
。

本文字数:9915;估计阅读时间:25 分钟
审校:庄晓东(魏庄)
本文在公众号【ClickHouseInc】首发

介绍
ClickHouse 是用于实时应用和分析的最快且资源利用率最高的开源数据库。ClickHouse Keeper 是 ClickHouse 的一个组件,是 ZooKeeper 的快速、更节省资源和功能丰富的替代品。这个开源组件提供了一个高度可靠的元数据存储,以及协调和同步机制。最初是为在自建集群或托管的 ClickHouse 系统中使用而开发的。然而,我们相信其他社区也能在他们的项目中用例中从中受益。
在这篇文章中,我们描述了 ClickHouse Keeper 的动机、优势和开发,并预览了我们计划的下一步改进。此外,我们介绍了一个可重用的基准套件,它使我们能够轻松地模拟和测试典型的 ClickHouse Keeper 使用场景。基于此,我们呈现基准测试结果,突显 ClickHouse Keeper 在保持性能接近 ZooKeeper 的同时,使用的内存却只有 ZooKeeper 的1/46。
动机
现代分布式系统需要一个共享且可靠的信息存储库和一致性系统,以协调和同步分布式操作。对于 ClickHouse,最初选择了 ZooKeeper。它广泛被使用,证明是可靠的,并提供了简单而强大的 API,合理的性能。
然而,对于 ClickHouse,不仅性能,而且资源效率和可扩展性一直是首要任务。ZooKeeper 作为一个 Java 生态系统项目,不能很好地优雅地融入我们的 C++ 代码库,而且随着我们以越来越高的规模使用它,我们开始遇到资源使用和运维挑战。为了克服 ZooKeeper 的这些缺点,考虑到我们的项目需要解决的其他要求和目标,我们从零开始构建了 ClickHouse Keeper。
ClickHouse Keeper 是 ZooKeeper 的替代方案,具有完全兼容的客户端协议和相同的数据模型。除此之外,它还提供以下好处:
- 更容易的设置和操作:ClickHouse Keeper 是用 C++ 实现的,而不是 Java,因此可以嵌入到 ClickHouse 中或独立运行
- 由于更好的压缩,快照和日志占用的磁盘空间要少得多
- 默认数据包和节点数据大小没有限制(在 ZooKeeper 中是 1 MB)
- 没有 ZXID 溢出问题(在 ZooKeeper 中,它在每 20 亿次事务时强制重新启动)
- 因为使用了更好的分布式一致性协议,在网络分区后能更快地恢复。
- 额外的一致性保证:ClickHouse Keeper 提供与 ZooKeeper 相同的一致性保证 - 线性可写,以及相同会话内严格的操作顺序。此外,通过设置 quorum_reads,ClickHouse Keeper 还提供线性读取。
- ClickHouse Keeper 对于相同数量的数据更节约资源,使用的内存更少(稍后在本博客中我们将证明这一点)
ClickHouse Keeper 的开发始于 2021 年 2 月,作为 ClickHouse 服务中的嵌入式服务。同一年,引入了独立模式,并添加了 Jepsen 测试 - 每 6 小时,我们运行带有多种不同工作流和失败场景的自动化测试,以验证一致性机制的正确性。
