
HADOOP安装步骤
一.创建Hadoop用户
二.更新apt和安装vim编辑器
更新apt:
sudo apt-get install update
安装VIM编辑器:
apt install vim
在弹出的提示中输入yes(y)
三、安装SSH和配置SSH无密码登录
apt install openssh-server
ssh登录:
ssh localhost
退出ssh登录:
exit
ssh无密码登录配置:
cd ~/.ssh/
ssh-keygen -t rsa
cat ./id_rsa.pub >>./authorized_keys
四、安装vim编辑器
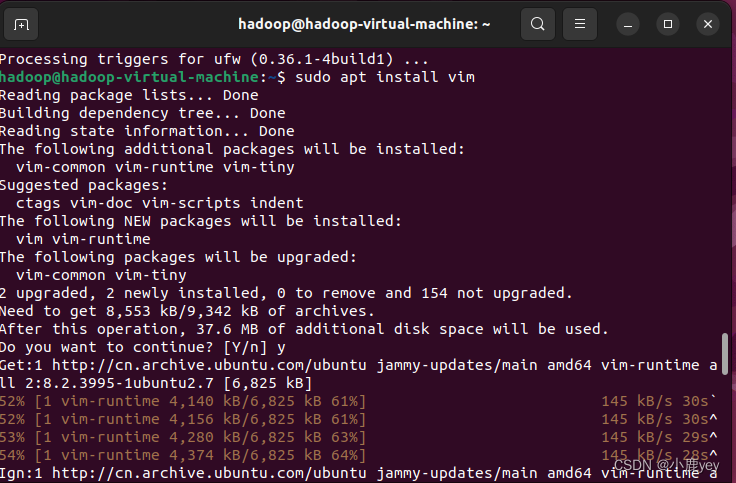
sudo apt install vim
五、安装Java环境
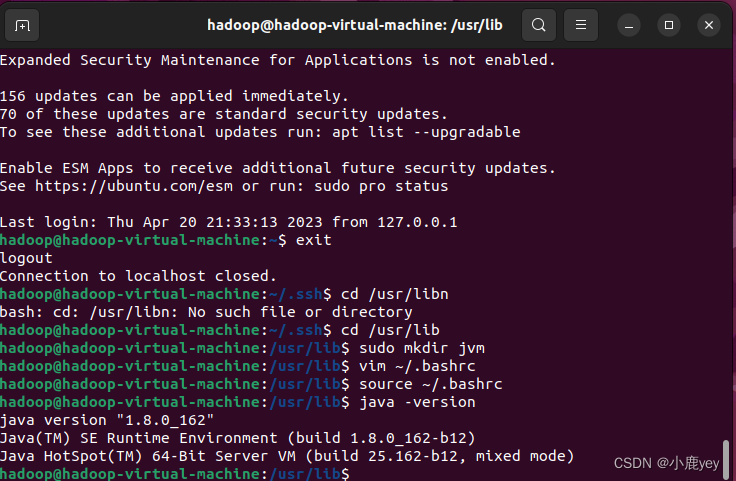
cd /usr/lib
sudo mkdir jvm
进入jdk的存放目录:
sudo tar -zxvf (安装包)-C/usr/lib/jvm
设置环境变量:
vim ~/.bashrc
在文件开头添加:
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_162
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
保存.bashrc文件并退出vim编辑器。然后,继续执行如下命令让.bashrc文件的配置立即生效:
source ~/.bashrc
查看配置是否生效:
java -version
返回以下信息即为成功:
java version "1.8.0_162"Java(TM) SE RuntimeEnvironment(build 1.8.0_162-b12)JavaHotSpot(TM)64-BitServer VM (build 25.162-b12, mixed mode)
六、安装hadoop
在安装包所在目录打开终端,解压安装包:
sudo tar -zxvf hadoop-3.1.3.tar.gz -C/usr/local
cd /usr/local
sudo mv ./hadoop-3.1.3/./hadoop # 将文件夹名改为hadoop
sudo chown -R hadoop ./hadoop # 修改文件权限
检查 Hadoop:
cd /usr/local/hadoop
./bin/hadoop version
安装成功输出以下内容:
Hadoop3.1.3Source code repository https://gitbox.apache.org/repos/asf/hadoop.git -r ba631c436b806728f8ec2f54ab1e289526c90579
Compiled by ztang on 2019-09-12T02:47Z
Compiledwithprotoc2.5.0From source withchecksum ec785077c385118ac91aadde5ec9799
