
文章目录
1. 克隆虚拟机
kafka集群搭建,需要3台虚拟机环境,但是我目前只安装了一台虚拟机,因此还需要准备两台虚拟机环境,正常情况下应该再安装2台虚拟机,这里为了方便直接克隆出3台虚拟机。
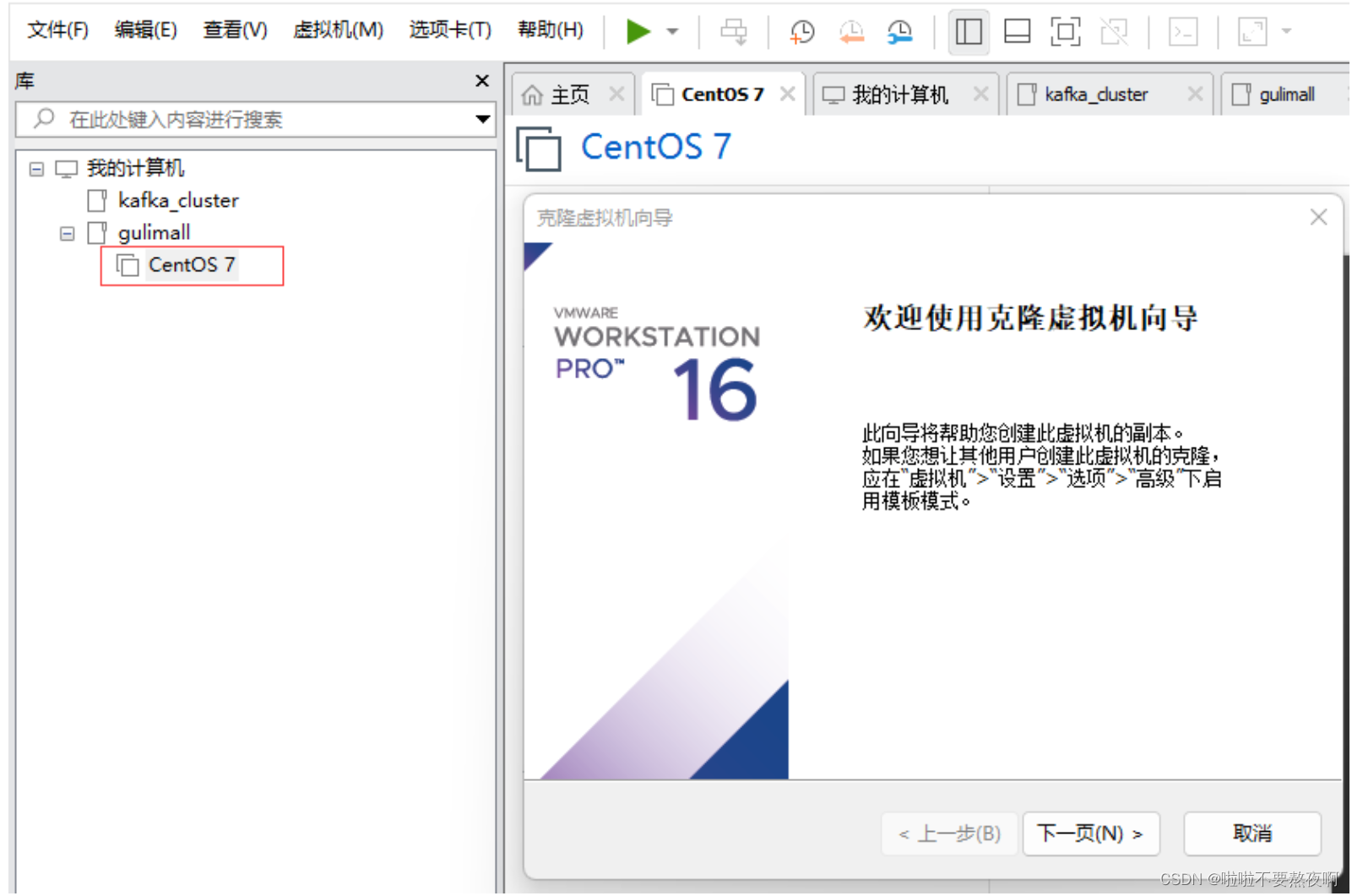
① 选中 CentOs7 右键—> 管理—> 克隆—> 执行克隆操作:
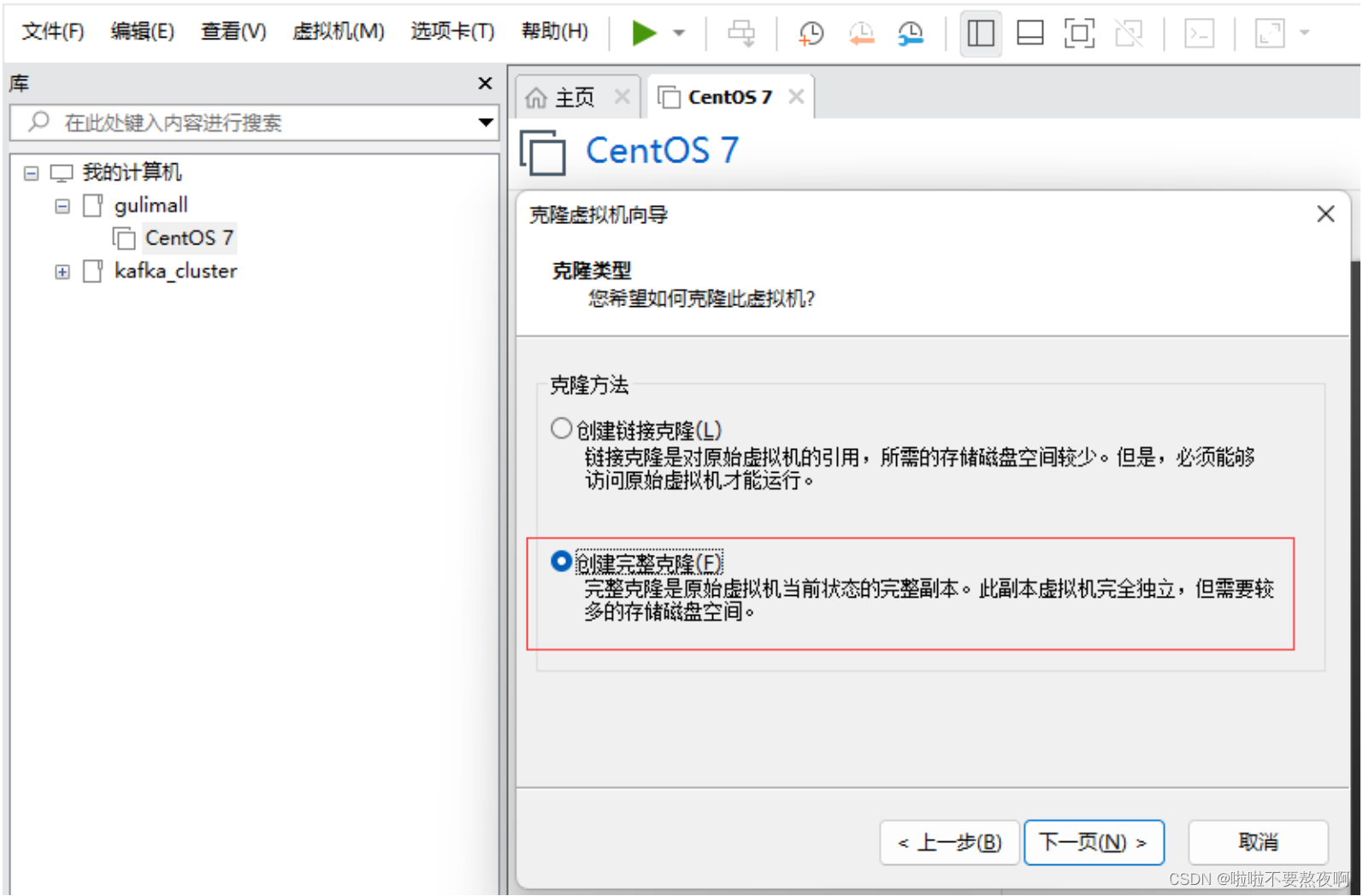
② 下一页,选择创建完整克隆:
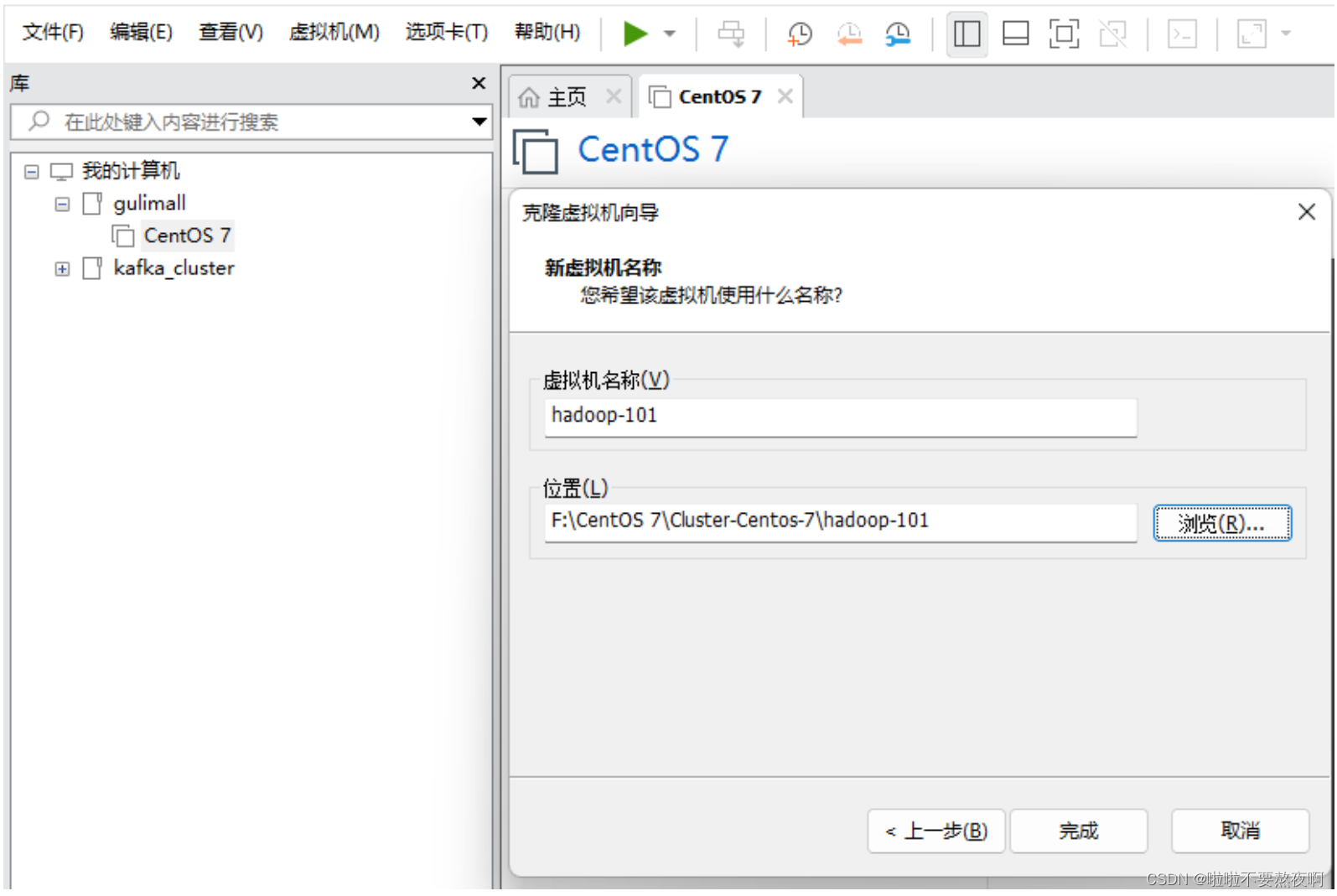
③ 填入虚拟机名称和安装位置:
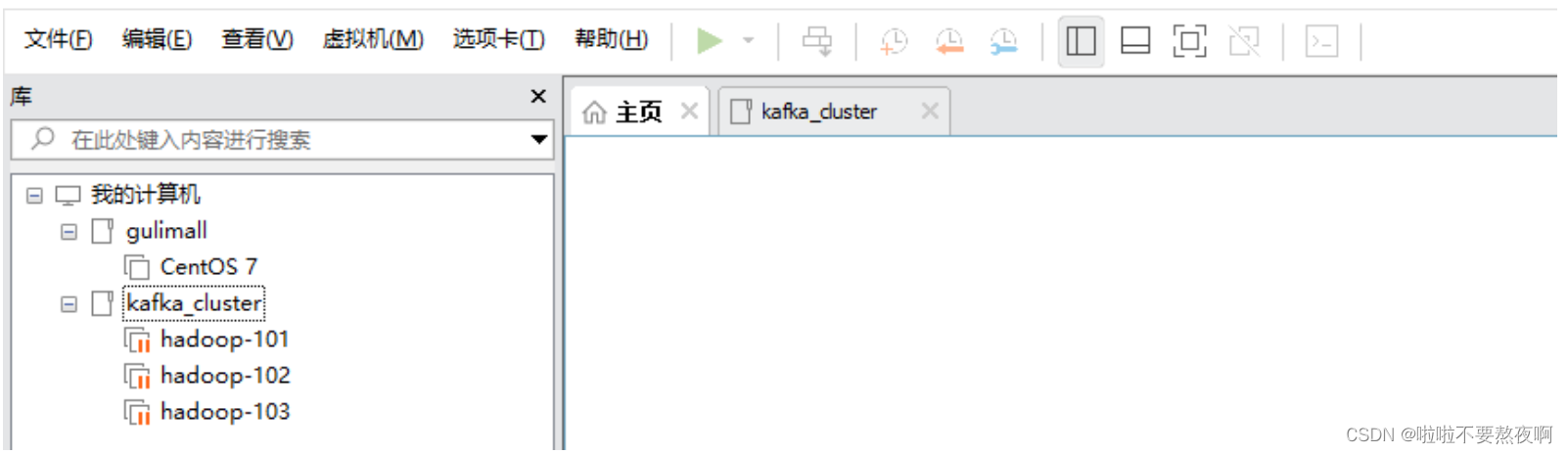
④ 按照上面的步骤创建3台虚拟机环境,先不要开机不然会ip地址冲突:
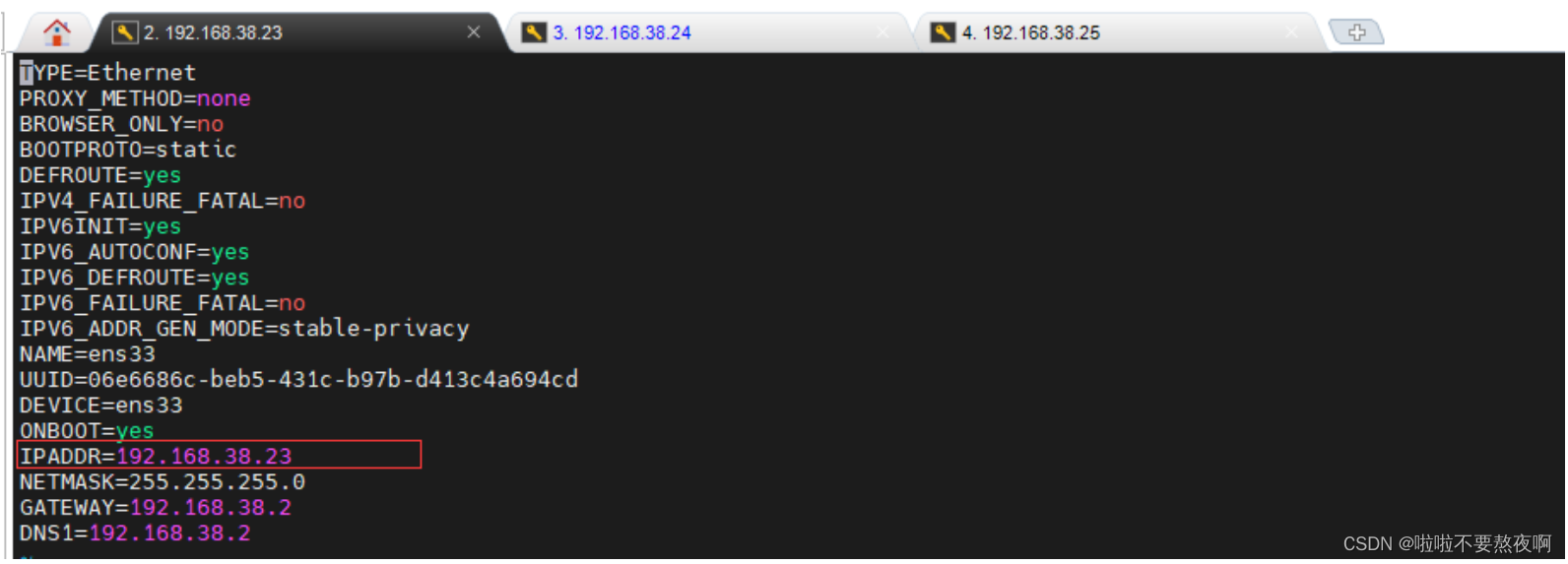
⑤ 修改每台虚拟机的IP地址:
vi /etc/sysconfig/network-scripts/ifcfg-ens33
hadoop-101 虚拟机的 IPADDR 的地址改为:192.168.38.23;hadoop-102 的改为192.168.38.24;hadoop-103 虚拟机的 IPADDR 的地址改为:192.168.38.25;
