
Flink 命令行参数介绍
参考文档:
1、https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/deployment/cli/
2、Flink 三种模式 | 不同的执行命令的差异
一、Flink Command | CLI Actions
1.1 客户端命令介绍
Flink 提供了一个命令行界面 (CLI)
bin/flink
来运行为
JAR
文件的程序并控制它们的执行
命令行格式,一定要理解命令行的格式,每个 ACTION 都用自己对应的 OPTION(很重要,不然很容易搞混)
# ACTION 必选# OPTION 可选# ARGUMENTS 可选
.bin/flink <ACTION>[OPTIONS][ARGUMENTS]
flink 中的
Action
有这些:
ActionPurposerun这个操作用于执行flink中的应用, 该命令至少需要包含作业的 jar, 可以传递与 Flink 或作业相关的参数, 一般用于执行 yarn-session 和 yarn-per-job 模式run-application这个操作用于执行 Application Mode 模式的应用info这个操作可用于打印作业的优化执行图, 需要传递包含作业的 jarlist此操作列出所有正在运行或计划的作业savepoint此操作可用于为给定作业创建或处置检查点, 如果
conf/flink-conf.yaml
中未指定
state.savepoints.dir
参数,则需要指定
JobID
之外的保存点目录cancel此操作可用于根据 JobID 取消正在运行的作业stop此操作结合了取消和保存点操作以停止正在运行的作业, 但也创建一个保存点以重新开始
1.2 使用示例
① ./bin flink run
② ./bin flink run-application
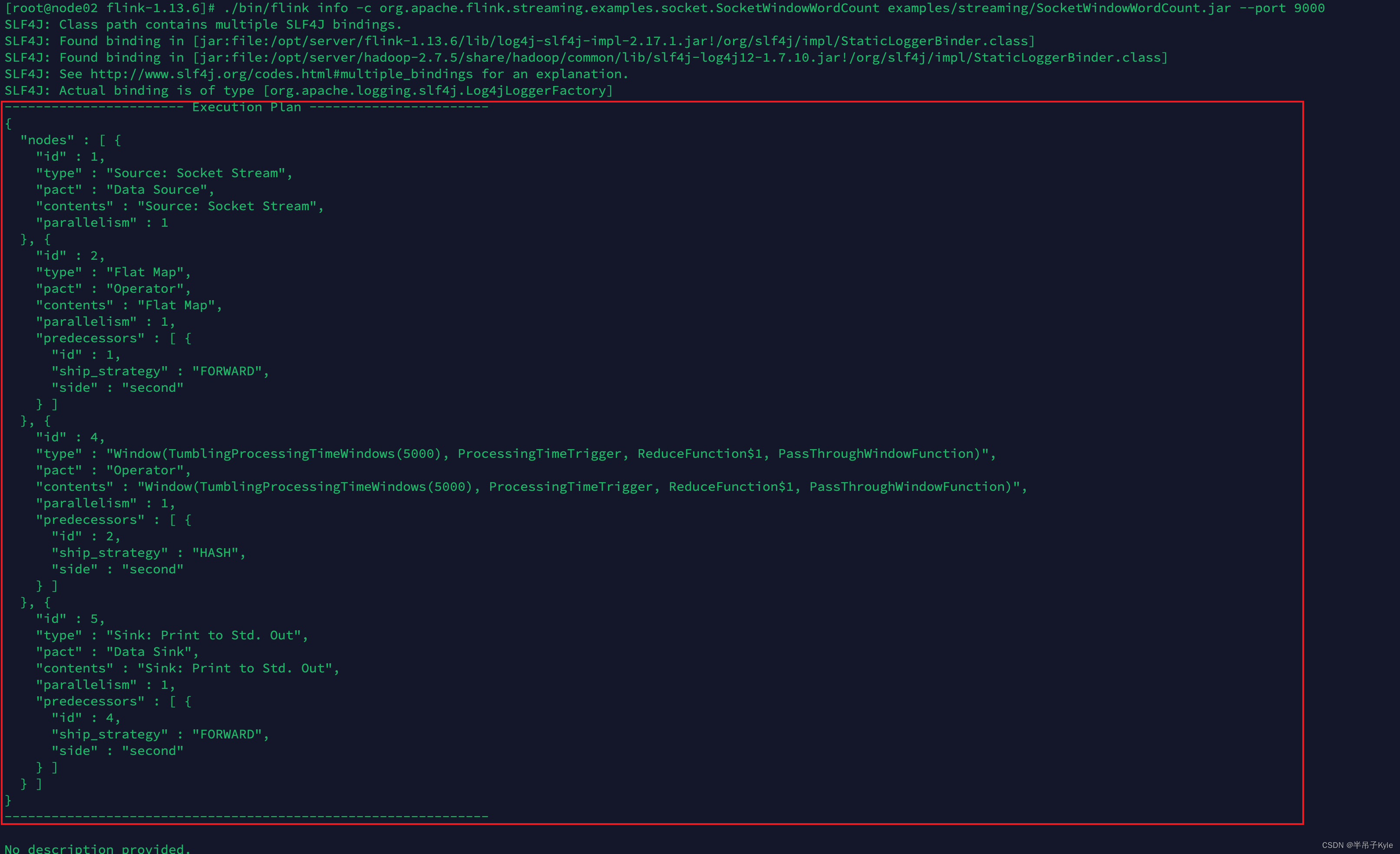
示例 3 :查看作业的执行计划
# 进入 FLINK 安装目录, 执行如下命令
./bin/flink info \
-c org.apache.flink.streaming.examples.socket.SocketWindowWordCount \
examples/streaming/SocketWindowWordCount.jar \
--port 9000
示例 4 :查看执行的作业列表
# 查看该命令的帮助
./bin/flink list -h
# 查看正在执行作业列表(如果你的程序运行在yarn集群上,这个命令可能会报错)# flink on yarn 时,使用该命令一定要指定 cluster_id ,即可以理解为 jobId
./bin/flink list
