
最近的项目中有用到Flink Oracle CDC实时到监听数据库变化,将变化的数据sink到Kafka。Oracle CDC依赖Debezium组件解析Redo Log与Archive Log,Debezium 通过Oracle 的Logminer解析Log。在我们生产环境遇到
运行一段时间后,再也查询不到数据,直到报miss log file异常(线上环境cron job 将一小时前的archvied log压缩生成gzip文件),Flink job运行失败。
日志量比较大的时候,延迟非常大,每小时archived log size超过60G时延迟去到小时级别。
分析问题前,先简单介绍下Oracle LogMiner流程,
- start log miner
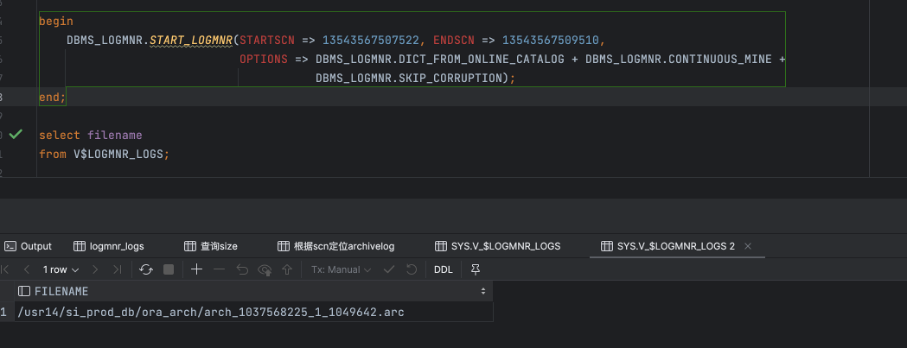
begin
DBMS_LOGMNR.START_LOGMNR(STARTSCN => scn, ENDSCN => end scn,
OPTIONS => DBMS_LOGMNR.DICT_FROM_ONLINE_CATALOG + DBMS_LOGMNR.CONTINUOUS_MINE +
DBMS_LOGMNR.SKIP_CORRUPTION);
end;
Start LogMiner,添加scn 对应的日志文件到待解析列表
