
在本教程中,我们将展示如何使用 Selenium 爬取网页中的视频 URL。我们将以快手短视频页面为例,演示如何自动化浏览器操作,等待页面加载完成后,获取视频元素的 URL 并打印出来。
使用python爬取快手视频URL.py资源-CSDN文库https://download.csdn.net/download/m0_74972192/89578924
前提条件
在开始之前,请确保你已经安装了以下工具和库:
- Python:确保你已经安装了 Python。
- Selenium:可以通过
pip install selenium安装。 - ChromeDriver:确保你已经下载并安装了 ChromeDriver,并将其路径添加到系统环境变量中。
步骤 1:设置 WebDriver
首先,我们需要设置 WebDriver。为了在无头模式下运行 Chrome 浏览器,我们需要添加一些选项。这些选项包括
--headless
(无头模式)、
--disable-gpu
(禁用 GPU 加速)、
--no-sandbox
(禁用沙盒模式)和
--disable-dev-shm-usage
(禁用共享内存)。
步骤 2:打开目标网页
接下来,我们将使用 Selenium 打开目标网页。在本例中,我们将打开一个快手短视频页面。你需要将 URL 替换为实际的网页 URL。
步骤 3:等待视频元素加载完成
我们需要等待视频元素加载完成。为此,我们将使用
WebDriverWait
和
expected_conditions
模块。
WebDriverWait
将等待指定的时间,直到条件满足。
expected_conditions
模块提供了一些常用的条件,如元素是否存在、元素是否可见等。
步骤 4:获取视频的 URL
一旦视频元素加载完成,我们可以获取视频的 URL 并打印出来。我们将使用
get_attribute
方法获取视频元素的
src
属性。
步骤 5:关闭浏览器
最后,我们需要关闭浏览器以释放资源。我们将使用
quit
方法关闭浏览器。
在网页中搜索王者:
点击其中一个视频 将视频的链接复制下来 输入到程序中即可获取视频链接
 运行结果:
运行结果: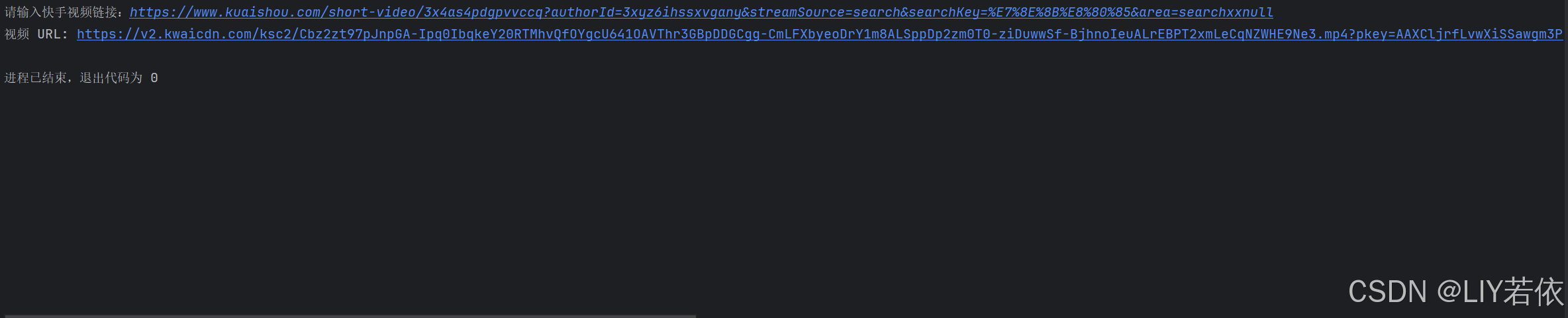
代码解析
- 导入必要的模块:- 导入 Selenium 的 WebDriver 和相关模块,包括
webdriver、By、WebDriverWait和expected_conditions。- 导入Options模块以设置 Chrome 浏览器的选项。 - 设置 WebDriver:- 创建一个
Options对象,并添加无头模式、禁用 GPU 加速、禁用沙盒模式和禁用共享内存的选项。- 使用这些选项初始化 Chrome WebDriver。 - 打开目标网页:- 使用
get方法打开目标网页。你需要将 URL 替换为实际的网页 URL。 - 等待视频元素加载完成:- 使用
WebDriverWait等待视频元素加载完成,最多等待 10 秒。- 使用presence_of_element_located条件检查视频元素是否存在。 - 获取视频的 URL:- 使用
get_attribute方法获取视频元素的src属性,即视频的 URL,并打印出来。 - 处理异常和关闭浏览器:- 使用
try-except-finally结构处理可能发生的异常,并在操作完成后关闭浏览器。
通过以上步骤,你可以使用 Selenium 爬取快手的视频 URL。希望这个教程对你有帮助!如果你有任何问题或需要进一步的帮助,请告诉我。 😊
本文转载自: https://blog.csdn.net/m0_74972192/article/details/140689726
版权归原作者 LIY若依 所有, 如有侵权,请联系我们删除。
版权归原作者 LIY若依 所有, 如有侵权,请联系我们删除。