

目录
WordCount案例:
需求分析与步骤:
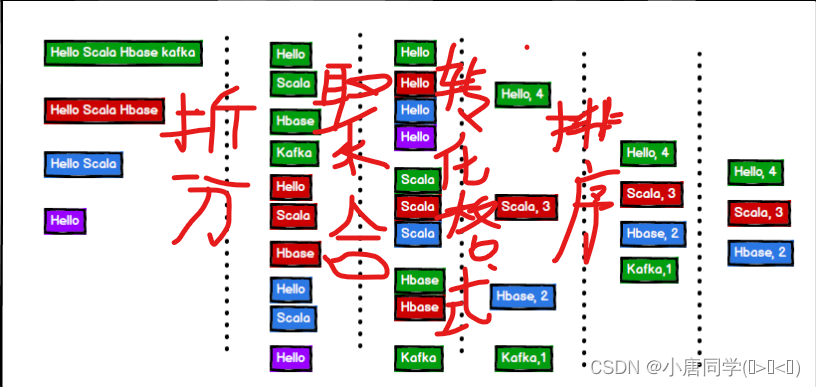
拆分:
val list: List[String] = stringList.flatMap((s) => {
s.split(" ")
})
聚合:
聚合过程较为繁琐,分为以下几步:
(1)先将切割后的List集合转变成二元组并且value设置为1
val tuples: List[(String, Int)] = list.map(s => (s, 1))
(2)对现在的二元组进行分组(相同的key)
val map: Map[String, List[(String, Int)]] = tuples.groupBy(tuple => tuple._1)
格式转化:
方法1:
通过map映射映射成我们需要的形式
val map1: Map[String, Int] = map.map(tuple => (tuple._1, tuple._2.size))
方法2:
方法2使用的是value特定的函数
val map2: Map[String, Int] = map.mapValues(value => value.size)
排序:
方法1:
现在的集合是Map集合,需要排序所以要转换成List再调用排序函数(sortBy方法)
val list1: List[(String, Int)] = map2.toList
val tuples1: List[(String, Int)] = list1.sortBy(map1 => map1._2).reverse
方法2:
采用sortWith方法:
val list2: List[(String, Int)] = list1.sortWith((map1l, map2r) => map1l._2 > map2r._2)
取top3:
val list3: List[(String, Int)] = list2.take(3)
整体化简后的代码:
val tuples1: List[(String, Int)] = stringList.map(_.split(" "))
.flatten
.map(s => (s, 1))
.groupBy( _._1)
.map(tuple => (tuple._1, tuple._2.size))
.toList
.sortBy(_._2)(Ordering[Int].reverse)
.take(3)
WordCoount案例升级:
给定数据:
val tupleList = List(("Hello Scala Spark World", 4), ("Hello Scala Spark", 3), ("Hello Scala", 2), ("Hello", 1))
与上述数据不同
方法1:
方法一就是把数据打散变成普通版数据再按照普通版数据进行操作
(1)切割与扁平化:
val list1: List[String] = list.flatMap(s => {
s.split(" ")
})
(2)将集合中方法都改变结构变成二元组(value=1)
val tuples: List[(String, Int)] = list1.map(s => (s, 1))
(3)按照key进行分组
val map: Map[String, List[(String, Int)]] = tuples.groupBy(tup => tup._1)
(4)通过map进行格式转换成最终格式
val list2: List[(String, Int)] = map.map(tp => (tp._1, tp._2.size))
(5)转换成List集合并且进行排序取前三(按业务要求)
.toList
.sortWith((tpl, tpr) => tpl._2 > tpr._2)
.take(3)
总结:上述方法理解简单,但是比较消耗内存 当每个字符串的次数较大时 是非常消耗内存的,消耗时间
方法2:
方法2采取的是不打散策略,直接使用聚合的策略
(1)对集合进行切割并且转换成元组(key,value)
val list3: List[List[(String, Int)]] = tupleList.map(s => {
val strings: Array[String] = s._1.split(" ")
val list: List[String] = strings.toList
list.map(list => {
(list, s._2)
})
}
)
(2)进行扁平化
val flatten: List[(String, Int)] = list3.flatten
(3)进行分组
val map1: Map[String, List[(String, Int)]] = flatten.groupBy(tuple => tuple._1)
(4)对value值进行改变 改变为我们需要的格式
val map2: Map[String, Int] = map1.mapValues(value => value.map(tuple => tuple._2).sum)
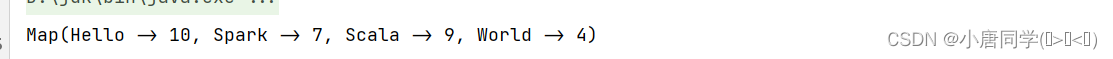
方法3:
方法3是在我们分组的基础之上对value进行调用归约函数,直接对value进行累加
val map3: Map[String, Int] = map.mapValues(value => value.foldLeft(0)((res, elem) => res + elem._2))
并行集合:
并行集合涉及多线程
Scala 为了充分使用多核 CPU,提供了并行集合(有别于前面的串行集合),用于多核
环境的并行计算。
在我们日常用的main函数是单线程
在集合的后边加上.par后 变成了并行集合 使用多线程打印(同时也是乱序的)
在同一个线程内是有序的但是线程之间是无序的
集合终于终结了!!!!!
本文转载自: https://blog.csdn.net/m0_61469860/article/details/130303782
版权归原作者 小唐同学爱学习 所有, 如有侵权,请联系我们删除。
版权归原作者 小唐同学爱学习 所有, 如有侵权,请联系我们删除。