参数说明:
start scn:scn = start scn + 1, LogMiner 根据scn定位对应的日志文件,日志文件分为redo log与archived log,每个日志文件对应数据一条记录,其中 first_change#(这个日志文件最小的scn 值),next_change# (下一个日志文件的开始scn值)。[first_change#,next_change#)前闭后开。
下一个日志文件的 first_change#与上一个的日志文件的next_change# 值相等。
LogMiner 根据scn处在[first_change#,next_change#)区间定位到日志文件(redo
log或者archvied log文件)。
日志文件包含很多block。每个block会有对应的start scn索引信息,方便我们根据scn 定位要解析的日志块,因此LogMiner就可以只解析少量的日志块,而不是整个日志文件(这块非常类似于HBase基于rowid查询数据逻辑)。
end scn: LogMiner解析到end scn定位等日志块。
CONTINUOUS_MINE: 自动添加对应的日志文件到待解析列表
Redo LOG:
select *
from v$log
where first_change# <= scn and next_change# > scn;
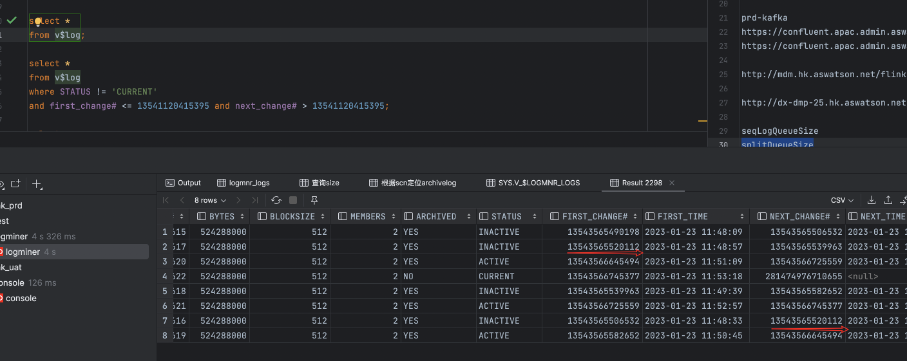
Archvied LOG:
select *
from v$archived_log A
where first_change# <= scn and next_change# > scn
AND A.ARCHIVED = 'YES' AND A.STATUS = 'A' ;
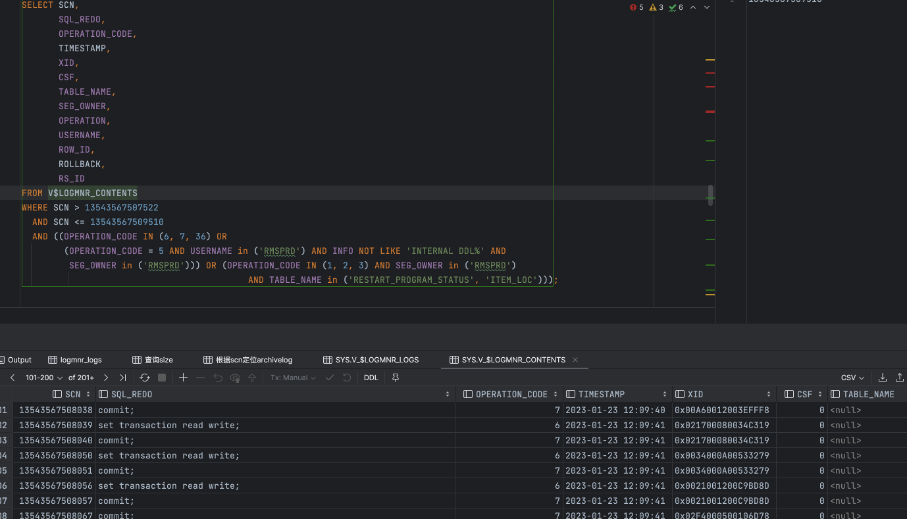
- 查询V$LOGMNR_CONTENTS触发LogMiner解析
SELECT SCN,
SQL_REDO,
OPERATION_CODE,
TIMESTAMP,
XID,
CSF,
TABLE_NAME,
SEG_OWNER,
OPERATION,
USERNAME,
ROW_ID,
ROLLBACK,
RS_ID
FROM V$LOGMNR_CONTENTS
WHERE SCN > start scn
AND SCN <= end scn
AND ((OPERATION_CODE IN (6, 7, 36) OR
(OPERATION_CODE = 5 AND USERNAME in ('RMSPRD') AND INFO NOT LIKE 'INTERNAL DDL%' AND