⑥ 修改每台虚拟机的主机名称 hostname:
vi /etc/hostname
hadoop-101 虚拟机的 hostname 改为:hadoop101;hadoop-102 虚拟机的改为:hadoop102;hadoop-103 虚拟机的 hostname 的地址改为:hadoop103;

⑦ 将每台虚拟机的 hostname 和 ip 绑定,添加下面三行:
vi /etc/hosts

⑧ 执行 reboot 命令重启每台虚拟机,然后使用 mobaxterm/xshell工具连接每台虚拟机。
2. Zookeeper 集群搭建
在前面文章 Kafka - 03 Kafka安装 | 单机环境搭建 | 伪集群环境搭建 (一台虚拟机) 中,我使用一台虚拟机环境搭建了kafka伪集群,而我们现在的3台虚拟机是基于这台虚拟机克隆的,因此 jdk 、 zookeeper 、kafka 已经安装了,我们只需要修改一些配置文件就行了,他们的安装目录如下:

zookeeper-01、zookeeper-02、zookeeper-03 这三个安装目录是搭建伪集群使用的,这里搭建真正的集群环境可以不用管他们,我们直接使用每个节点的 zookeeper-3.4.14 安转目录:

① 配置每一个 zookeeper 节点的 dataDir,克隆之前已经配置过,这里直接删除重新创建data目录:

② 在每个zookeeper的 data 目录下创建一个 myid 文件,内容分别是0、1、2 。myid 这个文件就是记录每个服务器的ID
[root@hadoop101 zookeeper-3.4.14]# cd data
[root@hadoop101 data]# vi myid
[root@hadoop101 data]#
0
[root@hadoop102 zookeeper-3.4.14]# cd data
[root@hadoop102 data]# vi myid
[root@hadoop102 data]#
1
[root@hadoop103 zookeeper-3.4.14]# cd data
[root@hadoop103 data]# vi myid
[root@hadoop103 data]#
2
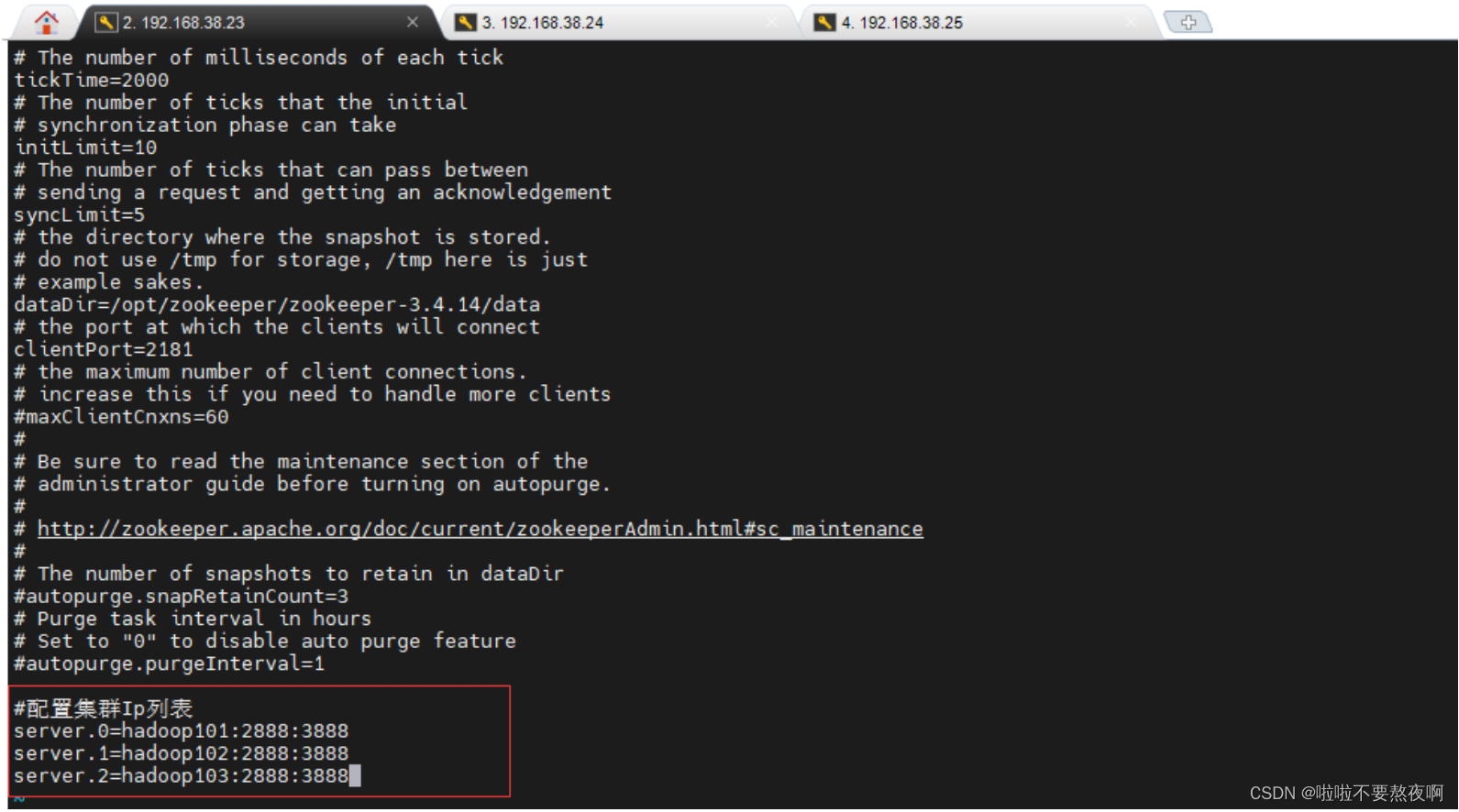
③ 在每一个zookeeper 的 zoo.cfg 配置集群服务器IP列表
server.服务器ID=服务器IP地址:服务器之间通信端口:服务器之间投票选举端口
