
** ** Selenium 是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera,Edge等。这个工具的主要功能包括:测试与浏览器的兼容性——测试应用程序看是否能够很好得工作在不同浏览器和操作系统之上。测试系统功能——创建回归测试检验软件功能和用户需求。支持自动录制动作和自动生成。
一、如何安装:
- 先在python环境下安装selenium依赖包
pip uninstall selenium
配置浏览器驱动
这个得根据你下载的浏览器版本去安装对应的浏览器驱动,我以谷歌浏览器为例: 这些是以前的很多版本的驱动
点击这里下载http://chromedriver.storage.googleapis.com/index.html 要是你是最新的浏览器可以看一下这一篇文章:
selenium安装谷歌浏览器驱动chromedriver 122/123/124新版本_chromedriver123-CSDN博客文章浏览阅读3.3w次,点赞41次,收藏83次。根据自己浏览器的版本来选择驱动,status 要选200的。_chromedriver123https://blog.csdn.net/linglong_L/article/details/136283810?ops_request_misc=&request_id=&biz_id=102&utm_term=python%20selenium%20%E8%B0%B7%E6%AD%8C%E6%B5%8F%E8%A7%88%E5%99%A8%E6%9C%80%E6%96%B0%E9%A9%B1%E5%8A%A8&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-0-136283810.142%5Ev100%5Epc_search_result_base7&spm=1018.2226.3001.4187
二、具体使用
安装完了我们看看如何调用:
from selenium import webdriver #引入依赖
browser = webdriver.Chrome() # 使用谷歌浏览器
browser.get('http://www.baidu.com/') #使用谷歌打开百度
当出现这个页面就说明你的selenium安装成功 我们就可以进行下一步的操作了。
这一篇文档主要讲的就是selenium的八大元素定位
find_element()系列:用于定位单个的页面元素。find_elements()系列:用于定位一组页面元素,获取到的是一组列表。
1. id定位元素
find_element(By.ID,' ') 根据元素的id属性值定位
下面是执行 **打开百度 并搜索你好**
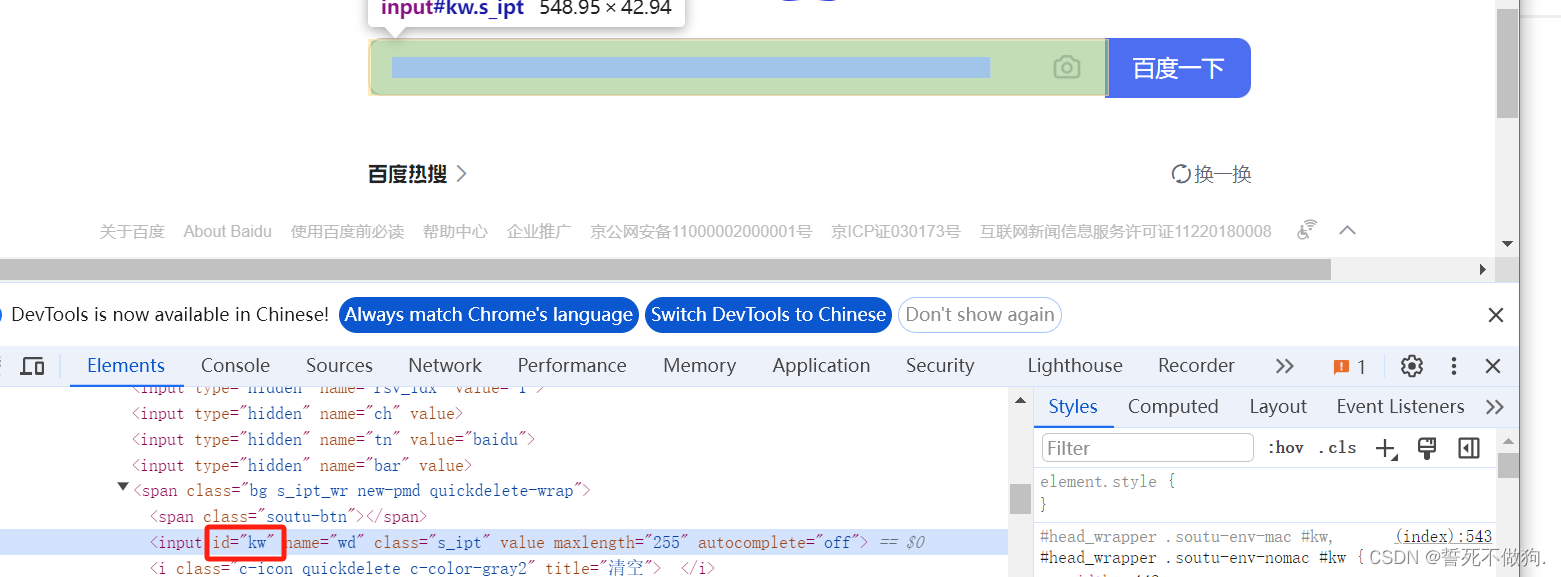

可以看到 这个搜索的input框的id为‘kw’ ,百度一下的按钮的id为‘su’
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
browser = webdriver.Chrome()
browser.get('http://www.baidu.com/')
#.send_keys('你好') 在id为‘kw’的元素定位内输入你好
