
Messaging that just works — RabbitMQ
消息队列 MQ_打造消息服务生态-阿里云
#阿里云消息队列
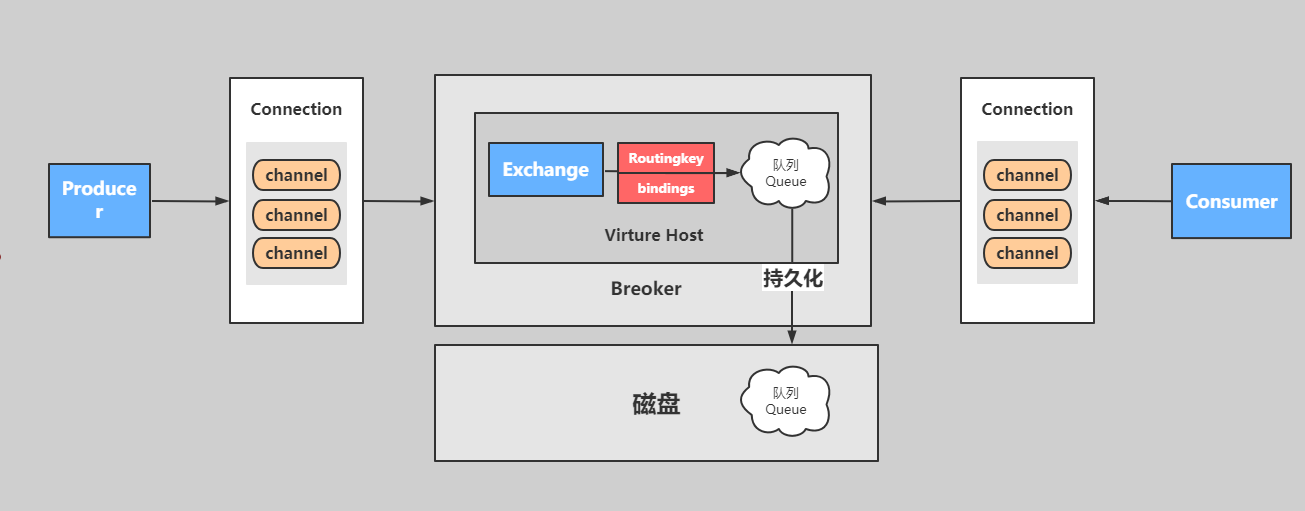
RabbitMQ 简介
RabbitMQ 采用 Erlang 语言开发,Erlang 语言由 Ericson 设计,Erlang 在分布式编程和故障恢复方面表现出色,电信领域被广泛使用。
Index - Erlang/OTP
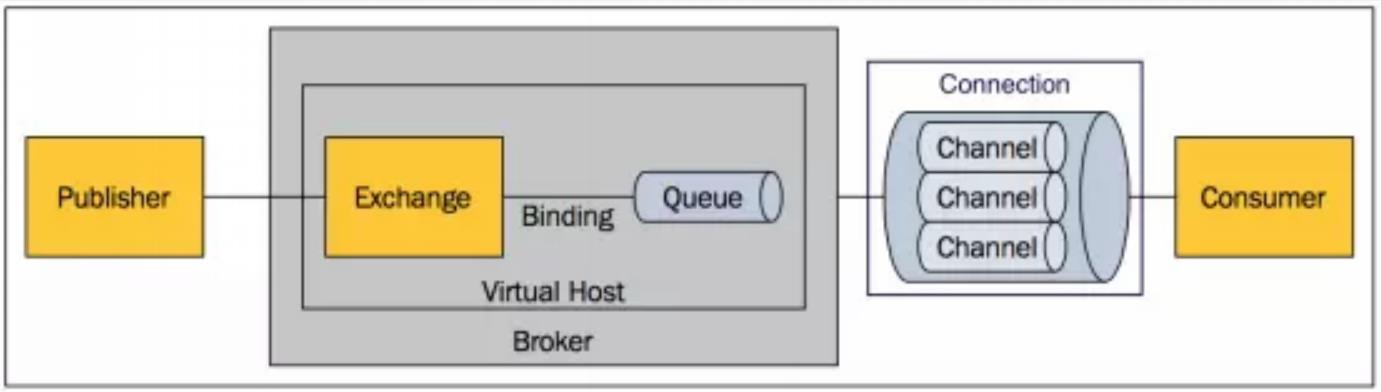
Broker: 接收和分发消息的应用,RabbitMQ Server 就是 Message Broker。
Virtual host: 出于多租户和安全因素设计的,把 AMQP 的基本组件划分到一个虚拟的分组中,类似于网络中的 namespace 概念,当多个不同的用户使用同一个RabbitMQ server 提供的服务时,可以划分出多个 vhost,每个用户在自己的vhost创建 exchange/queue 等。
**Connection: **publisher/consumer 和 broker 之间的 TCP 连接。
**Channel: **如果每一次访问 RabbitMQ 都建立一个 Connection,在消息量大的时候建立 TCP Connection 的开销将是巨大的,效率也较低。Channel 是在 connection内部建立的逻辑连接,如果应用程序支持多线程,通常每个 thread 创建单独的channel 进行通讯,AMQP method 包含了 channel id 帮助客户端和 message broker识别 channel,所以 channel 之间是完全隔离的。Channel 作为轻量级的 Connection极大减少了操作系统建立 TCP connection 的开销。
**Exchange: **message 到达 broker 的第一站,根据分发规则,匹配查询表中的 routing key,分发消息到 queue 中去。常用的类型有:direct (point-to-point), topic (publishsubscribe) and fanout (multicast)。
**Queue: **消息最终被送到这里等待 consumer 取走。
**Binding: **exchange 和 queue 之间的虚拟连接,binding 中可以包含 routing key。Binding 信息被保存到 exchange 中的查询表中,用于 message 的分发依据。
rabbitmq 优势
- 基于 erlang 语言开发,具有高并发优点、支持分布式
- 具有消息确认机制、消息持久化机制,消息可靠性和集群可靠性高
- 简单易用、运行稳定、跨平台、多语言
- 开源
Queue 的特性:
- 消息基于先进先出的原则进行顺序消费
- 消息可以持久化到磁盘节点服务器
- 消息可以缓存到内存节点服务器提高性能
RabbitMQ 中的生产者消费者示例
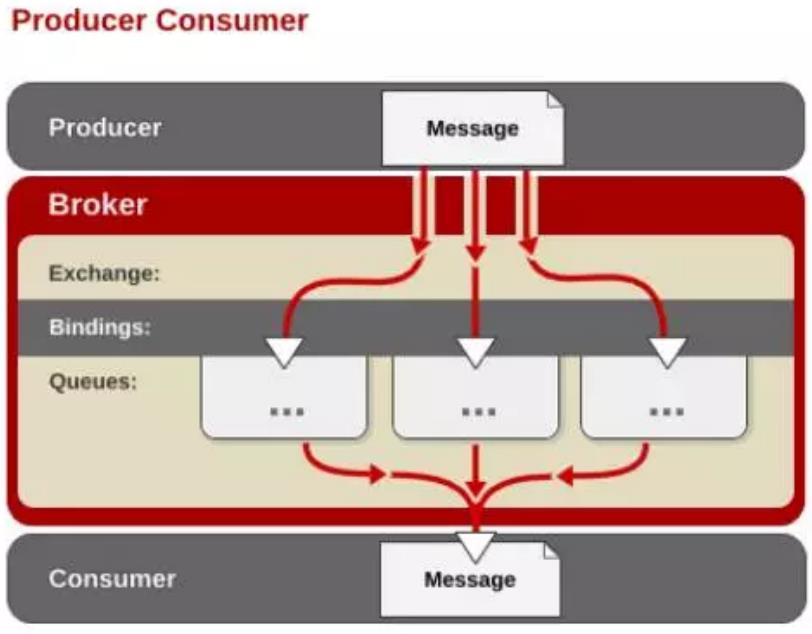
工作原理:生产者发送消息到 broker server(RabbitMQ),在 Broker 内部,用户创建Exchange/Queue,通过 Binding 规则将两者联系在一起,Exchange 分发消息,根据类型/binding 的不同分发策略有区别,消息最后来到 Queue 中,等待消费者取走。
JMS 是在 2001 年发布的 Java 消息服务(Java Message Service)应用程序接口,是一个 Java 平台中关于面向消息中间件(MOM,message oriented middleware)的 API,用于在两个应用程序之间,或分布式系统中发送消息,进行异步通信。
RabbitMQ 单机部署
Downloading and Installing RabbitMQ — RabbitMQ #官网下载地址
Releases · rabbitmq/rabbitmq-server · GitHub #github 下载地址
RabbitMQ Erlang Version Requirements — RabbitMQ #Erlang与RabbitMq版本对应表
RabbitMQ是一个开源的遵循 AMQP协议实现的基于 Erlang语言编写,即需要先安装部署Erlang环境再安装RabbitMQ环境。需加注意的是,若不想跟着我的版本号下载安装,可根据两者版本号的对应表(下面图示只展示了部分),安装相应版本的Erlang和RabbitMQ,只需在下文修改命令里面的版本号即可。

