
发一下我三天肝完的菜菜项目过程,林子雨老师的课大作业。介绍配环境,以及遇到的各种问题,方便自己以后万一转码回来重头学。
内容有虚拟机配置,ubuntu安装,创建项目,hadoop部署,python使用spark库等等,也附上所有用到的软件的网盘下载链接,算是提供一个完整的思路。
大作业要求:伪分布式hadoop+pandas预处理数据+hdfs保存数据+spark从hdfs读取数据+ sparksql处理+sparkmllib处理+matplotlib可视化处理数据。
环境要求:
一、 环境安装
链接:https://pan.baidu.com/s/1cwbvCLmv87fnlKnSMn7rWA
提取码:afta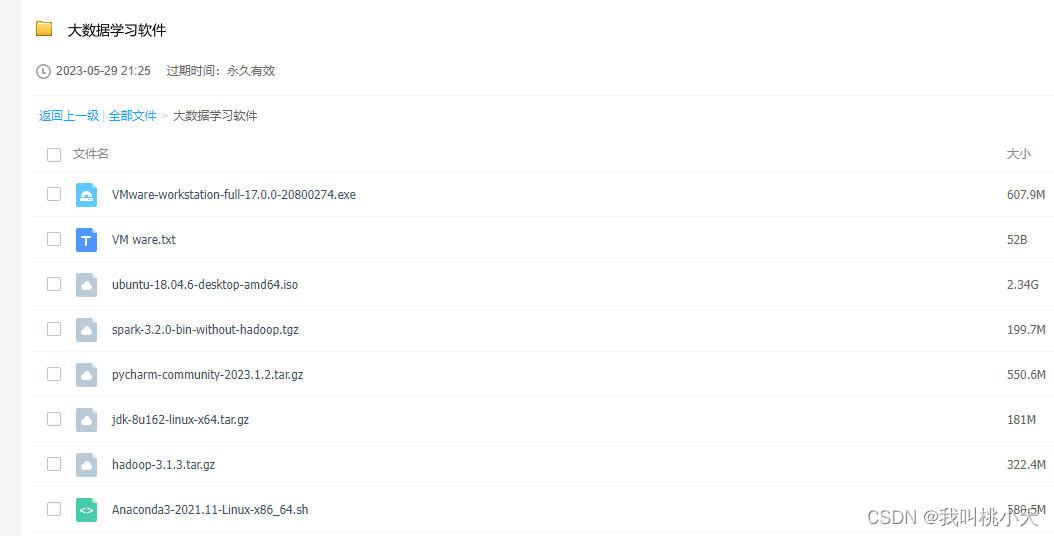
网盘下载的网速问题:可以下载个篡改猴 (Tampermonkey)扩展应用到你的浏览器上,然后在greasyfork网站中下载一个“百度网盘千千下载助手”的插件,然后在百度网盘的网页版本可获取下载原链接,安装个IDM下载器,把链接放进去就可以快速下载了。
1、虚拟机VM ware ,Ubuntu系统
VM ware安装,Ubuntu 安装
在我们的电脑上可以装一类虚拟机软件,例如VM ware,收费但可以免费一个月体验,够用了,当然,网盘有科学使用方法😜。
安装教程参考这个:https://blog.csdn.net/m0_49328056/article/details/124009592
PS!:(Ubuntu安装的时候,记得把分配的磁盘大小从20G大一些,比如40G,而且在Ubuntu装好刚开始要创建用户的时候,你的用户名就输hadoop好了,省的后面再重新创建这个用户了。二者出现的步骤如下图)!!!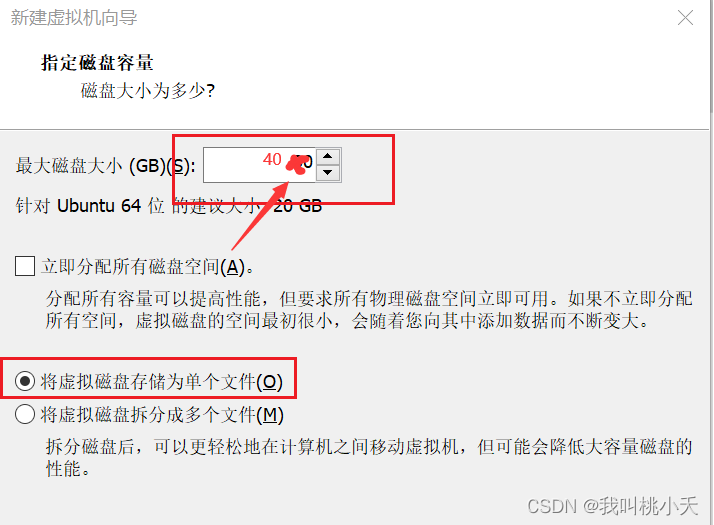
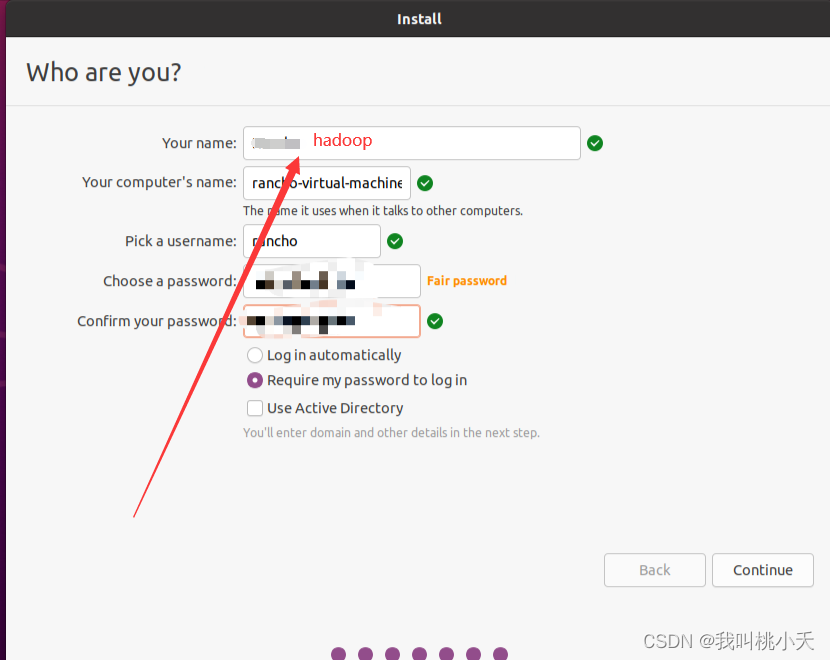
创建虚拟机的时候把分配的磁盘调整到40G,是因为默认的20G不够用的,很快就满了,我就是被坑重装了一次所有环境,因为后面再扩展空间的时候出问题无法进入图形界面。而且安装的时候首选中文最好,便于操作。
————————————————
其实上面那个安装的博客说的很清楚,但装好了虚拟机和系统仍会面临几个问题:一个就是系统无法自适应虚拟机窗口大小,看起来很小。另一个更重要的是无法在物理机和虚拟机来回复制粘贴,还有一个是无法把我物理机下载的安装包共享给虚拟机用,就是两边难以共享的问题。!!!
虚拟机安装后必要的配置:
针对上面三个问题,以下有三个配置。
1、第一步开机之后,需要先给ubuntu系统下载安装一个工具叫ubuntu tools,这个工具很重要。
安装VM ware Tools,是刚开机进入桌面的时候,下面区域(红色区域)会显示让你下载 tool,点击即可。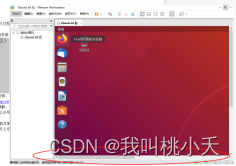
或者你没看到的话,虚拟机工具栏这里也会有让你安装的选项(刚开始是显示“安装VMware Tools”字样,我已经下载并安装成功了,所以显示重新安装VMware Tools),点击它一下。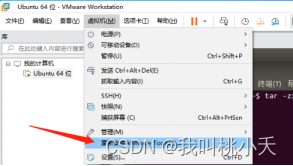
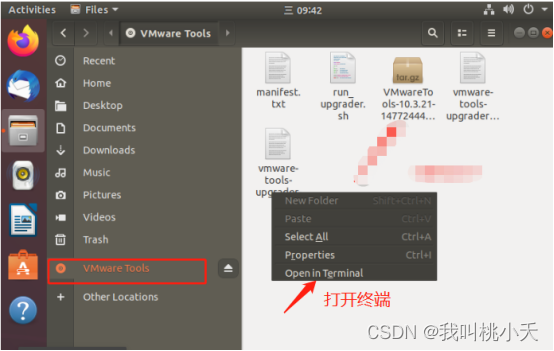
然后桌面或者文件管理里就有这个叫VMware tools的东西,点击进入VMware tools目录,然后在右边空白区域鼠标右键打开终端(在哪个目录打开终端,默认执行命令的当前目录就是在哪个目录,这里打开是在 /media/用户名/VM ware Tools 目录下):
(这是文件管理器图标)
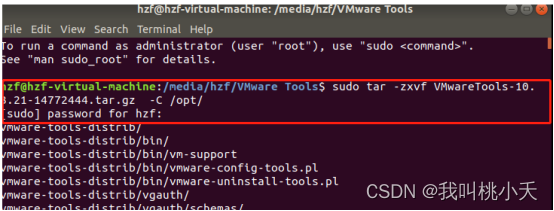
前面只是下载好了tools安装包,接下来就得在终端用命令进行安装了,执行下面的命令,先用下面的命令将当前目录的.gz文件解压缩文件到/opt目录下(记得VMwareTools-10.3.21-14772444.tar.gz更换为你的包名,为什么在/opt目录,似乎是/opt 目录不太容易出现运行时权限问题):
tar-zxvf VMwareTools-10.3.21-14772444.tar.gz -C /opt/
PS:然后你发现外面复制的命令无法粘贴到虚拟机,点击虚拟机这里可以粘贴进来:
后面会说怎么设置快捷键复制粘贴,因为得先安装好tool才行。另外,在虚拟机内部,本身的复制粘贴快捷键是:Ctrl + Shift +C与Ctrl + Shfit + V,比外面多了一个Shfit。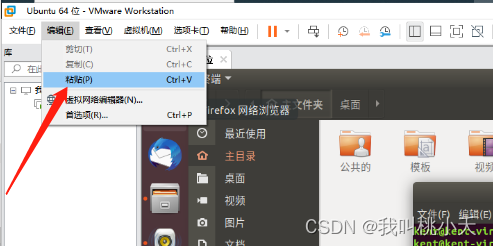
解压缩之后,接着第二步,二进制安装:
先切换到解压的目录:
cd /opt/vmware-tools-distrib
然后执行安装命令(安装时要输入一些回答,第一次输入yes,后面全程按enter回车默认)
sudo ./vmware-install.pl
直到下图出现,即安装完成。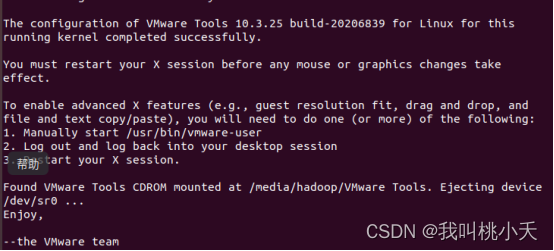
成功安装后,靠左上角那边虚拟机选项中由 ’安装VMware Tools‘ 变成 ’重新安装VMware Tools‘字样,你得先重启一下虚拟机。
然后下面这里就可以让ubuntu自适应虚拟机了画面大小了: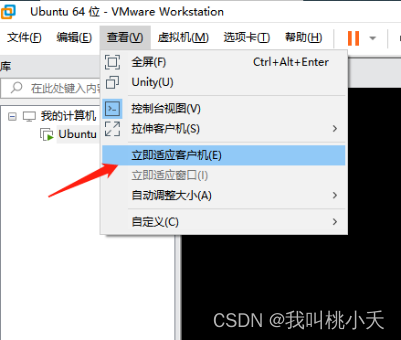
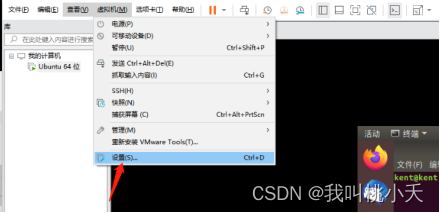
2、更改镜像设置,现在其实还是不能物理机和虚拟机来回复制粘贴的,这很不方便。
接下来设置一下。找到虚拟机设置,更换硬件那行CD/DVD的镜像文件,换为VMware安装目录下的名为Linux.iso文件:
-
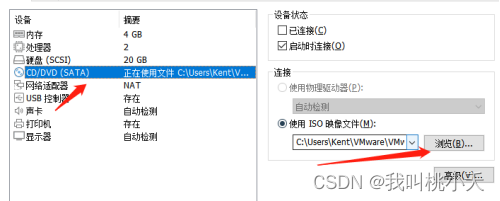
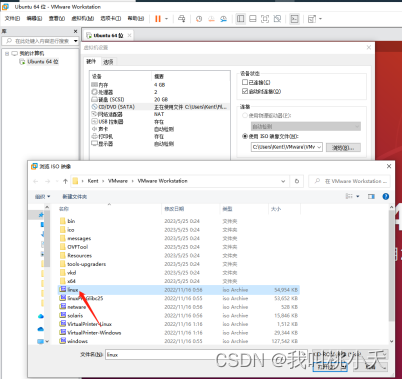
选择更换后,点击确定。
然后,在终端依次输入如下两个命令:
sudoapt-get update
sudoapt-getinstall open-vm-tools-desktop
然后重启即可。
你就能在物理机上ctrl + c 然后在虚拟机上ctrl + shift + v,或者在虚拟机ctrl + shift + c在物理机ctrl + v。
3、创建共享文件夹,让虚拟主机与物理主机交换文件: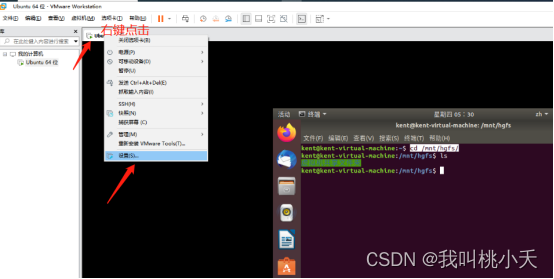
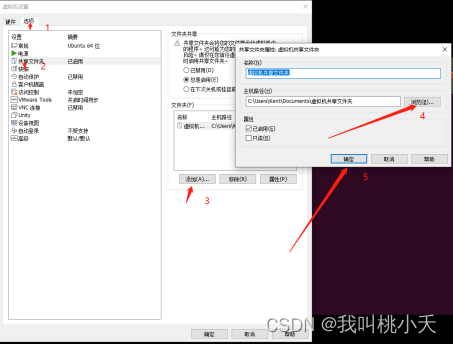
这里我在物理机C盘创建了一个名为“虚拟机共享文件夹”的文件夹(最好在linux系统中别用中文命名文件夹,不过目前我用中文命名文件夹倒是没出现问题) (ubuntu右上角可以切换输入法)
(ubuntu右上角可以切换输入法)
然后在虚拟机的终端切换到目录**/mnt/hgfs/**,就能看到你创建的共享文件夹了:
cd /mnt/hgfs/ ,记住这个目录,后面经常会用到,好像外设的挂载(例如U盘)也是在这个目录
然后你就可以把本机下载好的安装包之类的共享给虚拟机了。
2、hadoop(含java),spark,anaconda3(含python3.x),pycharm社区版安装
hadoop安装教程:http://dblab.xmu.edu.cn/blog/2441-2/(仅跳过 Hadoop单机配置(非分布式) 部分)
Spark安装教程:http://dblab.xmu.edu.cn/blog/2501-2/ (仅需要照着做 安装 部分即可)
anaconda3安装教程:https://blog.csdn.net/WwLK123/article/details/125574958(这个教程没配置环境变量,但配置环境这取决于你的anaconda安装的时候是否已经自动配置了,有时候会自动配置有时候不会,安装好之后在命令行输入 conda -V试一下就知道了,如果没有信息就得自己添加环境变量,cd ~进入主目录,然后vim .bashrc编辑配置文件,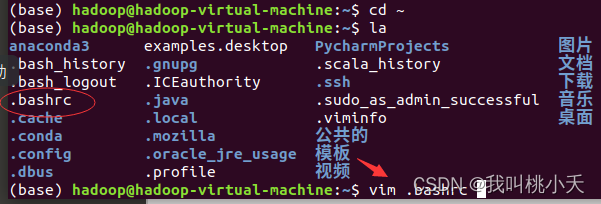
然后按一下键盘的i 键进入文本的插入(insert)模式(看到下面字样即为插入模式)。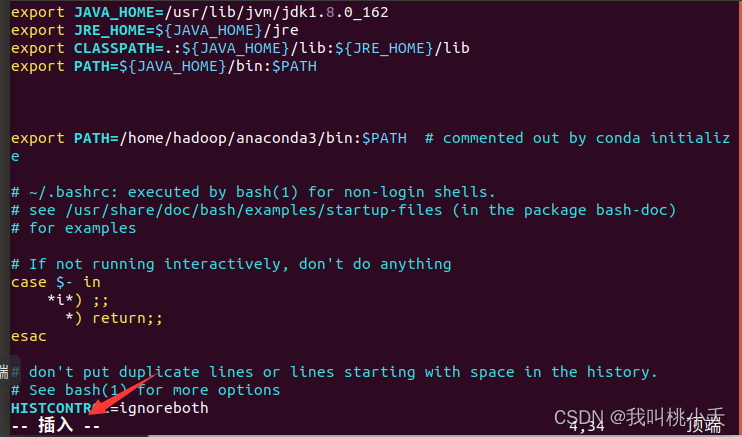
然后像我一样找个位置粘贴加入下面这行(直接贴,不需要双引号)
exportPATH=/home/hadoop/anaconda3/bin:$PATH