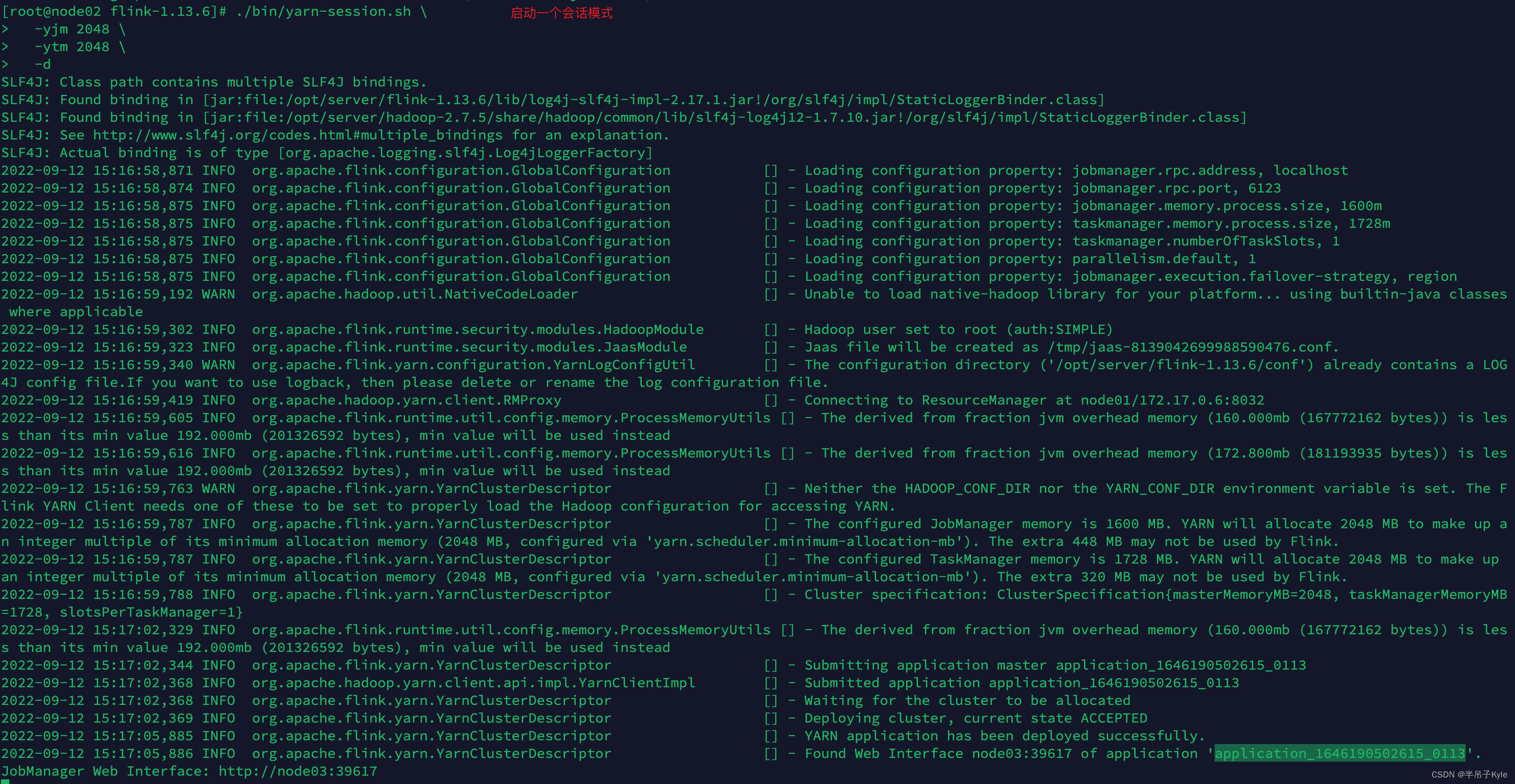
为了测试该命令,我们需要启动一个 flink 作业,我们先启动一个会话模式,然后在会话中提交一个作业 (参考该博客启动作业)
https://blog.csdn.net/hell_oword/article/details/120116908
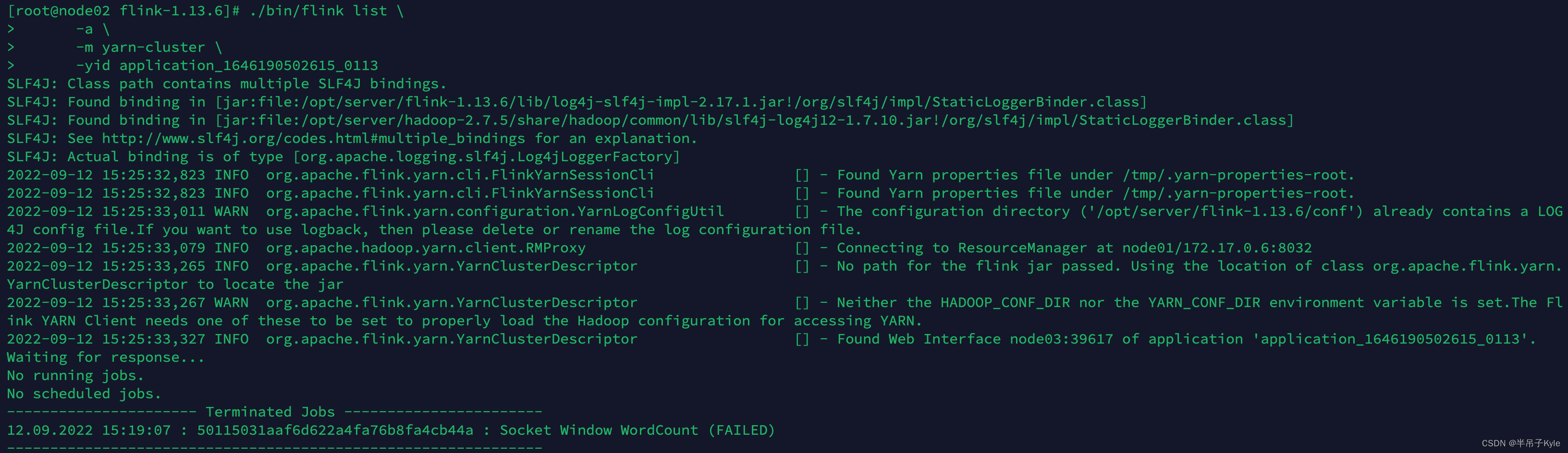
# 查看该会话下的所有运行作业列表
./bin/flink list \
-a \
-m yarn-cluster \
-yid application_1646190502615_0113
示例 4 :取消一个作业
https://blog.csdn.net/hell_oword/article/details/120116908
二、Flink Run Command | flink run
2.1 命令介绍
flink run
命令用于编译和执行一个程序
查看命令参数选项
# 命令格式
run [OPTIONS]<jar-file><arguments># 查看命令帮助
./bin/flink run -h

命令参数分为 4 部分,分别为
$ ./bin/flink run -h
Syntax: run [OPTIONS]<jar-file><arguments>"run" action options:
...
