
注:本文已首发于PowerData公众号!
1 Spark Shuffle 是什么?
Shuffle 中文意思是“洗牌,混洗”,而在 Hadoop 的 MapReduce 框架中,Shuffle 是 Map 和 Reduce 中间必不可少的连接桥梁。数据在从Map 阶段结束经过 Shuffle 到 Reduce 阶段的过程中,涉及到磁盘的读写、网络传输和数据序列化,Shuffle 操作还会在磁盘上生成大量中间
文件,这些都是直接影响程序的性能的,因此,Shuffle 过程的性能高低能够直接影响整个程序的性能高低。
Spark 使用 Hadoop 的 MapReduce 分布式计算框架作为基础,自然也是实现了 Shuffle 的逻辑,而且还进行了优化改进。 Spark Shuffle 的发展时间线如下:
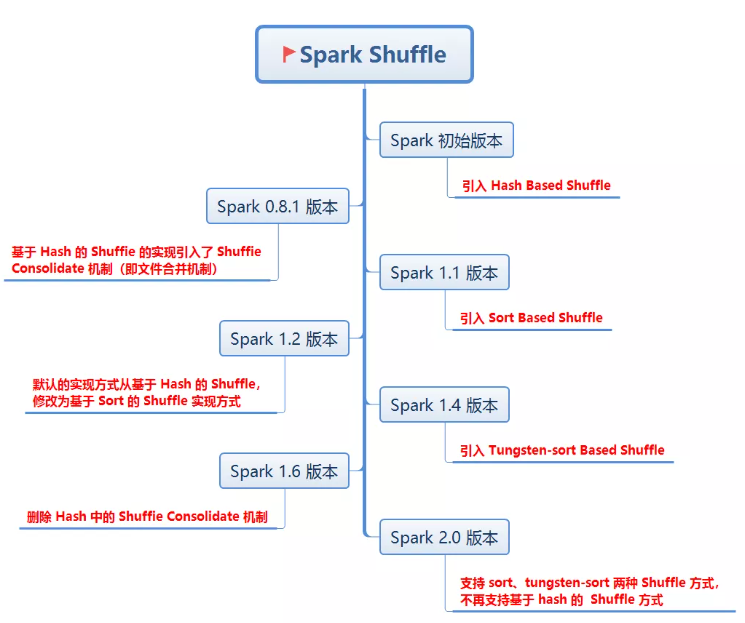
2 为什么会产生 Shuffle
2.1 产生Shuffle的过程
要了解 Shuffle 的产生,首先我们得知道什么是 RDD 的依赖关系。RDDs 通过操作算子进行转换,转换得到的新 RDD 包含了从其他 RDDs衍生所必需的信息,RDDs 之间维护着这种血缘关系(lineage),也称之为依赖。依赖包括两种:窄依赖和宽依赖。
- 窄依赖:父 RDD 的一个分区只会被子 RDD 的一个分区依赖,即 RDDs 之间分区是一一对应的(1:1 或 n:1)
- 宽依赖:子 RDD 每个分区与父 RDD 的每个分区都有关,是多对多的关系(即 n:m)
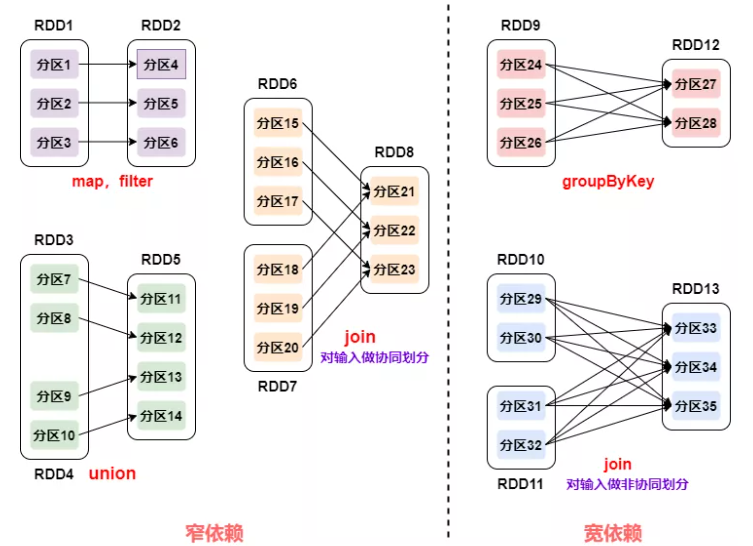
从上图我们可以看出,在窄依赖的过程中,并不会出现原本同属于父 RDD 同一个分区的数据分散到子 RDD 的不同分区,因此而不会产生Shuffle。相反,宽依赖的过程属于是多对多的情况,自然会产生 Shuffle。
2.2 没有Shuffle行不行
首先明确一下,没有Shuffle是不行的。计算过程之所以需要 Shuffle,往往是由计算逻辑、或者说业务逻辑决定的,比如在 Word Count 的例子中,我们的“业务逻辑”是对单词做统计计数,那么对单词“Spark”来说,在做“加和”之前,我们就是得把原本分散在不同 Executors 中的“Spark”,拉取到某一个 Executor,才能完成统计计数的操作。因此,Spark 在做分布式计算的过程中,没有Shuffle就没办法去完成一些聚合计算。
