
教你用python实现34行代码爬取东方财富网信息,爬虫之路,永无止境!!
代码展示:
开发环境:
windows10
python3.6
开发工具:
pycharm
weddriver
库:
selenium、lxml、openpyxl、time
安装webdriver
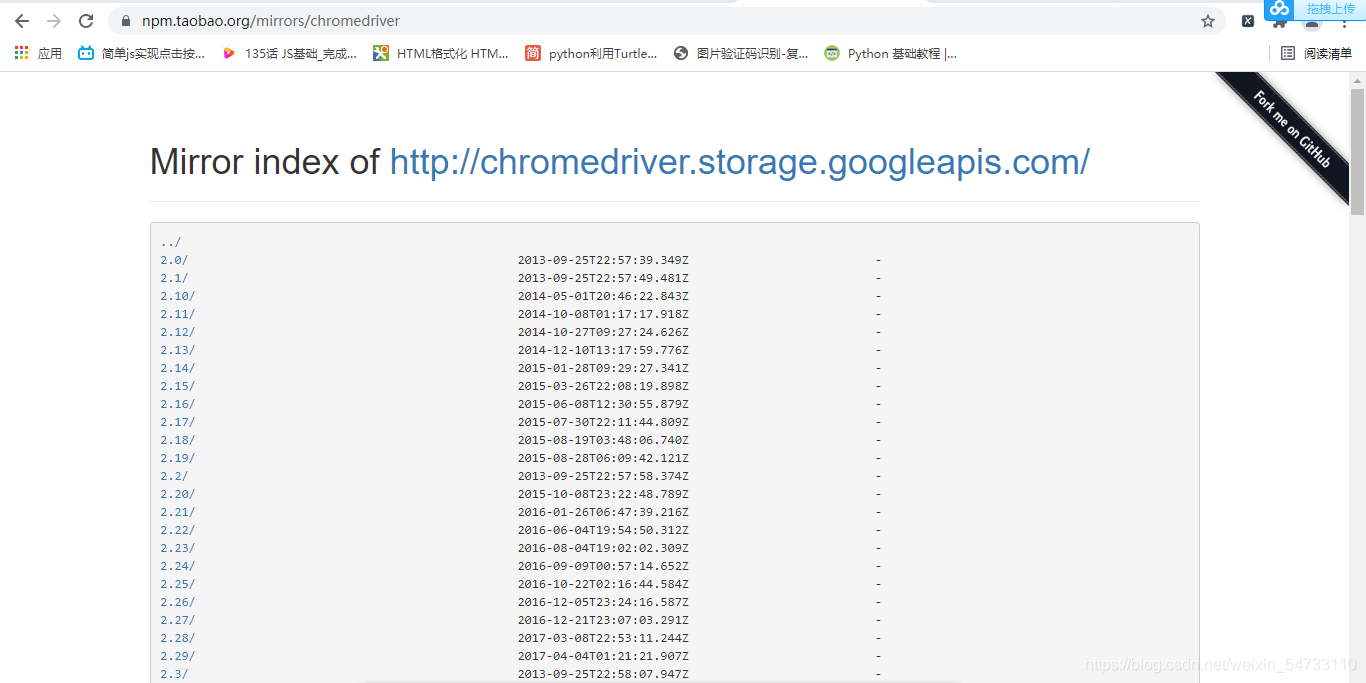
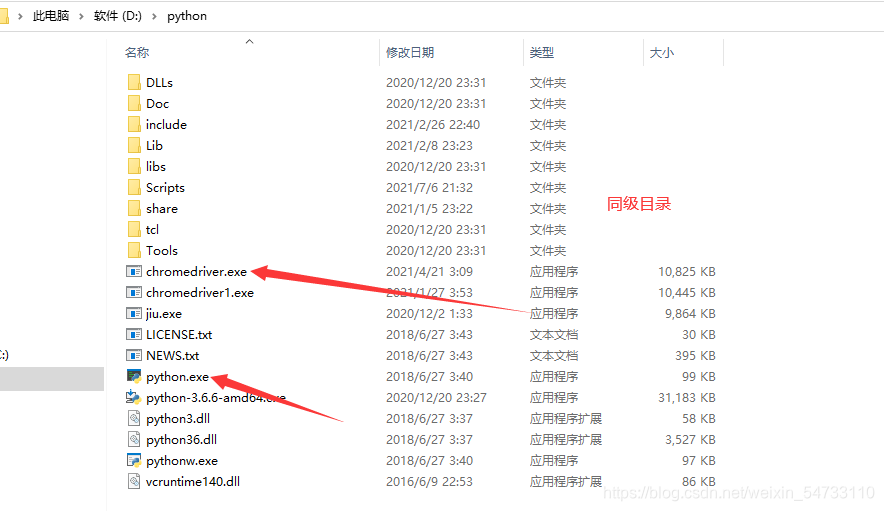
首先要安装webdriver插件,本文以谷歌浏览器为例,点开谷歌浏览器,点击右上角三个点,然后点击帮助,然后点击关于Google