(其中/home/hadoop/anaconda3是我的ancaonda的安装目录,如果安装的时候没有刻意指定更改,默认就是在用户主目录下的。其实也可以换成下面这样也是可以的)
exportPATH=~/anaconda3/bin:$PATH
加入一行代码之后,然后按Esc键(取消插入模式,那个Insert消失),输入一个冒号*😗,再输入wq(保存并退出编辑的命令),按回车即可保存退出。
然后在命令行输入
source .bashrc
,执行让环境立即生效,你就能看到前面有个base了,base环境这是anaconda默认创建的一个虚拟环境,在此环境之下可以用conda命令创建新的环境。
至于anaconda3用conda命令创建新的python虚拟环境:
conda create --name hadoop python=3.8.2
然后切换到这个环境(激活名为hadoop虚拟环境,当你看到命令行中前面的(base)换成(hadoop)就说明切换到了hadoop环境):
conda acivate hadoop
接下来你就可以在hadoop虚拟环境下载一些常用的python库例如pandas之类的,大部分都可以用conda install 库名下载,conda下载不了的用pip install 库名下载。
然后在python的开发工具例如pycharm,vscode, jupyternotebook中运行时选择python解释器的时候,就选conda管理工具下的虚拟环境名为hadoop中的python3.8.2.exe这个解释器就行了,对于每个编辑器操作不一样,后面会说pycharm中怎么选。
pycharm社区版安装:https://blog.csdn.net/m0_64071068/article/details/123284573 (安装和配置启动快捷键按照这个教程就没问题)
https://dblab.xmu.edu.cn/blog/3859/ (pycharm新建项目的话,看这个教程:这个也是林子雨老师的教程。主要是新建项目然后选择项目的运行环境)
选择运行环境就是选择python解释器,就选择你上面安装anaconda之后创建的hadoop这个虚拟环境中的python解释器。
如果上面按照教程创建好了名为hadoop的conda虚拟环境,并且创建时指定虚拟环境python版本为3.8.2,而且你的ananconda的安装目录也按照教程装在主目录/home/下面,那么你在add 需要找的python解释器路径就是:
/home/hadoop/anaconda3/envs/hadoop/bin/python3.8.2
选择他即可。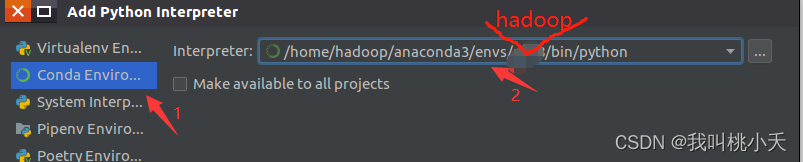
如果这些都弄好了,以后你就可以在虚拟机肆意的在项目文件下新建文件,写代码运行了。
——————————————————————————————————
二、开始项目
我从https://www.kaggle.com/datasets下载了一个数据集叫Survey of Labour and Income Dynamics
结构如下: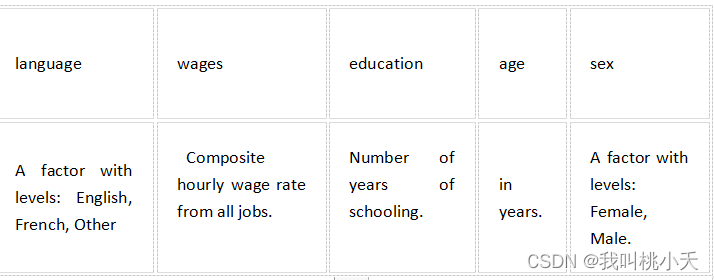
总共7500+行数据,.csv文件的数据集部分数据展示如下: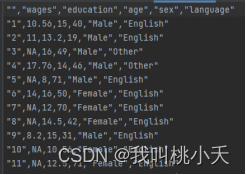
kaggle挺多数据集的,如果时间足够,随便下一个自己折腾一下。
然后展示一下我写项目的具体过程,还是回到开始说的那个作业要求来:
要求:伪分布式hadoop+pandas预处理数据+hdfs保存数据+spark从hdfs读取数据+ spark mlib处理+matplotlib可视化处理数据。
跟着要求来做,刚开始先创建pthon项目文件(路径为~/PyhotnProjects/myhadoop),并把我的数据集SLID.csv移动到文件下。
最终实验结束的项目结构如下: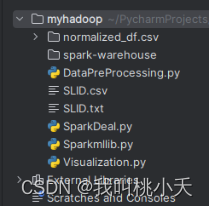
整个实验代码运行的过程:执行DataPreProcessing.py(处理SLID.csv生成SLID.txt文件)->执行SparkDeal.py(生成normalized_df.csv文件夹)-> 执行Sparkmllib.py(训练模型)-> 执行Visualization.py(可视化结果)