3 Shuffle 包括什么?
Spark 的 Shuffle 包括 Shuffle 写操作和 Shuffle 读操作两类操作。下面将对这两类操作进行详细介绍。
3.1 Shuffle 写操作
Spark 的 Shuffle 相对于 Hadoop 阶段的 Shuffle 进行了一些改动,比如为了避免 Hadoop 多余的排序操作(Reduce 之前按获取的数据需要经过排序),提出了基于哈希的 Shuffle 操作:Hash Shuffle。不过这种方式也有问题,即当 Map 和 Reduce 数量较多的情况下会导致写文件数量大和缓存开销过大,因此,在此基础上,Spark1.2 版本对 Shuffle 又进行了改进,提出了基于排序的 Shuffle 操作:Sort Shuffle。
3.1.1 Hash Shuffle
使用历程
Spark1.1 版本之前,它是 Spark 唯一的 Shuffle 方式,Spark 版本后,默认将 Shuffle 方式为了 Sort Shuffle,在之后的 Spark2.0 中,Hashshuffle 被弃用。
产生原因:
Hadoop 中 Reduce 所处理的很多数据是需要经过排序的,但是实际的数据处理过程中,很多场景并不会对数据进行排序,因此省去外部排序,从而产生了 Hash Shuffle。
其处理流程如下图:

在该机制中每个Mapper会根据Reduce的数量创建出相应的bucket,bucket的数据是M * R,其中M是Map 的个数,R是Reduce的个数;Mapper生成的结果会根据设置的Partition算法填充到每个bucket中。这里的bucket是一个抽象的概念,在该机制中每个bucket对应一个文件:当Reduce启动时,会根据任务的编号和所依赖的Mapper的编号从远端或者是本地取得相应的bucket作为Reduce任务的输入进行处理。
该机制的优缺点:
- 优点:MapReduce中sort作为固定步骤,有许多任务不需要排序,hashShuffle避免不必要的排序所导致不必要的排序和内存开销,提升 了性能。
- 缺点:缺点:每个mapTask都会为reduceTask生成一个文件, 会生成M*R个中间文件。数据量越来越多时,产生的文件量是不可控的,严重制约了Spark的性能及扩展能力。
3.1.2 Sort Shuffle
使用历程
Spark1.1版本的时候引入,Spark1.2版本之后,默认使用Sort Shuffle,Spark1.4版本引入钨丝机制
产生原因:
Hash Shuffle采用了文件合并机制后,中间结果文件依旧依赖Reduce的Task个数,文件数仍不可控,其缓存所占用的内存也是一笔不小的开销。为了解决这个问题Spark引入了Shuffle写操作机制。
其处理流程如下图:
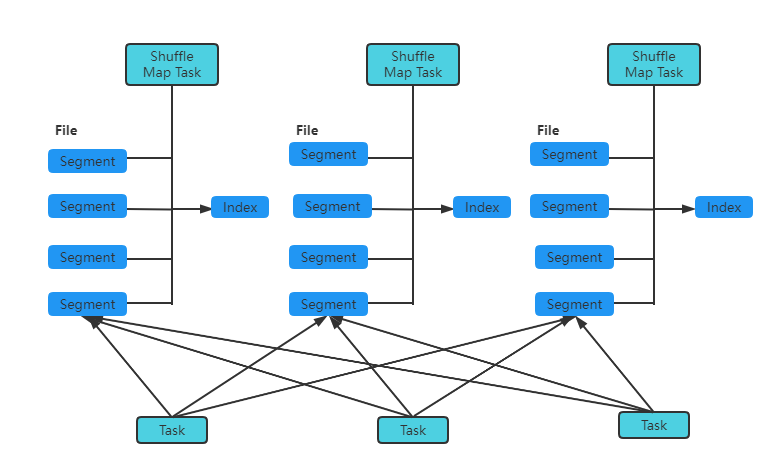
在该机制中,需要先判断Shuffle MapTask输出结果在Map端是否需要合并(Combine),如果需要合并,则外部排序中进行聚合并排序;如果不需要,则外部排序中不;进行聚合和排序,例如sortByKey操作在Reduce端会进行聚合并排序。确认外部排序方式后,在外部排序中将使用PartitionedAppendOnlyMap来存放数据,当排序中的Map占用的内存已经.超越了使用的阈值,则将Map中的内容溢写到磁盘中,每一次溢写产生一个不同的文件。当所有数据处理完毕后,在外部排序中有可能一部分计算结果在内存中,另一部分计算结果溢写到一或多个文件之中,这时通过merge操作将内存和spill文件中的内容合并整到一个文件里。
该机制的优缺点:
- 优点:mapTask不会为每个reduceTask生成一个单独的文件,而是全部写到一个数据文件中,同时生成一一个索引文件,reduceTask可以通过索引文件获取相关数据。
- 缺点:强制要求数据在map端进行排序,导致大量CPU开销。
3.2 Shuffle 读操作
有Shuffle的写操作,自然也就要说一说Shuffle的读操作。相对于Shuffle的写操作,其读操作还是要简单一点的,虽然Shuffle的写操作有不同方式,但是Spark对此采用了相同的读取方式,直接将读取的数据放在哈希列表中方便后续的处理。
其读操作流程如下图:
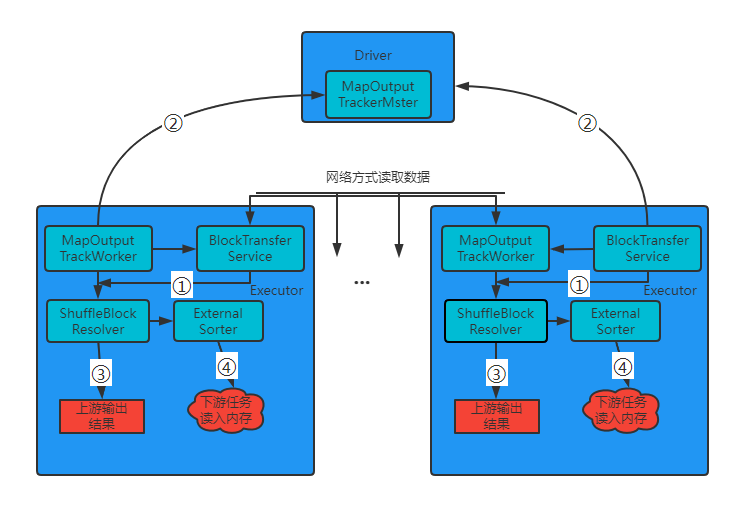
该流程的实现如下:
- ①由Executor 的MapOutputTracker发送获取结果状态消息给Driver端的MapOutputTrackerMaster
- ②然后请求获取上游Shuffle输出结果对应的MapStatus(在该MapStatus存放了结果数据的位置信息);
- ③得到上游Shuffle结果的位置信息后,对这些位置进行筛选,判断当前运行的数据是从本地还是从远程节点获取。
- ④如果是本地获取,直接调用BlockManager的getBlockData 方法,在读取数据的时候会根据写入方式采取不同ShuffleBlockResolver读取;如果是在远程节点上,需要通过Netty网络方式读取数据,在远程读取的过程中使用多线程的方式进行读取。