element = browser.find_element(By.ID,'kw').send_keys('你好')
# .click()id为‘su’的元素触发点击按钮
element = browser.find_element(By.ID,'su').click()
sleep(5) #持续时间5秒
browser.quit() #退出浏览器
2. name定位元素
find_element(By.NAME,' ')根据元素的name属性值定位,定位到的标签不一定是唯一的。
我们还是先用f12查看页面的一个name元素
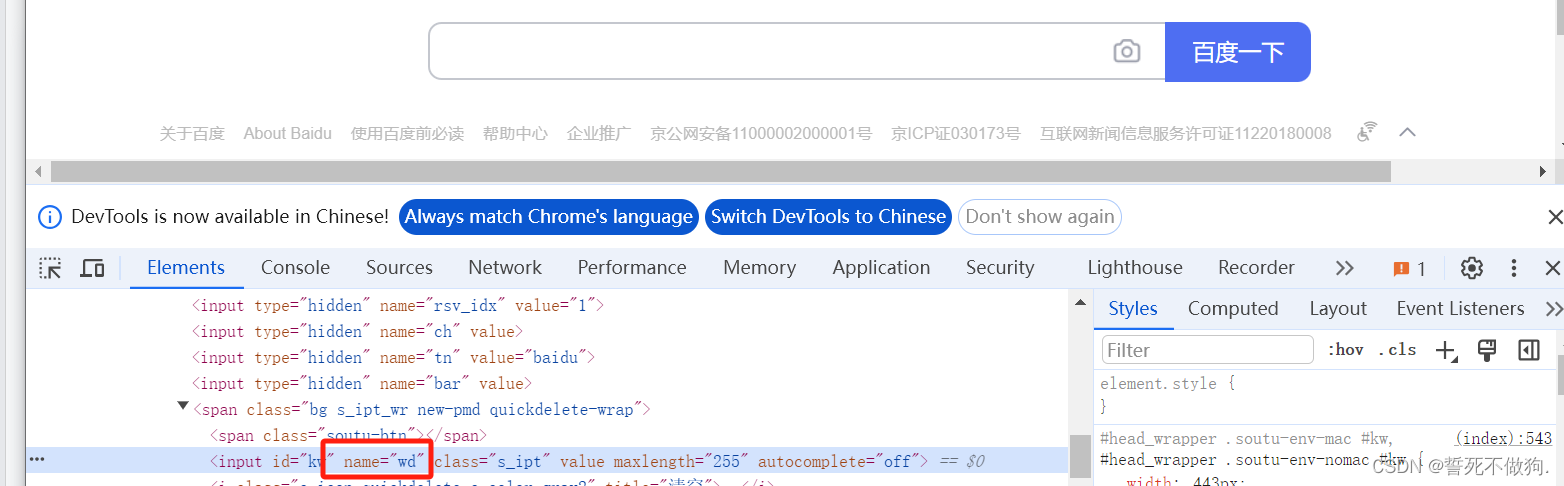
输入框的 name是‘wd’
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
browser = webdriver.Chrome()
browser.get('http://www.baidu.com/')
element = browser.find_element(By.NAME,'wd').send_keys('你好')
element = browser.find_element(By.ID,'su').click()
sleep(5)
browser.quit()
3. classname定位元素
这一次我们定位百度搜索的底部第二个超链接
还是先看元素 就会发现 三个class 名都一样
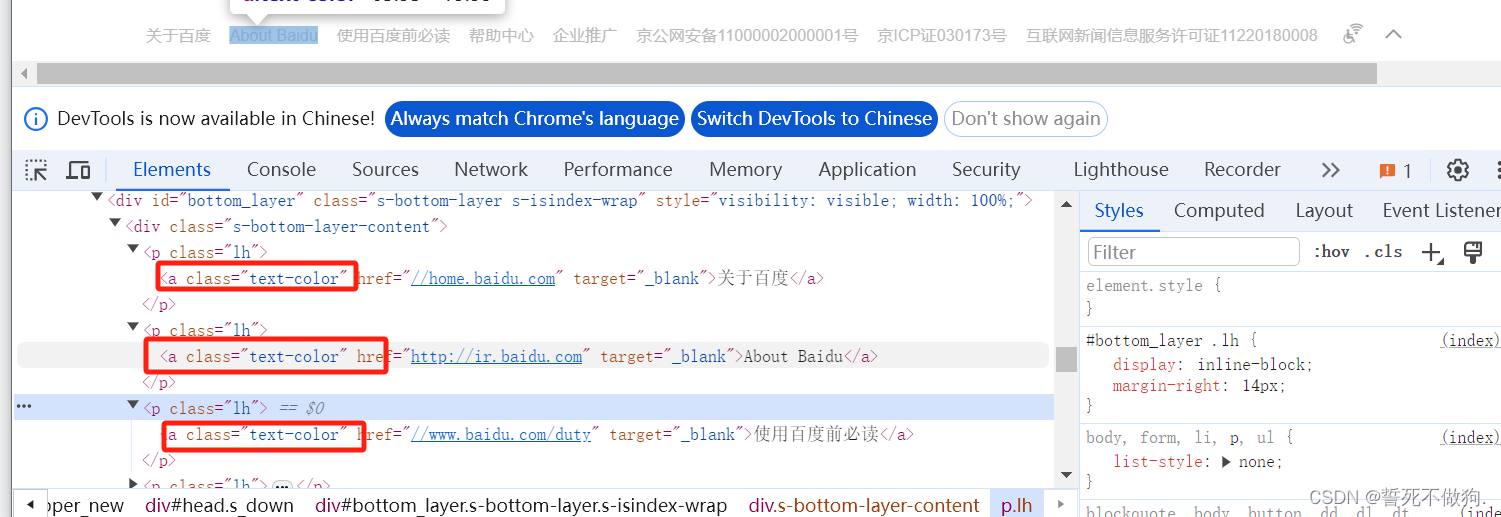
这个时候如果还是非要用classname去定位元素的话我们可以使用 find_elements去定位