在撰写本博客时,ClickHouse Keeper 已经在生产环境中运行了一年半以上,并且自 2022 年 5 月首次进行私人预览以来,已经在我们自己的 ClickHouse Cloud 中大规模部署。
在博客的其余部分,我们有时将 ClickHouse Keeper 简称为“Keeper”,因为我们内部经常这样称呼它。
在 ClickHouse 中的使用
通常,任何需要在多个 ClickHouse 服务器之间保持一致性的事物都依赖于 Keeper:
- Keeper 为自建的shared-nothing ClickHouse 集群中的数据复制提供协调系统
- Mergetree 引擎系列的复制表的自动插入去重是基于存储在 Keeper 中的block-hash-sums实现的
- Keeper 为part名称(基于顺序块编号)提供一致性,并为将part合并和mutation分配给特定集群节点提供一致性
- Keeper 在 KeeperMap 表引擎的后台中使用,该引擎允许您使用 Keeper 作为一致的键值存储,具有线性可写和顺序一致的读取- 利用这一点在 ClickHouse 上实现任务调度队列的应用程序- Kafka Connect Sink 使用此表引擎作为可靠的状态存储,以实现精确一次交付保证
- Keeper 持续跟踪 S3Queue 表引擎中消费的文件
- 复制的 Database 引擎将所有元数据存储在 Keeper 中
- Keeper 用于与 ON CLUSTER 子句一起协调备份
- UDF可以存储在 Keeper 中
- 访问控制信息可以存储在 Keeper 中
- Keeper 用作 ClickHouse Cloud 中所有元数据的共享中央存储
观测 Keeper
在接下来的几节中,为了观测(并稍后在基准测试中模拟)ClickHouse Cloud 与 Keeper 的一些交互,我们将一个月的 WikiStat 数据集加载到一个具有 3 个节点的 ClickHouse Cloud 服务中。每个节点有 30 个 CPU 核心和 120 GB 的 RAM。每个服务都使用自己专用的 ClickHouse Keeper 服务,包括 3 个服务器,每个 Keeper 服务器有 3 个 CPU 核心和 2 GB RAM。
下图说明了这个数据加载场景:
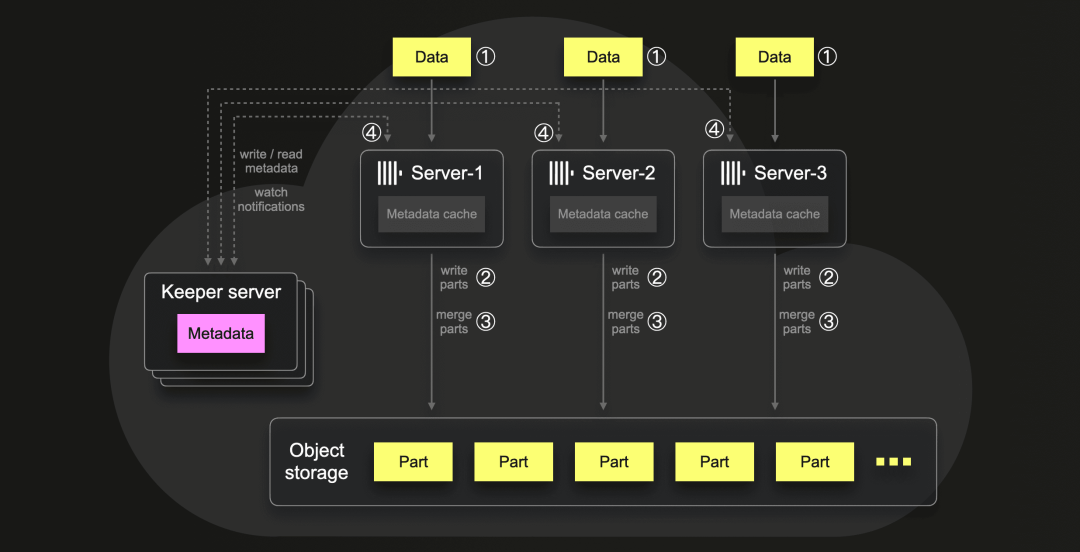
① 数据加载
通过一个数据加载,在大约 100 秒内,我们从大约 740 个压缩文件中(一个文件表示一天中的一个特定小时)并行加载了约 46 亿行数据到所有三个 ClickHouse 服务器。单个 ClickHouse 服务器的内存使用峰值约为 107 GB:
0 rows in set. Elapsed: 101.208 sec. Processed 4.64 billion rows, 40.58 GB (45.86 million rows/s., 400.93 MB/s.)
Peak memory usage: 107.75 GiB.
② Part创建
为了存储数据,3 个 ClickHouse 服务器共同在对象存储中创建了 240 个part。每个初始part的平均行数约为 1934 万行。平均大小约为 100 MiB,插入的总行数为 46 亿:
┌─parts──┬─rows_avg──────┬─size_avg───┬─rows_total───┐
│ 240.00 │ 19.34 million │ 108.89 MiB │ 4.64 billion │
└────────┴───────────────┴────────────┴──────────────┘
由于我们的数据加载利用了 s3Cluster 表函数,part的创建均匀分布在 ClickHouse Cloud 服务的 3 个 ClickHouse 服务器上:
┌─n─┬─parts─┬─rows_total───┐
│ 1 │ 86.00 │ 1.61 billion │
│ 2 │ 76.00 │ 1.52 billion │
│ 3 │ 78.00 │ 1.51 billion │
└───┴───────┴──────────────┘
③ part合并
在数据加载过程中,ClickHouse 在后台执行了 1706 次part合并:
┌─merges─┐
│ 1706 │
└────────┘
④ Keeper 交互
ClickHouse 完全将数据和元数据的存储从服务器中分离。所有数据都存储在共享对象存储中,所有元数据存储在 Keeper 中。当 ClickHouse 服务器将新的part写入对象存储(参见 ② 上文)或将一些part合并为新的较大part时(参见 ③ 上文),则该 ClickHouse 服务器会使用事务请求多写来更新 Keeper 中关于新part的元数据。此信息包括part的名称、哪些文件属于该part以及与文件对应的 blob 在对象存储中的位置。每个服务器都有一个包含元数据子集的本地缓存,并通过 Keeper 实例通过基于订阅的监视机制自动了解数据更新。
对于我们上述的初始part的创建和后台part的合并,执行了总共约 18,000 次 Keeper 请求。其中包括约 12,000 次多写事务请求(仅包含写子请求)。所有其他请求是读写请求的混合。此外,ClickHouse 服务器从 Keeper 收到了约 800 次通知:
total_requests: 17705
multi_requests: 11642
watch_notifications: 822
我们可以看到这些请求如何相当均匀地从所有三个 ClickHouse 节点发送和接收监视通知:
┌─n─┬─total_requests─┬─multi_requests─┬─watch_notifications─┐
│ 1 │ 5741 │ 3671 │ 278 │
│ 2 │ 5593 │ 3685 │ 269 │
│ 3 │ 6371 │ 4286 │ 275 │
└───┴────────────────┴────────────────┴─────────────────────┘
以下两张图可视化了在数据加载过程中这些 Keeper 请求:
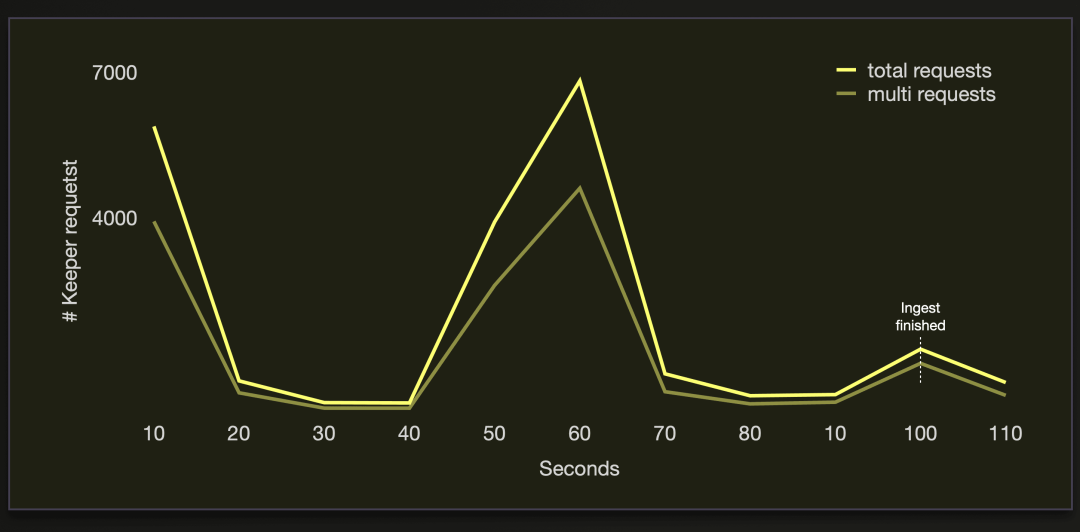
我们可以看到大约 70% 的 Keeper 请求是多写事务。
请注意,Keeper 请求的数量可能会根据 ClickHouse 集群大小、写入设置和数据大小而变化。我们简要演示了这三个因素如何影响生成的 Keeper 请求数量。
ClickHouse 集群大小