Chrome,查看浏览器的版本,然后点击网址http://npm.taobao.org/mirrors/chromedriver寻找自己浏览器对应的版本进行下载,下载之后将chromedriver.exe的文件最好放在你python解释器的同级目录下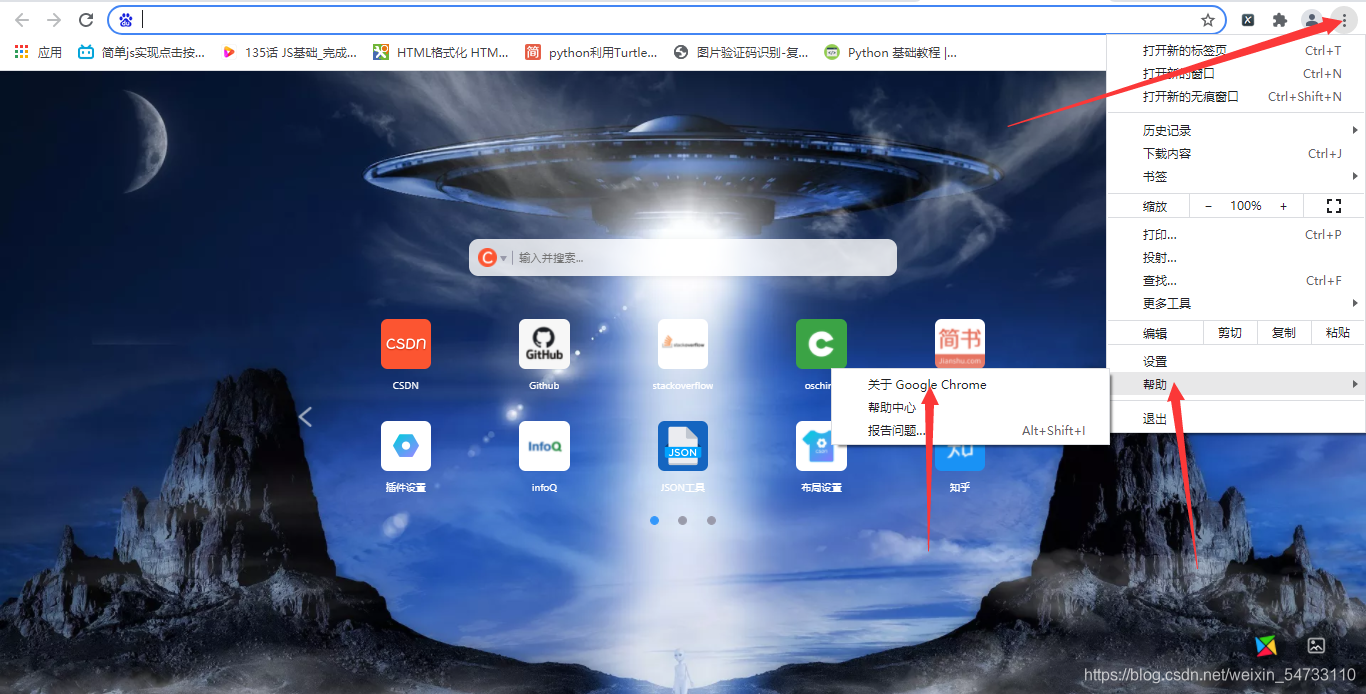
进行标签定位

数据都在tbody标签里,tr代表一行的数据,有20个tr标签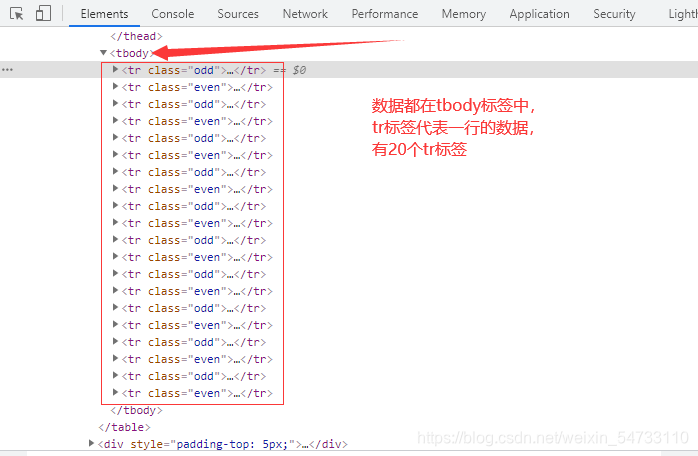
构造一下网页翻页
