
我的是hive3.1.3 spark3.3.0(请先将自己的 hive on mr 搭建完场,有简单了解在搞这个)
1.下载hive源码
2. maven编译:mvn clean -DskipTests package -Pdist (idea 编译不行,能行的评论告诉我)
右键 - Git Bash

- idea打开项目,右键pom 添加成maven项目
- 修改pom中自己所需依赖的版本
改为自己所需版本
<spark.version>3.3.0</spark.version><scala.binary.version>2.12</scala.binary.version><scala.version>2.12.15</scala.version><SPARK_SCALA_VERSION>2.12</SPARK_SCALA_VERSION>
编译报错(idea build查看错误位置也可)解决参考地址
往下滑查看文中的
< 整合spark3.0.0
< 改造原来hive(可略过)我补充下
<<1. 我是将原来的 conf 文件中用到的配置文件 copy 到新的项目中
<<2. 将原来 metastore_db copy过来(不知跨什么版本会有问题 欢迎评论)
5. 重新命令编译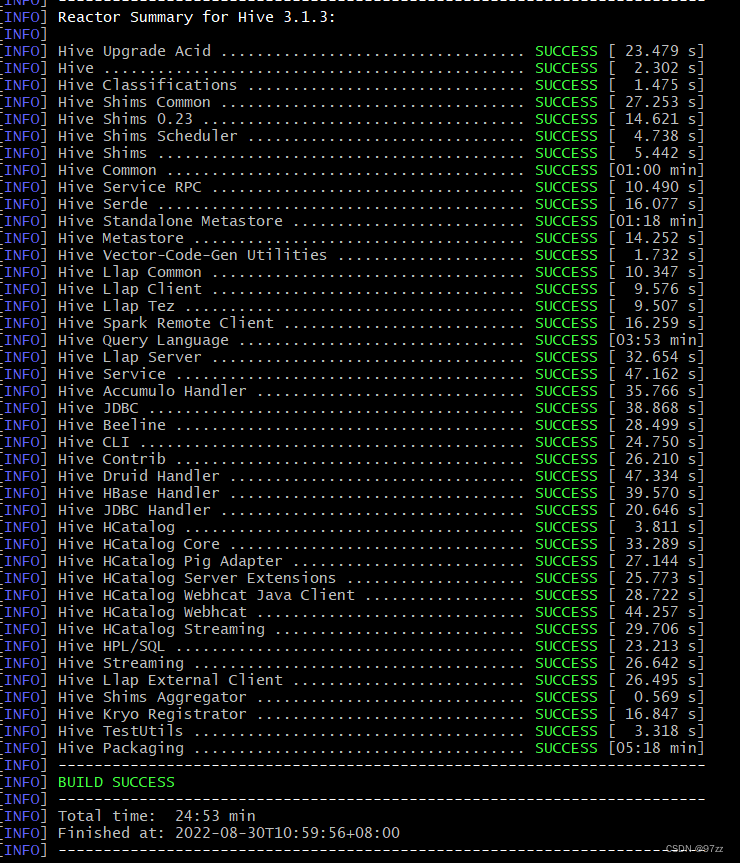
成功后找到编译完的包:packaging\apache-hive-3.1.3-bin.tar.gz ,上传到服务器解压,再idea项目中下图的包上传到 hive/lib 下
参考自此链接 - Hive On Spark配置 标题下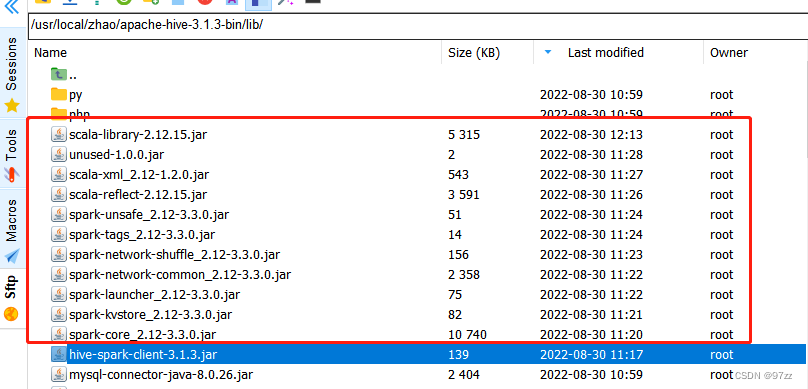
将原来的元数据服务 kill 掉,然受启动新的
hive --service metastore &
hive 启动验证:
- 看看元数据是否正常
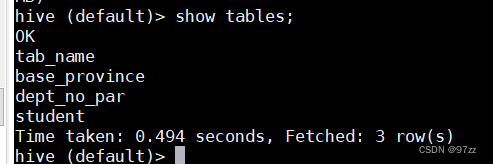
- create table student(id int, name string);
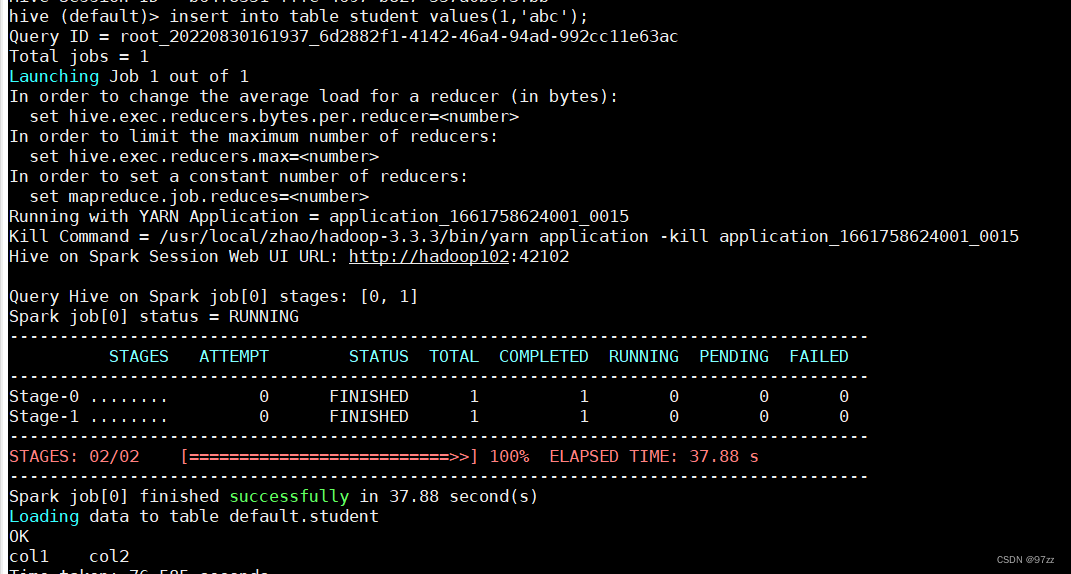
- insert into table student values(1,‘abc’);
hive-site.xml 要注意的配置
<property><name>spark.yarn.jars</name><value>hdfs://hadoop102:9000/spark-jars/*</value>
</property>
<property>
<name>hive.spark.client.connect.timeout</name>
<value>30000</value>
</property>
<property>
<name>hive.spark.client.server.connect.timeout</name>
<value>300000</value>
</property>
<property>
<name>hive.spark.client.future.timeout</name>
<value>1200</value>
</property>
注意:
环境变量要不要改 记得 source /etc/profile(只有当前及之后的会话才生效)
本文转载自: https://blog.csdn.net/qq_39035267/article/details/126608808
版权归原作者 97zz 所有, 如有侵权,请联系我们删除。
版权归原作者 97zz 所有, 如有侵权,请联系我们删除。