This command was run using /usr/local/hadoop/share/hadoop/common/hadoop-common-3.1.3.jar
七、Hadoop伪分布式模式配置
cd ./etc/hadoop
vim core-site.xml
在 core-site.xml 中添加如下文件内容:
<configuration><property><name>hadoop.tmp.dir</name><value>file:/usr/local/hadoop/tmp</value><description>Abasefor other temporary directories.</description></property><property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property></configuration>
编辑完成后,按esc键退出,然后在底部输入 :wq(保存退出)
在hdfs-site-xml文件中输入以下内容:
<configuration><property><name>dfs.replication</name><value>1</value></property><property><name>dfs.namenode.name.dir</name><value>file:/usr/local/hadoop/tmp/dfs/name</value></property><property><name>dfs.datanode.data.dir</name><value>file:/usr/local/hadoop/tmp/dfs/data</value></property></configuration>
保存退出
修改配置文件以后,要执行名称节点的格式化,命令如下:
cd /usr/local/hadoop
./bin/hdfs namenode -format
成功后输出以下页面: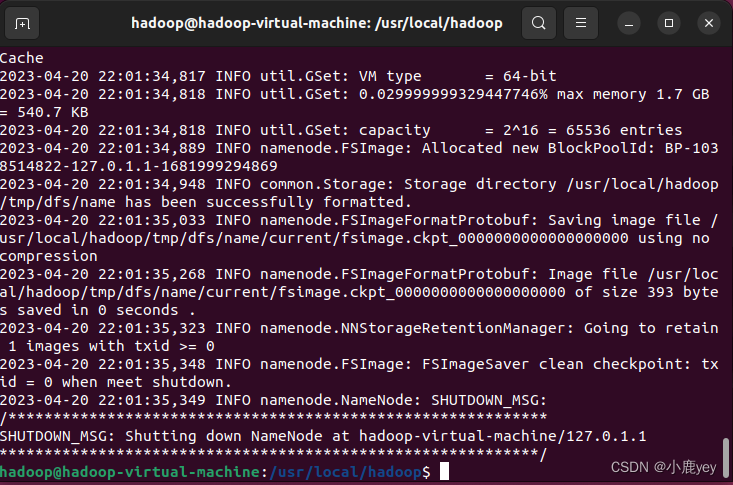
注意:名称节点不能多次格式化,多次格式化后启动jps时Datanode将不会启动!!!
八、伪分布式模式配置
开启 NameNode 和 DataNode 守护进程
cd /usr/local/hadoop
./sbin/start-dfs.sh
节点成功开启后显示如下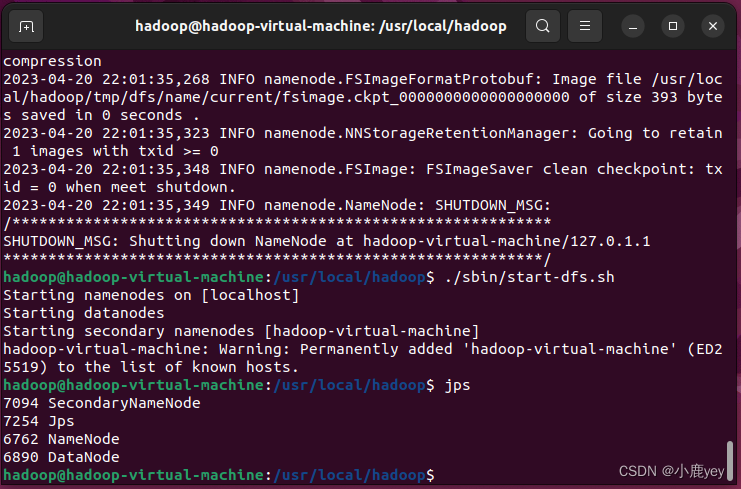
若要关闭 Hadoop,则运行:
./sbin/stop-dfs.sh
注意: 下次启动 hadoop 时,无需进行 NameNode 的初始化,只需要运行 ./sbin/start-dfs.sh 就可以!!!
本文转载自: https://blog.csdn.net/qq_45283292/article/details/130230409
版权归原作者 小鹿yey 所有, 如有侵权,请联系我们删除。
版权归原作者 小鹿yey 所有, 如有侵权,请联系我们删除。