
一 副本的作用
1.Kafka 副本作用:提高数据可靠性。
2.Kafka 中副本分为:Leader 和 Follower。Kafka 生产者只会把数据发往 Leader, 然后 Follower 找 Leader 进行同步数据。
读写由leader来完成,follower只备份,和leader同步数据,leader发生故障,follower顶上去。
leader副本:可以理解为某个分区中,除了不是副本的那个分区。
3.Kafka 分区中的所有副本统称为 AR(Assigned Repllicas)。
AR = ISR + OSR
4.ISR:表示和 Leader 保持同步的 Follower 集合。如果 Follower 长时间未向 Leader 发送通信请求或同步数据,则该 Follower 将被踢出 ISR。该时间阈值由 replica.lag.time.max.ms参数设定,默认 30s。Leader 发生故障之后,就会从 ISR 中选举新的 Leader。
5.OSR:表示 Follower 与 Leader 副本同步时,超时的副本集合。
二 副本与分区的作用
2.1 案例描述
假设创建4个节点,5个分区,2个副本,那么分区,副本的关系,如下图所示:
root@VM_15_71_centos kafka_2.11-1.0.0]# bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic test-part
[2019-06-28 01:23:50,646] INFO Accepted socket connection from /127.0.0.1:41204 (org.apache.zookeeper.server.NIOServerCnxnFactory)
[2019-06-28 01:23:50,646] INFO Client attempting to establish new session at /127.0.0.1:41204 (org.apache.zookeeper.server.ZooKeeperServer)
[2019-06-28 01:23:50,649] INFO Established session 0x16b99ec1ce1000c with negotiated timeout 30000 for client /127.0.0.1:41204 (org.apache.zookeeper.server.ZooKeeperServer)
Topic:test-part PartitionCount:5 ReplicationFactor:2 Configs:
Topic: test-part Partition: 0 Leader: 0 Replicas: 0,2 Isr: 0,2
Topic: test-part Partition: 1 Leader: 1 Replicas: 1,3 Isr: 1,3
Topic: test-part Partition: 2 Leader: 2 Replicas: 2,0 Isr: 2,0
Topic: test-part Partition: 3 Leader: 3 Replicas: 3,1 Isr: 3,1
Topic: test-part Partition: 4 Leader: 0 Replicas: 0,3 Isr: 0,3
[2019-06-28 01:23:50,899] INFO Processed session termination for sessionid: 0x16b99ec1ce1000c (org.apache.zookeeper.server.PrepRequestProcessor)
[2019-06-28 01:23:50,904] INFO Closed socket connection for client /127.0.0.1:41204 which had sessionid 0x16b99ec1ce1000c (org.apache.zookeeper.server.NIOServerCnxn)
通过以上信息我们可以分析得出:
1.opic:test-part PartitionCount:5 ReplicationFactor:2 Configs:
一个主题: test-part, 5个分区,2个副本。
2.Partition这一列竖着看,【0,1,2,3,4】共5个分区。
3.Replicas 这一列竖着看,将所有boker的id去重后【[0,2],[1,3],[2,0],[3,1],[0,3]】,得到的集合个数为节点的数目【0,1,2,3】
4.Replicas 这一列,选择任意一行横着看,boker的id的集合大小为,副本的个数,如【0,2】副本数为2。
梳理存储分布图:

三 kafka的分区的leader副本选举
3.1 leader选举思想
按照:在 isr中存活为前提,按照 AR中排在前面的优先顺序,比如
选举规则:在isr中存活为前提,按 照AR中排在前面的优先。例如 ar[1,0,2], isr [1,0,2],那么leader 就会按照1,0,2的顺序轮询。
- 创建一个新的 topic,4 个分区,4 个副本

2.查看 Leader 分布情况
 3.停止掉 hadoop105 的 kafka 进程,并查看 Leader 分区情况
3.停止掉 hadoop105 的 kafka 进程,并查看 Leader 分区情况

** 可以看到按照AR中的顺序,3021中3挂掉,0成为主节点。**
四 leader与follower发生故障处理
4.1 follower发生故障
1.LEO和HW
LEO(Log End Offset):每个副本的最后一个offset,LEO其实就是最新的offset+ 1。
HW(High Watermark):所有副本中最小的LEO 。
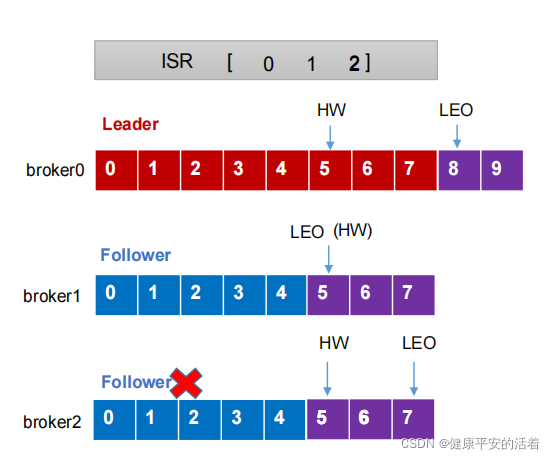
2.流程
1.Follower发生故障后会被临时踢出ISR
2.这个期间Leader和Follower继续接收数据(不管follower是否还能接收到,二者还是在通信同步数据)
3.待该Follower恢复后,Follower会读取本地磁盘记录的上次的HW,并将log文件高于HW的部分截取掉,从HW开始向Leader进行同步。
4.等该Follower的LEO大于等于该Partition的HW,即Follower追上Leader之后,就可以重新加入ISR了。
4.2 leader发生故障
1.LEO和HW
LEO(Log End Offset):每个副本的最后一个offset,LEO其实就是最新的offset+ 1。
HW(High Watermark):所有副本中最小的LEO 。
2.流程