实验使用版本号:
linux系统:centos7.x
Erlang:erlang-21.3.8.21-1.el7.x86_64.rpm
RabbitMq:3.8.3
安装Erlang
下载链接:rabbitmq/erlang - Packages · packagecloud

复制下载命令

下载

下载完后安装

安装完毕

安装RabbitMq
下载链接:rabbitmq/rabbitmq-server - Packages · packagecloud


下载

接着,当你下载完成后,你需要运行下面的命令来将 Key 导入,执行命令:
rpm --import https://www.rabbitmq.com/rabbitmq-release-signing-key.asc
然后继续安装

启动rabbitmq并设置开机启动
systemctl start rabbitmq-server
systemctl enable rabbitmq-server

RabbitMQ web界面管理
Management Plugin — RabbitMQ
使用插件的方式安装
默认情况下,是没有安装web端的客户端插件,需要安装才可以生效。执行命令:
rabbitmq-plugins enable rabbitmq_management
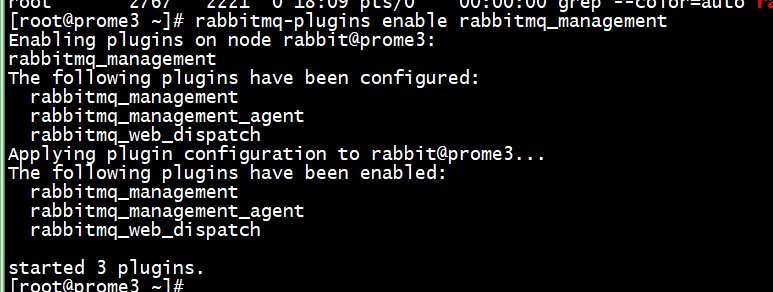
安装完毕后需要重启
systemctl restart rabbitmq-server
使用的端口:
5672:消费者访问的 端口
15672:web 管理端口
25672:集群状态通信端口
默认账号密码:guest/guest
rabbitmq 从 3.3.0 开始禁止使用 guest/guest 权限通过除 localhost 外的访问,直
接访问报错如下:

允许登录方式:
vim /usr/lib/rabbitmq/lib/rabbitmq_server-3.8.3/ebin/rabbit.app
39 {loopback_users, []}, #删除被禁止登陆的 guest 账户

systemctl restart rabbitmq-server.service #重启 rabbitmq 服务
完成
新增用户
设置账号密码都为admin
rabbitmqctl add_user admin admin
设置用户分配操作权限
rabbitmqctl set_user_tags admin administrator