dirver.find_element_by_xpath(r’//*[@id=“main-table_paginate”]/a[2]’).click()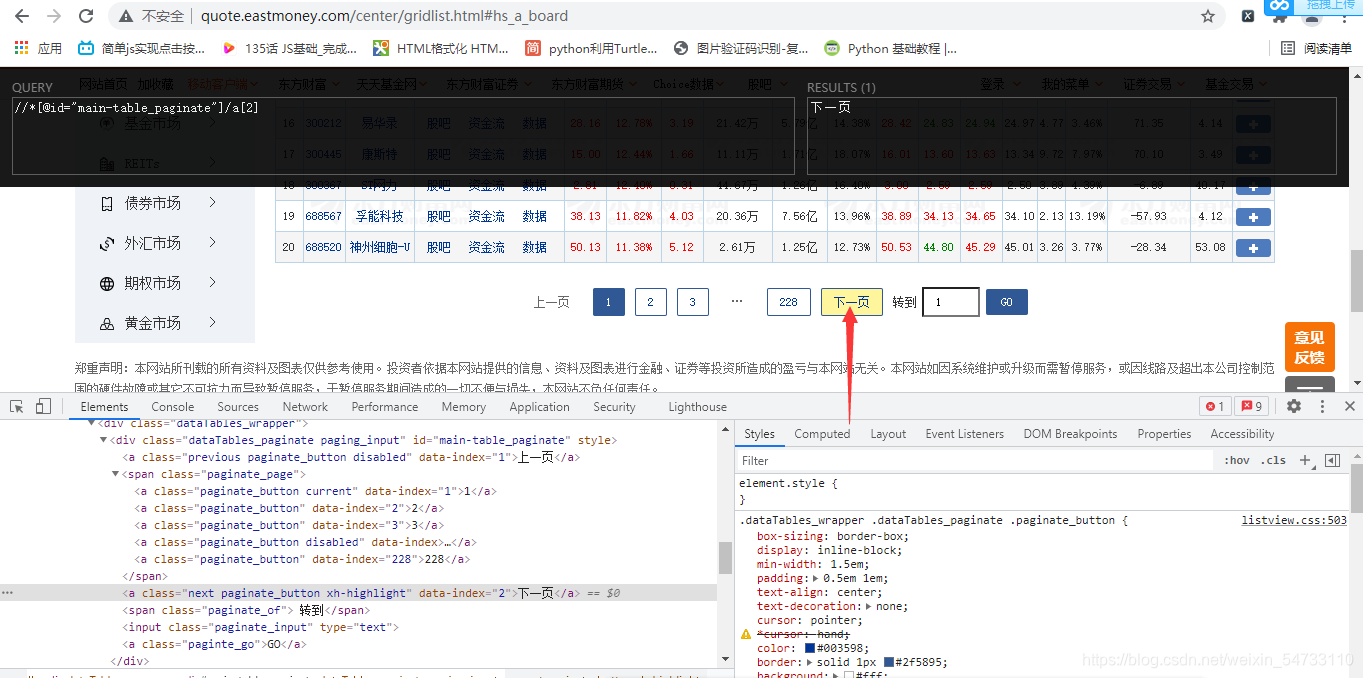
开发思路:
1.自动化获取源码
2.xpath获取标签信息
3.将信息添加到表格
4.自动化翻页
5.循环上述操作
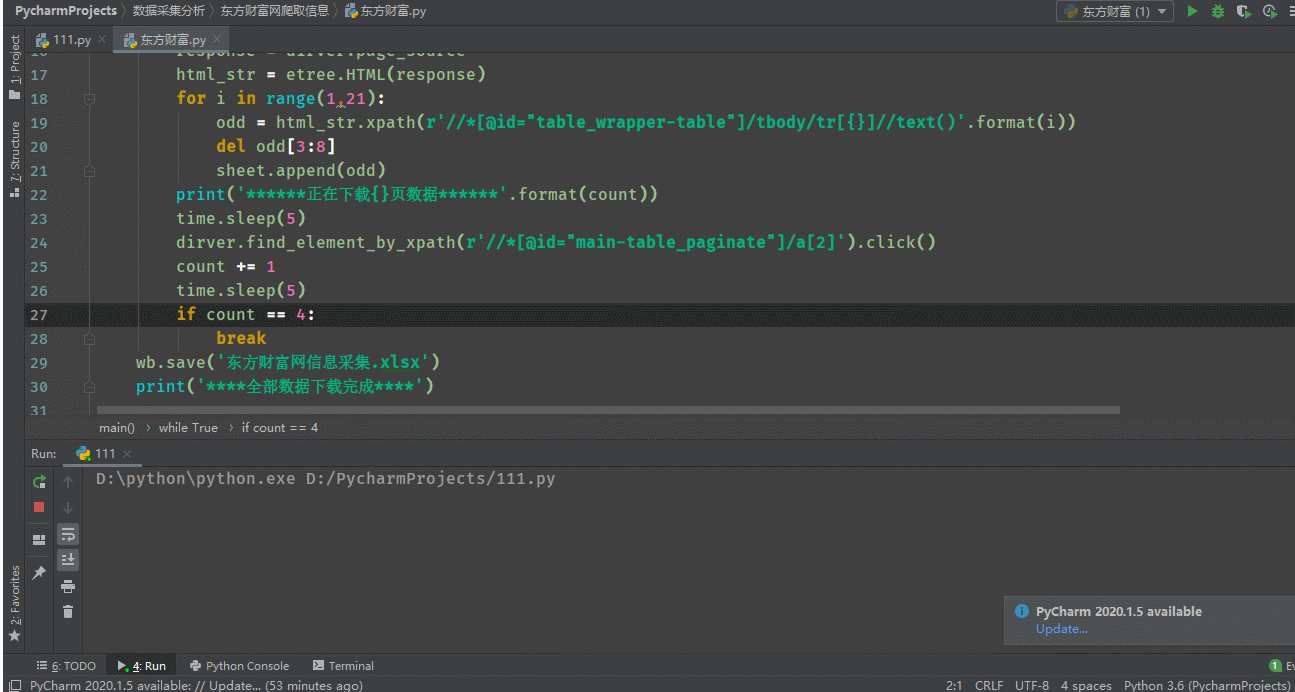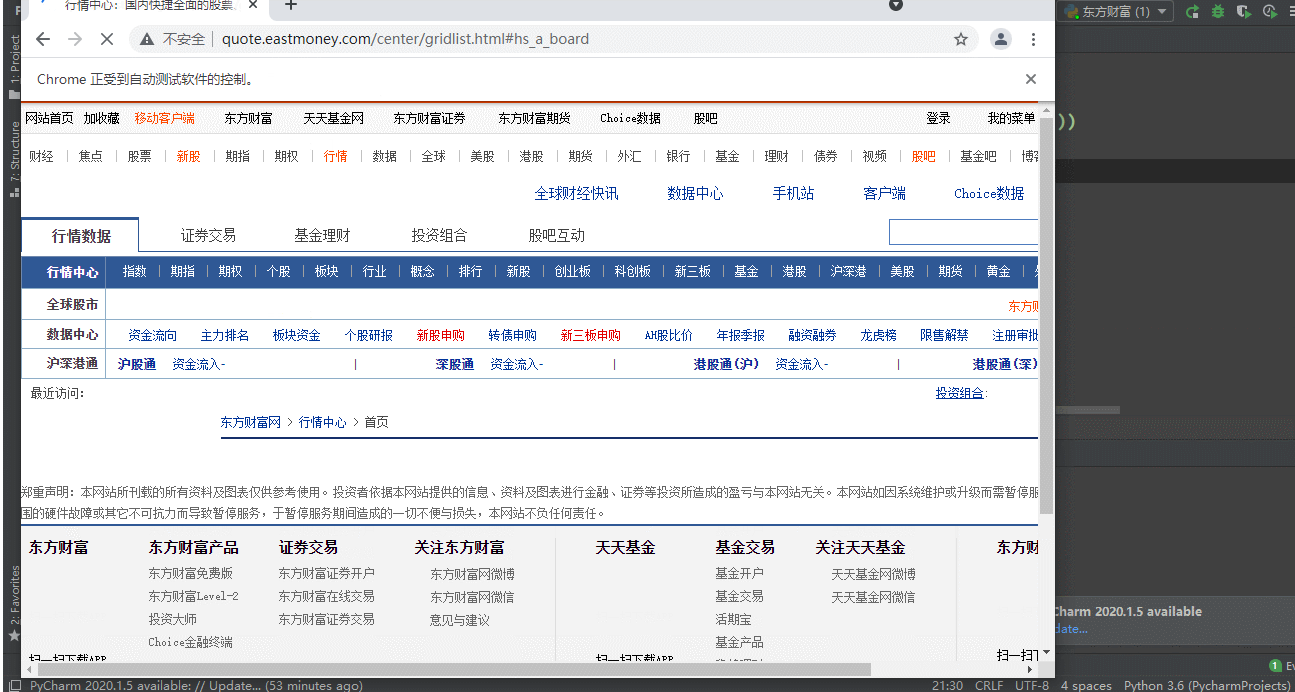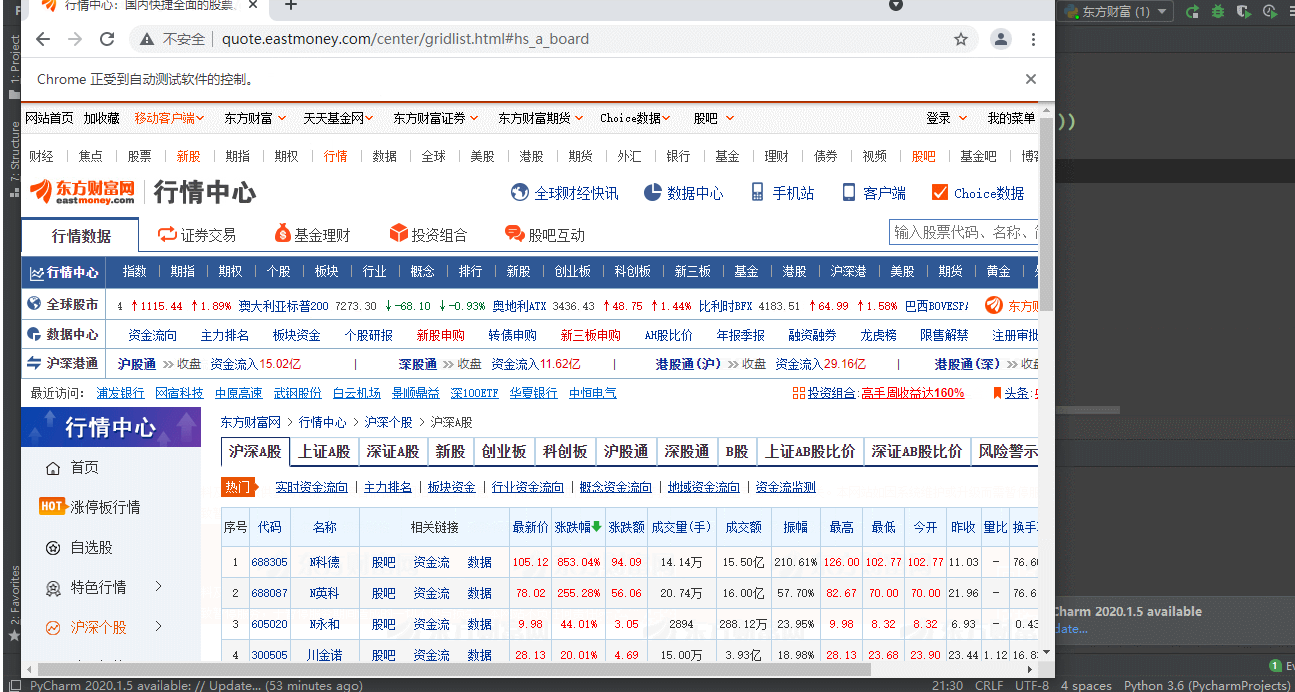