侵权,请联系我们删除。