1、编写并执行预处理程序DataPreProcessing.py,用pandas处理数据集,预处理SLID.csv后得到SLID.txt,
该过程主要是删掉没用的列和对数据集中的null值的处理,代码如下。
import pandas as pd
slid = pd.read_csv('./SLID.csv')# Now we are reading the dataset vgsales.csv using read_csv function# 从中删除名为'Unnamed: 0'的列,没有用。
slid.drop('Unnamed: 0', axis=1, inplace=True)# 处理为null的数据:删除性别为null的行,wages列中的缺失值用该列的均值填充,education 列的缺失值(NaN)替换为该列的众数,将language中NaN的值填充为Unknown
slid = slid[(slid['sex']=='Male')|(slid['sex']=='Female')]
slid['wages'].fillna(slid['wages'].mean(), inplace=True)
slid['education'].fillna(slid['education'].mode()[0], inplace=True)
slid['language'].fillna('Unknown', inplace=True)
slid['sex']= slid['sex'].replace({'Female':0,'Male':1})print(slid)# .csv->.txt ,将预处理好的数据保存为txt文件withopen('./SLID.txt','a+', encoding='utf-8')as f:# 先写入列名,无论是Pandas还是Spark读取数据都需要列名,也即DataFrame的header
column_names = slid.columns
f.write("\t".join(column_names)+"\n")for line in slid.values:
f.write((str(line[0])+'\t'+str(line[1])+'\t'+str(line[2])+'\t'+str(line[3])+'\t'+str(line[4])+'\n'))
然后运行上面的预处理文件,在项目下会出现一个文件名为SLID.txt。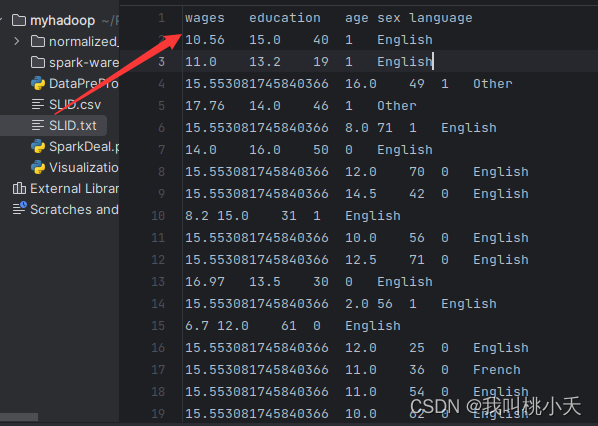
2、将预处理后的数据集,上传到hdfs的Datanode里面存储。
2.1 如果hadoop没出错的话就好,有问题可以用2.2排查
然后你用jps命令查看自己是否已经启动了hdfs的两个应用(Namenode与Datanode开启了没有,下面是没开的样子)
没有开启hadoop的hdfs文件管理服务,就进入hadoop目录下的sbin目录执行start-dfs.sh开启. 开启后,你要确保以下这两个东西出现
开启后,你要确保以下这两个东西出现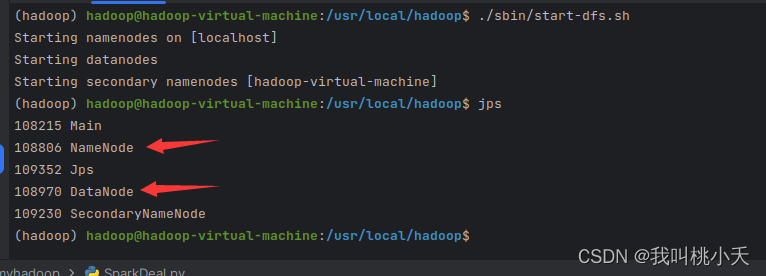 在终端执行命令将预处理好的数据集文件SLID.txt上传到hdfs用户目录下(命令如下):
在终端执行命令将预处理好的数据集文件SLID.txt上传到hdfs用户目录下(命令如下):
./bin/hdfs dfs -put ~/PycharmProjects/myhadoop/SLID.txt
因为我已经上传过预处理之后的数据集了,下面我用上传另外一个非数据集文件Visualization.py演示了一下:
然后,文件上传到哪里了呢?你不妨打开上面hadoop安装教程,里面伪分布式部分那里,里面肯定有下图这样一行。然后就是上传到这里了,这是你曾为自己创建的用户目录。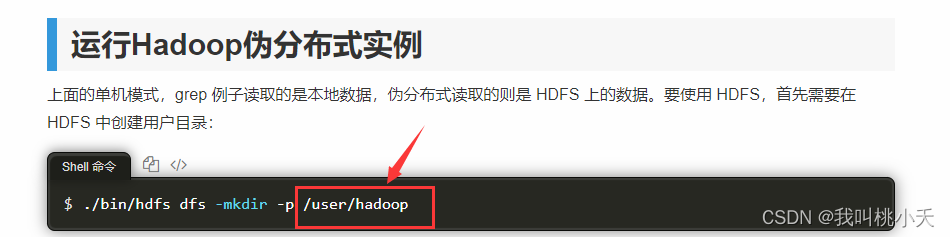
你也可以查看自己曾上传的文件有哪些,用命令:
./bin/hdfs dfs -ls

以下是一些hdfs的其他命令,供参考:
2.2有关hadoop的错误经验
需要注意的是,hadoop安装和运行比较晦涩,其中虽然我没有听课,但我的理解是hadoop像是一个公司,hdfs是公司中的人事系统,Namenode有点像公司的主管,而每个dataNode就像主管手下的员工,他们是真正掌握数据的。伪分布式存储就是主管即是主管,并且它手下只有一个员工,就是它自己。
