
文章目录
一、提出任务
- 分组求TopN是大数据领域常见的需求,主要是根据数据的某一列进行分组,然后将分组后的每一组数据按照指定的列进行排序,最后取每一组的前N行数据。
- 有一组学生成绩数据
张三丰 90
李孟达 85
张三丰 87
王晓云 93
李孟达 65
张三丰 76
王晓云 78
李孟达 60
张三丰 94
王晓云 97
李孟达 88
张三丰 80
王晓云 88
李孟达 82
王晓云 98
- 同一个学生有多门成绩,现需要计算每个学生分数最高的前3个成绩,期望输出结果如下所示:
张三丰:94
张三丰:90
张三丰:87
李孟达:88
李孟达:85
李孟达:82
王晓云:98
王晓云:97
王晓云:93
- 数据表
t_grade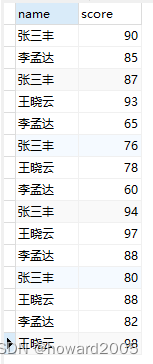
- 执行查询

SELECT*FROM t_grade tg
WHERE(SELECTCOUNT(*)FROM t_grade
WHERE tg.name = t_grade.name
AND score >= tg.score
)<=3ORDERBY name, score DESC;
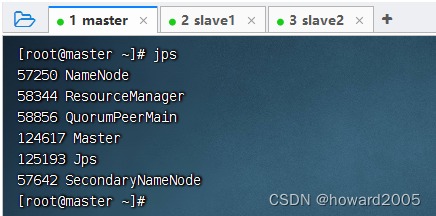
- 预备工作:启动集群的HDFS与Spark
- 将成绩文件 -
grades.txt上传到HDFS上/input目录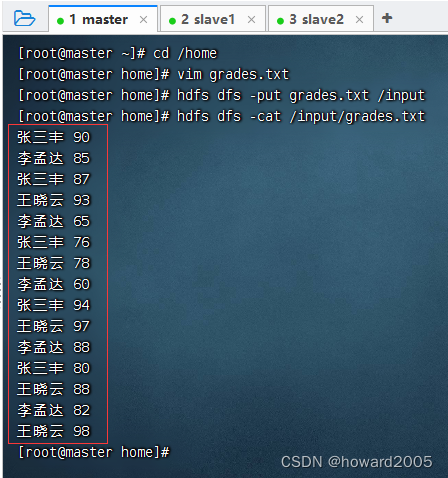
二、涉及知识点
(一)数据集与数据帧
- 参看本博《Spark基础学习笔记23:DataFrame与Dataset》
(二)开窗函数
1、开窗函数概述
- Spark 1.5.x版本以后,在Spark SQL和DataFrame中引入了开窗函数,其中比较常用的开窗函数就是
row_number(),该函数的作用是根据表中字段进行分组,然后根据表中的字段排序;其实就是根据其排序顺序,给组中的每条记录添加一个序号,且每组序号都是从1开始,可利用它这个特性进行分组取topN。
2、开窗函数格式
ROW_NUMBER()OVER (PARTITION BYfield1ORDER BYfield2DESC) rank- 分组求top3的SQL语句

三、完成任务
(一)新建Maven项目
- 设置项目信息(项目名、保存位置、组编号、项目编号)
