
selenium是一个Web自动化测试工具,可以直接运行在浏览器上·支持所有主流的浏览器.可以根据我们的指令,让浏览器自动加载页面,获取需要的数据,基础页面截图等。
使用pip install selenium命令下载selenium模块。
运行下列代码:
from selenium import webdriver
driver = webdriver.Chrome()

说明没有下载对应浏览器的驱动,这里使用谷歌浏览器
注意:
需要根据浏览器版本下载对应插件。
插件下载地址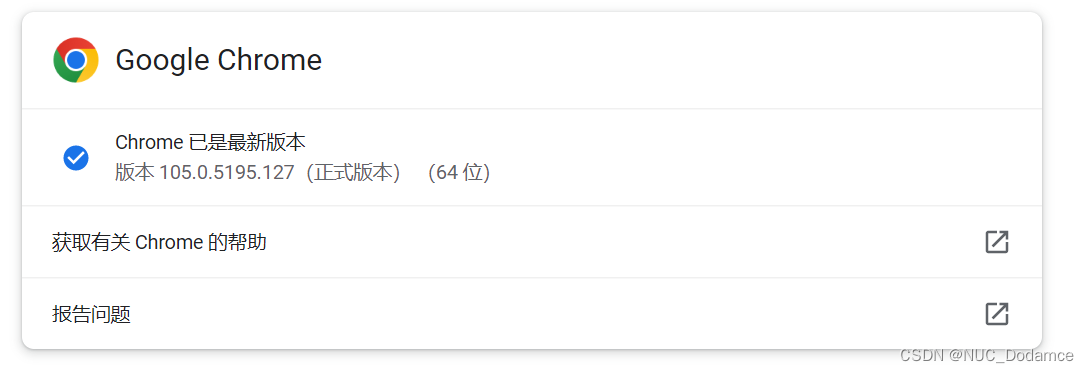

如果没有对应版本,直接选择最近版本的插件下载即可,这里选择.52版本即可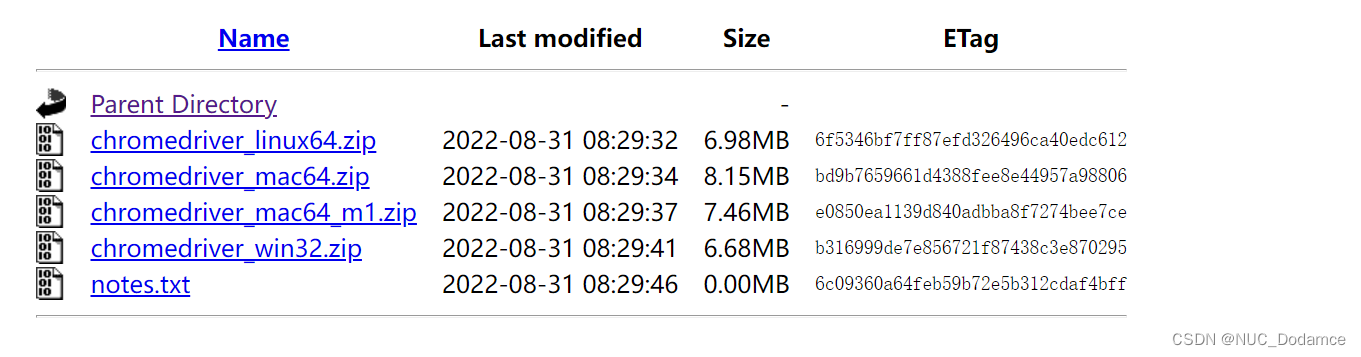
下载对应平台即可。
下载好后,解压,把可执行程序放到项目同级目录下,或者可以在函数webdriver.Chrome()上传递这个插件路径
driver = webdriver.Chrome(executable_path=r"F:\chrome\chromedriver.exe")
(可能会因方法弃用爆红字,忽略即可)
重新运行代码可以发现不报错了。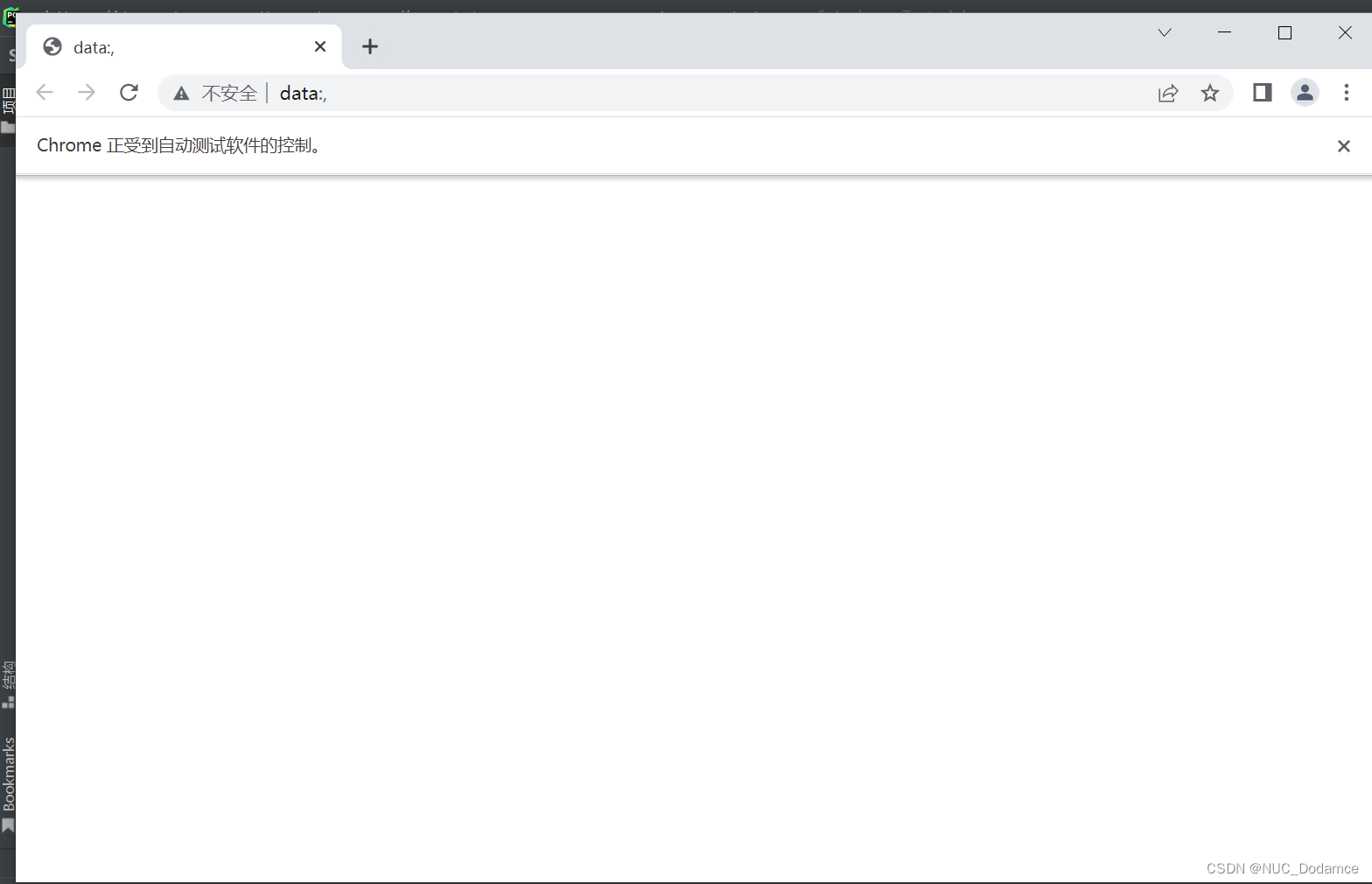
文章目录
1. selenium练习