如果我们使用 10 台服务器而不是 3 台服务器并行加载数据,我们可以将数据写入速度提高 3 倍多(使用 SharedMergeTree):
0 rows in set. Elapsed: 33.634 sec. Processed 4.64 billion rows, 40.58 GB (138.01 million rows/s., 1.21 GB/s.)
Peak memory usage: 57.09 GiB.
更多服务器的数量会产生超过 3 倍的 Keeper 请求量:
total_requests: 60925
multi_requests: 41767
watch_notifications: 3468
写入设置
对于我们最初使用 3 台 ClickHouse 服务器运行的数据加载,我们配置了每个初始part的最大大小为 ~25 百万行,以加快写入速度,代价是更高的内存使用。如果我们改为使用默认值 ~1 百万行每个初始part运行相同的数据加载,则数据加载速度较慢,但每个 ClickHouse 服务器的主要内存使用量减少了约 9 倍:
0 rows in set. Elapsed: 121.421 sec. Processed 4.64 billion rows, 40.58 GB (38.23 million rows/s., 334.19 MB/s.)
Peak memory usage: 12.02 GiB.
并且创建的初始part数量从 240 个增加到了 约4 千个:
┌─parts─────────┬─rows_avg─────┬─size_avg─┬─rows_total───┐
│ 4.24 thousand │ 1.09 million │ 9.20 MiB │ 4.64 billion │
└───────────────┴──────────────┴──────────┴──────────────┘
这导致了更多的part合并:
┌─merges─┐
│ 9094 │
└────────┘
我们得到了更多的 Keeper 请求(约 147k 而不是约 17k):
total_requests: 147540
multi_requests: 105951
watch_notifications: 7439
数据大小
同样,如果我们加载更多的数据(使用默认值 ~1 百万行每个初始part),例如 六个月的WikiStat 数据,则我们的服务将获得更多约 24k个初始part:
┌─parts──────────┬─rows_avg─────┬─size_avg─┬─rows_total────┐
│ 23.75 thousand │ 1.10 million │ 9.24 MiB │ 26.23 billion │
└────────────────┴──────────────┴──────────┴───────────────┘
这导致了更多的合并:
┌─merges─┐
│ 28959 │
└────────┘
从而产生了约 680k 的 Keeper 请求:
total_requests: 680996
multi_requests: 474093
watch_notifications: 32779
Keeper 基准测试