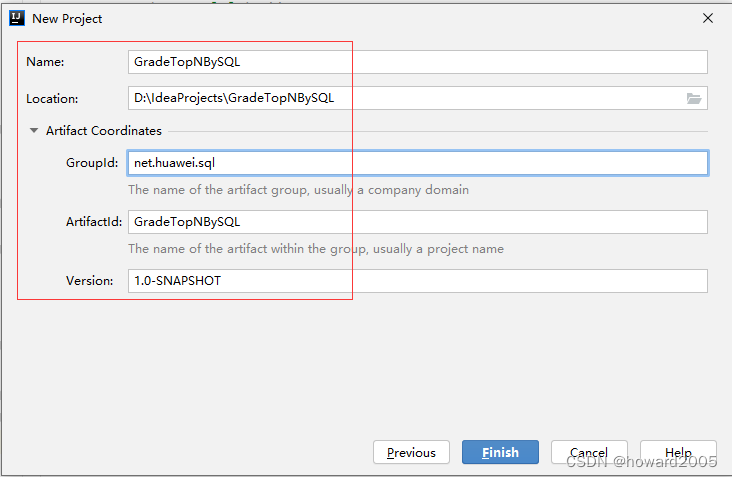
- 单击【Finish】按钮
- 将
java目录改成scala目录
(二)添加相关依赖和构建插件
- 在
pom.xml文件里添加依赖与Maven构建插件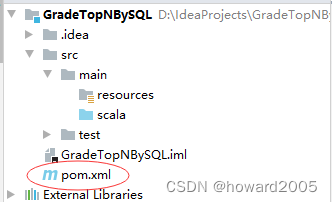
<?xml version="1.0" encoding="UTF-8"?><projectxmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>net.huawei.sql</groupId><artifactId>GradeTopNBySQL</artifactId><version>1.0-SNAPSHOT</version><dependencies><dependency><groupId>org.scala-lang</groupId><artifactId>scala-library</artifactId><version>2.11.12</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.11</artifactId><version>2.1.1</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.11</artifactId><version>2.1.1</version></dependency></dependencies><build><sourceDirectory>src/main/scala</sourceDirectory><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-assembly-plugin</artifactId><version>3.3.0</version><configuration><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin><plugin><groupId>net.alchim31.maven</groupId><artifactId>scala-maven-plugin</artifactId><version>3.3.2</version><executions><execution><id>scala