Options for Generic CLI mode:
...
Options for yarn-cluster mode:
...
Options for default mode:
① run action options(主要用于设置执行的主类)
OptionsPurpose
-c,--class <classname>
具有程序入口的类, 即该类下有
main()
方法, 只需要指定类名即可
-C,--classpath <url>
具有程序入口的类, 即该类下有
main()
方法, 需要指定类的全路径, 使用较多-d,–detached分离模式执行作业, 程序提交完就退出客户端, 不再打印作业进度等信息, 可以理解为异步提交, 使用较多-n,–allowNonRestoredState允许跳过无法恢复的保存点状态, 如果从程序中删除了一个operator,该operator在savepotint中是程序的一部分时, 不使用该操作会报错
-p,--parallelism <parallelism>
指定作业的并行度, 注意并行度设置的优先级
-py,--python <pythonFile>
带有程序入口点的 Python 脚本, 可以使用
--pyFiles
选项配置依赖资源, 和
-c
是一个意思, 这个是通过 python 提交作业而已
-pyxx
py 相关的 options 不在此处介绍, 后续补充, 目前主要以
-c
提交作业为主
② Options for Generic CLI mode
OptionsPurpose-D <property=value>允许指定多个通用配置选项, 配置可以参考 https://nightlies.apache.org/flink/flink-docs-stable/ops/config.html
-e,--executor <arg>
已弃用, 不再赘述
-t,--target <arg>
设置应用程序的部署目标,相当于
execution.target
配置选项
run
action 可以使用: “remote”, “local”, “kubernetes-session”, “yarn-per-job”, “yarn-session”
run-application
action 可以使用: “kubernetes-application”, “yarn-application”.
③ Options for yarn-cluster mode(yarn-cluster 模式下的 Options)
OptionsPurpose-d,–detached分离模式执行作业, 程序提交完就退出客户端, 不再打印作业进度等信息, 可以理解为异步提交, 使用较多
-m,--jobmanager <arg>
将该 option 的值设置为 yarn-cluster, 以此使用 yarn 集群模式
-yat,--yarnapplicationType <arg>
为 YARN 上的应用程序设置自定义应用程序类型
-yD <property=value>
设置传递参数的键值对
-yh,--yarnhelp
查看 yarn 提交命令
-yid,--yarnapplicationId <arg>
向会话模式中提交应用
-yj,--yarnjar <arg>
指定 Flink jar 文件的路径
-yjm,--yarnjobManagerMemory <arg>
指定 JobManager 使用的内存大小, 使用较多, 单位(MB)
-ynl,--yarnnodeLabel <arg>
为 YARN 应用程序指定 YARN 节点标签
-ynm,--yarnname <arg>
设置作业在 Hadoop Applications 界面显示的名称, 使用较多
-yq,--yarnquery
显示可用的 yarn 资源大小 (memoty, cores)
-yqu,--yarnqueue <arg>
指定作业使用的 yarn 队列, , 使用较多
-ys,--yarnslots <arg>
指定每个 TaskManager 使用的 slots 的数量
-yt,--yarnship <arg>
传送指定目录中的文件
-ytm,--yarntaskManagerMemory <arg>
指定每个TaskManager使用的内存大小, 使用较多, 单位(MB)
-yz,--yarnzookeeperNamespace <arg>
为高可用性模式创建 Zookeeper 子路径的命名空间
-z,--zookeeperNamespace <arg>
为高可用性模式创建 Zookeeper 子路径的命名空间
④ Options for default mode
OptionsPurpose-D <property=value>允许指定多个通用配置选项, 配置可以参考 https://nightlies.apache.org/flink/flink-docs-stable/ops/config.html
-m,--jobmanager <arg>
将该 option 的值设置为 yarn-cluster, 以此使用 yarn 集群模式
-z,--zookeeperNamespace <arg>
为高可用性模式创建 Zookeeper 子路径的命名空间
2.2 使用示例
示例一:提交一个应用(job分离模式)
版权归原作者 半吊子Kyle 所有, 如有侵权,请联系我们删除。