
1.redis持久化RDB、AOF
RDB(Redis database)
在当前redis目录下生成一个dump.rdb文件,对redis数据进行备份

常用save、bgsave命令进行数据备份:
- save命令会阻塞其他redis命令,不会消耗额外的内存,与IO线程同步;
- bgsave命令不会阻塞其他redis命令,会耗额外内存,与IO线程异步;
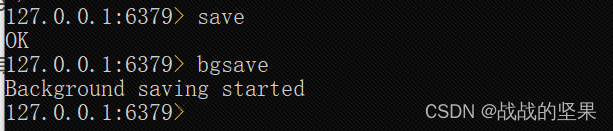
bgsave命令是由主线程衍生出来的一个子进程,该子进程可以获取主线程的全部内存数据。若在执行bgsave命令时,还有其他redis命令被执行(主线程数据修改),此时会对数据做个副本,然后bgsave命令执行这个副本数据写入rdb文件,此时主线程还可以继续修改数据。
配置自动生成rdb文件的后台使用bgsave命令
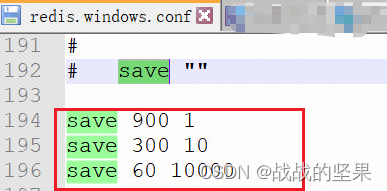
AOF(append-only-file)
在当前redis目录下会生成aof文件,对redis修改数据的命令进行备份

开启aof方式,并配置aof文件名字
redis命令与AOF文件内容
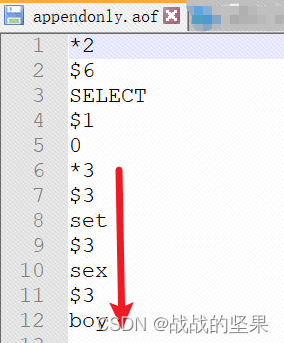
操作redis,命令如下
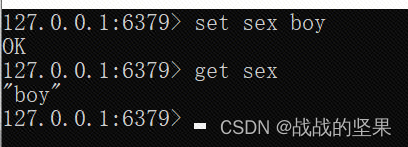
可以看到aof文件内容,记录修改数据命令
为一条命令的开始,后面的数字为命令的参数个数,$及数字表示该命令的参数长度
配置redis多久将命令执行到aof文件中
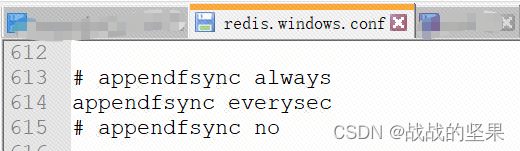
- appendfsync always:每次有新命令就会追加aof文件中
- appendfsync everysec:每秒追加到aof文件中,所以可能会丢失一秒钟的数据(默认)
- appendfsync no:不追加,将数据交给操作系统来负责
AOF重写:定期根据内存的最新数据生成aof文件
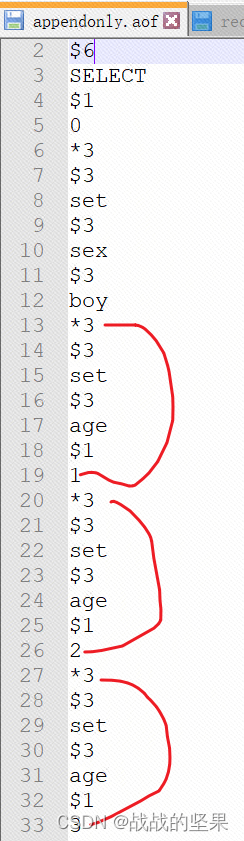
由于一些命令一直在修改同一个key的信息,所以有时可以合并为一条命令。例如 set age 1 ->set age 2 ->set age 3,此时可以直接在aof文件写set age 3这一条命令即可。
对应aof文件:
手动重写命令:bgrewriteaof

对应aof文件:

配置自动重写的条件:
- auto-aof-rewrite-percentage 100: 当aof文件比上一次重写大了100%,触发重写机制
- auto-aof-rewrite-min-size 64mb:当aof文件大小超过64M,触发重写机制