-compile-first</id><phase>process-resources</phase><goals><goal>add-source</goal><goal>compile</goal></goals></execution><execution><id>scala-test-compile</id><phase>process-test-resources</phase><goals><goal>testCompile</goal></goals></execution></executions></plugin></plugins></build></project>
(三)创建日志属性文件
- 在资源文件夹里创建日志属性文件 -
log4j.properties
log4j.rootLogger=ERROR, stdout, logfile
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c]-%m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spark.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c]-%m%n
(四)创建分组排行榜单例对象
- 在
net.huawei.sql包里创建GradeTopNBySQL单例对象
packagenet.huawei.sqlimportorg.apache.spark.sql.{Dataset, SparkSession}/**
* 功能:利用Spark SQL实现分组排行榜
* 作者:华卫
* 日期:2022年06月15日
*/object GradeTopNBySQL {def main(args: Array[String]):Unit={// 创建或得到Spark会话对象val spark = SparkSession.builder().appName("GradeTopNBySQL").master("local[*]").getOrCreate()// 读取HDFS上的成绩文件val lines: Dataset[String]= spark.read.textFile("hdfs://master:9000/input/grades.txt")// 导入隐式转换importspark.implicits._
// 创建成绩数据集val gradeDS: Dataset[Grade]= lines.map(
line =>{val fields = line.split(" ")val name = fields(0)val score = fields(1).toInt
Grade(name, score)})// 将数据集转换成数据帧val df = gradeDS.toDF()// 基于数据帧创建临时表
df.createOrReplaceTempView("t_grade")// 查询临时表,实现分组排行榜val top3 = spark.sql("""
|SELECT name, score FROM
| (SELECT name, score, row_number() OVER (PARTITION BY name ORDER BY score DESC) rank from t_grade) t
| WHERE t.rank <= 3
|""".stripMargin
)// 显示分组排行榜结果
top3.show()// 按指定格式输出分组排行榜
top3.foreach(row => println(row(0)+": "+ row(1)))// 关闭Spark会话
spark.close()}// 定义成绩样例类caseclass Grade(name:String, score:Int)}
(五)本地运行程序,查看结果
- 在控制台查看输出结果
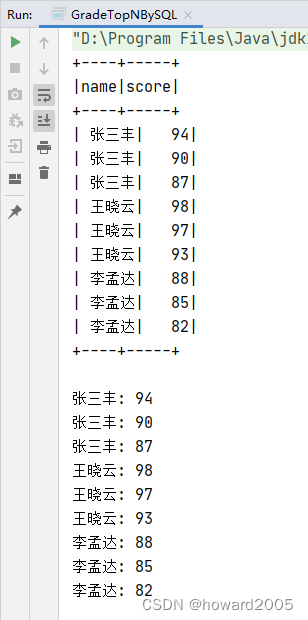
(六)交互式操作查看中间结果
1、读取成绩文件得到数据集
- 执行命令:
val lines: Dataset[String] = spark.read.textFile("hdfs://master:9000/input/grades.txt")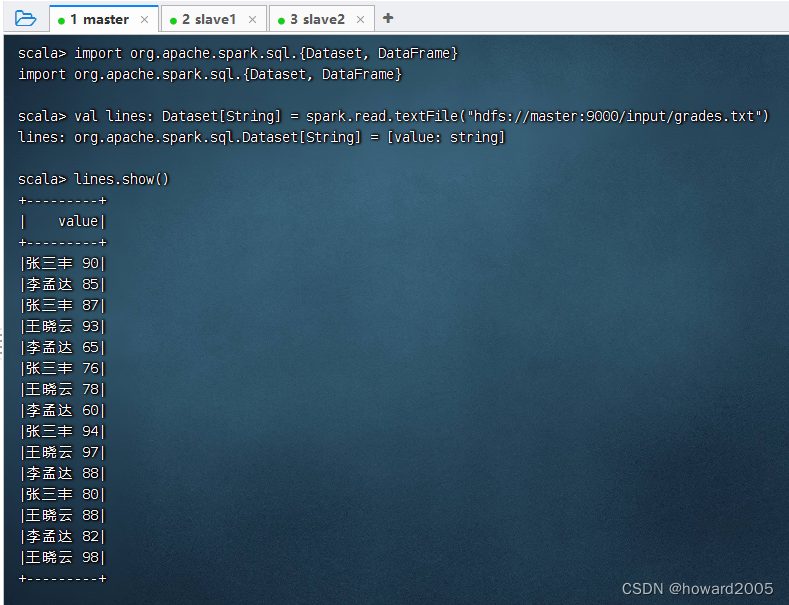
2、定义成绩样例类
- 执行命令:
case class Grade(name: String, score: Int)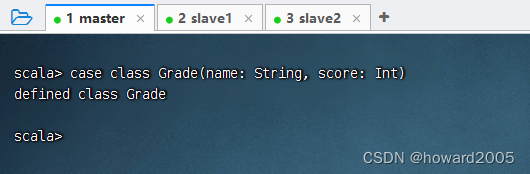
3、导入隐式转换
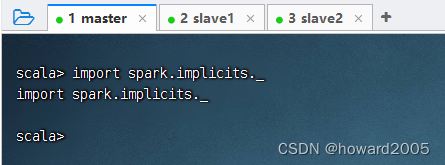
4、创建成绩数据集