五 手动调试分区副本存储
** 5.1 **需求描述
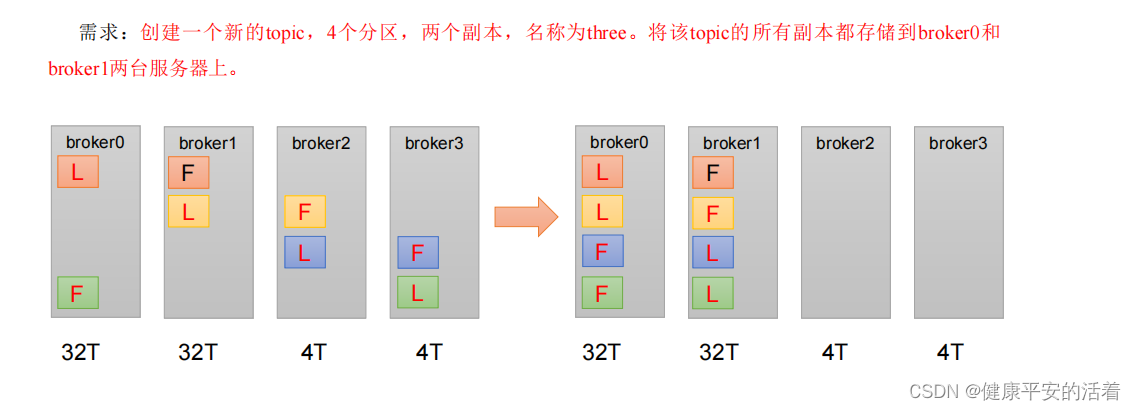
5.2 操作步骤
1.创建一个新的 topic,名称为 three

2.查看分区副本存储情况。

- 创建副本存储计划(所有副本都指定存储在 broker0、broker1 中)。

4.执行副本存储计划。

5.验证副本存储计划。
 6.查看分区副本存储情况
6.查看分区副本存储情况

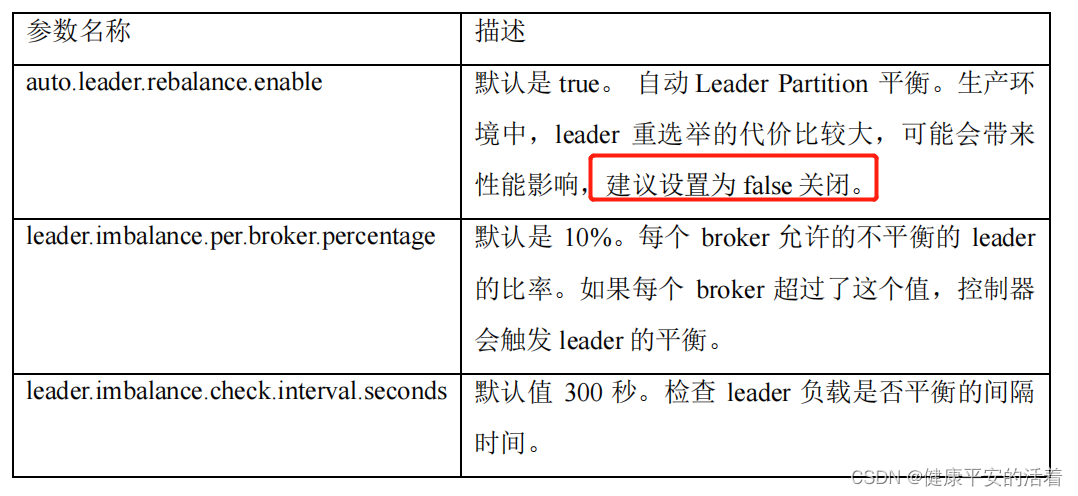
六 生产经验——Leader Partition 负载平衡(了解)
正常情况下,Kafka本身会自动把Leader Partition均匀分散在各个机器上,来保证每台机器的读写吞吐量都是均匀的。但是如果某些broker宕机,会导致Leader Partition过于集中在其他少部分几台broker上,这会导致少数几台broker的读写请求压力过高,其他宕机的 broker重启之后都是follower partition,读写请求很低,造成集群负载不均衡。

版权归原作者 健康平安的活着 所有, 如有侵权,请联系我们删除。