SEG_OWNER in ('Schema'))) OR (OPERATION_CODE IN (1, 2, 3) AND SEG_OWNER in ('RMSPRD')
AND TABLE_NAME in ('table_name')));
参数说明:
OPERATION_CODE:
public static final int INSERT = 1;
public static final int DELETE = 2;
public static final int UPDATE = 3;
public static final int DDL = 5;
public static final int ROLLBACK = 36;
查询数据:
事物:开启,提交,回滚事物
DDL:监听的schema与table的DDL操作事件
数据操作:监听的table的数据变化(增加,删除,修改,save point 记录回滚。save point记录回滚,回滚的每条记录都会有一条记录,OPERATION_CODE与正向的操作一样,只是ROLLBACK=1)。
start scn 上次一次返回的数据的最后记录的scn值(last processed scn),再继续查询。
问题一,因为start scn是上次一次返回的数据的最后记录的scn值(last processed scn),仅查询我们监听表的事件;end scn是会根据一定规则进行计算,end scn与 start scn最大区间默认不超过50w,超过50w后end scn不再继续增加。在我们线上有遇到50w的区间查不到数据,我们也尝试增大到500w,同样也有查不到数据情况,因为没有查到数据,start scn不会往前递进,而且end scn与start scn range已经达到配置到最大值,end scn也不会往前递进,这样就会一直查询这范围的数据,而且一直没有我们需要的数据,直到logminer 报miss log file异常。
为啥start scn是取上次一次返回的数据的最后记录的scn值(last processed scn)而不是上一次的end scn值,代码中注释如下:
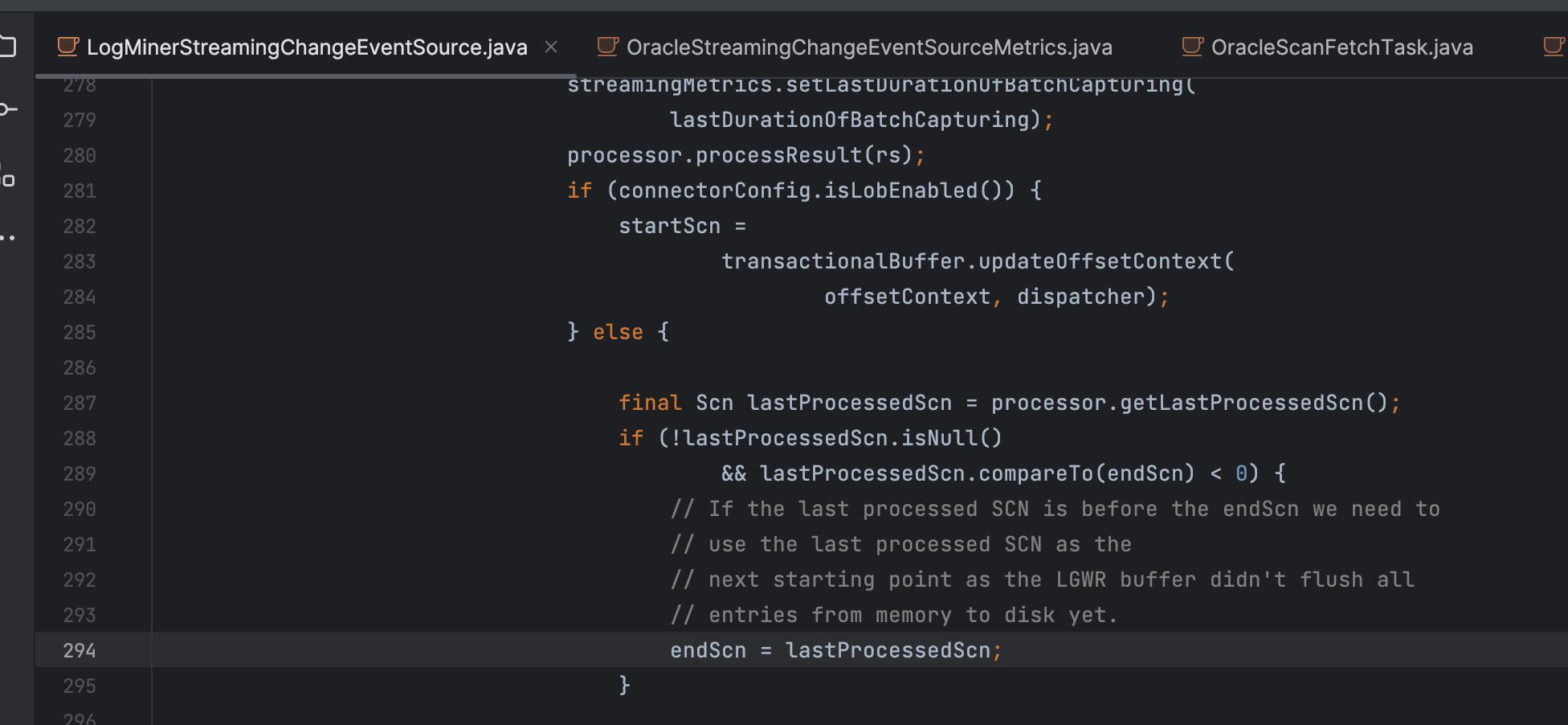
大概就是说LGWR写缓存的数据还没有刷新到日志文件,logminer没有查询到数据,并不能说明当前range真的是没有数据返回,有可能到end scn的事件还没有被刷新到日志文件,下一次查询可能返回我们需要的数据。
修复如下:
如果对应scn 范围的文件是archived log文件,查询没有数据返回了,就表明这范围内没有我们需要的数据,start scn = end scn;