val gradeDS: Dataset[Grade]= lines.map(
line =>{val fields = line.split(" ")val name = fields(0)val score = fields(1).toInt
Grade(name, score)})
- 执行上述语句
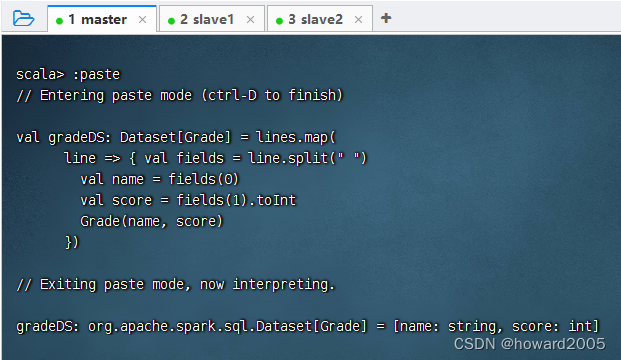
5、将数据集转换成数据帧
- 执行命令:
val df = gradeDS.toDF()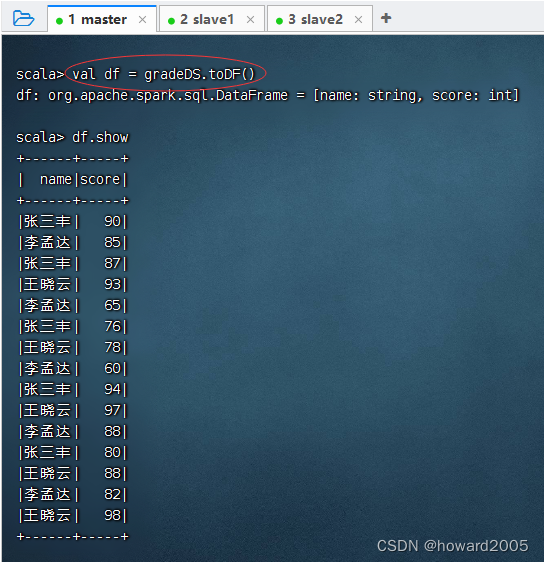
6、基于数据帧创建临时表
- 执行命令:
df.createOrReplaceTempView("t_grade")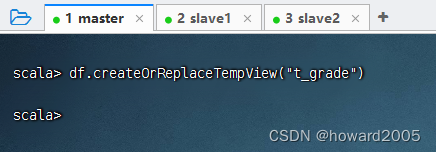
7、查询临时表,实现分组排行榜
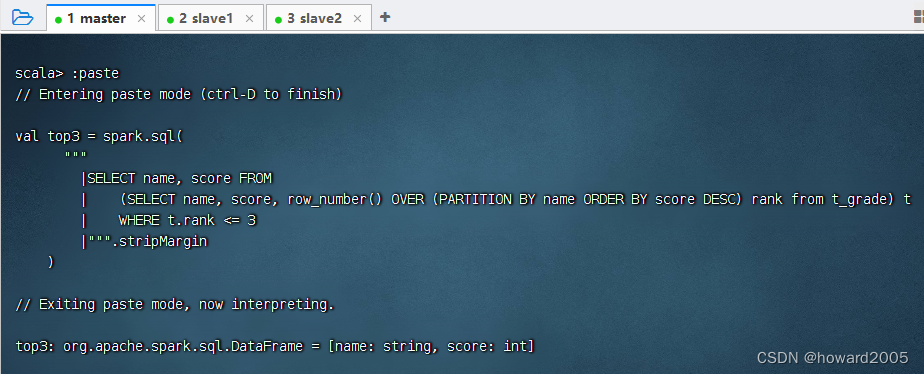
val top3 = spark.sql("""
|SELECT name, score FROM
| (SELECT name, score, row_number() OVER (PARTITION BY name ORDER BY score DESC) rank from t_grade) t
| WHERE t.rank <= 3
|""".stripMargin
)
- 执行上述语句
8、显示分组排行榜结果
- 执行命令:
top3.show()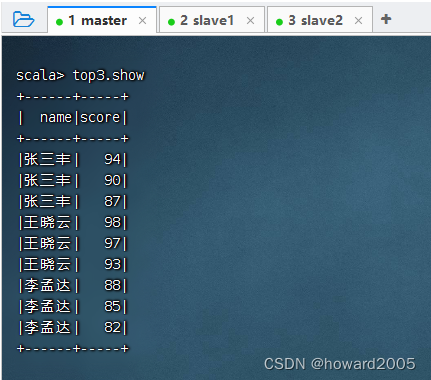
四、可能会出现的问题
- MySQL支持这样的子查询
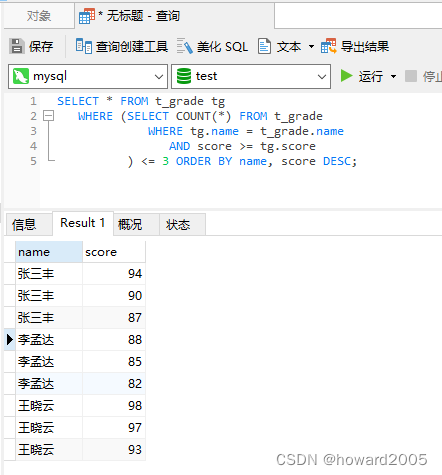
- 但是Spark SQL不支持,会抛出异常
AnalysisException: Correlated column is not allowed in a non-equality predicate。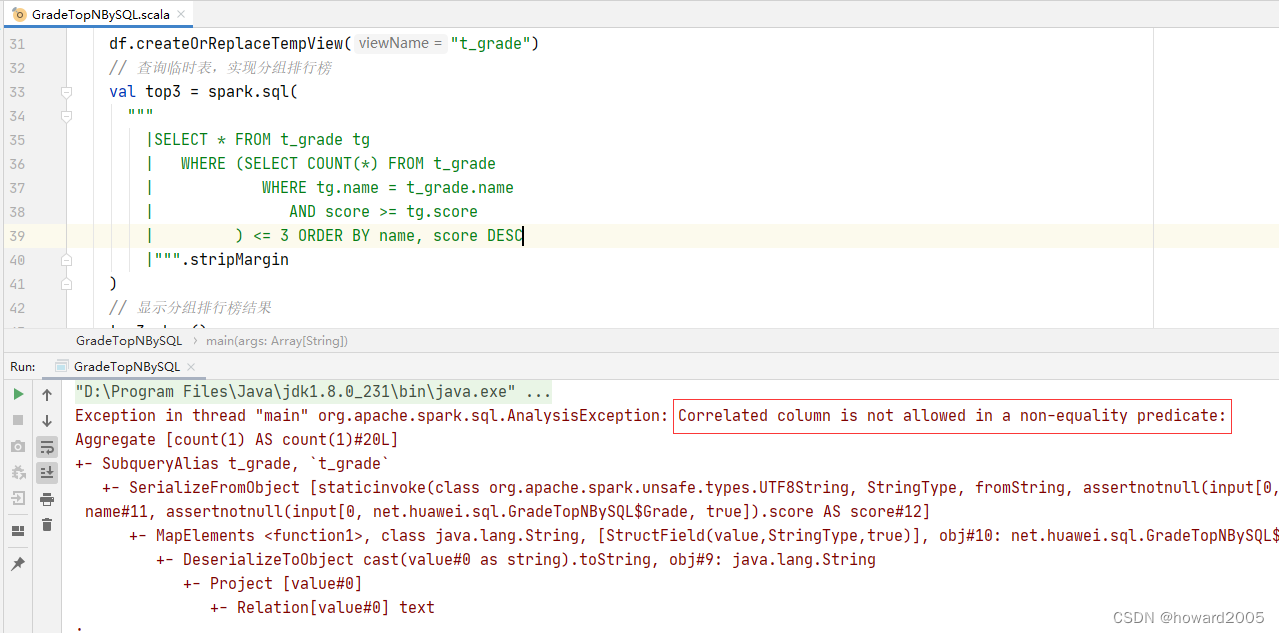
本文转载自: https://blog.csdn.net/howard2005/article/details/125303513
版权归原作者 howard2005 所有, 如有侵权,请联系我们删除。
版权归原作者 howard2005 所有, 如有侵权,请联系我们删除。