我们开发了一个名为 keeper-bench-suite 的基准测试套件,用于基准测试上述探讨的 ClickHouse 与 Keeper 的典型交互。为此,keeper-bench-suite 允许模拟来自由 N 台(例如 3 台)服务器组成的 ClickHouse 集群的并行 Keeper 工作负载:
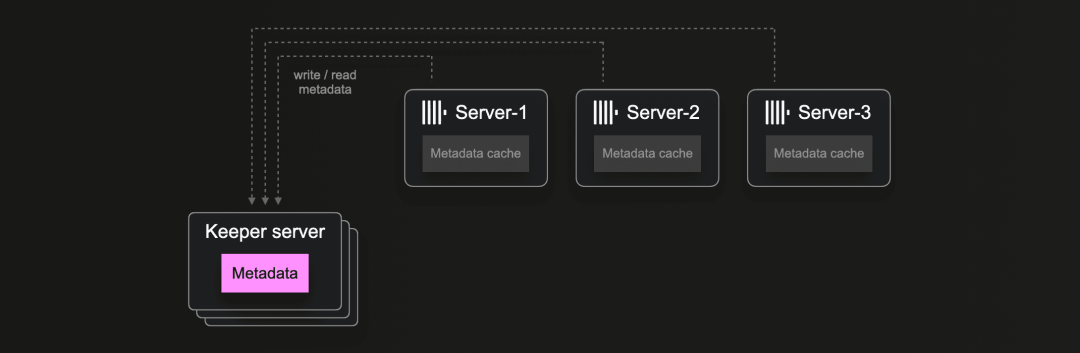
我们利用了 keeper-bench,这是一个用于基准测试 Keeper 或任何与 ZooKeeper 兼容的系统的工具。借助这个基础构建块,我们可以模拟并基准测试从 N 台 ClickHouse 服务器发送的典型并行 Keeper 流量。此图显示了Keeper Bench Suite的完整架构,它使我们能够轻松设置和基准测试任意 Keeper 工作负载场景:
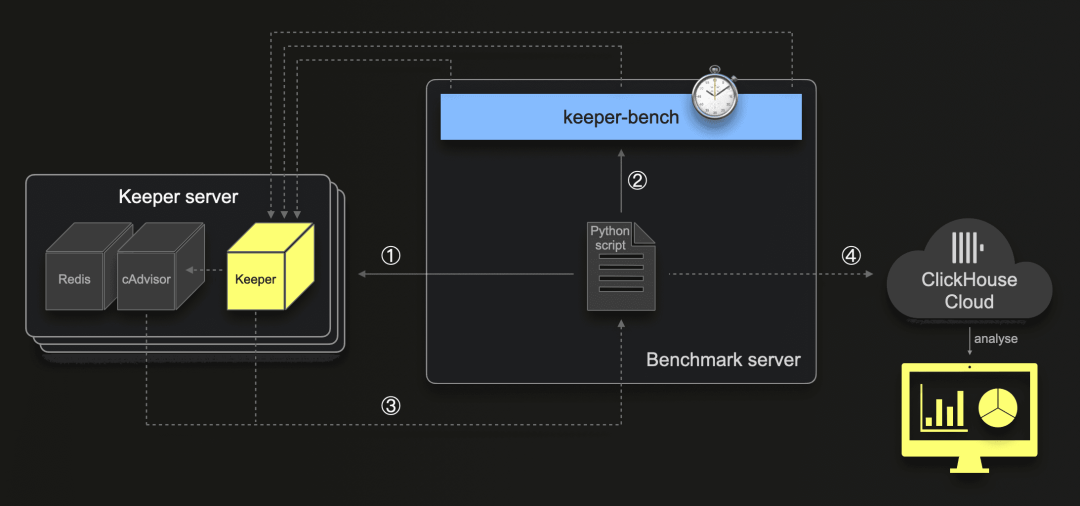
我们使用 AWS EC2 实例作为基准服务器,执行一个 Python 脚本,该脚本执行以下操作:
①通过启动 3 个适当配置的 EC2 实例(例如 m6a.4xlarge),每个实例运行一个 Keeper Docker 容器和两个包含 cAdvisor 和 Redis(cAdvisor 需要)的容器,从而设置和启动一个 3 节点的 Keeper 集群。
②启动
keeper-bench并使用预配置的工作负载配置。③每秒从每个 cAdvisor 和 Keeper 的 Prometheus 端点获取数据。
④将获取的指标及时间戳写入 ClickHouse Cloud 服务中的两个表中,这是通过 SQL 查询和 Grafana 仪表板方便地分析指标的基础。
请注意,ClickHouse Keeper 和 ZooKeeper 直接提供 Prometheus 端点。目前,这些端点的重叠部分很小,并且通常提供非常不同的指标,特别是在内存和 CPU 使用方面。因此,我们选择了基于 cAdvisor 的基本容器指标。此外,将 Keeper 运行在 Docker 容器中使我们可以轻松更改为 Keeper 提供的 CPU 核心数和内存大小。
配置参数
Keeper 的大小
我们使用不同的 Docker 容器大小运行 ClickHouse Keeper 和 ZooKeeper 的基准测试。例如,1 CPU 核心 + 1 GB RAM,3 CPU 核心 + 1 GB RAM,6 CPU 核心 + 6 GB RAM。
客户端数量和请求数
对于每个 Keeper 大小,我们使用 keeper-bench 的并发设置模拟不同数量的客户端(例如,ClickHouse 服务器)并行发送请求到 Keeper:例如 3、10、100、500、1000。
从这些模拟的客户端中,为了模拟短时和长时运行的 Keeper 会话,我们使用 keeper-bench 的迭代设置向 Keeper 发送总计介于 1 万和 ~1000 万请求。这旨在测试组件的内存使用量是否随时间变化。
工作负载
我们模拟了一个典型的 ClickHouse 工作负载,其中包含 约1/3 的写入和删除操作,以及 约2/3 的读取。这反映了一种情景,其中一些数据被写入、合并,然后进行查询。很容易定义和基准测试其他工作负载。
测量指标
Prometheus 端点