后面的两个端口在三个节点中只要不同即可,服务器ID就是myid文件中的值。
server.0=192.168.38.23:2888:3888
server.1=192.168.38.24:2888:3888
server.2=192.168.38.25:2888:3888

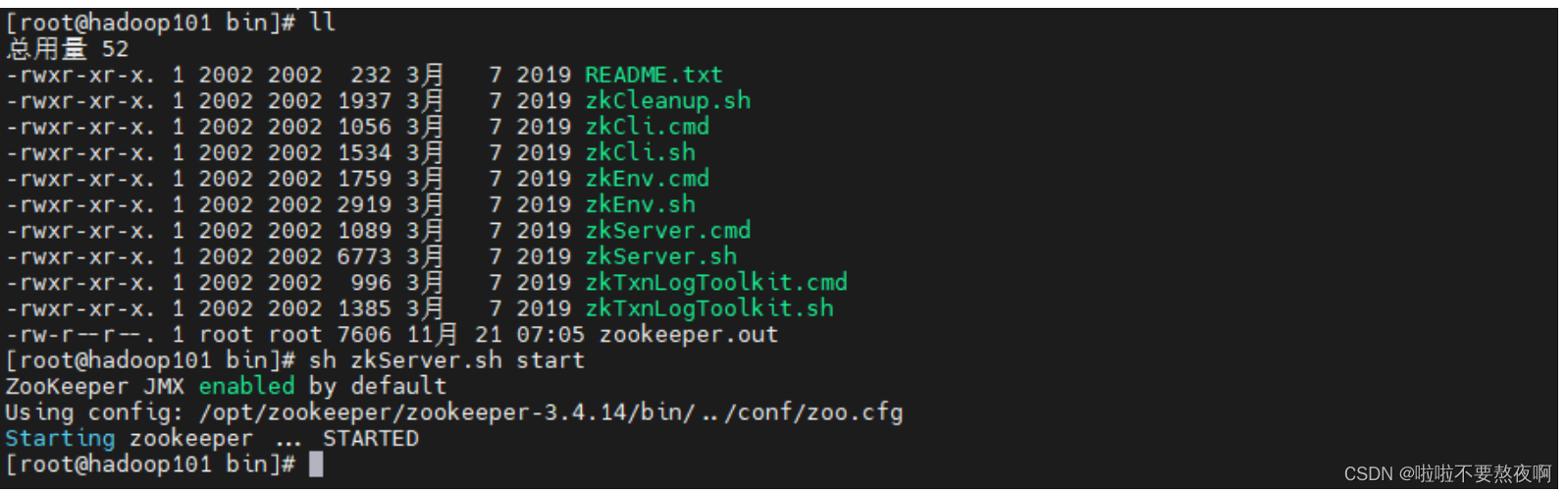
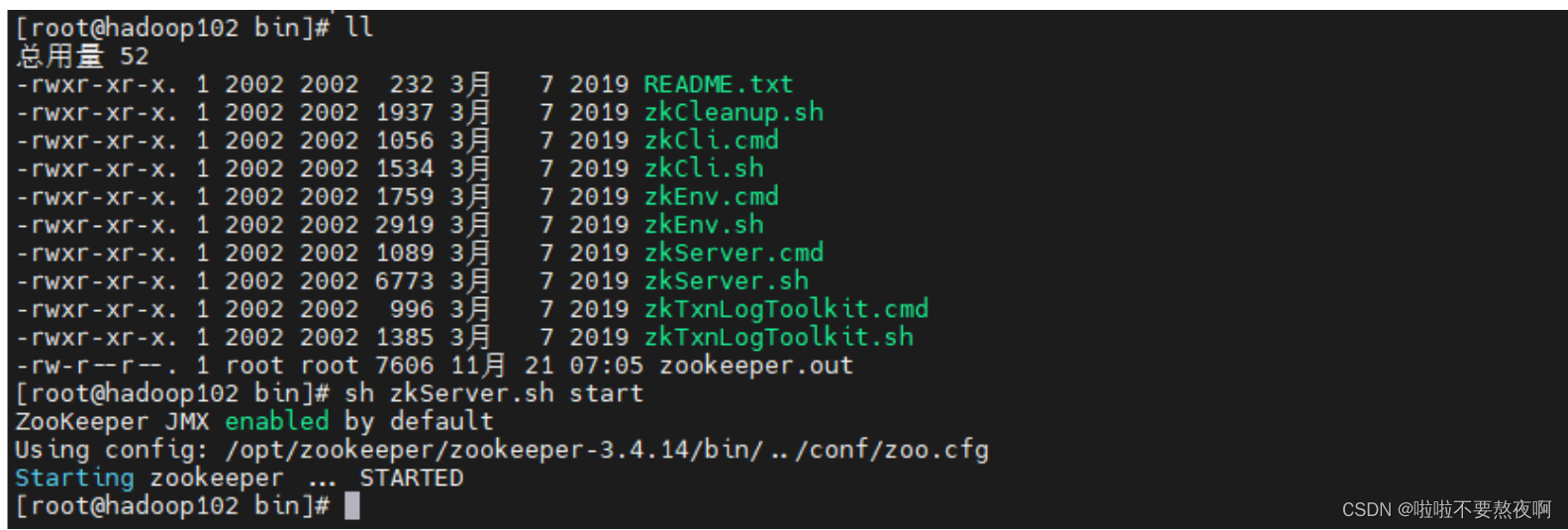
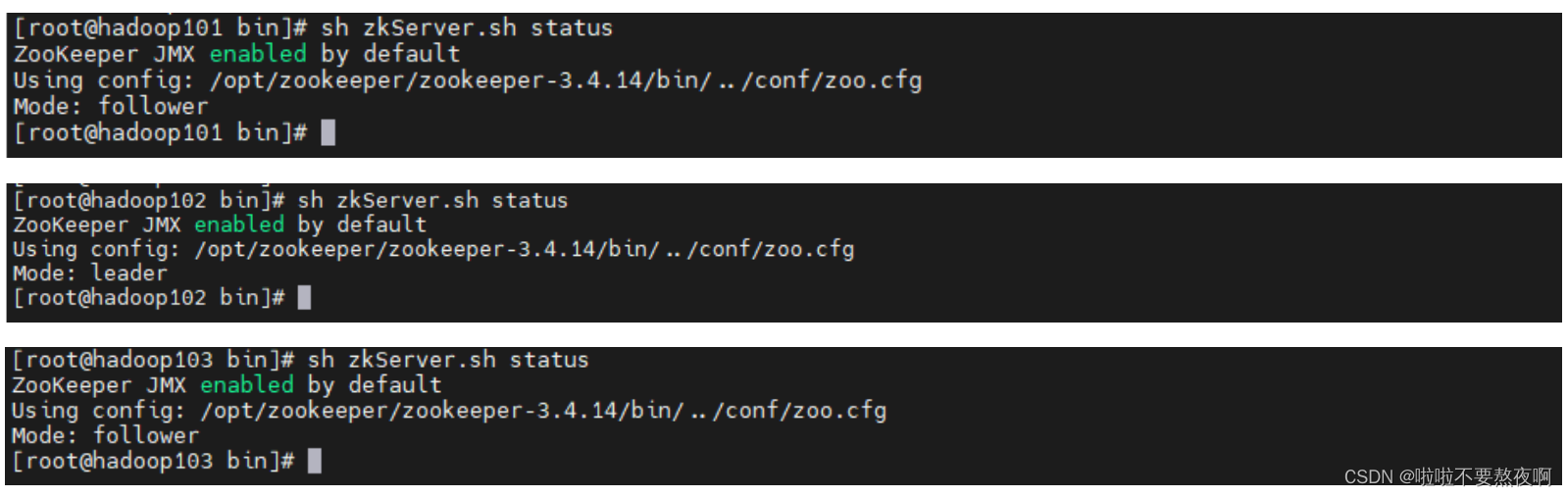
④ 启动集群:启动集群就是分别启动每个实例,启动后我们查询一下每个实例的运行状态。
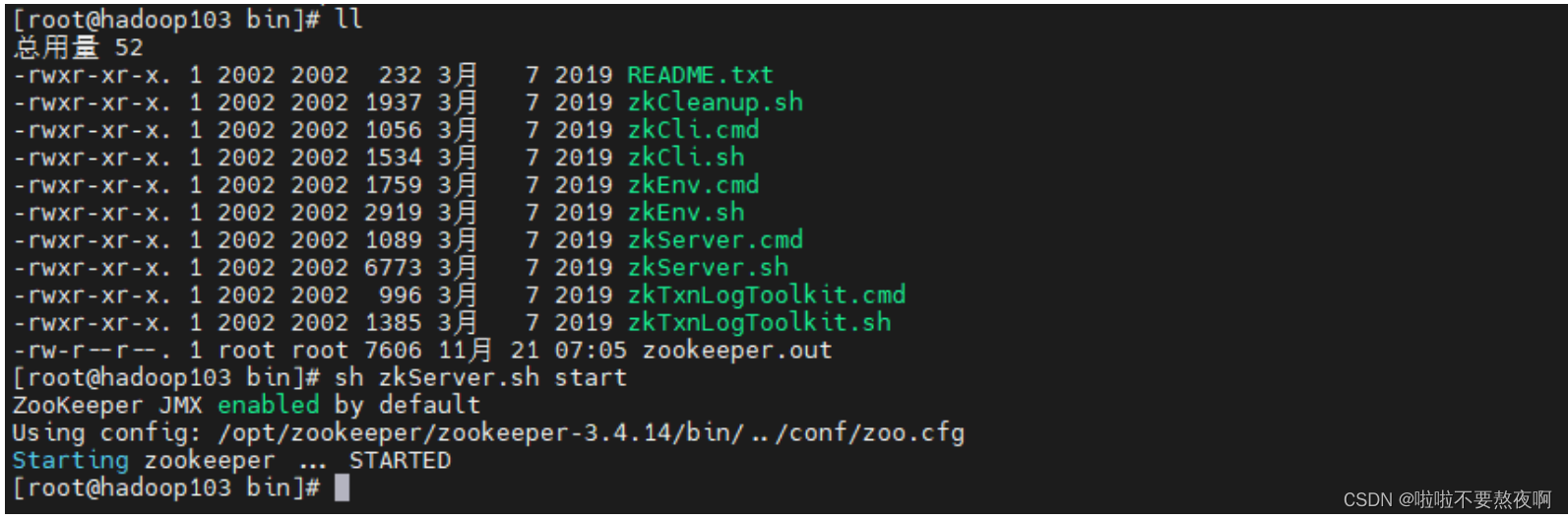
查看启动状态报错 Error contacting service. It is probably not running 原因:
- 必须3个服务都启动再查看状态,否则在查看状态时会报错;
- 必须关闭防火墙;
3. Kafka 集群搭建
在前面文章 Kafka - 03 Kafka安装 | 单机环境搭建 | 伪集群环境搭建 (一台虚拟机) 中,我使用一台虚拟机环境搭建了kafka伪集群,而我们现在的3台虚拟机是基于这台虚拟机克隆的,因此 jdk 、 zookeeper 、kafka 已经安装了,我们只需要修改一些配置文件就行了,他们的安装目录如下:

kafka-01、 kafka-02、 kafka-03这三个安装目录是搭建伪集群使用的,这里搭建真正的集群环境可以不用管他们,我们直接使用每个节点的 kafka_2.12-2.2.1安转目录:

修改每个kafka节点的server.properties配置文件:
broker.id=0
listeners=PLAINTEXT://192.168.38.23:9092
advertised.listeners=PLAINTEXT://192.168.38.23:9092
zookeeper.connect=hadoop101:2181,hadoop102:2181,hadoop103:2181/kafka_cluster
broker.id=1
listeners=PLAINTEXT://192.168.38.24:9092
advertised.listeners=PLAINTEXT://192.168.38.24:9092
zookeeper.connect=hadoop101:2181,hadoop102:2181,hadoop103:2181/kafka_cluster
broker.id=2
listeners=PLAINTEXT://192.168.38.25:9092
advertised.listeners=PLAINTEXT://192.168.38.25:9092
zookeeper.connect=hadoop101:2181,hadoop102:2181,hadoop103:2181/kafka_cluster
① 配置 log.dirs,克隆之前已经配置过,因此直接删除重新创建logs目录
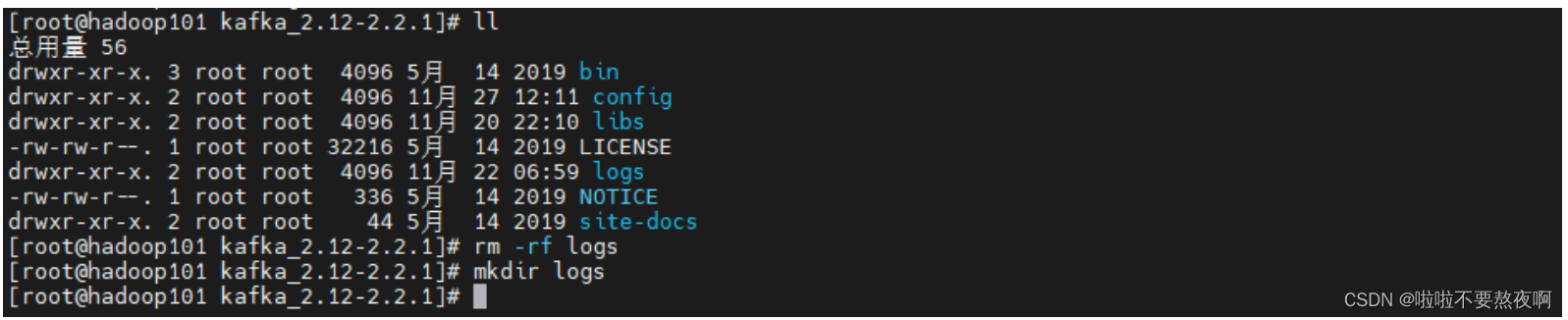
② 配置 broker.id,这是Kafka在整个集群当中的唯一身份标识,每个节点不能重复。
③ 配置 zookeeper.connect,zookeeper根目录下有个 zookeeper节点,正常情况我们可以按照下面这样配置,那么kafka集群信息就会放入zookeeper节点的各个目录中:
zookeeper.connect=hadoop101:2181,hadoop102:2181,hadoop103:2181
如果我们想把kafka集群信息放到一个文件夹kafka_cluster下,可以添加在按照下面这样配置:
zookeeper.connect=hadoop101:2181,hadoop102:2181,hadoop103:2181/kafka_cluster