然后安装的时候有几个坑,就是所有软件的安装我们必须尽量在hadoop用户下安装。但我不明白即使我这样做中间为什么会出现权限不足的问题,因为明明用hadoop用户安装,里面有些文件竟然属于root。
创建hdfs用户目录的时候出现以下问题:一个是namenode,一个是datanode的问题
然后我去hadoop安装目录的logs文件夹中查看了日志,发现是namenode进程启动有问题,对有些文件权限不够,这里看到我./sbin/start-all/sh执行了所有进程(本应包括namenode,但是没有)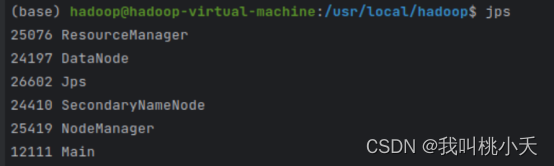
然后解决办法是我进./hadoop/logs/目录下看了最近的有关namenode的日志,找到对应的无权限的文件夹(不明白明明是hadoop安装的,有些文件夹还属于root),先赋予hadoop用户执行和读的权限,但还是没用,然后我直接删掉了就行了。
另外,解决这个问题之后,某一刻。我发现我突然上传不了到hsfs的数据了,提示的错误是没有datanode进程,然后你jps查看进程发现也没有datanode进程,此时,结局方法是找到以下的配置文件的这个目录,删掉即可,据说是执行多次、format格式化namenode数据错乱的结果。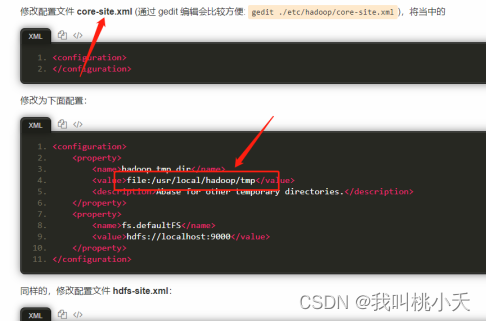
然后其实全过程只需要执行.hadoop/sbin/start-dfs.sh开启namenode和datanode两个进程就行了,其他的SecondaNode之类的暂时用不到。
另外需要记住的是,执行创建你的hdfs用户目录命令:./bin/hdfs dfs -mkdir -p /user/hadoop 后,你在用python获取hdfs文件的时候,路径用hdfs://localhost/user/hadoop/(你曾上传的文件名)
当然,这个hdfs路径用浏览器访问不了,我也不知道为什么,按理来说应该可以的。
3、使用spark将数据从hdfs系统中获取数据,并进一步分析处理,编写SparkDeal.py文件。
创建SparkDeal.py文件,用spark sql处理数据集,得到一个带标签的并且拥有四个特征的经过归一化的数据集,具体过程看代码注释(比较详细):
from pyspark import SparkContext, SparkConf
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, when
from pyspark.sql.functions importmax,minimport matplotlib.pyplot as plt
conf = SparkConf().setAppName("ReadTextFileFromHDFS")
sc = SparkContext.getOrCreate(conf)
spark = SparkSession(sc)# 替换为您的 HDFS 用户目录中的文本文件路径
text_file_path ="hdfs://localhost:9000/user/hadoop/SLID.txt"# 读取 TXT 文件并创建 DataFrame
df = spark.read.option("sep","\t").option("header","true").csv(text_file_path)
df.createOrReplaceTempView("my_table")print("spark sql处理之前:")
df.show(20)#将language也转化浮点型
df = df.withColumn("language", when(df["language"]=='English',-1.5).when(df["language"]=='Unknown',-0.5).when(df["language"]=='Other',0.5).when(df["language"]=='French',1.5))# 全部数据转换成浮点型
columns_to_convert =[c for c in df.columns]