我们使用 cAdvisor 的 Prometheus 端点测量:
- 主内存使用量(container_memory_working_set_bytes)
- CPU 使用量(container_cpu_usage_seconds_total)
我们使用 ClickHouse Keeper 和 ZooKeeper 的 Prometheus 端点测量附加的(所有可用的) Keeper Prometheus 端点指标值。例如,对于 ZooKeeper,有许多 JVM 特定的指标(堆大小和使用情况、垃圾回收等)。
运行时间
我们还根据每次运行的最小和最大时间戳测量 Keeper 处理所有请求的运行时间。
结果
我们使用 keeper-bench-suite 比较了 ClickHouse Keeper 和 ZooKeeper 在我们的工作负载下的资源消耗和运行时间。我们每个基准配置运行 10 次,并将结果存储在 ClickHouse Cloud 服务中的两个表中。我们使用 SQL 查询生成了三个表格化的结果表:
- 平均值
- 95 分位数
- 99 分位数
这些结果的列在此处描述。
我们使用 ClickHouse Keeper 23.5 和 ZooKeeper 3.8(带有捆绑的 OpenJDK 11)进行所有运行。请注意,我们不在这里列出三个表格化的结果,因为每个表格包含 216 行。您可以通过上面的链接查看结果。
示例结果
在这里,我们展示了两个图表,其中过滤了处理相同大小请求的 3 个模拟客户端(ClickHouse 服务器)并行发送的情况下,两个 Keeper 版本使用 3 个 CPU 核心和 2 GB RAM 运行的 99 分位数结果。这些可视化的表格结果在此处。
内存使用
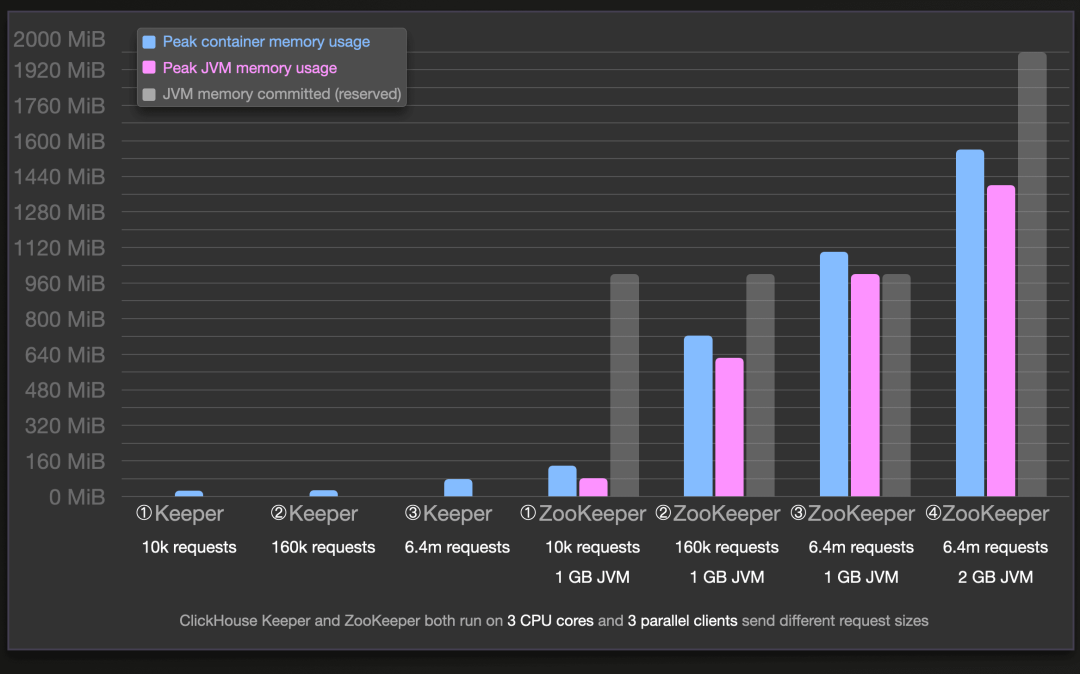
我们可以看到,对于我们模拟的工作负载,ClickHouse Keeper 对于相同数量的处理请求,始终比 ZooKeeper 使用更少的主内存。例如,对于处理由 3 个模拟 ClickHouse 服务器并行发送的 640 万个请求的基准运行 ③,ClickHouse Keeper 的主内存使用量比运行 ④ 中的 ZooKeeper 少约 46 倍。
对于 ZooKeeper,我们使用了 1GiB 的 JVM 堆大小配置(JVMFLAGS:-Xmx1024m -Xms1024m)进行所有主要运行(①、②、③),这意味着对于这些运行,已提交的 JVM 内存(保留的堆和非堆内存保证可供 Java 虚拟机使用)大小为 ~1GiB(请参见上图中透明的灰色条,显示使用了多少)。除了 Docker 容器的内存使用(蓝条)之外,我们还测量了实际在提交的 JVM 内存内使用的(堆和非堆)JVM 内存量(粉条)。运行 JVM 本身有一些轻微的容器内存开销(蓝条和粉条的差异)。然而,实际使用的 JVM 内存仍然一致显着大于 ClickHouse Keeper 的总体容器内存使用。
此外,我们可以看到 ZooKeeper 在运行 ③ 期间使用了完整的 1 GiB 的 JVM 堆大小。我们进行了额外的运行 ④,使用增加的 2 GiB JVM 堆大小进行了额外的运行,导致 ZooKeeper 使用了其 2 GiB JVM 堆的 1.56 GiB,运行时间与 ClickHouse Keeper 的运行 ③ 相匹配。我们在下一个图表中展示了所有运行的运行时间。我们在表格结果中看到,在 ZooKeeper 运行期间发生了几次(主要)垃圾回收。