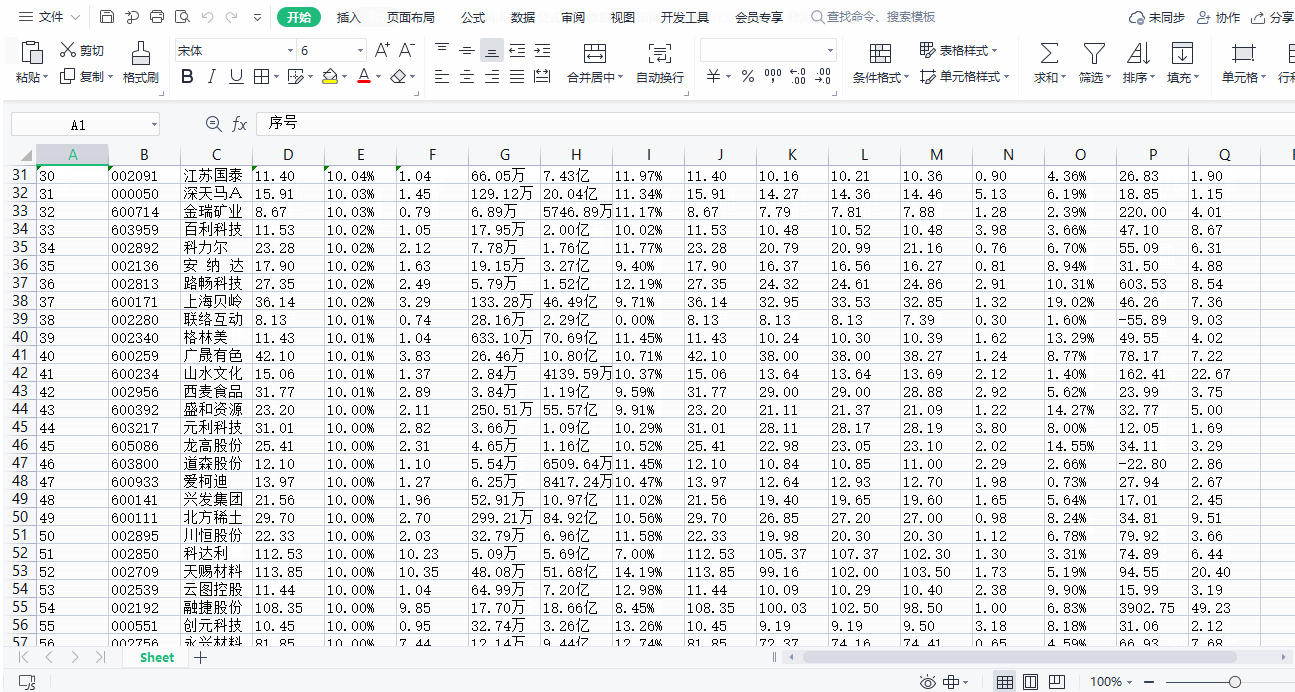
源码展示
import time
from openpyxl import Workbook
from lxml import etree
from selenium import webdriver
defmain():
url =r'http://quote.eastmoney.com/center/gridlist.html#hs_a_board'
wb = Workbook()
sheet = wb.active