④ 配置 listeners,允许外部端口连接。
⑤ 配置 advertised.listeners,外部代理地址。
⑥ 启动每个 kafka 实例:
bin/kafka-server-start.sh config/server.properties
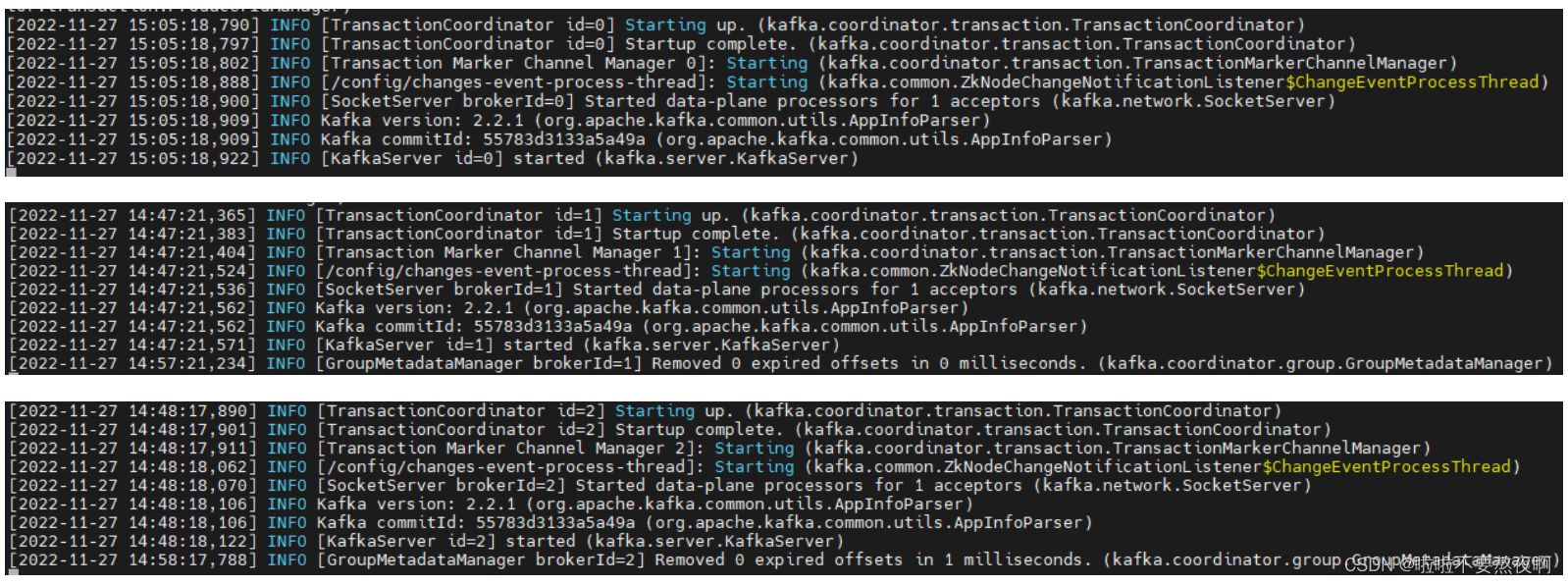
4. 测试消息发送和消费
1. 主题操作
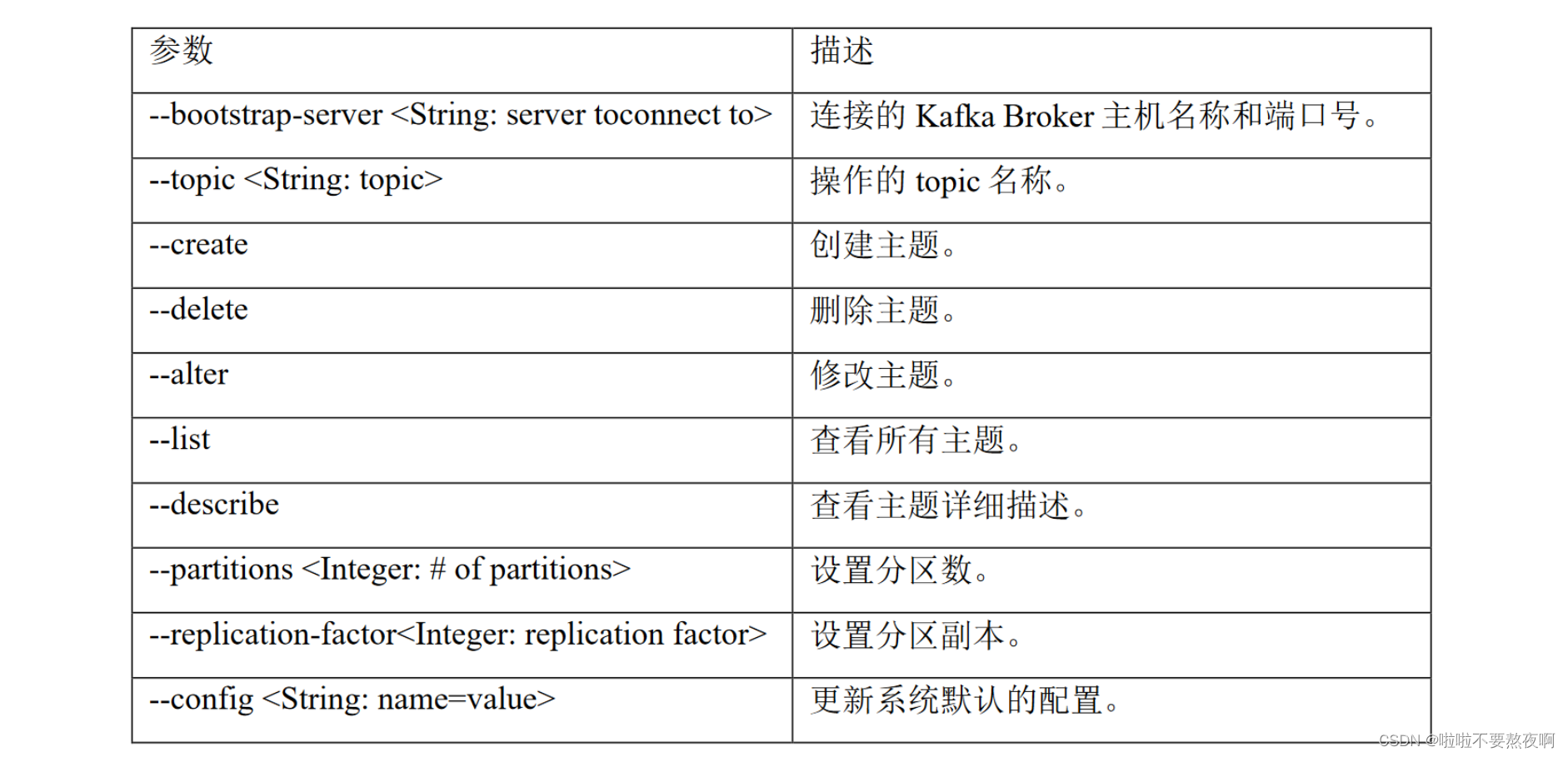
1. 创建主题:
[root@hadoop101 kafka_2.12-2.2.1]# bin/kafka-topics.sh --bootstrap-server hadoop101:9092 --create --partitions 1 --replication-factor 3 --topic test1
2. 查看主题详情:
[root@hadoop101 kafka_2.12-2.2.1]# bin/kafka-topics.sh --bootstrap-server hadoop101:9092 --describe --topic test1