df = df.select([col(c).cast("float").alias(c)if c in columns_to_convert else col(c)for c in df.columns])# #增加一个标签列isHigh
result = df.agg(max("wages"),min("wages"))#df.agg()聚合成一个新的DataFrame。每列会自动命名
result_array = result.collect()#将其转化成数组
max_wages = result_array[0][0]
min_wages = result_array[0][1]# print(max_wages,min_wages,df.filter(col('wages') > 40).count())# #薪资在上20%的临界薪资
highLevel =(min_wages +0.8*(max_wages - min_wages))# #薪资在下20%的临界薪资
lowLevel =(min_wages +0.2*(max_wages - min_wages))# print(highLevel,lowLevel)
df = df.withColumn("isHigh", when(df["wages"]>= highLevel,1).when(df["wages"]<= lowLevel,-1).otherwise(0))#删除一个wages列
df = df.drop("wages")# #所有列进行归一化#排除isHigh标签,对其他特征变量列归一化
column_names =[col for col in df.columns if col !='isHigh']
min_values = df.agg(*[min(c)for c in column_names]).collect()[0]print(min_values)
max_values = df.agg(*[max(c)for c in column_names]).collect()[0]print(max_values)
normalized_df = df.select(*[((df[c]- min_values[i])/(max_values[i]- min_values[i])).alias(c)for i, c inenumerate(column_names)],'isHigh')print("处理之后:")
normalized_df.show(20)#存储起来供可视化分析
normalized_df.write.csv('normalized_df.csv', header=True)
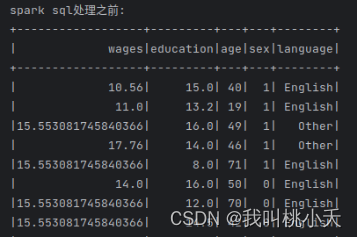
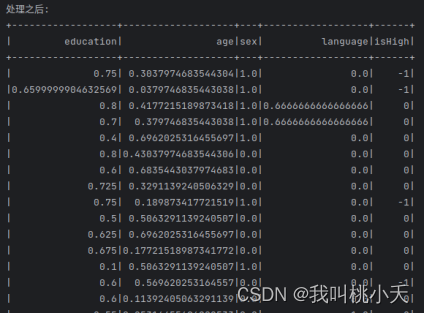
isHigh列属性是根据wages薪资高低评判出来的,有三个值,判断方式很粗暴:其中1是指属于20%的较高工资人群那一类,0-是指属于介于中间薪资水平的60%那一类人群,而-1是指属于20%较低工资人群的那一类)。language原本有四种值,归一化之后变成0,0.33,0.66,0.99四个值。
另外,注意上面的获取数据的路径,从 HDFS 用户目录中的获取文本数据的路径如下:
text_file_path = “hdfs://localhost:9000/user/hadoop/SLID.txt”
其中/user/hadoop/是你上面创建的用户目录的路径。
然后执行上面这个程序,python的spark库就可以像 “sql语句处理数据库表”一样处理DataFrame表格数据,并保存处理好的数据到normalized_df.csv文件目录中。
4、使用Spark MLlib库的应用于我的数据, 编写Sparkmllib.py文件
使用saprk MLlib组件对数据集进行简单的逻辑回归分类训练
from pyspark.sql import SparkSession
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.classification import LogisticRegression
from pyspark.ml.evaluation import MulticlassClassificationEvaluator