不需要重启,登录即可。

用户角色
(1) 超级管理员(administrator)
可登陆管理控制台(启用managementplugin的情况下),可查看所有的信息,并且可以对用户,策略(policy)进行操作。
(2) 监控者(monitoring)
可登陆管理控制台(启用managementplugin的情况下),同时可以查看rabbitmq节点的相关信息(进程数,内存使用情况,磁盘使用情况等)
(3) 策略制定者(policymaker)
可登陆管理控制台(启用managementplugin的情况下),同时可以对policy进行管理。但无法查看节点的相关信息(上图红框标识的部分)。
(4) 普通管理者(management)
仅可登陆管理控制台(启用managementplugin的情况下),无法看到节点信息,也无法对策略进行管理。
(5) 其他
无法登陆管理控制台,通常就是普通的生产者和消费者。
RabbitMQ docker部署
请在服务器上开放相应地安全组
- 端口:15672
- ui页面通信口:5672
- 集群状态通信端口:25672
- server间内部通信口:61613、1883
命令:
docker run -d --name rabbit -e RABBITMQ_DEFAULT_USER=admin -e RABBITMQ_DEFAULT_PASS=admin -p 15672:15672 -p 5672:5672 -p 25672:25672 -p 61613:61613 -p 1883:1883 rabbitmq:management
镜像名:rabbitmq:management
docker容器会自动从Docker Hub中拉取RabbitMQ的镜像,并创建容器(注意:此镜像包含Erlang环境)
rabbitmq有一个默认账号和密码是:** guest ,默认情况只能在 localhost本计下访问,所以我们需要通过刚才创建的admin用户进行登录。输入 http://IP地址:15672 即可完成访问,账号密码都为admin。**
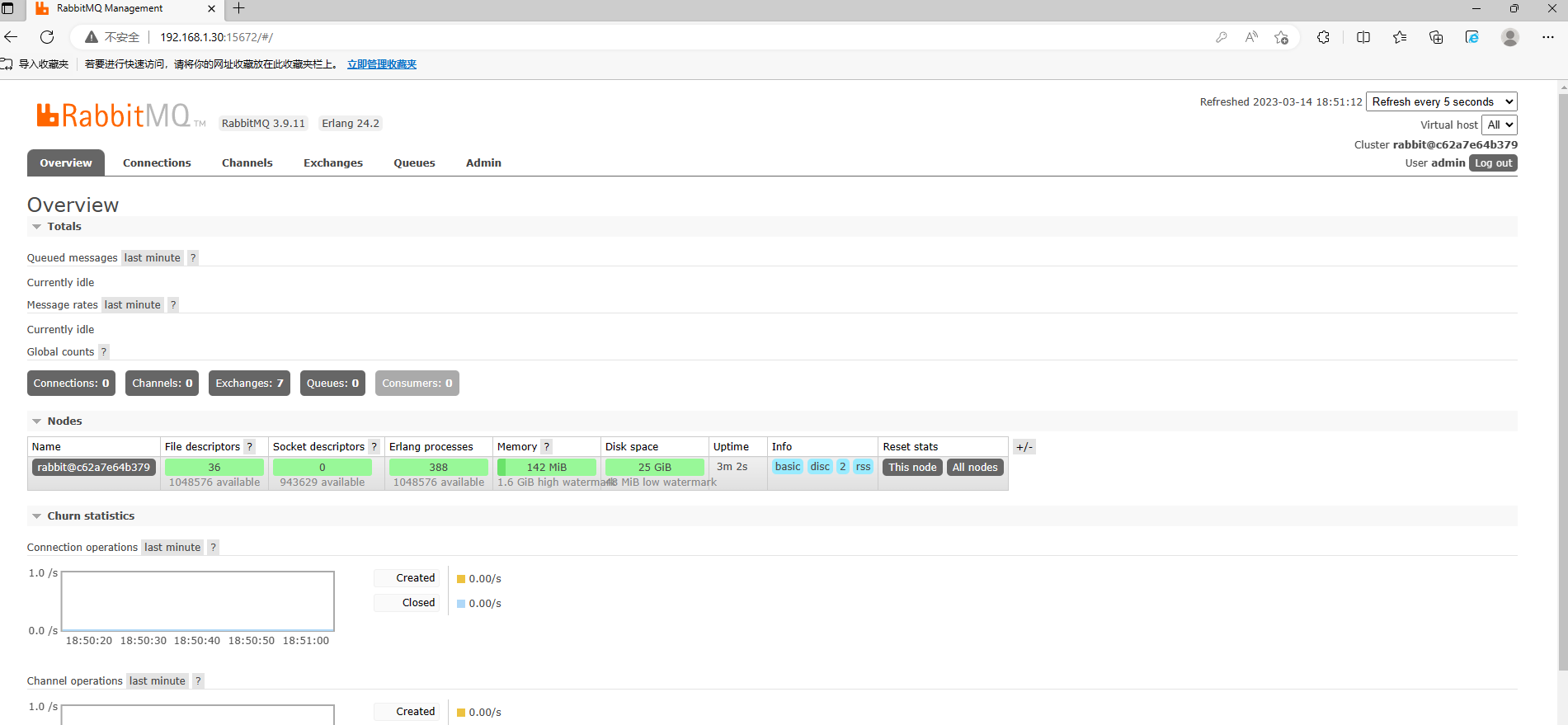
RabbitMQ 集群部署
Rabbitmq 集群分为二种方式:
普通模式:创建好 RabbitMQ 集群之后的默认模式。
镜像模式:把需要的队列做成镜像队列。
普通集群模式:queue 创建之后,如果没有其它 policy,消息实体只存在于其中一个节点,A、B 两个 Rabbitmq 节点仅有相同的元数据,即队列结构,但队列的数据仅保存有一份,即创建该队列的 rabbitmq 节点(A 节点),当消息进入 A 节点的 Queue 中后,consumer 从 B 节点拉取时,RabbitMQ 会临时在 A、B 间进行消息传输,把 A 中的消息实体取出并经过 B 发送给 consumer,所以 consumer 可以连接每一个节点,从中取消息,该模式存在一个问题就是当 A 节点故障后,B节点无法取到 A 节点中还未消费的消息实体。
镜像集群模式:把需要的队列做成镜像队列,存在于多个节点,属于 RabbitMQ 的 HA 方案(镜像模式是在普通模式的基础上,增加一些镜像策略)该模式解决了普通模式中的数据丢失问题,其实质和普通模式不同之处在于,消息实体会主动在镜像节点间同步,而不是在 consumer 取数据时临时拉取,该模式带来的副作用也很明显,除了降低系统性能外,如果镜像队列数量过多,加之大量的消息进入,集群内部的网络带宽将会被这种同步通讯大大消耗掉,所以在对可靠性要求较高的场合中适用,一个队列想做成镜像队列,需要先设置 policy,然后客户端创建队列的时候,rabbitmq 集群根据“队列名称”自动设置是普通集群模式或镜像队列。客户端可以通过HA+4层负载均衡器(比如haproxy+keepalived)来实现高可用
集群中有两种节点类型:
内存节点:只将数据保存到内存
磁盘节点:保存数据到内存和磁盘。
内存节点虽然不写入磁盘,但是它执行比磁盘节点要好,集群中,只需要一个磁盘节点来保存数据就足够了如果集群中只有内存节点,那么不能全部停止它们,否则所有数据消息在服务器全部停机之后都会丢失。
推荐设计架构:
在一个 rabbitmq 集群里,有 3 台或以上机器,其中 1 台使用磁盘模式,其它节点使用内存模式,内存节点无访问速度更快,由于磁盘 IO 相对较慢,因此可作为数据备份使用。
实验环境
192.168.1.29 mq-server2
192.168.1.30 mq-server1
192.168.1.31 mq-server3
创建erlang集群
Rabbitmq 的集群是依赖于 erlang 的集群来工作的,所以必须先构建起 erlang 的集群环境,而 Erlang 的集群中各节点是通过一个 magic cookie 来实现的,这个cookie 存放在 /var/lib/rabbitmq/.erlang.cookie 中,文件是 400 的权限,所以必须保证各节点 cookie 保持一致,否则节点之间就无法通信。
各服务器同步erlang.cookie
[root@prome2 ~]# systemctl stop rabbitmq-server
[root@prome3 ~]# systemctl stop rabbitmq-server
[root@prome4 ~]# systemctl stop rabbitmq-server
在mq-server1同步erlang.cookie到其他服务器
[root@prome3 ~]# scp /var/lib/rabbitmq/.erlang.cookie prome2:/var/lib/rabbitmq/
[root@prome3 ~]# scp /var/lib/rabbitmq/.erlang.cookie prome4:/var/lib/rabbitmq/
启动rabbitmq
[root@prome2 ~]# systemctl start rabbitmq-server
[root@prome3 ~]# systemctl start rabbitmq-server
[root@prome4 ~]# systemctl start rabbitmq-server
查看集群状态
[root@prome3 ~]# rabbitmqctl cluster_status

创建rabbit集群
在 mq-server1 作为内存节点添加到 mq-server3,并作为内存节点,在 mq-server1执行以下命令:
[root@prome3 ~]# rabbitmqctl stop_app #停止APP服务
[root@prome3 ~]# rabbitmqctl reset #清空元数据
- 将 rabbitmq-server1 添加到集群rabbit@prome2当中,不加--ram 默认是磁盘节点
[root@prome3 ~]# rabbitmqctl join_cluster rabbit@prome2