Topic:test1 PartitionCount:1 ReplicationFactor:3 Configs:segment.bytes=1073741824
Topic: test1 Partition: 0 Leader: 0 Replicas: 0,1,2 Isr: 0,1,2
3. 查看所有主题:
[root@hadoop101 kafka_2.12-2.2.1]# bin/kafka-topics.sh --bootstrap-server hadoop101:9092 --list
__consumer_offsets
test
test1
2. 生产者生产消息

[root@hadoop101 kafka_2.12-2.2.1]# bin/kafka-console-producer.sh --broker-list hadoop101:9092 --topic test1

3. 消费者消费消息
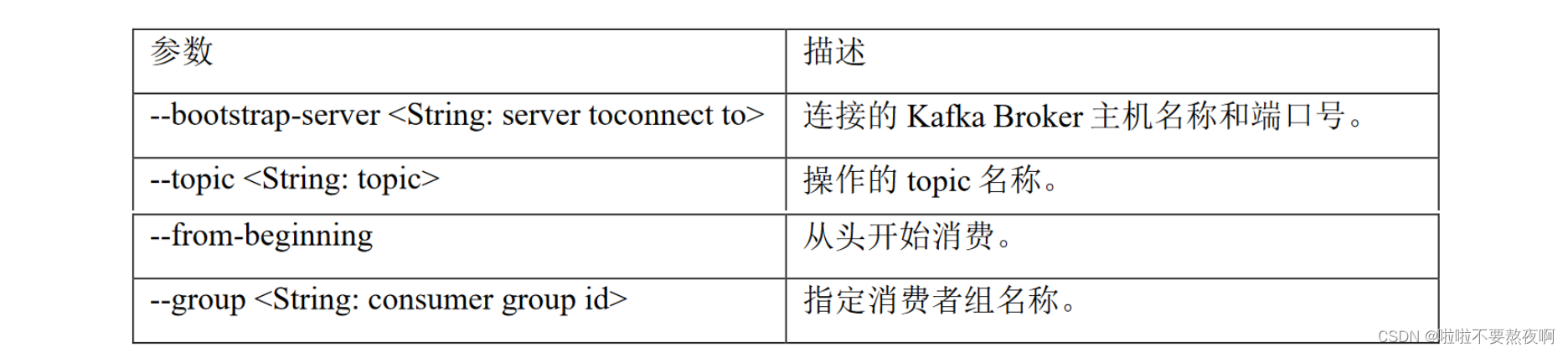
[root@hadoop101 kafka_2.12-2.2.1]# bin/kafka-console-consumer.sh --bootstrap-server hadoop101:9092 --topic test1

版权归原作者 我一直在流浪 所有, 如有侵权,请联系我们删除。