如果对应scn 范围的文件是redo log文件,且当的文件正在写入,查询没有数据返回了,不能说明明这范围内没有我们需要的数据,有可能LGBR还没有刷新到文件中,我们需要修改start scn 上次一次返回的数据的最后记录的scn值(last processed scn),再继续查询,直到end scn对应的日志文件不是当前写入状态,或者对应的日志文件被 archive。
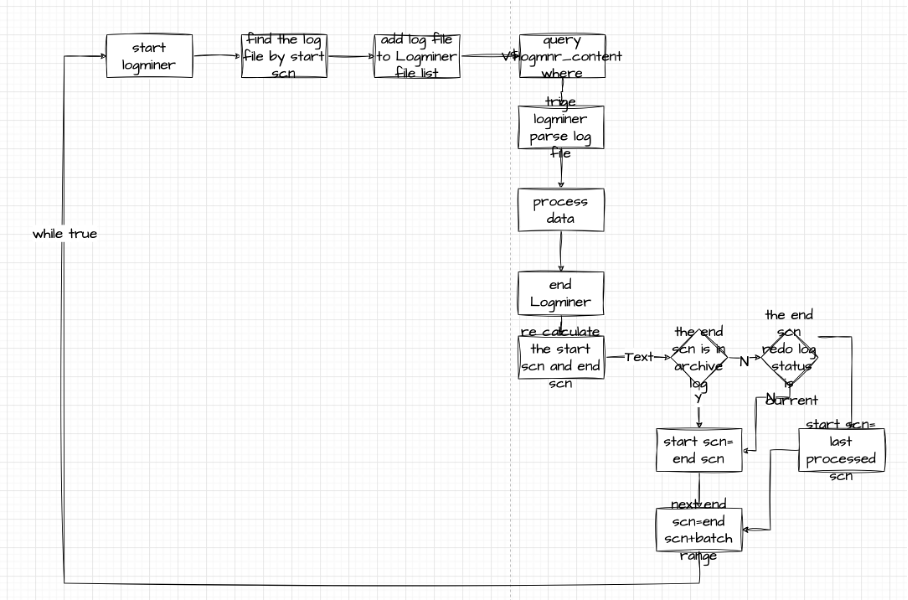
问题二:日志太大,logminer性能问题
LogMiner 最大的问题在于其性能, 他运行在 Oracle 内部, 并且运行在日志落地之后, 不可避免地需要消耗数据库的算力去完成工作, 为了降低这个不在主流程的进程的资源消耗, Oracle 对 LogMiner 做了非常严格的资源限制, 每个 LogMiner 进程, 他的资源消耗都不能超过 1 个 cpu 核心, 在大多数场景下, 这个将 LogMiner 的日志解析速度限制在 1w 条每秒以下, 在一些严肃的场合, 这个速度是远远不够的, Oracle 是一个事务数据库, 一个大的Update, 可能会带来数十万上百万的更新, 在这种情况下, 每秒 1w 的解析速度会使得下游延迟增大到数分钟级别, 更糟糕的是, 在数据库本身负载较高的情况下, 由于 LogMiner 的解析与数据库共享负载, 会让解析速度进一步下降。