[root@prome3 ~]# rabbitmqctl start_app #启动app服务

- 在 mq-server2 作为内存节点添加到 集群rabbit@prome2,并作为内存节点,在 mq-server2执行以下命令:
[root@prome2 ~]# rabbitmqctl stop_app
[root@prome2 ~]# rabbitmqctl reset
Resetting node rabbit@prome2 ...
报错:
Error:
{:resetting_only_disc_node, 'You cannot reset a node when it is the only disc node in a cluster. Please convert another node of the cluster to a disc node first.'}
当节点是群集中唯一的光盘节点时,无法重置节点。请先将群集的另一个节点转换为光盘节点。
mq-server2作为被加入的集群,不需要做任何操作
- 在mq-server3作为内存节点添加到集群rabbit@prome2
[root@prome4 ~]# rabbitmqctl stop_app
[root@prome4 ~]# rabbitmqctl reset
[root@prome4 ~]# rabbitmqctl join_cluster rabbit@prome2 --ram

[root@prome4 ~]# rabbitmqctl start_app
修改RabbitMQ集群的名字为testmq,在哪台机器上都可以
[root@prome4 ~]# rabbitmqctl set_cluster_name testmq

将集群设置为镜像模式
只要在其中一台节点执行以下命令即可:
- 设置policy,以ha.开头的队列将会被镜像到集群其他所有节点,一个节点挂掉然后重启后需要手动同步队列消息
[root@prome2 ~]# rabbitmqctl set_policy ha-all "#" '{"ha-mode":"all"}'

- 设置policy,以ha.开头的队列将会被镜像到集群其他所有节点,一个节点挂掉然后重启后会自动同步队列消息(生产环境采用这个方式)
[root@prome4 ~]# rabbitmqctl set_policy ha-all-queue "^ha." '{"ha-mode":"all","ha-sync-mode":"automatic"}'

问题:
配置镜像队列后,其中1台节点失败,队列内容是不会丢失,如果整个集群重启,队列中的消息内容仍然丢失,如何实现队列消息内容持久化那?
集群节点跑在disk模式,创建见消息的时候也声明了持久化,为什么还是不行那?
因为创建消息的时候需要指定消息是否持久化,如果启用了消息的持久化的话,重启集群消息也不会丢失了,前提是创建的队列也应该是创建的持久化队列。
验证当前集群状态
命令:rabbitmqctl cluster_status



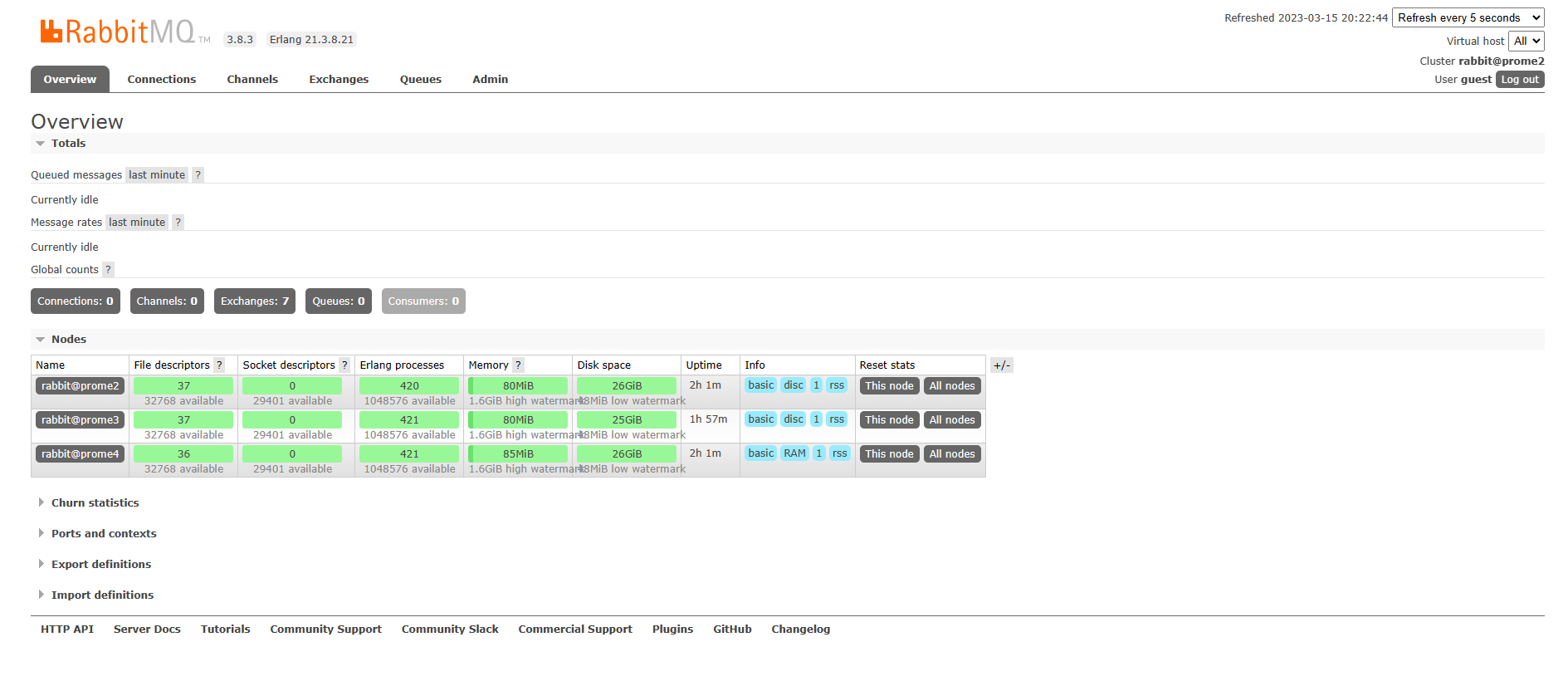
web界面验证当前集群状态:
不启用 web 插件的 rabbitmq 服务器,会在 web 节点提示节点统计信息不可用
(Node statistics not available)
启用web插件:rabbitmq-plugins enable rabbitmq_management
重启服务即可
RabbitMQ 常用命令
#创建 vhost
root@mq-server1:~# rabbitmqctl add_vhost magedu

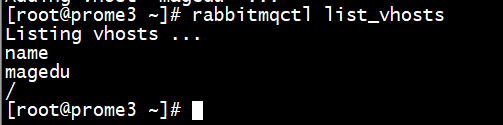
#列出所有 vhost
root@mq-server1:~# rabbitmqctl list_vhosts
#列出所有队列
root@mq-server1:~# rabbitmqctl list_queues