sheet.append(['序号','代码','名称','最新价','涨跌幅','涨跌额','成交量(手)','成交额','振幅','最高','最低','今开','昨收','量比','换手率','市盈率(动态)','市净率'])
dirver = webdriver.Chrome(executable_path=r'D:\python\chromedriver.exe')
dirver.get(url)
count =1whileTrue:
response = dirver.page_source
html_str = etree.HTML(response)for i inrange(1,21):
odd = html_str.xpath(r'//*[@id="table_wrapper-table"]/tbody/tr[{}]//text()'.format(i))del odd[3:8]
sheet.append(odd)print('******正在下载{}页数据******'.format(count))
time.sleep(5)
dirver.find_element_by_xpath(r'//*[@id="main-table_paginate"]/a[2]').click()
count +=1
time.sleep(5)if count ==4:break
wb.save('东方财富网信息采集.xlsx')print('****全部数据下载完成****')if __name__ =='__main__':
main()
大家还可以继续开发
比如沪深A股的网址http://quote.eastmoney.com/center/gridlist.html#hs_a_board
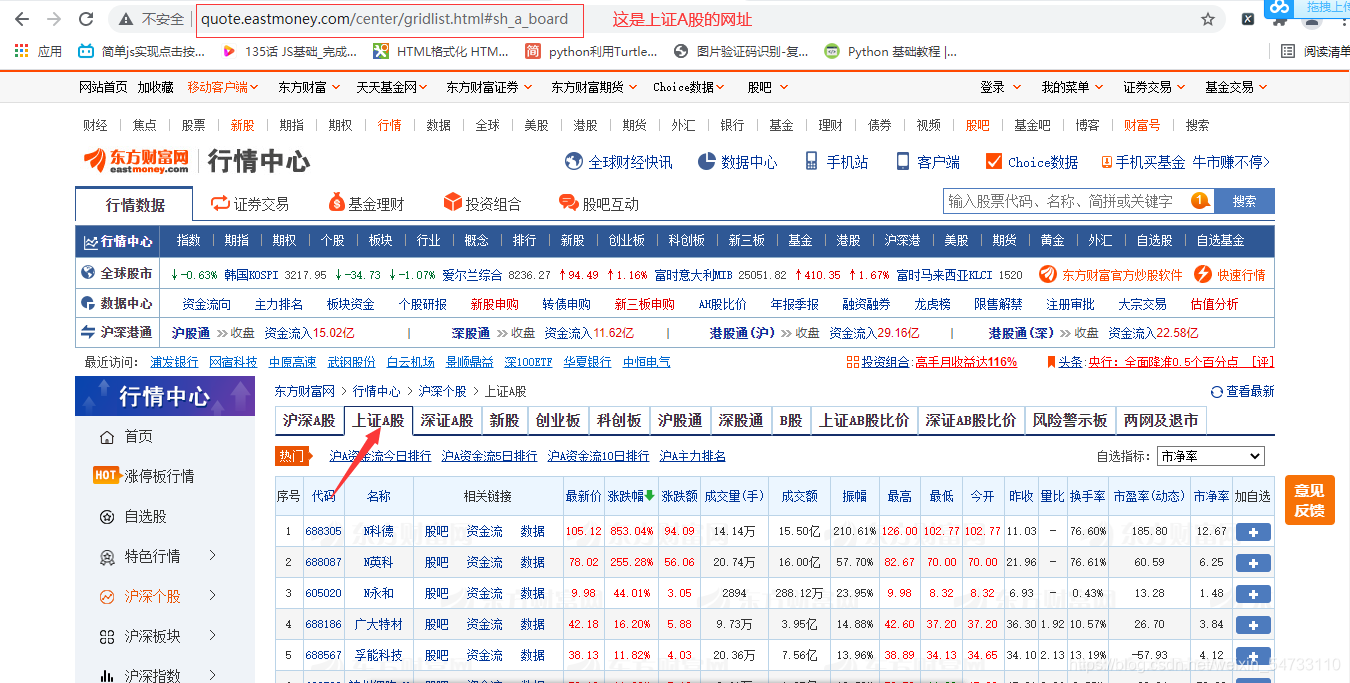
上证A股的网址http://quote.eastmoney.com/center/gridlist.html#sh_a_board