在工程上, 这个问题也有办法可以解决, LogMiner 本质上只是一个日志解析工具, 如果开发者在外部自己管理LogMiner 进程, 将不同的日志通过不同的 LogMiner 进程并行解析, 理论上可以通过消耗更多的 CPU, 来实现更快的解析, 但是这个也导致了数据库的资源被进一步消耗, 最终速度是否达到预期并不是想当然的事情。
为了解决 LogMiner 与数据库争夺资源的问题, 还有一个异步解析的方案, 首先通过 Oracle 的机制, 将 redo log 异步传输到另外一台没有业务压力的 Oracle 实例上, 然后在另外一台机器上开启并发解析。
并发LogMiner解析方案:
主要分为三模块,
模块一:一个线程负责scn range 切分
模块二:获取切分的scn range,开启LogMiner线程并发的解析对应scn range 事件
模块三:顺序的处理获取到的事件
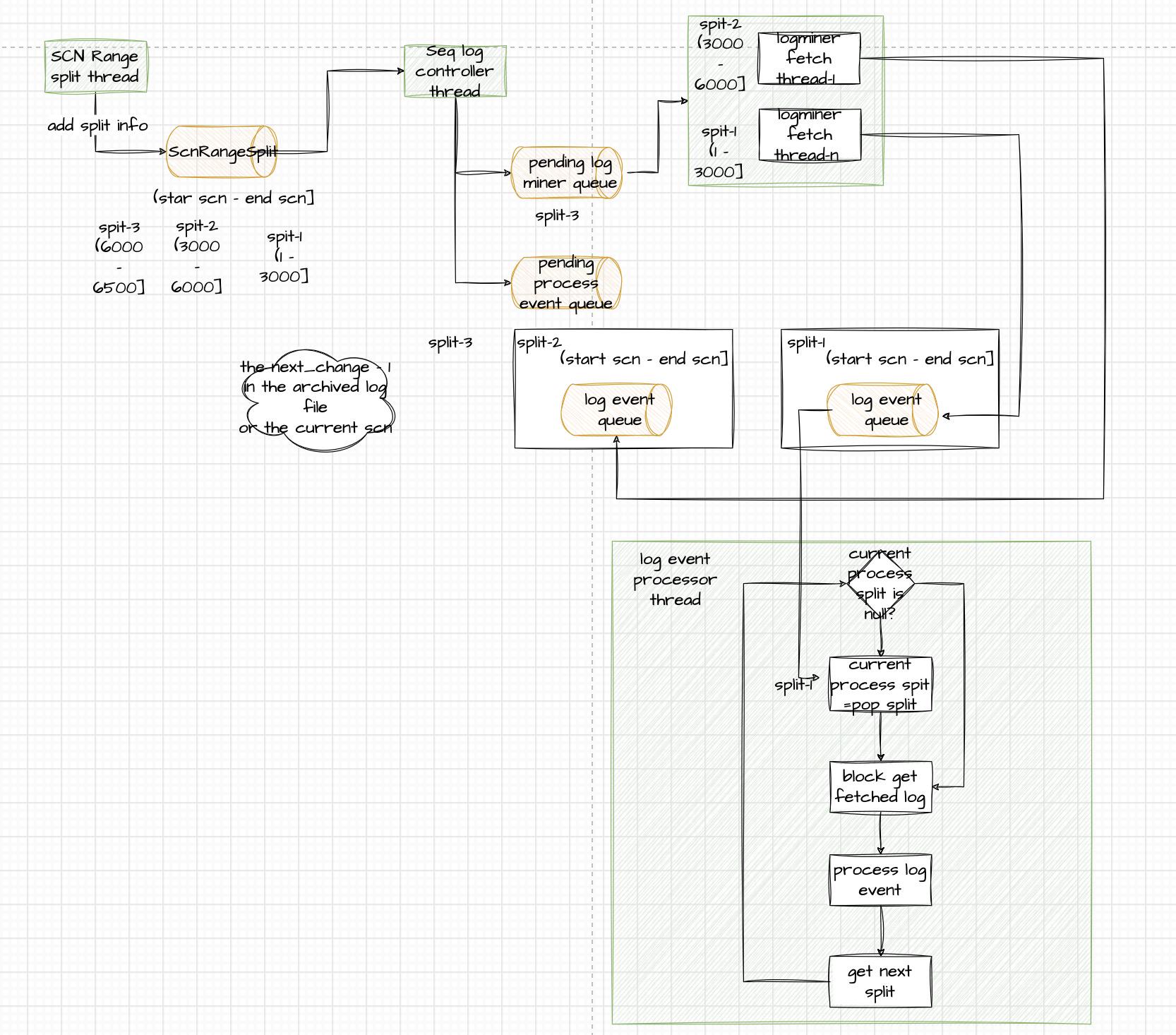
流程描述:
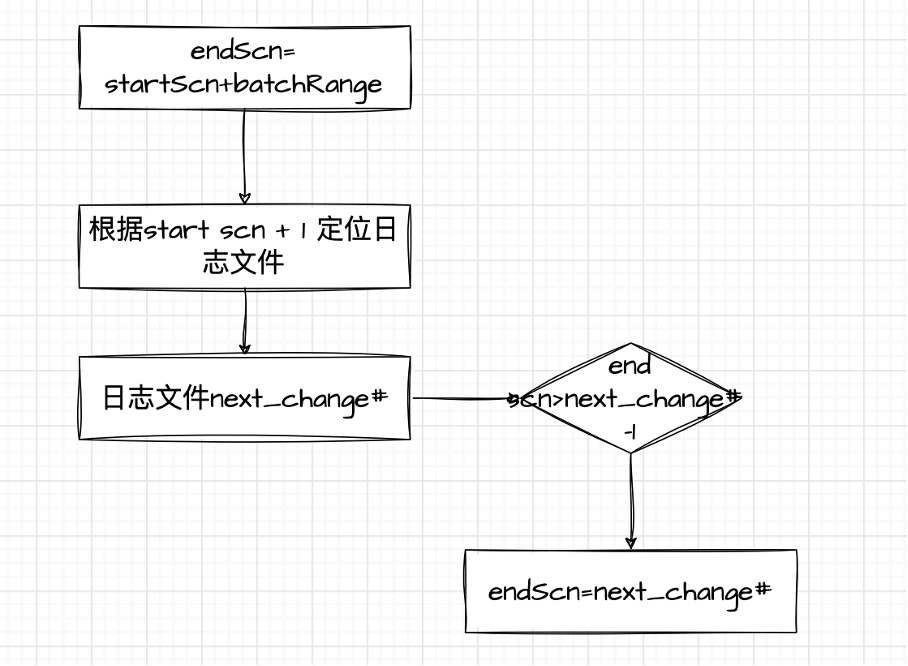
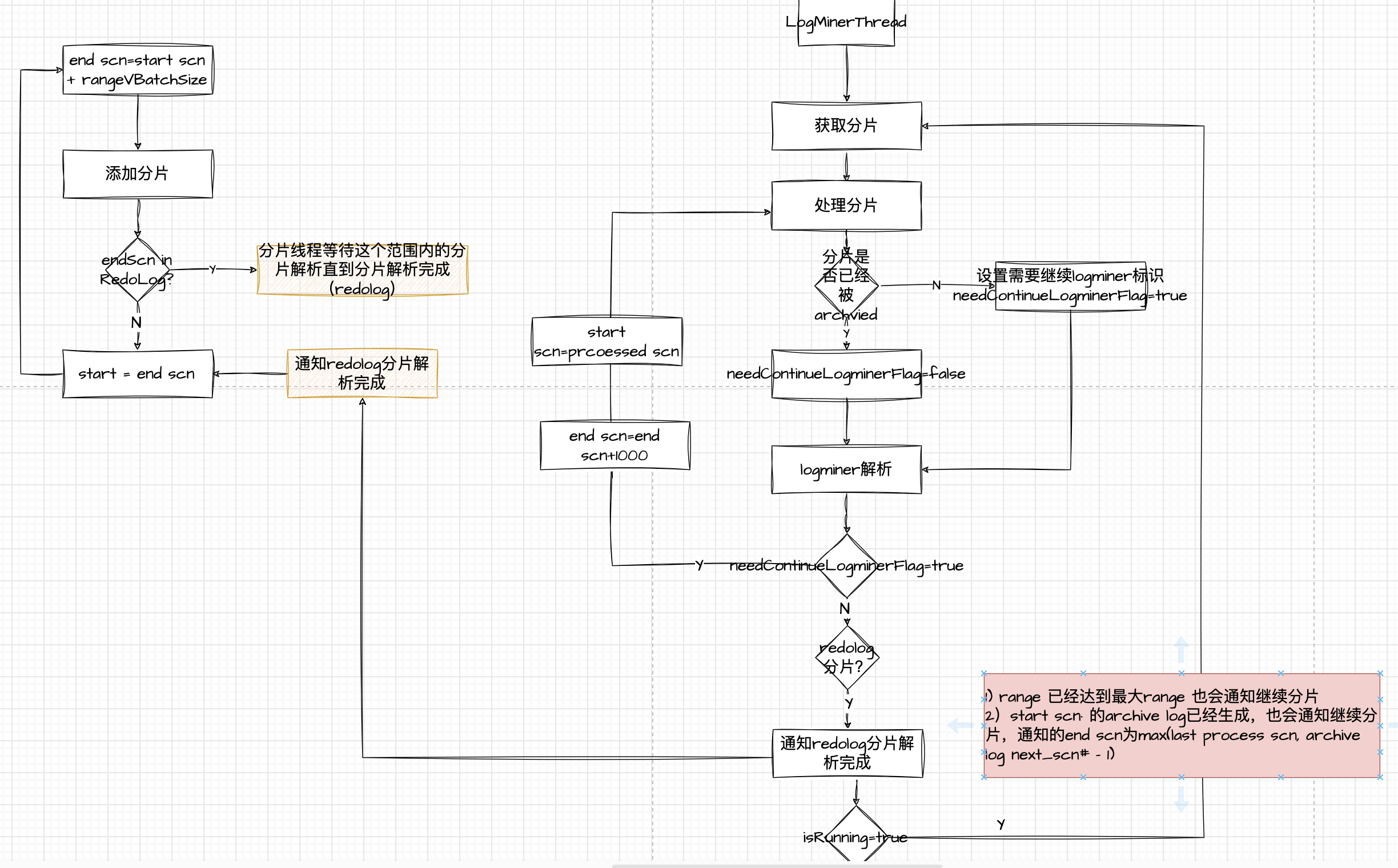
- scn range 切分线程