selenium有很多种定位方式,如下表
自动搜索
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
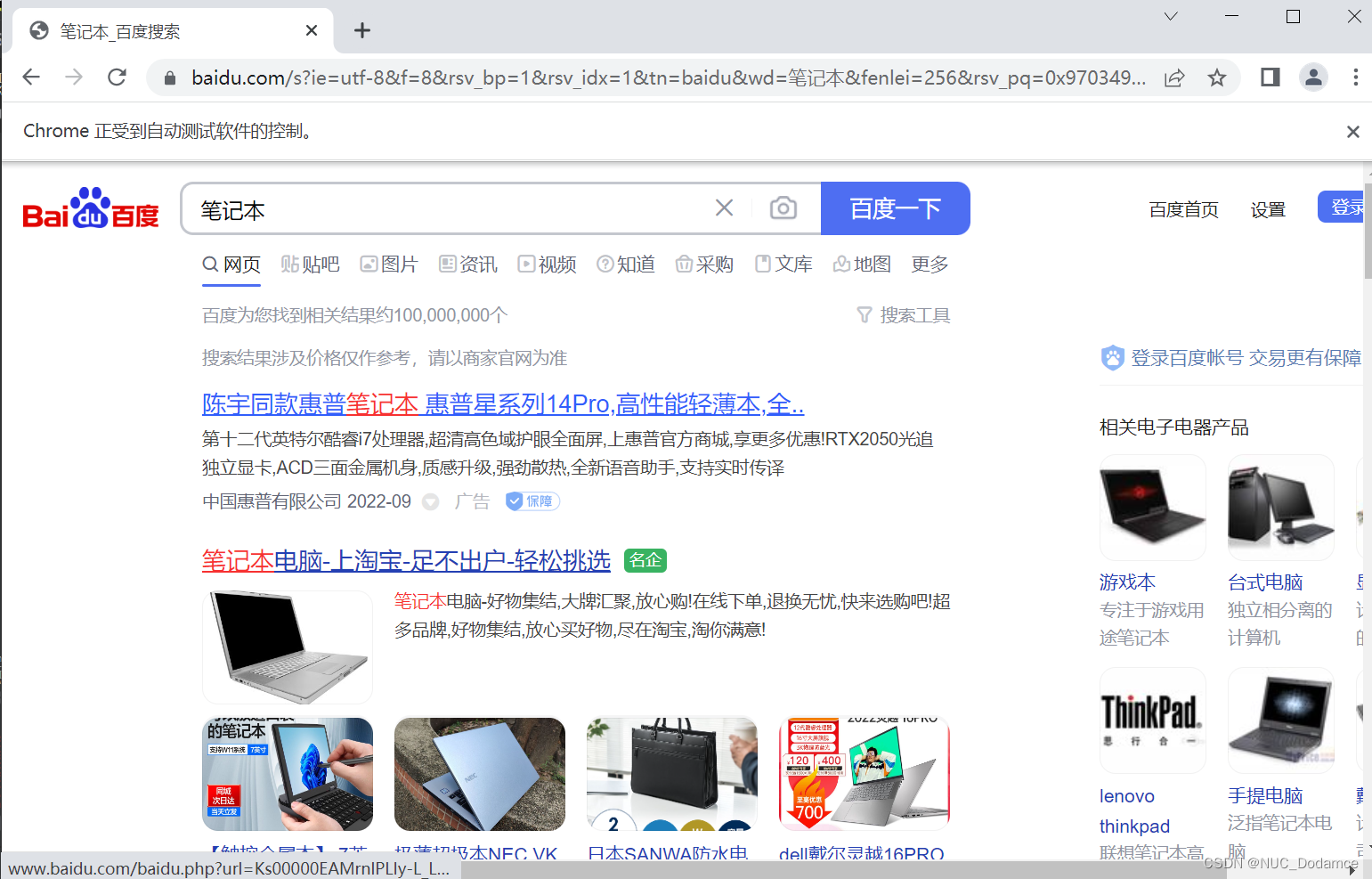
driver.get("https://www.baidu.com/")# 通过xpath找百度网页搜索框
search = driver.find_element(By.XPATH,'//*[@id="kw"]')
search.send_keys('笔记本')
time.sleep(5)# 通过id找搜索按钮
submit = driver.find_element(By.ID,'su')
submit.click()
time.sleep(5)
driver.close()
网页下拉框选择测试
网页下拉框:

通过导入
from selenium.webdriver.support.ui import Select
来实现下拉框的选择
从selenium.webdriver.Support.ui导入选择
Select().select_by_index()索引获取
Select().select_by_value() value获取
Select().deselect_by_visible_text()文本获取