运行时间和 CPU 使用
下图展示了在前一个图表中讨论的运行的运行时间和 CPU 使用情况(两个图表中的圆圈数字是对齐的):

ClickHouse Keeper 的运行时间与 ZooKeeper 的运行时间非常相近。尽管 ClickHouse Keeper 使用的主内存明显较少(请参见前一个图表),而且 CPU 使用率较低。
扩展 Keeper
我们观察到 ClickHouse Cloud 在与 Keeper 交互时经常使用多写事务。我们更深入地了解 ClickHouse Cloud 与 Keeper 的交互,勾勒出 ClickHouse 服务器使用的两个主要场景中的这些 Keeper 事务。
自动插入去重
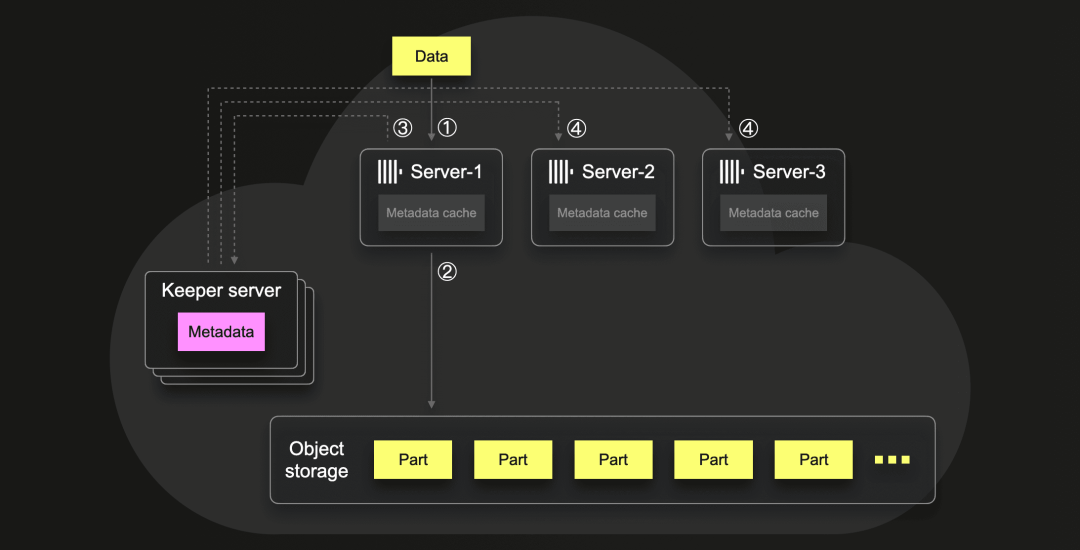
在上面勾画的场景中,服务器-2 ① 以块的形式处理插入到表中的数据。对于当前的块,服务器-2 ② 将数据写入对象存储中的新part,并使用 Keeper 多写事务在 Keeper 中存储有关新part的元数据,例如,part文件对应的 blob 存储在对象存储中的位置。在存储此元数据之前,事务首先尝试将步骤 ① 中处理的块的哈希总和存储在 Keeper 中的去重日志 znode 中。如果相同的哈希总和值已经存在于去重日志中,则整个事务失败(被回滚)。此外,步骤 ② 中的数据part会被删除,因为该part中包含的数据已经在过去插入过了。这种自动插入去重使得 ClickHouse 插入变得幂等,因此容错,允许客户端重试插入而无需担心数据重复。成功后,事务触发子监视器, ④ 所有订阅了part元数据 znodes 事件的 ClickHouse 服务器都会被 Keeper 自动通知新条目。这导致它们从 Keeper 中获取元数据更新到它们的本地元数据缓存中。
分配part合并给服务器
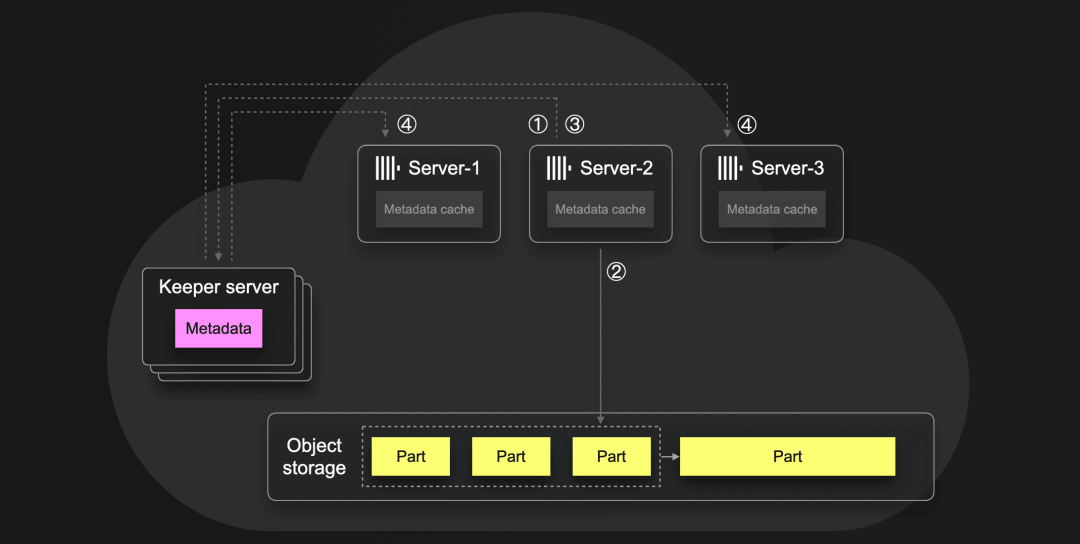
当 server-2 决定将一些part合并成一个较大的part时,那么该服务器 ① 使用 Keeper 事务将待合并的part标记为已锁定(以防止其他服务器将其合并)。接下来,服务器-2 ② 将这些part合并成一个新的更大的part, ③ 使用另一个 Keeper 事务存储有关新part的元数据,这触发监视器 ④ 通知所有其他服务器有关新元数据条目。
请注意,上述场景只有在这样的 Keeper 事务被 Keeper 原子地和顺序地执行时才能正确工作。否则,同时并行发送相同数据的两个 ClickHouse 服务器在去重日志中可能无法找到数据的哈希总和,从而导致在对象存储中出现数据重复。或者多个服务器将合并相同的part。为防止这种情况发生,ClickHouse 服务器依赖于 Keeper 的一切或无事务和其可线性化写入保证。
线性一致性与多核处理
ZooKeeper 和 ClickHouse Keeper 中的共识算法,分别是 ZAB 和 Raft,都确保多个分布式服务器可以可靠地达成相同的信息,例如上面的示例中允许合并哪些part。