区别是后面不一样
只要将url地址变一下就可以爬取其他股票信息
自动化还是很好用的,缺点有点慢,爬取所有股票信息只是时间问题了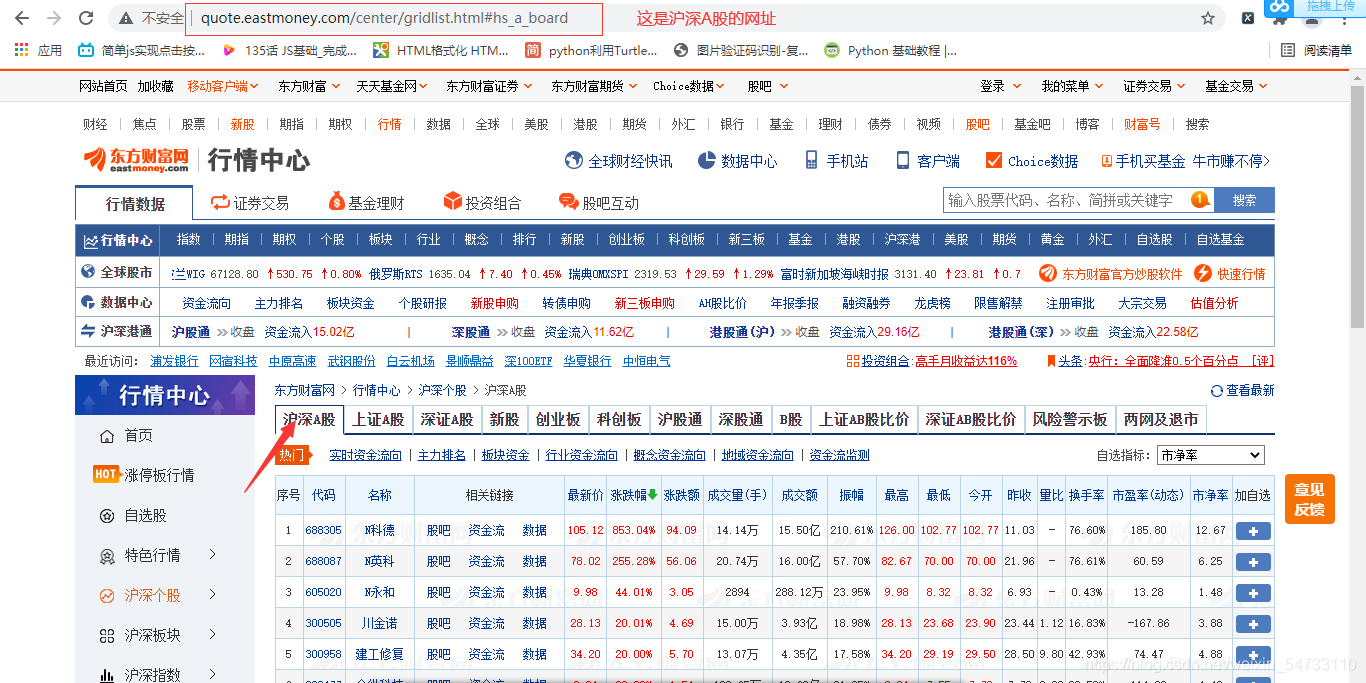

代码仅供学习!
祝大家学习python顺利!
本文转载自: https://blog.csdn.net/weixin_54733110/article/details/118641320
版权归原作者 主打Python 所有, 如有侵权,请联系我们删除。
版权归原作者 主打Python 所有, 如有侵权,请联系我们删除。