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import Select
driver = webdriver.Chrome()
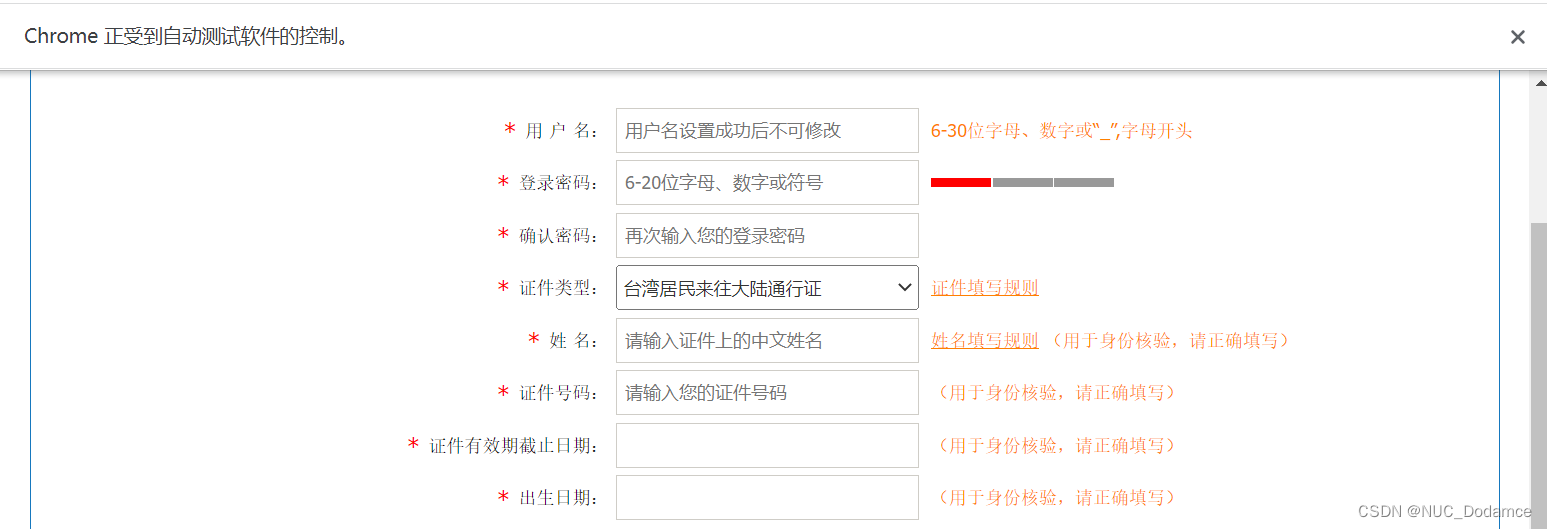
driver.get("https://kyfw.12306.cn/otn/regist/init")
index = driver.find_element(By.ID,'cardType')
select = Select(index)# 通过下标选择,列表是从0号下标开始
select.select_by_index(3)
time.sleep(5)
driver.close()
动态页面翻页
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get('https://www.duitang.com/search/?kw=%E7%BE%8E%E5%A5%B3&type=feed')for i inrange(1,200,5):# 实现网页下拉
js ='window.scrollTo(0,%s)'%(i *100)
driver.execute_script(js)
time.sleep(0.3)print(driver.page_source)input()# 关闭页面
driver.close()