4 Shuffle怎么用?
关于Shuffle的使用,体现在Spark 计算过程中,出现跨节点进行数据分发的数据聚合的场景,本文以最简单的wordcount进行举例。
4.1 需求说明
统计在给定的文本文件中输出每一个单词出现的总次数
4.2 代码实现
1 编写Mapper类
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
//map阶段
/*
* KEYIN 输入数据的key
* VALUEIN 输入数据的value
* KEYOUT 输出数据的key的类型
* VALUEOUT 输出数据的value类型
*/
public class WordcountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
Text k = new Text();
IntWritable v = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
//获取1行
String line = value.toString();
//切割单词
String[] words = line.split(" ");
//循环写出
for (String word : words) {
k.set(word);
context.write(k, v);
}
}
}
2 编写Reducer类
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordcountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
IntWritable v = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
int sum = 0;
//累加求和
for (IntWritable value : values) {
sum += value.get();
}
v.set(sum);
//写出
context.write(key, v);
}
}
3 编写Driver类
import java.io.File;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordcountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 输入输出路径需要根据自己电脑上实际的输入输出路径设置
args = new String[] { "自己的输入路径", "自己的输出路径" };
Configuration conf = new Configuration();
//获取Job对象
Job job = Job.getInstance(conf);
//设置jar存储位置
job.setJarByClass(WordcountDriver.class);
//关联Map和Reduce类
job.setMapperClass(WordcountMapper.class);
job.setReducerClass(WordcountReducer.class);
//设置Mapper阶段输出数据key和value类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//设置最终数据输出的key和value类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// job.setCombinerClass(WordcountReducer.class);
//设置输入路径和输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//提交Job
// job.submit();
boolean result = job.waitForCompletion(true);
System.out.println(result? 0 : 1);
}
}
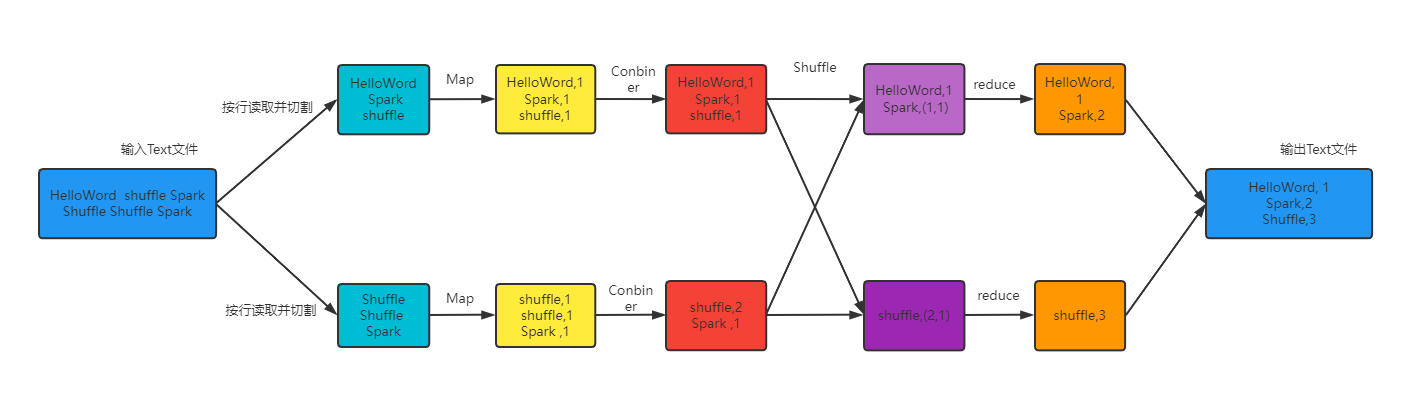
4.3 执行过程图
下图是上述代码的流程图,其中体现了Shuffle的使用过程。
版权归原作者 Faith_xzc 所有, 如有侵权,请联系我们删除。