RDB、AOF区别
- 由于RDB文件体积小(二进制文件),所以恢复数据速度快;相对AOF文件体积大(命令存储),所以恢复数据速度慢
- RDB比AOF文件可能丢失数据(RDB是通过save命令设置持久化,所以可能会丢失很多数据;而AOF可能会丢失一秒的数据),相对数据安全,所以一般数据恢复时系统默认使用AOF方式
混合持久化
redis4后可以将RDB、AOF混合使用,速度很快
- 混合持久化设置启用 aof-use-rdb-preamble yes,AOF也需要开启,RDB配置可去掉(save命令)
- redis数据重写时AOF文件以二进制形式(RDB)存储+增量AOF数据继续以命令存储
- 考虑redis性能时,无论什么架构,一般对master节点不进行持久化,对slave节点进行AOF持久化
- 若对master节点不进行持久化,那么不建议运维自动重启master节点,因为重启master节点,数据未做持久化,是个空实例,最后主从同步会导致数据全部丢失。所以建议哨兵模式,哨兵自己判断去重启某个节点
2.缓存击穿、缓存穿透、缓存雪崩
缓存击穿(缓存失效)
某一时刻热点key过期了,同时有大量请求过来,出现查询不到redis数据,都去查询数据库,造成数据库的压力瞬间过大问题;重点是缓存key失效(Redis不存在,数据库存在)
解决办法:
对redis的过期时间设置成不一样
对读取数据库后写入Redis这步骤加个锁,防止并发
缓存穿透
某一时刻大批量不存在的key请求过来,出现查询不到redis数据,都去查询数据库,造成数据库的压力瞬间过大问题;重点是不存在的数据(Redis不存在,数据库也不存在)
解决办法:
参数校验
当数据库也查询不到数据时,给个默认空字符串并设置过期时间,然后在查询redis时数据不为空,对空字符串数据进行判断,伪代码如下:
public String get(String pid) {
//1.查询Redis数据
String redisInfo = redis.get(pid);
if (StringUtils.isNotEmpty(redisInfo)) {
//1.1Redis数据为空字符串,读缓存延长
if ("{}".equals(redisInfo)) {
redis.expire(pid, 1000, TimeUnit.SECONDS);
}
//1.2Redis数据不为空字符串,也读缓存延长
redis.expire(pid, 24 * 60 * 60, TimeUnit.SECONDS);
return redisInfo;
}
//2.查询数据库
String daoInfo = dao.get(pid);
if (StringUtils.isNotEmpty(daoInfo)) {
//2.1数据库查询到数据,并添加缓存到redis
redis.set(pid, daoInfo, 24 * 60 * 60, TimeUnit.SECONDS);
return redisInfo;
} else {
//2.2数据库查询不到数据,缓存到redis为空字符串
redis.set(pid, "{}", 1000, TimeUnit.SECONDS);
}
return daoInfo;
}
布隆过滤器 在访问Redis前判断
缓存雪崩
某一时刻大批量的过期key查询Redis查不到,后查询数据库,造成数据库挂掉;重点是大批量不同的过期key
解决办法:
Redisson分布式锁
使用分布式锁对商品ID进行控制,因为Redis的执行操作是单线程的,无论哪台服务器,最后都要执行到Redis;若不使用Redisson,而是用synchronized(this),此时会造成对服务器的加锁,若开始大量查询ID为1的商品,每台机器都会先跑一遍加个锁,然后在查询ID为2的数据,此时需要等待ID为1的锁释放,所以需要将this对象调整为全局商品ID。
使用Redis分布式锁+二级缓存(Map<String,Object>)解决
public String get(String pid) {
//1.查询Redis数据
String redisInfo = redis.get(pid);
if (StringUtils.isNotEmpty(redisInfo)) {
//1.1Redis数据为空字符串,读缓存延长
if ("{}".equals(redisInfo)) {
