
文章目录
前言
需求背景是java代码提交服务器测试周期流程太慢,需要一种能直接在windows本地部署的相关组件。分析项目现有大数据技术栈,包括hadoop、hive和spark(sparksql),存储和计算都依赖windows系统。期中hive保存在本地的hadoop上,spark提交在hadoop的yarn上。
· hadoop on windows
· hive on windows
· spark on windows(提交方式是spark on yarn)
注意事项:
在spark官网选择spark版本的时候确定对应支持的hadoop版本,然后选择对应hadoop的winutils-master的版本。
Spark下载路径:https://spark.apache.org/downloads.html
Hadoop下载路径:https://archive.apache.org/dist/hadoop/common/
Scala下载路径:https://www.scala-lang.org/download/all.html
Winutils-master下载路径:https://github.com/cdarlint/winutils
1. hadoop on windows
1.1 安装jdk
jdk安装省略了
Win+R输入cmd,再键入java -version,确认jdk安装是否成功
1.2 安装hadoop
1.2.1 解压
解压下载的包到一个无中文无空格的路径下
1.2.2 备用目录
新建一个无中文无空格的文件夹,作为hadoop的namenode地址和datanode地址
1.2.3 修改配置
分别修改解压包下~\etc\hadoop的相关配置文件
- hdfs-site.xml
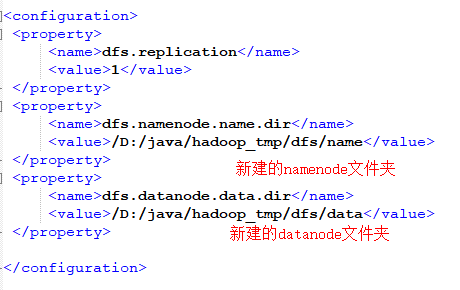
- yan-site.xml

- mapred-site.xml

- core-site.xml

- hadoop-env.cmd
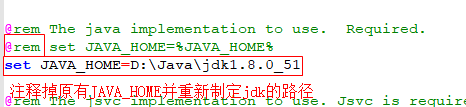
1.2.4 安装winutils-master
解压winutils-master包,找到对应hadoop依赖版本的并进入bin目录将这个文件夹里面的文件整体复制到hadoop的安装路径~/bin下
1.2.5 格式化namenode
以管理员启动cmd.exe,键入hdfs namenode -formet,再确认Y
1.2.6 启动hadoop
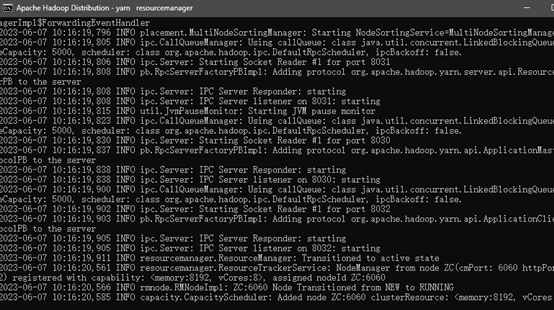
以管理员启动cmd.exe,进入到hadoop加压路径~/sbin,执行start-all,当再弹出四个窗口并无报错的时候即启动成功
- namenode
- datanode
- nodemanager
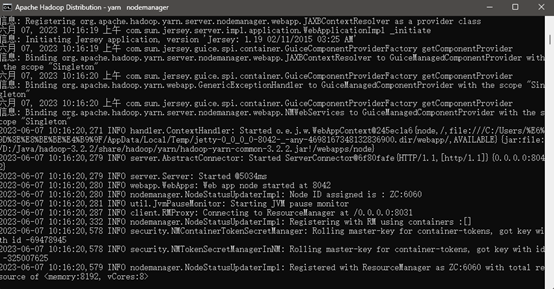
- resourcemanager
1.2.7 web-ui登陆hadoop hdfs
我安装的是3.0版本的hadoop,所以登陆页面是https://localhost:9870,如果是2.0版本的hadoop,登陆页面是https://localhost:50070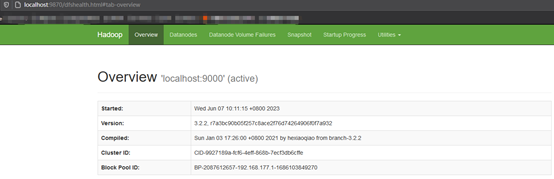
2. spark on windows
2.1 安装scala
spark是scala语言开发的,依赖语言环境。类似于安装jdk,Win+R输入cmd,再键入scala -version,确认scala安装是否成功
2.2 安装spark
2.2.1 解压
解压spark安装包到一个无中文无空格的路径下
2.2.2 环境变量
配置spark环境变量,类似于配置jdk变量。需要配置SPARK_HOME和Path
SPARK_HOME=spark解压安装路径
Path新增一个%SPARK_HOME%\bin
2.2.3 spark配置
修改spark-env.sh添加以下配置,这一步修改的意义是为了让spark的提交走hadoop的yarn
YARN_CONF_DIR=hadoop安装路径/etc/hadoop
2.3 启动spark-shell
执行spark-shell启动
2.4 登陆web-ui
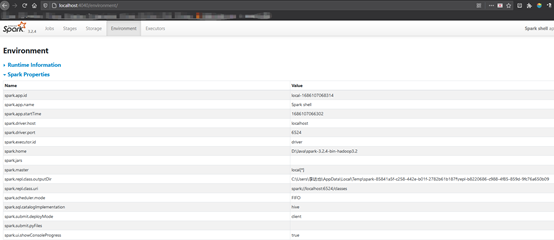
3. hive on windows
hive on windows 需要安装本地化mysql 忒麻烦了。但是hive on windows 其实很好实现,这里就偷个懒省略了。
版权归原作者 陈舟的舟 所有, 如有侵权,请联系我们删除。