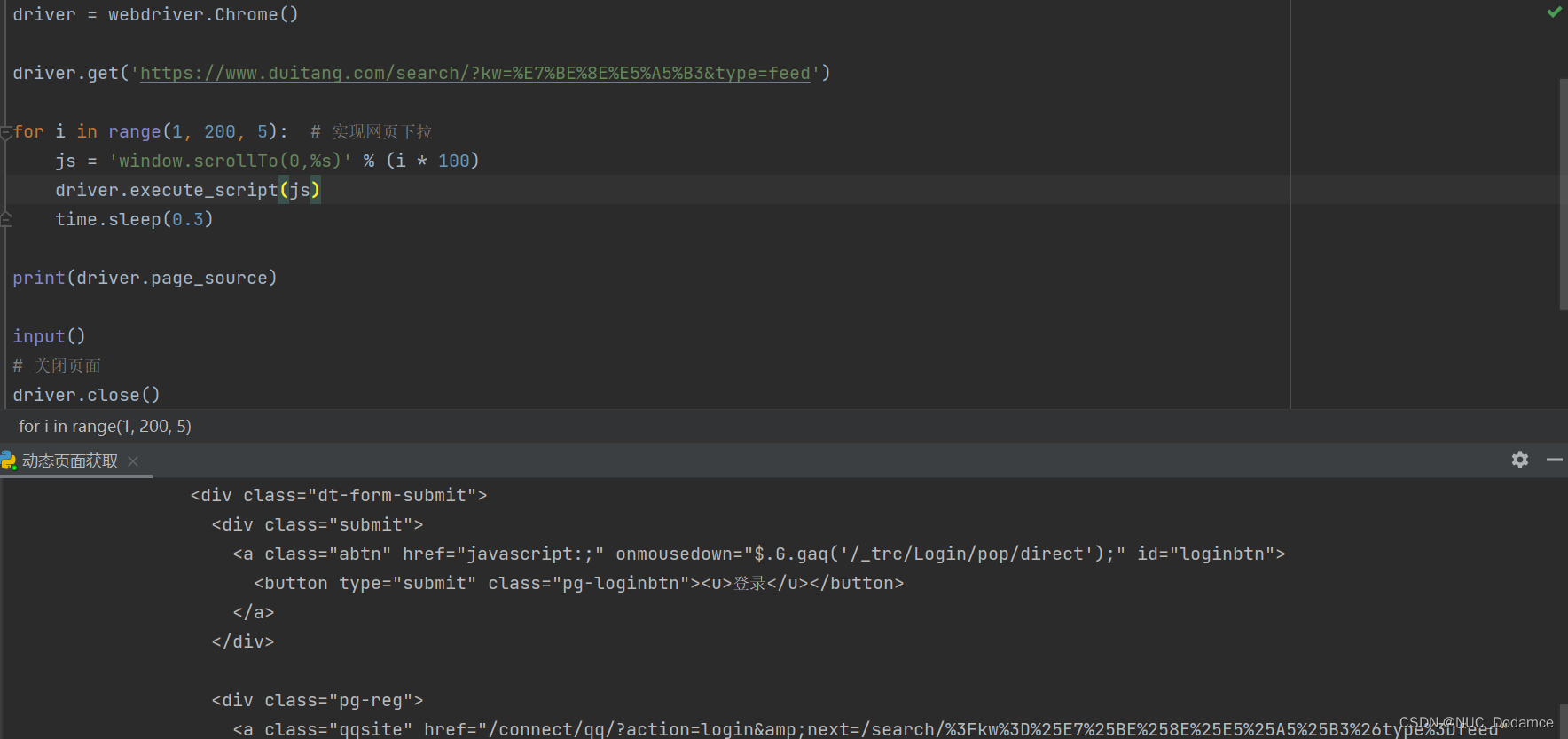
通过selenium可以直接获取到数据。
2. selenium行为链
为了更好的让selenium模拟人的行为,所以引出了 selenium行为链
这里以搜索行为链为例学习:
from selenium.webdriver.common. action_chains import ActionChains
导入selenium行为链模块
基本操作为:
action = ActionChains(driver)# 在driver创建行为链对象
inp = driver.find_element(By.ID,'kw')# 获取到输入框位置
action.move_to_element(inp)# 把鼠标移动到输入框
action.send_keys_to_element(inp,'百度贴吧')# 模拟输入,函数中自动包括点击搜索框行为
btn = driver.find_element(By.ID,'su')# 获取搜索按钮
action.move_to_element(btn)# 移动鼠标到搜索按钮
action.click(btn)# 模拟点击
action.perform()# 执行行为
from selenium.webdriver.common.action_chains import ActionChains