from pyspark.sql.functions import col, when
# 创建SparkSession
spark = SparkSession.builder.appName("LogisticRegressionExample").getOrCreate()# 加载.csv文件作为DataFrame
data = spark.read.csv("./normalized_df.csv/part-00000-0fa4c735-4a8f-4457-af15-239fa5ff90bc-c000.csv", header=True, inferSchema=True)# 创建特征向量列,将特征列合并为一个向量列
assembler = VectorAssembler(inputCols=["education","age","sex","language"], outputCol="features")
data = assembler.transform(data)# 将"isHigh"列从整数类型更改为双精度浮点类型,并进行特定条件下的值的更改
data = data.withColumn("isHigh", col("isHigh").cast("double")) \
.withColumn("label", when(col("isHigh")==-1,0).when(col("isHigh")==0,1).when(col("isHigh")==1,2))# 选择特征向量列和标签列
data = data.select("features","label")# 拆分数据集为训练集和测试集
trainData, testData = data.randomSplit([0.7,0.3], seed=12345)# 创建逻辑回归模型对象
lr = LogisticRegression(labelCol="label", featuresCol="features", family="multinomial")# 使用训练集训练逻辑回归模型
model = lr.fit(trainData)# 使用测试集进行预测
predictions = model.transform(testData)# 选择预测结果列和真实标签列
predictions = predictions.select("prediction","label")# 评估模型性能
evaluator = MulticlassClassificationEvaluator(labelCol="label", predictionCol="prediction", metricName="accuracy")
accuracy = evaluator.evaluate(predictions)print("Accuracy = %g"% accuracy)
spark.stop()
输出模型测试效果: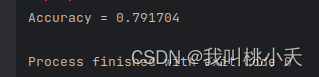
5、matplolib可视化pands库处理以及spark sql处理的数据,编写Visualization.py文件
DataPreProcessing.py执行后会保存一个SLID.txt,是处理了空值,null值之后的初步数据。而SparkDeal.py执行之后会保存一个normalized_df.csv文件夹,这下面有我用spark处理好的数据。刚开始我是想可视化Spark MLlib库应用过程的,然后没时间做了…就用matplolib分别简单可视化了一下前两步的数据:
import pandas as pd
import matplotlib.pyplot as plt
from pyspark.sql.types import FloatType
from pyspark import SparkContext, SparkConf
from pyspark.sql import SparkSession
from pyspark.sql.functions import col
defThreeCouplePopleCounts():
conf = SparkConf().setAppName("ReadTextFileFromHDFS")
sc = SparkContext.getOrCreate(conf)
