
1.1 概述
本文来探究一下使用消息队列的热点问题,如何保证消息队列的高可用,本文使用的消息队列是
RabbitMQ
,后续会出其他热门的
MQ
教程,敬请期待。
1.2
RabbitMQ
的高可用性
RabbitMQ
基于主从模式实现高可用。
RabbitMQ
有三种模式:单机模式、普通集群模式、镜像集群模式。
1.2.1 单机模式
单机模式,即单机情况不做集群,就单独运行一个
rabbitmq
而已
就是
Demo
级别的,一般就是你本地启动了玩的,没人生产用单机模式。
1.2.2 普通模式
普通集群模式,意思就是在多台机器上启动多个
RabbitMQ
实例,每个机器启动一个。你创建的
queue
,只会放在一个
RabbitMQ
实例上,但是每个实例都同步
queue
的元数据(元数据可以认为是
queue
的一些配置信息,通过元数据,可以找到
queue
所在实例)。你消费的时候,实际上如果连接到了另外一个实例,那么那个实例会从
queue
所在实例上拉取数据过来。
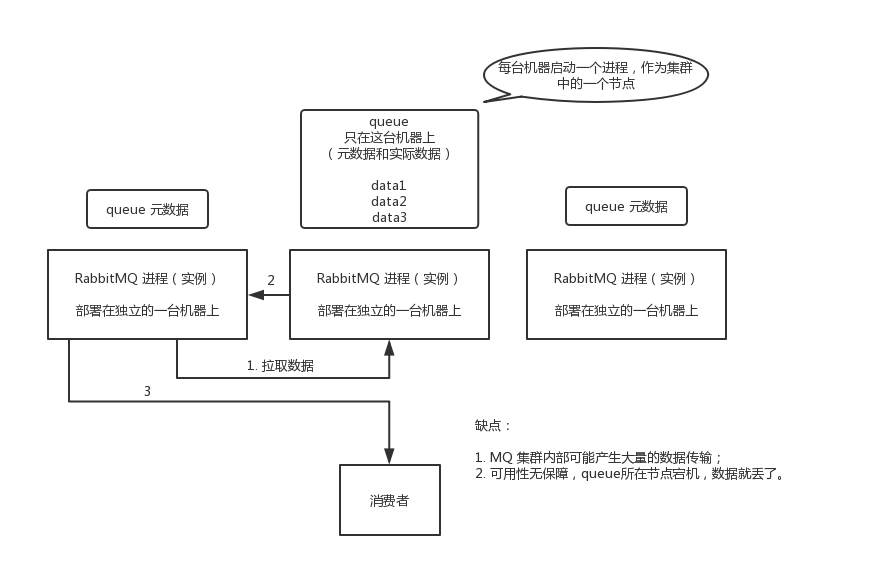
下图对上图其进行了详细说明:

这种方式确实很麻烦,也不怎么好,没做到所谓的分布式,就是个普通集群。因为这导致你要么消费者每次随机连接一个实例然后拉取数据,要么固定连接那个
queue
所在实例消费数据,前者有数据拉取的开销,后者导致单实例性能瓶颈。
而且如果那个放
queue
的实例宕机了,会导致接下来其他实例就无法从那个实例拉取,如果你开启了消息持久化,让
RabbitMQ
落地存储消息的话,消息不一定会丢,得等这个实例恢复了,然后才可以继续从这个
queue
拉取数据。
所以这个事儿就比较尴尬了,这就没有什么所谓的高可用性,这方案主要是提高吞吐量的,就是说让集群中多个节点来服务某个
queue
的读写操作
1.2.3 镜像集群模式(高可用性)
这种模式,才是所谓的
RabbitMQ
的高可用模式。跟普通集群模式不一样的是,在镜像集群模式下,你创建的
queue
,无论元数据还是
queue
里的消息都会存在于多个实例上,就是说,每个
RabbitMQ
节点都有这个
queue
的一个完整镜像,包含
queue
的全部数据的意思。然后每次你写消息到
queue
的时候,都会自动把消息同步到多个实例的
queue
上。

下面对上图进行详细描述: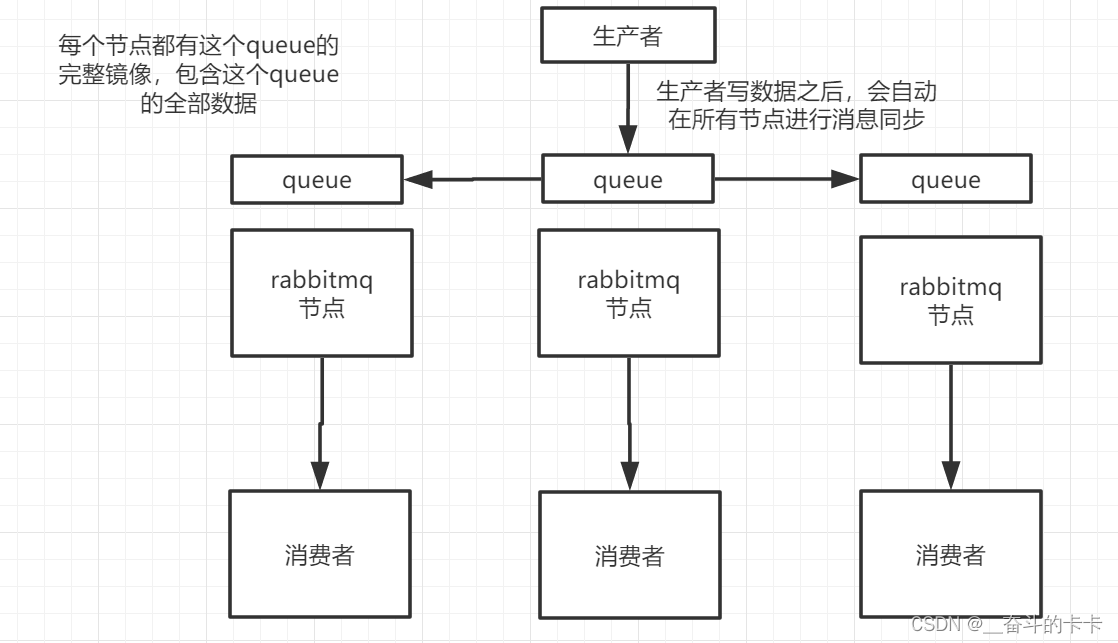
好处
任何一台机器宕机了,其他的机器还可以使用(包含了这个
queue
的完整数据)。
坏处
1、性能消耗太大,所有机器都要进行消息的同步,导致网络压力和消耗很大。
2、没有扩展性可言,如果有一个queue负载很重,就算加了机器,新增的机器还是包含了这个queue的所有数据,并没有办法扩展queue。
如何开启镜像模式
如何开启镜像集群模式:其实很简单,
RabbitMQ
有很好的管理控制台,就是在后台新增一个策略,这个策略是镜像集群模式的策略,指定的时候是可以要求数据同步到所有节点的,也可以要求同步到指定数量的节点,再次创建
queue
的时候,应用这个策略,就会自动将数据同步到其他的节点上去了。
1.3 详细部署
mq01:192.168.100
mq02:192.168.101
1.3.1 配置普通集群模式
把mq01的cookie值复制到mq02服务器
配置cookie
vi /var/lib/rabbitmq/.erlang.cookie
确保rabbitMQ服务处于停止状态:service rabbitmq-server stop