redis.expire(pid, 1000, TimeUnit.SECONDS);
}
//1.2Redis数据不为空字符串,也读缓存延长
redis.expire(pid, 24 * 60 * 60, TimeUnit.SECONDS);
return redisInfo;
}
//2.获取Redis分布式锁
RLock hotLock = redissonClient.getLock("lock:"+pid);
hotLock.lock();
try {
//3.重新查询缓存
redisInfo = redis.get(pid);
if (StringUtils.isNotEmpty(redisInfo)) {
if ("{}".equals(redisInfo)) {
redis.expire(pid, 1000, TimeUnit.SECONDS);
}
redis.expire(pid, 24 * 60 * 60, TimeUnit.SECONDS);
return redisInfo;
}
//4.查询数据库
String daoInfo = dao.get(pid);
if (StringUtils.isNotEmpty(daoInfo)) {
//4.1数据库查询到数据,并添加缓存到redis
redis.set(pid, daoInfo, 24 * 60 * 60, TimeUnit.SECONDS);
return redisInfo;
} else {
//4.2数据库查询不到数据,缓存到redis为空字符串
redis.set(pid, "{}", 1000, TimeUnit.SECONDS);
}
}finally {
hotLock.unlock(); //释放锁
}
return daoInfo;
}
key的过期时间设置随机数,防止同时过期
3.redis分布式锁
TODO
**4.redis主从同步机制 **
配置文件中从节点需要记录主节点的ip及端口号信息。主从数据复制时,若是master节点下面有很多slave节点,在某一时刻同时让master节点发送RDB文件给slave节点,会造成主节点压力过大,形成主从复制风暴问题。可以调整为从节点复制从节点的树形复制。
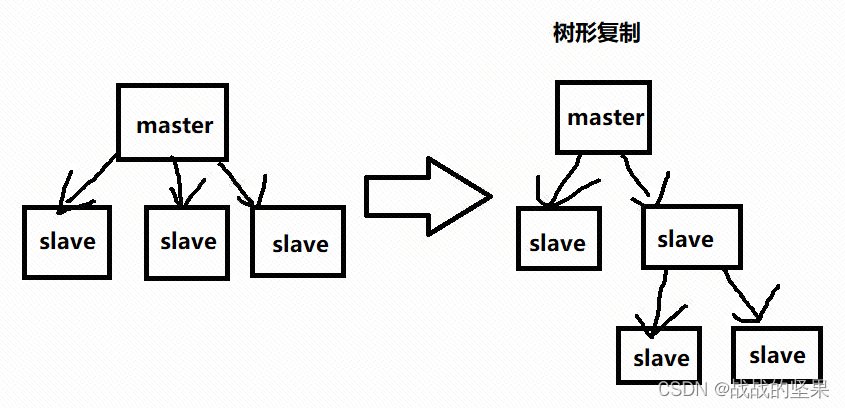
主从复制有全量复制和增量复制
全量复制
- bgsave命令,主线程衍生一个子进程,将持久化RDB文件通过网络传输给从节点
- 从节点先删除旧数据,然后重新载入RDB文件(此过程是阻塞的)
增量复制
- 偏移量:主从节点都存储一个偏移量,用于记录增量的offset
- 复制积压缓冲区:复制到持久化RDB文件之前有个积压缓冲区,这样主从复制速度快些
- 服务器运行ID:每个节点启动时自动生成一个服务器运行ID,然后主从节点都会互相发送并存储这个ID,每次增量复制会判断运行ID,若与之前存储的ID不同,则需要全量复制;否则增量复制
5.redis数据备份
数据备份模式一般都是大同小异的(无论是redis还是日志等其他文件数据)
- 对RDB文件或AOF文件进行定时备份到另一台机器中,保留72小时的备份(时间以项目情况为准)
- 每天保留一份数据进行备份到另一个目录,保留一个月的备份(时间以项目情况为准)
- 每次备份时需要将之前的旧数据删除掉
6.redis在电商的使用
- 一般数据量电商项目中,新增/修改接口都会先入数据库,后将该数据放到redis缓存中[set(key,value)];在查询该商品时,先去redis缓存中读取,若未查询到再去数据库中获取,否则直接返回缓存数据;
- 海量数据的电商项目中,新增/修改接口在操作redis缓存时,需要给个过期时间[set(key,value,time,unit)];在查询该商品时,从redis缓存读取后,需要将该商品的redis缓存过期时间延长。这样可以实现缓存数据的冷热分离。因为数据的访问量不同,加个过期时间可提高效率
- 查询接口中当查询数据库时有写操作(修改接口)进来,导致数据库与Redis数据不一致,此时Redis分布式锁有读写锁,需要在读数据库前补充读锁,修改操作补充写锁
- 布隆过滤器:int[10]共4810=320个字节的位图,用于在查询Redis判断是否存在该数据,若不存在,则直接返回不存在该数据;存在则继续查询Redis;

版权归原作者 战战的坚果 所有, 如有侵权,请联系我们删除。