find_elements 是**定位后返回列表** , 一般会返回多个元素 。而将这些元素都放在一个列表中 。所以 ,当获取其中的某一个元素时 ,就必须使用**列表中的索引**来获取
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
browser = webdriver.Chrome()
browser.get('http://www.baidu.com/')
element = browser.find_elements(By.CLASS_NAME,'text-color')[1].click()
sleep(5)
browser.quit()
4. tag标签定位元素
这是通过标签去定位元素 不唯一

输入框和回车按钮分别是第八个和第九个 我们还是得通过 find_elements去使用
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
browser = webdriver.Chrome()
browser.get('http://www.baidu.com/')
element = browser.find_elements(By.TAG_NAME,'input')[7].send_keys('你好')
element = browser.find_elements(By.TAG_NAME,'input')[8].click()
sleep(5)
browser.quit()
5. link_text链接文本定位元素 精确定位
link
表示包含有属性
href
的标签元素 根据链接文本全匹配进行精确定位。
这一次我们访问最上面的新闻

from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
browser = webdriver.Chrome()
browser.get('http://www.baidu.com/')
element = browser.find_element(By.LINK_TEXT,'新闻').click()
sleep(5)
browser.quit()
6. link_text链接文本定位元素 模糊定位
find_element(By.PARTIAL_LINK_TEXT,' ')
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
browser = webdriver.Chrome()
browser.get('http://www.baidu.com/')
element = browser.find_element(By.PARTIAL_LINK_TEXT,'新').click()
sleep(5)
browser.quit()
7. xpath定位
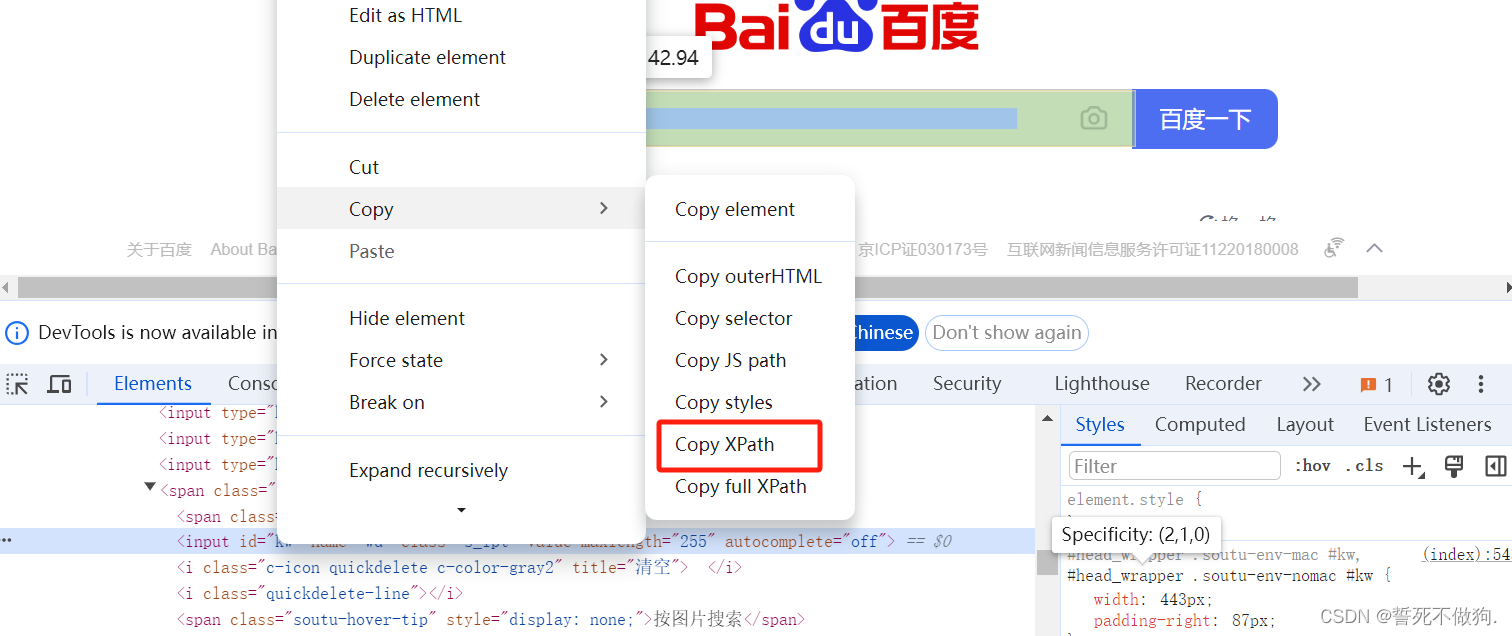
这一个大家可以先简单使用这个直接用xpath去复制
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
browser = webdriver.Chrome()
browser.get('http://www.baidu.com/')