确保2个节点的coolie文件使用相同的值
cookie文件默认路径为/var/lib/rabbitmq/.erlang.cookie(RPM安装)
或者$home/.erlang.cookie(解压方式安装)
.erlang.cookie设置可写
chmod u+w /var/lib/rabbitmq/.erlang.cookie
加入集群(默认加入的为磁盘节点)
rabbitmqctl join_cluster rabbit@mq02
如果要使用内存节点,则可以使用
rabbitmqctl join_cluster --ram rabbit@mq02
查看集群状态
rabbitmqctl cluster_status
1.3.2 配置镜像集群模式
1.3.2.1 通过命令行配置
rabbitmqctl set_policy [ha-all]"^"'{"ha-mode":"all"}'//策略正则表达式为 “^” 表示所有匹配所有队列名称
rabbitmqctl set_policy -p [虚拟主机名称][策略名称如ha-all ]"^"'{"ha-mode":"all" , "ha-sync-mode":"automatic"}'
在任意一个节点上执行:
rabbitmqctl set_policy ha-all "^"'{"ha-mode":"all" , "ha-sync-mode":"automatic"}'
或者指定vhost:
rabbitmqctl set_policy -p demo ha-all "^"'{"ha-mode":"all" , "ha-sync-mode":"automatic"}'
将所有队列设置为镜像队列,即队列会被复制到各个节点,各个节点状态保持一直。
到这里,RabbitMQ 高可用集群就已经搭建好了,最后一个步骤就是搭建均衡器。
策略名称:自定义
“^”:匹配所有队列
ha-sync-mode: 默认为手动,可以配置为自动,区别在于,如果是自动做镜像回复,则该队列会处于不可用状态直到同步完成
1.3.2.2 通过管理界面配置
界面配置示例(http://ip:15672/):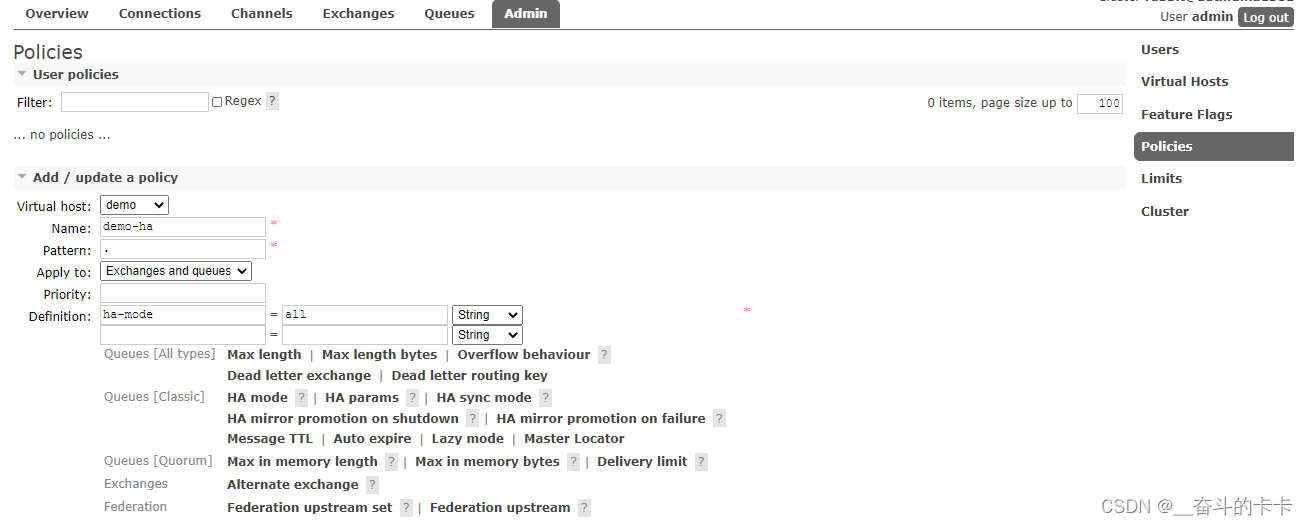
1.3.3 配置高可用
可以采用
HAProxy+Keepalived
或
Nginx+Keepalived
方式来部署实现。
我这里根据实际使用场采用另一种简洁方案,如下图所示,仅使用
Nginx
,配置
backup
路由策略,减轻部署复杂性。

1.3.4 集群常用命令
1、加入集群[--ram添加内存模式 默认disk模式]
rabbitmqctl join_cluster --ram rabbit@mq012、查看集群状态
rabbitmqctl cluster_status
3、更改节点模式[顺序 关闭运用-〉更改类型->开启运用]
rabbitmqctl stop_app –停止运用服务
rabbitmqctl change_cluster_node_type disc/ram –更改节点为磁盘或内存节点
rabbitmqctl start_app –开启运用服务
4、创建策略(集群同步策略……)
set_policy [-p vhostpath]{name}{pattern}{definition}[priority]5、查看策略
rabbitmqctl list_policies
6、移除远程offline的节点
1.节点2停掉应用