#删除指定 vhost
root@mq-server1:~# rabbitmqctl delete_vhost magedu

#添加账户 jack 密码为 123456
root@mq-server1:~# rabbitmqctl add_user jack 123456

#更改用户密码
root@mq-server1:~# rabbitmqctl change_password jack 654321

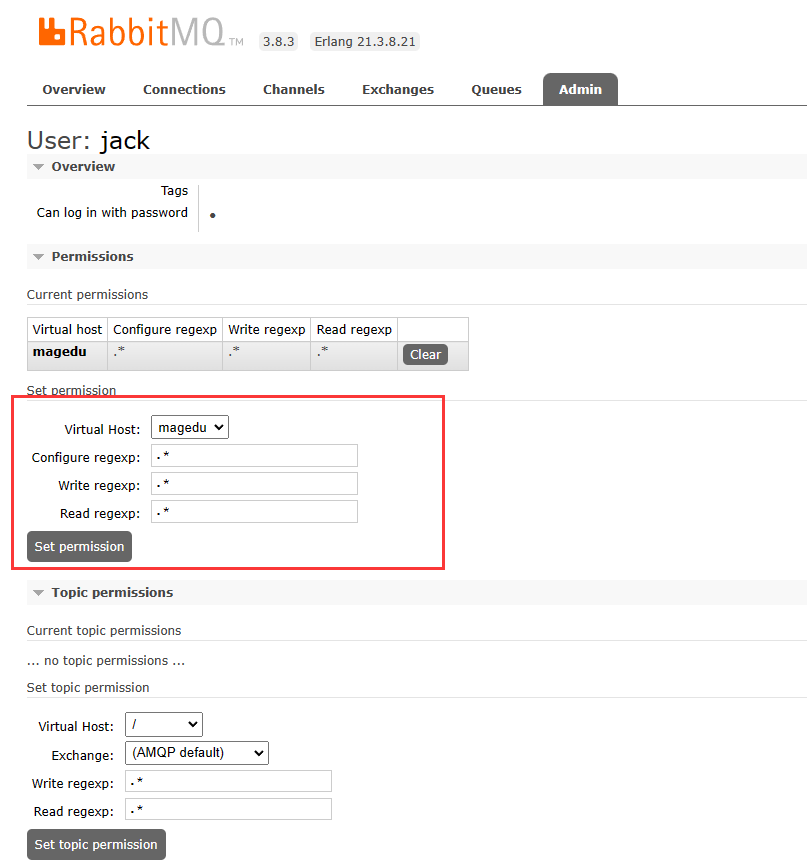
#设置 jack 用户对 magedu 的 vhost 有读写权限,三个点为配置正则、读和写
root@mq-server1:~# rabbitmqctl set_permissions -p magedu jack "." "." ".*"

#以内存节点加入集群(不加--ram是以硬盘节点加入
rabbitmqctl join_cluster --ram rabbit@mq1
#查看集群状态
rabbitmqctl cluster_status
#退出集群
rabbitmqctl stop_app #在需要退出的节点上执行
rabbitmqctl forget_cluster_node rabbit@mq3 #在master节点上执行踢出节点
rabbitmqctl reset #也可以退出集群
rabbitmq运维
RabbitMQ 运维篇_rabbitmq运维_路面烧卖的博客-CSDN博客
RabbitMQ目录结构
默认位置:/usr/lib/rabbitmq
目录结构

配置文件位置:
/usr/lib/rabbitmq/lib/rabbitmq_server-3.8.3/ebin/rabbit.app
/etc/rabbitmq/enabled_plugins #设置允许的插件列表
[rabbitmq_management].
/var/lib/rabbitmq/mnesia #后端存储目录
持久化机制
什么是RibbitMQ持久化:就把信息写入到磁盘的过程。
持久消息:把消息默认放在内存中是为了加快传输和消费的速度,存入磁盘是保证消息数据的持久化。
非持久消息:是指当内存不够用的时候,会把消息和数据转移到磁盘,但是重启以后非持久化队列消息就丢失。
RabbitMQ的持久化队列分为:
- 队列持久化
- 消息持久化
- 交换机持久化
不论是持久化的消息还是非持久化的消息都可以写入到磁盘中,只不过非持久的是等内存不足的情况下才会被写入到磁盘中。
队列持久化
队列的持久化是定义队列时的durable参数来实现的,Durable为true时,队列才会持久化。
// 参数1:名字
// 参数2:是否持久化,
// 参数3:独du占的queue,
// 参数4:不使用时是否自动删除,
// 参数5:其他参数
channel.queueDeclare(queueName,true,false,false,null);
其中参数2:设置为true,就代表的是持久化的含义。即durable=true。持久化的队列在web控制台中有一个D 的标记

消息持久化
消息持久化是通过消息的属性deliveryMode来设置是否持久化,在发送消息时通过basicPublish的参数传入。
// 参数1:交换机的名字
// 参数2:队列或者路由key
// 参数3:是否进行消息持久化
// 参数4:发送消息的内容
channel.basicPublish(exchangeName, routingKey, MessageProperties.PERSISTENT_TEXT_PLAIN,message.getBytes());
通过设置参数3,把消息本体设置为持久化
交换机持久化
和队列一样,交换机也需要在定义的时候设置持久化的标识,否则在rabbit-server服务重启以后将丢失。
// 参数1:交换机的名字
// 参数2:交换机的类型,topic/direct/fanout/headers
// 参数3:是否持久化
channel.exchangeDeclare(exchangeName,exchangeType,true);