ZAB 是 ZooKeeper 的专用共识机制,至少从 2008 年以来一直在开发中。
我们选择 Raft 作为我们的共识机制,原因是其简单易懂的算法以及在 2021 年我们启动 Keeper 项目时有一个轻量级且易于集成的 C++ 库可用。
然而,所有共识算法在本质上是同构的。对于可线性化写入,(依赖)事务和事务内的写操作必须以严格的顺序依次处理,不管使用哪种共识算法。假设 ClickHouse 服务器并行发送到 Keeper 的事务,并且这些事务是依赖的,因为它们写入相同的 znodes(例如,本节开头的示例场景中的去重日志),则 Keeper 只能通过严格按顺序执行此类事务及其操作来保证和实现线性一致性:
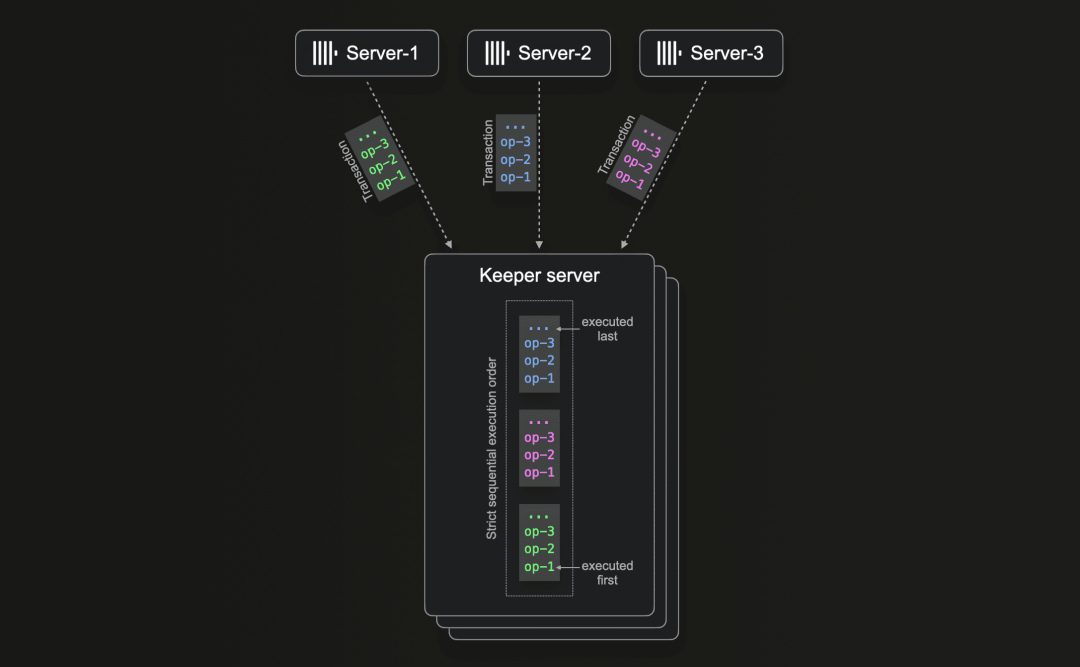
为此,ZooKeeper 使用单线程请求处理器实现写请求处理,而 Keeper 的 NuRaft 实现使用单线程全局队列。
一般来说,线性一致性使得垂直(更多的 CPU 核心)或水平(更多的服务器)扩展写入处理速度变得困难。可以分析和识别独立的事务并并行运行它们,但目前,无论是 ZooKeeper 还是 ClickHouse Keeper 都没有实现这一点。这个图表(我们在其中过滤了 99 分位数的结果)突显了这一点:
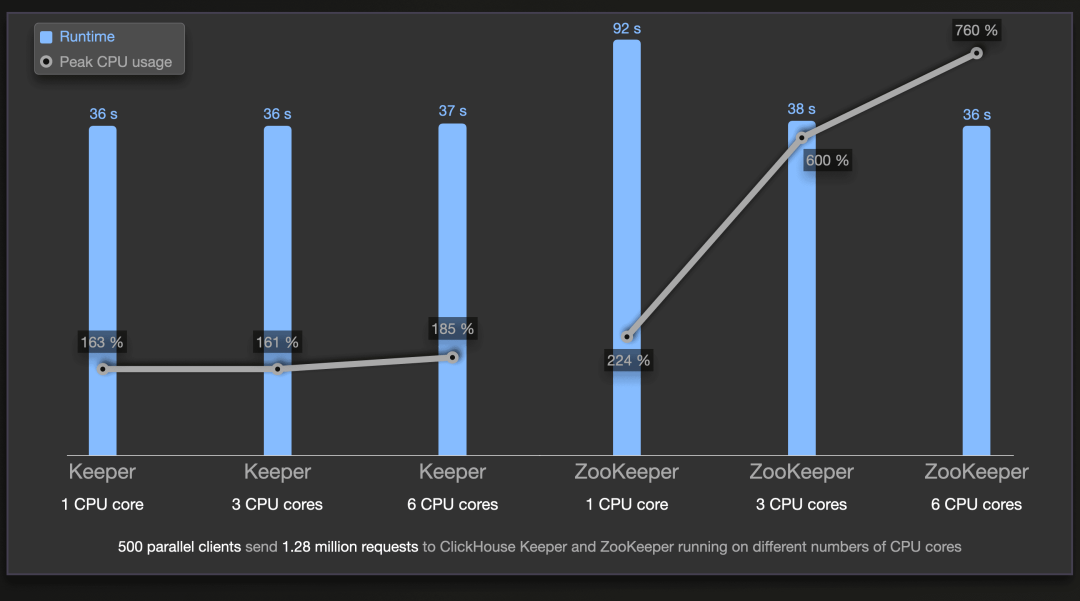
ZooKeeper 和 ClickHouse Keeper 都使用 1、3 和 6 个 CPU 核心并处理由 500 个客户端并行发送的 128 万总请求数。
我们的基准测试结果通常显示,从理论上讲,对于非线性化的读请求和辅助任务(管理网络请求、批处理数据等),ZAB 和 Raft 都可以按 CPU 核心的数量进行扩展。尽管我们一直在不断提高性能。
Keeper 的未来:Keeper 的多组 Raft 和更多
展望未来,我们看到有必要扩展 Keeper 以更好地支持我们上面描述的场景。因此,我们正在通过这个项目迈出一大步——引入 Keeper 的多组 Raft 协议。
因为如上所述,扩展非分区(非分片)线性化是不可能的,我们将专注于 Multi-group Raft,其中我们对存储在 Keeper 中的数据进行分区。这允许更多的事务独立于彼此(在不同分区上)工作。通过在同一服务器内的每个分区内使用单独的 Raft 实例,Keeper 可以自动并行执行独立的事务:
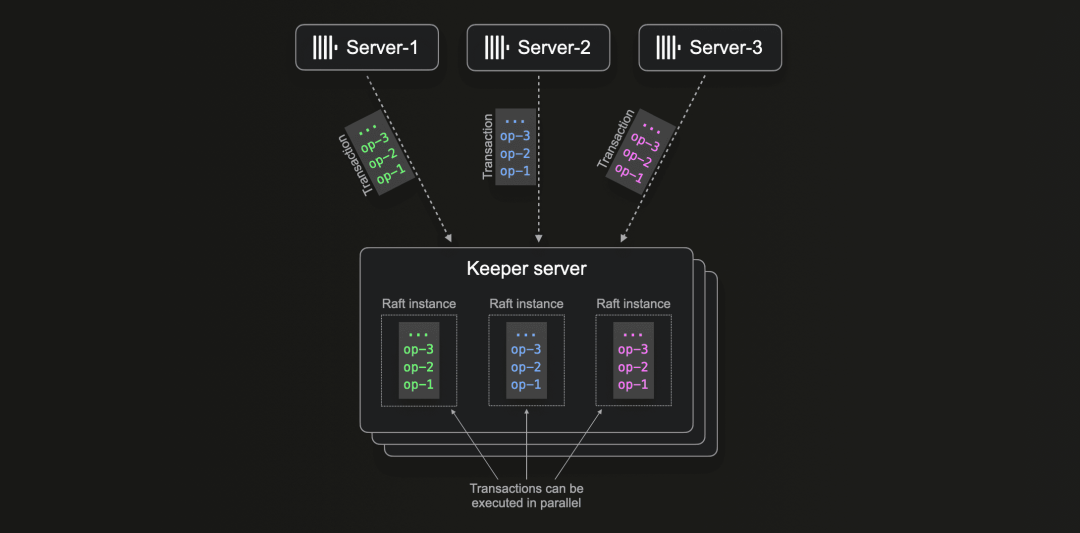
通过多 Raft,Keeper 将能够支持具有更高并行读/写要求的工作负载,例如具有数百节点的非常大的 ClickHouse 集群。
总结
在这篇博客文章中,我们描述了 ClickHouse Keeper 的特点和优势,这是 ZooKeeper 的资源高效开源替代品。我们探讨了它在 ClickHouse Cloud 中的使用情况,并基于此提供了一个基准测试套件和结果,突出显示 ClickHouse Keeper 在性能相当的情况下始终使用的硬件资源明显较少。我们还分享了我们的路线图以及您可以参与的方式。我们邀请您共同合作!

联系我们
手机号:13910395701
满足您所有的在线分析列式数据库管理需求
版权归原作者 ClickHouseDB 所有, 如有侵权,请联系我们删除。