spark = SparkSession(sc)# 用pandas预备处理之后的数据
text_file_path ="hdfs://localhost:9000/user/hadoop/SLID.txt"# 读取 TXT 文件并创建 DataFrame
df = spark.read.option("sep","\t").option("header","true").csv(text_file_path)# 将"wages"列的数据类型转换为FloatType
df = df.withColumn("wages", col("wages").cast(FloatType()))# 转换为Pandas DataFrame
pandas_df = df.toPandas()# 计算百分位数
percentiles = pandas_df["wages"].quantile([0.2,0.8])
min_value = percentiles[0.2]
max_value = percentiles[0.8]# 分组数据
group1 = pandas_df[pandas_df["wages"]<= min_value]
group2 = pandas_df[(pandas_df["wages"]> min_value)&(pandas_df["wages"]<= max_value)]
group3 = pandas_df[pandas_df["wages"]> max_value]# 计算每个组的数量
count1 = group1.shape[0]
count2 = group2.shape[0]
count3 = group3.shape[0]# 创建柱状图
groups =["Lower","Normal","Higher"]
counts =[count1, count2, count3]
plt.bar(groups, counts, color='steelblue', edgecolor='black')# 添加标签和标题
plt.xlabel("wages")
plt.ylabel("Count")
plt.title("Salary bar chart")
plt.show()defEduAndTimeWithWages():# 读取sparksql处理过后的数据
df = pd.read_csv('normalized_df.csv/part-00000-0fa4c735-4a8f-4457-af15-239fa5ff90bc-c000.csv')
x = df['education']
y = df['age']
z = df['isHigh']
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
ax.scatter(x, y, z)
ax.set_xlabel('education-time')
ax.set_ylabel('work-time')
ax.set_zlabel('isHightPay')
plt.show()
ThreeCouplePopleCounts()
EduAndTimeWithWages()
可视化三组收入人群的数量关系的柱状图: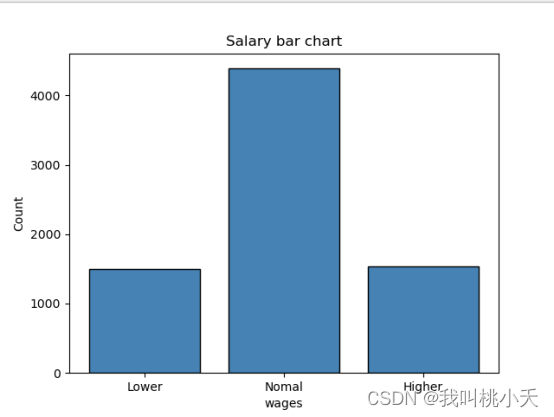
可视化分析劳动者受教育时常和工作年限两个变量与薪水高低的关系: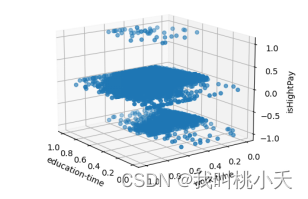
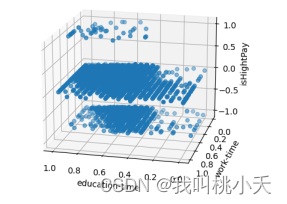
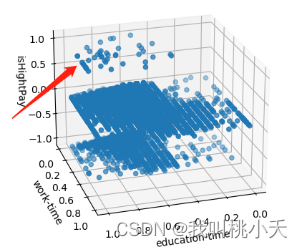
可视化结果得评估与分析:
从图中聚集的点可以看出,对于那些高工资的人,他们几乎都有不错的学历,工作时长也不低。奇怪的是,对于那些工资处于中下层的人来说,多数人也是工作时间都很长,且受教育程度也不低。所以我的推论是:从这个数据来看,学历是参加工作占比很大的一个因素,但这无所谓就是说它们一定就能决定薪资的高低,也许只是一个获得高薪水的必要条件,同样的,对于工作年限的时长也是。所以想要拿更高的薪水,除了长时间参加工作与获得学历之外,还得具备别的不一样的特质。
写完了😘😘😘。
版权归原作者 我叫桃小夭 所有, 如有侵权,请联系我们删除。