每一个节点,不管是磁盘存储还是内存存储,都具备全部的队列、消息数据;即,每一个节点都是一个单独的出入口,这样可以提高整体的吞吐量;
如果集群里只有一个磁盘节点,这个节点挂了,会发生什么?此时消息路由机制仍可正常进行(可以正常投递和消费消息),但是不能做如下事:
● create queues
● create exchanges
● create bindings
● add users
● change permissions
● add or remove cluster nodes
所以,考虑到高可用性,推荐在集群里保持2个磁盘节点,这样一个挂了,另一个还可正常工作。但上述最后一点,往集群里增加或删除节点,要求2个磁盘节点同时在线
如果不做队列持久化、消息持久化,那么当队列所在的节点宕掉后,数据就会全部丢失;
即便做了队列和消息的持久化,也需要队列所在的节点恢复启动后才可以使用;
RabbitMQ监控
监控脚本
集群状态监控
#!/bin/env python
#coding:utf-8
#Author: ZhangJie
import subprocess
running_list = []
error_list = []
false = "false"
true = "true"
def get_status():
obj = subprocess.Popen(("curl -s -u guest:guest
http://localhost:15672/api/nodes &> /dev/null"), shell=True,
stdout=subprocess.PIPE)
data = obj.stdout.read()
data1 = eval(data)
for i in data1:
if i.get("running") == "true":
running_list.append(i.get("name"))
else:
error_list.append(i.get("name"))
def count_server():
if len(running_list) < 3: # 可以判断错误列表大于 0 或者运行列表小于 3,3未总计的节点数量
print(101) # 100 就是集群内有节点运行不正常了
else:
print(50) # 50 为所有节点全部运行正常
def main():
get_status()
count_server()
if __name__ == "__main__":
main()
内存使用监控
cat rabbitmq_memory.py
#!/bin/env python
#coding:utf-8
#Author: ZhangJie
import subprocess
import sys
running_list = []
error_list = []
false = "false"
true = "true"
def get_status():
obj = subprocess.Popen(("curl -s -u guest:guest
http://localhost:15672/api/nodes &> /dev/null"), shell=True,
stdout=subprocess.PIPE)
data = obj.stdout.read()
data1 = eval(data)
#print(data1)
for i in data1:
if i.get("name") == sys.argv[1]:
print(i.get("mem_used"))
def main():
get_status()
if __name__ == "__main__":
main()
验证:
root@mq-server3:~# python3 rabbitmq_memory.py rabbit@mq-server1
85774336
root@mq-server3:~# python3 rabbitmq_memory.py rabbit@mq-server2
91099136
root@mq-server3:~# python3 rabbitmq_memory.py rabbit@mq-server3
96428032
zabbix监控节点状态
#!/bin/bash
STATUS=$(sudo /usr/sbin/rabbitmqctl -q cluster_status)
LIST_NODES=$(echo $STATUS |grep -o "{running_nodes.*.}," | sed -n '/running_nodes,\[.*\]\},/p' | sed -r 's/\[|\]|\{|\}|running_nodes,//g')
ARRAY_LIST_NODES=$(echo $LIST_NODES | tr "," "\n"| tr "\'" "\ ")
FIRST_ELEMENT=1
type_detect=0
function json_head {
printf "{"
printf "\"data\":["
}
function json_end {
printf "]"
printf "}"
}
function check_first_element {
if [[ $FIRST_ELEMENT -ne 1 ]]; then
printf ","
fi
FIRST_ELEMENT=0
}
function nodes_detect {
json_head
for node in $ARRAY_LIST_NODES
do
local VHOST_LIST=$(sudo /usr/sbin/rabbitmqctl -q -n ${node} list_vhosts )
for vhost in $VHOST_LIST
do
local vhost_t=$(echo $vhost| sed 's!/!\\/!g')
local node_t=$(echo $node| sed 's!@!__dog__!g')
#only nodes
if [[ $type_detect -eq 0 ]]; then
check_first_element
printf "{"
printf "\"{#NODENAME}\":\"$node_t\", \"{#VHOSTNAME}\":\"$vhost_t\""
printf "}"
fi
#queue
if [[ $type_detect -eq 1 ]]; then
local list_queue=$(sudo /usr/sbin/rabbitmqctl -q -n ${node} -p ${vhost} list_queues | awk '{print $1}')
for queue in $list_queue
do
check_first_element
printf "{"
printf "\"{#NODENAME}\":\"$node_t\", \"{#VHOSTNAME}\":\"$vhost_t\", \"{#QUEUENAME}\":\"$queue\" "
printf "}"
done
fi
#exchanges
if [[ $type_detect -eq 2 ]]; then
local list_exchange=$(sudo /usr/sbin/rabbitmqctl -q -n ${node} -p ${vhost} list_exchanges | awk '{print $1}' )
for exchange in $list_exchange
do
check_first_element
printf "{"
printf "\"{#NODENAME}\":\"$node_t\", \"{#VHOSTNAME}\":\"$vhost_t\", \"{#EXCHANGENAME}\":\"$exchange\" "
printf "}"
done
fi
done
done
json_end
}
case $1 in
queue)
type_detect=1
nodes_detect
;;
exchange)
type_detect=2
nodes_detect
;;
*)
type_detect=0
nodes_detect
;;
esac
zabbix监控状态
GitHub - alfssobsd/zabbix-rabbitmq: Monitoring script for rabbitmq
#!/bin/bash
#UserParameter=rabbitmq[*],<%= zabbix_script_dir %>/rabbitmq-status.sh
NODE=$(echo $1| sed 's!__dog__!@!g')
VHOST=$2
METRIC=$3
ITEM=$4
#rabbitmq[rabbit,\/,list_queues,none]
if [ "$METRIC" = "list_queues" ]; then
sudo /usr/sbin/rabbitmqctl -n $NODE -p $VHOST list_queues | grep -cv '\.\.\.'
fi
#rabbitmq[rabbit,\/,list_exchanges,none]
if [ "$METRIC" = "list_exchanges" ]; then
sudo /usr/sbin/rabbitmqctl -n $NODE -p $VHOST list_exchanges | grep -cv '\.\.\.'
fi
#rabbitmq[rabbit,\/,queue_durable,queue-name]
if [ "$METRIC" = "queue_durable" ]; then
sudo /usr/sbin/rabbitmqctl -n $NODE -p $VHOST list_queues name durable | grep "^$ITEM\s.*$" | awk '{ print $2 }'
fi
#rabbitmq[rabbit,\/,queue_msg_ready,queue-name]
if [ "$METRIC" = "queue_msg_ready" ]; then
sudo /usr/sbin/rabbitmqctl -n $NODE -p $VHOST list_queues name messages_ready | grep "^$ITEM\s.*$" | awk '{ print $2 }'
fi
#rabbitmq[rabbit,\/,queue_msg_unackd,queue-name]
if [ "$METRIC" = "queue_msg_unackd" ]; then
sudo /usr/sbin/rabbitmqctl -n $NODE -p $VHOST list_queues name messages_unacknowledged | grep "^$ITEM\s.*$" | awk '{ print $2 }'
fi
#rabbitmq[rabbit,\/,queue_msgs,queue-name]
if [ "$METRIC" = "queue_msgs" ]; then
sudo /usr/sbin/rabbitmqctl -n $NODE -p $VHOST list_queues name messages | grep "^$ITEM\s.*$" | awk '{ print $2 }'
fi
#rabbitmq[rabbit,\/,queue_consumers,queue-name]
if [ "$METRIC" = "queue_consumers" ]; then
sudo /usr/sbin/rabbitmqctl -n $NODE -p $VHOST list_queues name consumers | grep "^$ITEM\s.*$" | awk '{ print $2 }'
fi
#rabbitmq[rabbit,\/,queue_memory,queue-name]
if [ "$METRIC" = "queue_memory" ]; then
sudo /usr/sbin/rabbitmqctl -n $NODE -p $VHOST list_queues name memory | grep "^$ITEM\s.*$" | awk '{ print $2 }'
fi
#rabbitmq[rabbit,\/,exchange_durable,exchange-name]
if [ "$METRIC" = "exchange_durable" ]; then
sudo /usr/sbin/rabbitmqctl -n $NODE -p $VHOST list_exchanges name durable | grep "^$ITEM\s.*$" | awk '{ print $2 }'
fi
#rabbitmq[rabbit,\/,exchange_type,exchange-name]
if [ "$METRIC" = "exchange_type" ]; then
sudo /usr/sbin/rabbitmqctl -n $NODE -p $VHOST list_exchanges name type | grep "^$ITEM\s.*$" | awk '{ print $2 }'
fi
内存磁盘的监控配置
rabbitmq的内存警告
当内存使用超过配置的阈值或者磁盘空间剩余空间对于配置的阈值时,RabbitMQ会暂时阻塞客户端的连接,并且停止接收从客户端发来的消息,以此避免服务器的崩溃,客户端与服务端的心态检测机制也会失效。
如下图:
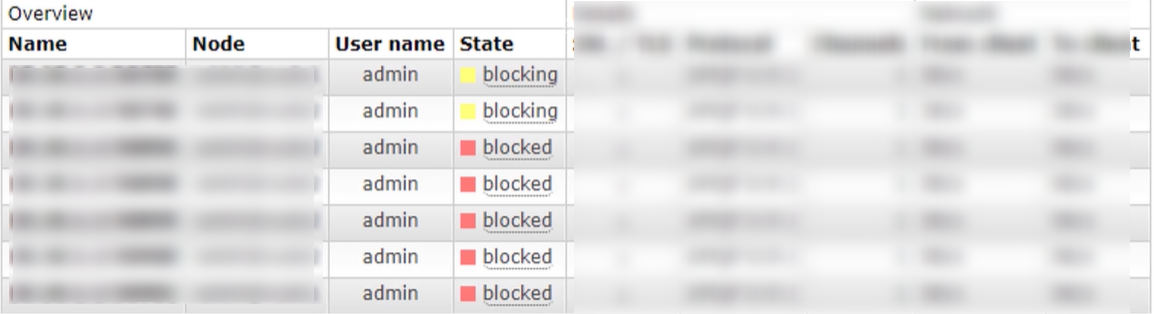
rabbitmq的内存控制
参考帮助文档:https://rabbitmq.com/memory.html
当出现警告的时候,可以通过配置去修改和调整。可以通过命令行或者修改配置文件方式配置。
命令行方式重启后就失效了,配置文件方式不会随重启失效,但是修改完配置文件需重启应用。
命令的方式
rabbitmqctl set_vm_memory_high_watermark <fraction>
rabbitmqctl set_vm_memory_high_watermark absolute 50MB
fraction/value 为内存阈值。默认情况是:0.4/2GB,代表的含义是:当RabbitMQ的内存超过40%时,就会产生警告并且阻塞所有生产者的连接。通过此命令修改阈值在Broker重启以后将会失效,通过修改配置文件方式设置的阈值则不会随着重启而消失,但修改了配置文件一样要重启broker才会生效。
示例:
[root@prome4 ~]# rabbitmqctl set_vm_memory_high_watermark absolute 50MB