element = browser.find_element(By.XPATH,'//*[@id="kw"]').send_keys('你好')
sleep(5)
browser.quit()
8. css选择器定位
find_element(By.CSS_SELECTOR,‘ ’)根据元素的css选择器来完成定位,可以准确定位任何元素
我们想要定位百度搜索页面最上面的第二个超链接
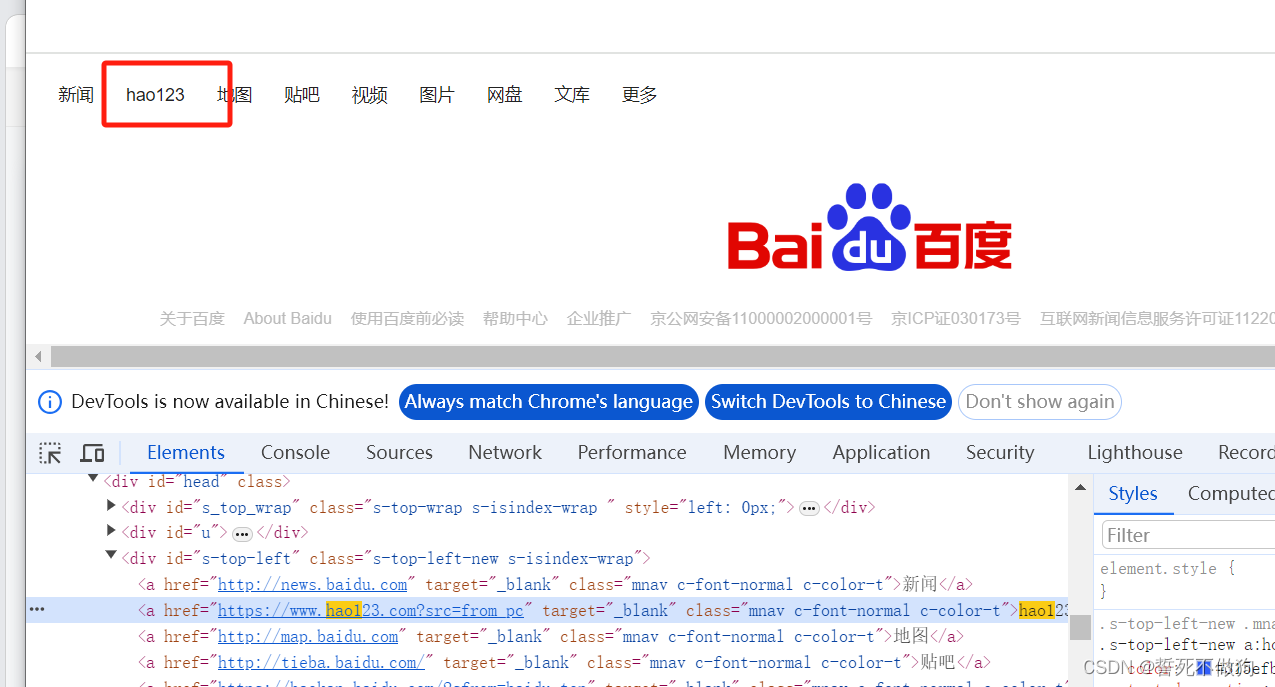
这个时候我们可以使用css选择器加find_elements去定位
大家这样写的话会报错 因为这个class名里面有空格
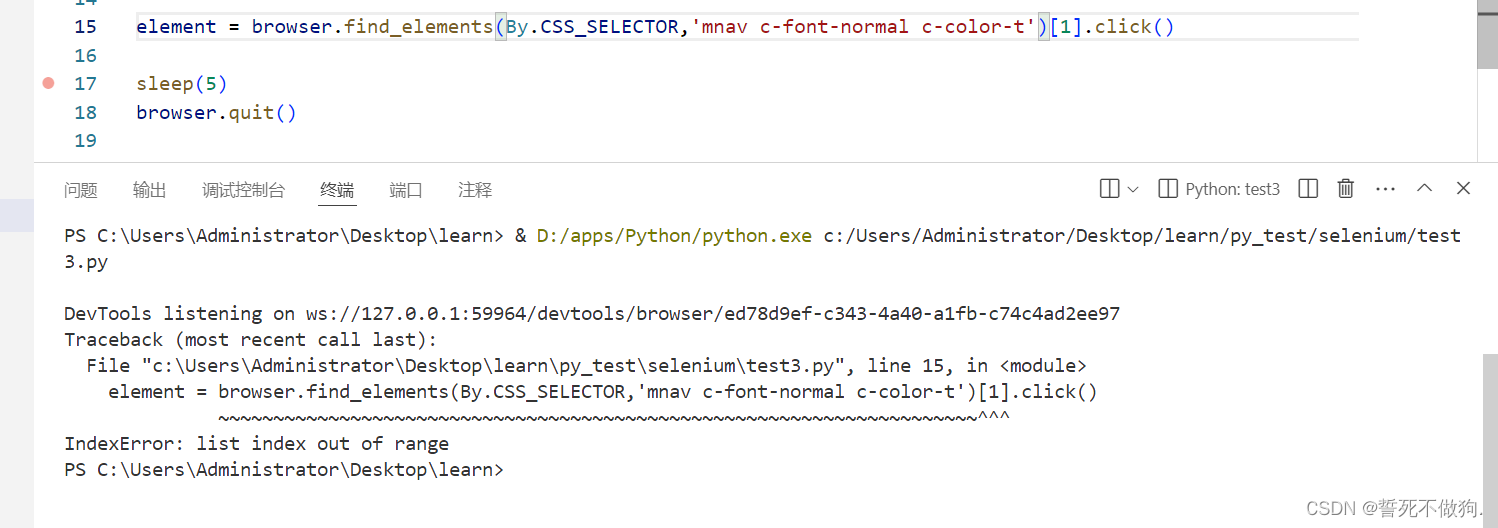
优化一下 用class=‘xxx xxx’去表述
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
browser = webdriver.Chrome()
browser.get('http://www.baidu.com/')
element = browser.find_elements(By.CSS_SELECTOR,"[class='mnav c-font-normal c-color-t']")[1].click()
sleep(5)
browser.quit()
成功!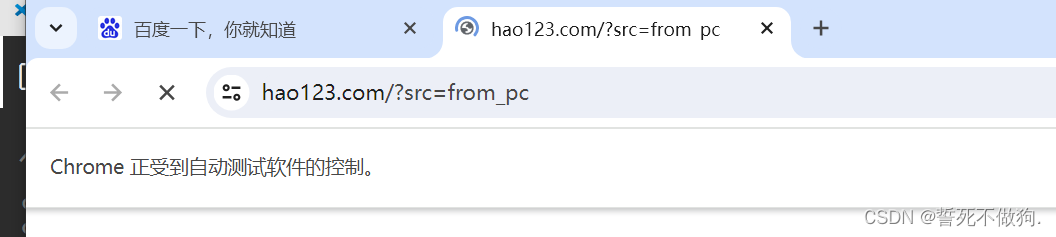
三、结语
以上就是selenium的八大元素定位的一个具体使用方式
版权归原作者 誓死不当狗. 所有, 如有侵权,请联系我们删除。