scn range,(start scn-end scn],end scn = start scn + batch range,根据scn = start scn + 1 定位日志文件,如果end scn > 这个日志文件的next_change-1, end scn=next_change-1
- 顺序log 处理控制线程
获取切换分的scn range对象,添加到待LogMiner解析队列,同时也添加到待处理的log队列
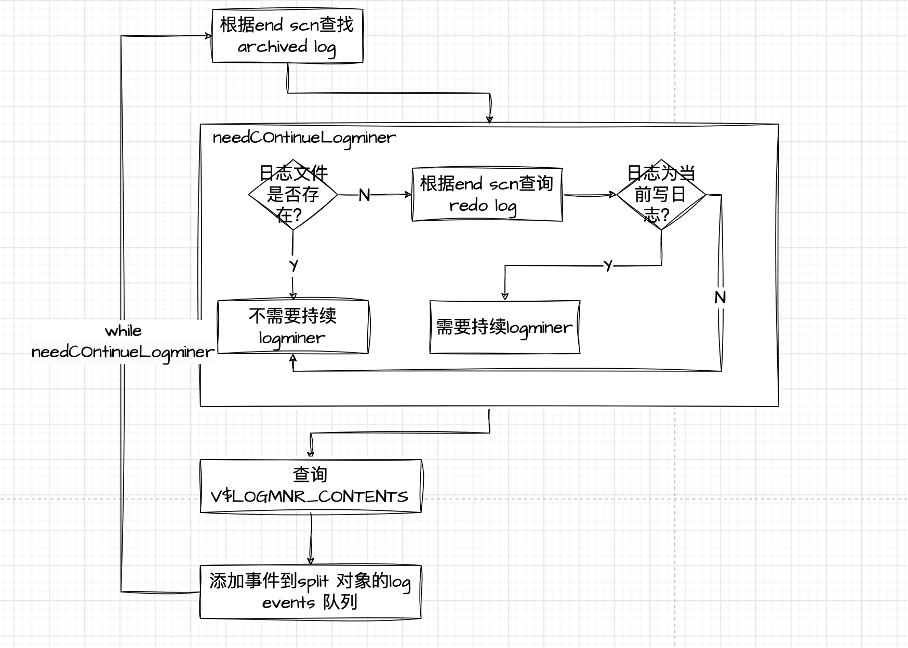
- LogMiner线程池
获取待LogMiner队列的数据,LogMiner线程获取分片的startScn, endScn,开启LogMiner,判断是否需要持续LogMiner,查询V$LOGMNR_CONTENTS数据
- LOG event 处理线程
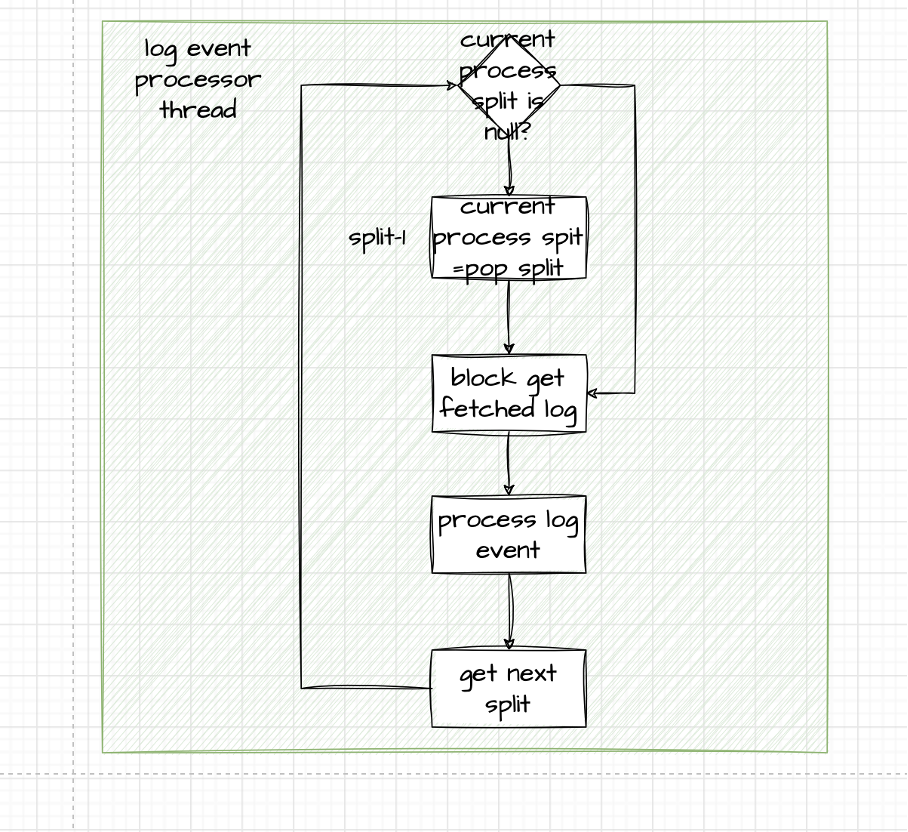
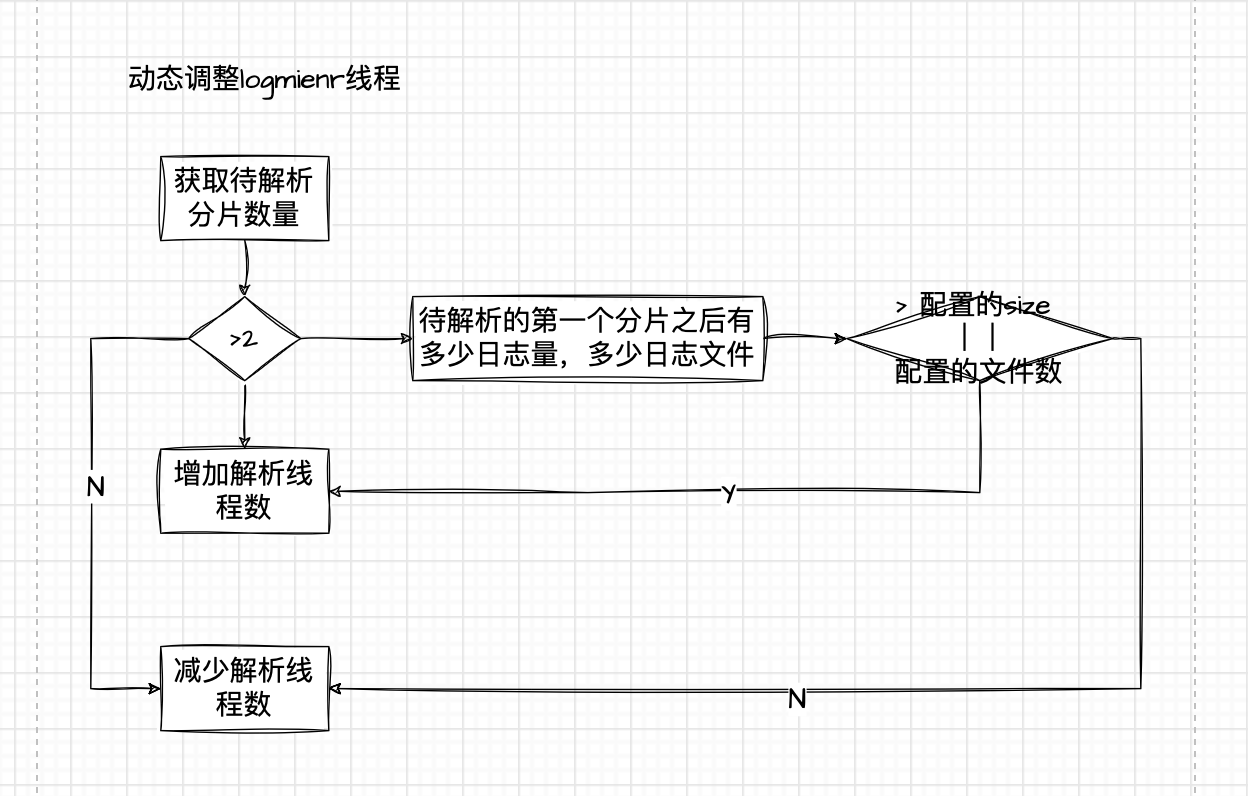
- 动态调整LogMiner线程数量
- 针对redo log分片策越调整
目前我们配置logminer 3-15线程数,大部分情况延迟都是在秒级;每小时日志size 去到100G,延迟也能控制在10分钟内。
主要代码链接:
版权归原作者 qiuqiufangfang1314 所有, 如有侵权,请联系我们删除。