还原可以重启服务或者重新修改成默认:
rabbitmqctl set_vm_memory_high_watermark 0.4
配置文件方式
vim /usr/lib/rabbitmq/lib/rabbitmq_server-3.8.3/ebin/rabbit.app
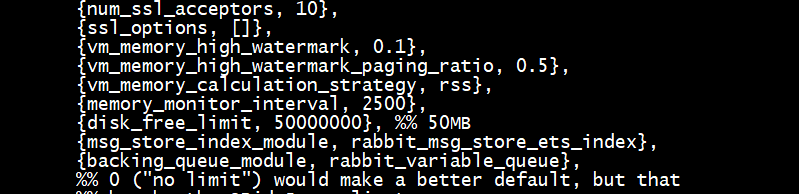
修改相应的参数后重启即可,内存限制到了400MB

rabbitmq的内存换页
在某个Broker节点及内存阻塞生产者之前,它会尝试将队列中的消息换页到磁盘以释放内存空间,持久化和非持久化的消息都会写入磁盘中,其中持久化的消息本身就在磁盘中有一个副本,所以在转移的过程中持久化的消息会先从内存中清除掉。
默认情况下,内存到达的阈值是50%时就会换页处理。
也就是说,在默认情况下该内存的阈值是0.4的情况下,当内存超过0.4*0.5=0.2时,会进行换页动作。
比如有1000MB内存,当内存的使用率达到了400MB,已经达到了极限,但是因为配置的换页内存0.5,这个时候会在达到极限400mb之前,会把内存中的200MB进行转移到磁盘中。从而达到稳健的运行。
可以通过设置 vm_memory_high_watermark_paging_ratio 来进行调整

** 注意 **:必须设置为小于1,因为你如果你设置为1的阈值。内存都已经达到了极限了。你在去换页意义不是很大了。
rabbitmq的磁盘预警
参考帮助文档:https://rabbitmq.com/disk-alarms.html
当磁盘的剩余空间低于确定的阈值时,RabbitMQ同样会阻塞生产者,这样可以避免因非持久化的消息持续换页而耗尽磁盘空间导致服务器崩溃。
默认情况下:磁盘预警为50MB的时候会进行预警。表示当前磁盘空间第50MB的时候会阻塞生产者并且停止内存消息换页到磁盘的过程。
这个阈值可以减小,但是不能完全的消除因磁盘耗尽而导致崩溃的可能性。比如在两次磁盘空间的检查空隙内,第一次检查是:60MB ,第二检查可能就是1MB,就会出现警告。
命令修改方式如下
# disk_limit:固定单位 KB MB GB
# fraction :是相对阈值,建议范围在:1.0~2.0之间。(相对于内存)
rabbitmqctl set_disk_free_limit <disk_limit>
rabbitmqctl set_disk_free_limit mem_relative <fraction>
示例:
[root@prome4 ~]# rabbitmqctl set_disk_free_limit 100GB


还原可以重启服务或者重新修改成默认:rabbitmqctl set_disk_free_limit 50MB
配置文件配置如下

日常故障处理
RabbitMQ消息丢失|消息重复|消息积压原因+解决方案+私人使用心得
百度安全验证
两个概念:
RabbitMQ避免消息丢失的方法主要是利用消息确认机制和手动签收机制,所以有必要把这两个概念搞清楚。
消息确认机制
主要是生产者使用的机制,用来确认消息是否被成功消费。
配置如下:
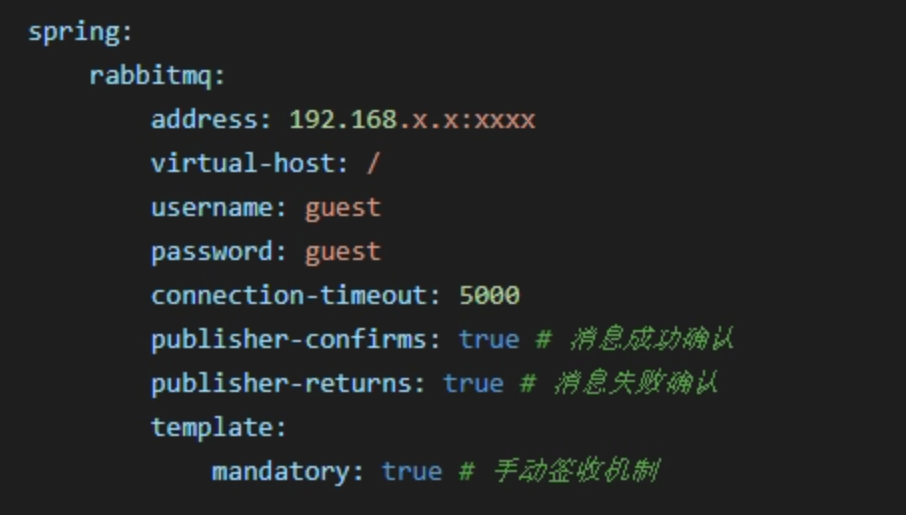
这样,当你实现RabbitTemplate.ConfirmCallback, RabbitTemplate.ReturnCallback这两个接口的方法后,就可以针对性地进行消息确认的日志记录,之后做进一步的消息发送补偿,以达到接近100%投递的目的。
消息签收机制
RabbitMQ的消息是自动签收的,你可以理解为快递签收了,那么这个快递的状态就从发送变为已签收,唯一的区别是快递公司会对物流轨迹有记录,而MQ签收后就从队列中删除了。
企业级开发中,RabbitMQ我们基本都开启手动签收方式,这样可以有效避免消息的丢失。
前文中已经在生产者开启了手动签收机制,那么作为消费方,也要设置手动签收。
配置如下:

消费监听时,手动签收就一行代码,伪代码如下:

消息丢失
两个概念搞清楚后,就可以来学习消息丢失的问题和处理方案了。
1、出现原因
消息丢失的原因无非有三种:
1)消息发出后,中途网络故障,服务器没收到;
2)消息发出后,服务器收到了,还没持久化,服务器宕机;
3)消息发出后,服务器收到了,消费方还未处理业务逻辑,服务却挂掉了,而消息也自动签收,等于啥也没干。
这三种情况,(1) 和 (2)是由于生产方未开启消息确认机制导致,(3)是由于消费方未开启手动签收机制导致。
2、解决方案
1)、生产方发送消息时,要try...catch,在catch中捕获异常,并将MQ发送的关键内容记录到日志表中,日志表中要有消息发送状态,若发送失败,由定时任务定期扫描重发并更新状态;
2)、生产方publisher必须要加入确认回调机制,确认成功发送并签收的消息,如果进入失败回调方法,就修改数据库消息的状态,等待定时任务重发;
3)、消费方要开启手动签收ACK机制,消费成功才将消息移除,失败或因异常情况而尚未处理,就重新入队。
其实这就是前面阐述两个概念时已经讲过的内容,也是接近100%消息投递的企业级方案之一,主要目的就是为了解决消息丢失的问题。
消息重复
1、出现原因
消息重复大体上有两种情况会出现:
1)、消息消费成功,事务已提交,签收时结果服务器宕机或网络原因导致签收失败,消息状态会由unack转变为ready,重新发送给其他消费方;
2)、消息消费失败,由于retry重试机制,重新入队又将消息发送出去。
2、解决方案
网上大体上能搜罗到的方法有三种:
1)、消费方业务接口做好幂等;
2)、消息日志表保存MQ发送时的唯一消息ID,消费方可以根据这个唯一ID进行判断避免消息重复;
3)、消费方的Message对象有个getRedelivered()方法返回Boolean,为TRUE就表示重复发送过来的。
我这里只推荐第一种,业务方法幂等这是最直接有效的方式,(2)还要和数据库产生交互,(3)有可能导致第一次消费失败但第二次消费成功的情况被砍掉。
消息积压
1、出现原因
消息积压出现的场景一般有两种:
1)、消费方的服务挂掉,导致一直无法消费消息;
2)、消费方的服务节点太少,导致消费能力不足,从而出现积压,这种情况极可能就是生产方的流量过大导致。
2、解决方案
1)、既然消费能力不足,那就扩展更多消费节点,提升消费能力;
2)、建立专门的队列消费服务,将消息批量取出并持久化,之后再慢慢消费。
(1)就是最直接的方式,也是消息积压最常用的解决方案,但有些企业考虑到服务器成本压力,会选择第(2)种方案进行迂回,先通过一个独立服务把要消费的消息存起来,比如存到数据库,之后再慢慢处理这些消息即可。
使用心得
这里单独讲一下本人在工作中使用RabbitMQ的一些心得,希望能有所帮助。
1)、消息丢失、消息重复、消息积压三个问题中,实际上主要解决的还是消息丢失,因为大部分公司遇不到消息积压的场景,而稍微有水准的公司核心业务都会解决幂等问题,所以几乎不存在消息重复的可能;
2)、消息丢失的最常见企业级方案之一就是定时任务补偿,因为不论是SOA还是微服务的架构,必然会有分布式任务调度的存在,自然也就成为MQ最直接的补偿方式,如果MQ一定要实现100%投递,这种是最普遍的方案。但我实际上不推荐中小企业使用该方案,因为凭空增加维护成本,而且没有一定规模的项目完全没必要,大家都小看了RabbitMQ本身的性能,比如我们公司,支撑一个三甲医院,也就是三台8核16G服务器的集群,上线至今3年毫无压力;
3)、不要迷信网上和培训机构讲解的生产者消息确认机制,也就是前面两个概念中讲到的ConfirmCallback和ReturnCallback,这种机制十分降低MQ性能,我们团队曾遇到过一次流量高峰期带来的MQ传输及消费性能大幅降低的情况,后来发现是消息确认机制导致,关闭后立马恢复正常,从此以后都不再使用这种机制,MQ运行十分顺畅。同时我们会建立后台管理实现人工补偿,通过识别业务状态判断消费方是否处理了业务逻辑,毕竟这种情况都是少数,性能和运维成本,在这一块我们选择了性能;
4)、我工作这些年使用RabbitMQ没见过自动签收方式,一定是开启手动签收;
5)、手动签收方式你在网上看到的教程几乎都是处理完业务逻辑之后再手动签收,但实际上这种用法是不科学的,在分布式的架构中,MQ用来解耦和转发是非常常见的,如果是支付业务,往往在回调通知中通过MQ转发到其他服务,其他服务如果业务处理不成功,那么手动签收也不执行,这个消息又会入队发给其他消费者,这样就可能在流量洪峰阶段因为偶然的业务处理失败造成堵塞,甚至标题所讲的三种问题同时出现,这样就会得不偿失。
不科学的用法:在处理完业务逻辑后再手动签收,否则不签收,就好比客人进店了你得买东西,否则不让走。
科学的用法:不论业务逻辑是否处理成功,最终都要将消息手动签收,MQ的使命不是保证客人进店了必须消费,不消费就不让走,而是客人能进来就行,哪怕是随便看看也算任务完成。
可能有人会问你这样不是和自动签收没区别吗,NO,你要知道如果自动签收,出现消息丢失你连记录日志的可能都没有。
另外,为什么一定要这么做,因为MQ是中间件,本身就是辅助工具,就是一个滴滴司机,保证给你送到顺便说个再见就行,没必要还下车给你搬东西。
如果强加给MQ过多压力,只会造成本身业务的畸形。我们使用MQ的目的就是解耦和转发,不再做多余的事情,保证MQ本身是流畅的、职责单一的即可。
总结下来就是三点:
1)、消息100%投递会增加运维成本,中小企业视情况使用,非必要不使用;
2)、消息确认机制影响性能,非必要不使用;
3)、消费者先保证消息能签收,业务处理失败可以人工补偿。
工作中怕的永远不是一个技术不会使用,而是遇到问题不知道有什么解决思路。
版权归原作者 char1otte 所有, 如有侵权,请联系我们删除。