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
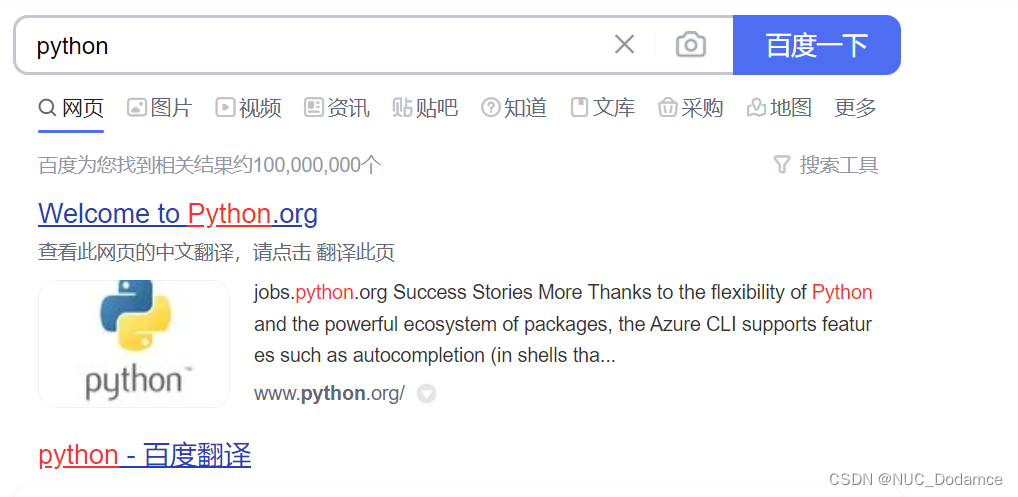
driver.get("https://www.baidu.com/")# 通过xpath找百度网页搜索框
search = driver.find_element(By.XPATH,'//*[@id="kw"]')# 通过id找搜索按钮
submit = driver.find_element(By.ID,'su')
action = ActionChains(driver)
action.move_to_element(search)
action.send_keys_to_element(search,'python')
action.move_to_element(submit)
action.click(submit)
action.perform()input()
driver.close()
本文转载自: https://blog.csdn.net/dodamce/article/details/127034358
版权归原作者 NUC_Dodamce 所有, 如有侵权,请联系我们删除。
版权归原作者 NUC_Dodamce 所有, 如有侵权,请联系我们删除。