rabbitmqctl stop_app
2.节点1执行删除
rabbitmqctl forget_cluster_node rabbit@mq027、设置集群名称
rabbitmqctl set_cluster_name cluster_name
8、设置镜像模式
Rabbit提供镜像功能,需要基于rabbitmq策略来实现,政策是用来控制和修改群集范围的某个vhost队列行为和Exchange行为
set_policy [-p vhostpath]{name}{pattern}{definition}[priority]
rabbitmqctl set_policy ha-all "^ha.""{""ha-mode"":""all""}"
rabbitmqctl set_policy ha-all "^""{""ha-mode"":""all"",""ha-sync-mode"":""automatic""}"
rabbitmqctl set_policy -p demo ha-all "^""{""ha-mode"":""all"",""ha-sync-mode"":""automatic""}"9、手动同步queue
rabbitmqctl sync_queue name
10、取消queue同步
rabbitmqctl cancel_sync_queue name
11、查看所有队列信息
rabbitmqctl list_queues
12、获取队列信息
rabbitmqctl list_queues[-p vhostpath][queueinfoitem ...]
Queueinfoitem可以为:name,durable,auto_delete,arguments,messages_ready,messages_unacknowledged,messages,consumers,memory。
13、获取Exchange信息
rabbitmqctl list_exchanges[-p vhostpath][exchangeinfoitem ...]
Exchangeinfoitem有:name,type,durable,auto_delete,internal,arguments。
14、获取Binding信息
rabbitmqctl list_bindings[-p vhostpath][bindinginfoitem ...]
Bindinginfoitem有:source_name,source_kind,destination_name,destination_kind,routing_key,arguments。
15、获取Connection信息
rabbitmqctl list_connections [connectioninfoitem ...]
Connectioninfoitem有:recv_oct,recv_cnt,send_oct,send_cnt,send_pend等。
16、获取Channel信息
rabbitmqctl list_channels[channelinfoitem ...]
Channelinfoitem有consumer_count,messages_unacknowledged,messages_uncommitted,acks_uncommitted,messages_unconfirmed,prefetch_count,client_flow_blocked。
版权归原作者 __奋斗的卡卡 所有, 如有侵权,请联系我们删除。