
1,kafka简单介绍
kafka是一款分布式、支持分区的、多副本,基于zookeeper协调的分布式消息系统。最大的特性就是可以实时处理大量数据来满足需求。
2,kafka使用场景
1,日志收集:可以用kafka收集各种服务的日志 ,通过已统一接口的形式开放给各种消费者。
2,消息系统:解耦生产和消费者,缓存消息。
3,用户活动追踪:kafka可以记录webapp或app用户的各种活动,如浏览网页,点击等活动,这些活动可以发送到kafka,然后订阅者通过订阅这些消息来做监控。
4,运营指标:可以用于监控各种数据。
3,kafka基本概念
kafka是一个分布式的分区的消息,提供消息系统应该具备的功能。
名称
解释
broker
消息中间件处理节点,一个broker就是一个kafka节点,多个broker构成一个kafka集群。
topic
kafka根据消息进行分类,发布到kafka的每个消息都有一个对应的topic
producer
消息生产(发布)者
consumer
消息消费(订阅)者
consumergroup
消息订阅集群,一个消息可以被多个consumergroup消费,但是一个consumergroup只有一个consumer可以消费消息。
partition
分区,一个topic可以对应多个分区
replica
副本,是一个只能追加写消息的日志文件
offset
偏移量
kafka中的topic被分为了多个partition分区。topic实际上是一个逻辑概念,partition是最小的存储单元,存储着一个topic的部分数据。每个partition都是一个单独的log文件,每条记录都以追加的形式写入。
partition中的每条记录都会被分配一个特有的offset,当一条记录写入时,他会追加到log文件的末尾,并分配一个序号,作为一个offset。
这里需要注意顺序消费的场景。每个topic对应多个partition,这些分区是无序的,但是分区里面的数据是有序的,所以我们在做顺序消费的场景的时候,需要注意要将消息放到一个partition。
kafka集群
kafka支持集群化部署就是依赖于分区机制。

这么设计的优点:
1,如果把 Topic 的所有 Partition 都放在一个 Broker 上,那么这个 Topic 的可扩展性就大大降低了,会受限于这个 Broker 的 IO 能力。把 Partition 分散开之后,Topic 就可以水平扩展 。
2,一个 Topic 可以被多个 Consumer 并行消费。如果 Topic 的所有 Partition 都在一个 Broker,那么支持的 Consumer 数量就有限,而分散之后,可以支持更多的 Consumer。
3,一个 Consumer 可以有多个实例,Partition 分布在多个 Broker 的话,Consumer 的多个实例就可以连接不同的 Broker,大大提升了消息处理能力。可以让一个 Consumer 实例负责一个 Partition,这样消息处理既清晰又高效。
数据冗余
在kafka集群中,kafka为Partition做了数据冗余处理,这样即使一个broker挂了,消费者也可以在其他broker找到这个partition。
分区的写入
既然一个topic可以有多个Partition,那么消息进来的时候,到底该进那个Partition呢,kafka提供了三种模式
1,使用 Partition Key 写入特定 Partition
Producer 发送消息的时候,可以指定一个 Partition Key,这样就可以写入特定 Partition 了。
Partition Key 可以使用任意值,例如设备ID、User ID。
Partition Key 会传递给一个 Hash 函数,由计算结果决定写入哪个 Partition。
所以,有相同 Partition Key 的消息,会被放到相同的 Partition。
例如使用 User ID 作为 Partition Key,那么此 ID 的消息就都在同一个 Partition,这样可以保证此类消息的有序性。
这种方式需要注意 Partition 热点问题。
例如使用 User ID 作为 Partition Key,如果某一个 User 产生的消息特别多,是一个头部活跃用户,那么此用户的消息都进入同一个 Partition 就会产生热点问题,导致某个 Partition 极其繁忙。
2,由 kafka 决定
如果没有使用 Partition Key,Kafka 就会使用轮询的方式来决定写入哪个 Partition。
这样,消息会均衡的写入各个 Partition。
但这样无法确保消息的有序性。
3,自定义规则
Kafka 支持自定义规则,一个 Producer 可以使用自己的分区指定规则。
读取分区数据
kafka是一个pull模型的消息队列,他不会向消费者主动去推送消息。必须由消费者去轮询。基于这种设置,有下面几种情况
一共有三种情况。
1.分区数高于消费者数量
在这种场景下,消费者2需要消费分区-1和分区-2的消息,会导致消费流量倾斜,消费者2所在的服务实例负载较高。
2,分区数低于消费者数量
在这种场景下,消费者3没有分配到分区,不消费数据,消费者3所在的服务实例负载较低。
3,分区数是消费者数量的N倍(N=1,2,3...)
这种场景下,每个消费者负责的分区数量一致,消费者负载均衡。
通常Kafka产生堆积的原因都是消费速率跟不上生产速率,生产者发送消费没有什么业务逻辑,而消费者消费时需要等待业务逻辑处理。因此,我们来看看“不考虑优化业务逻辑的前提下,如何通过设置合理的Topic分区数来提高消费能力”。
1,不确定生产速率和消费速率:分区数 = 部署的服务实例数
当研发人员需要申请新的Topic但还无法预估生产者和消费者处理消息的能力时,可以先按照标准场景申请与 服务实例数 相等的分区数。
2,明确生产速率低于消费速率:分区数 = 部署的服务实例数
当业务系统稳定运行并且确定Topic的平均生产速率低于消费速率时,也应该申请与 服务实例数 相等的分区数,避免消息突增时作为消费者的服务实例负载倾斜。
3,生产速率高于消费速率(同时增加分区数和服务实例数):分区数 = 部署的服务实例数
当业务能预估到消息的生产速率高于消费速率,最直接的方式就是同时增加分区数和服务实例数,从而提高整体消费速率。但往往在非必要的情况下增加服务实例数会导致严重的资源浪费,因此在不增加服务实例数的前提下,也可以通过提高单机 并行度 来提高消费速率。
4,生产速率高于消费速率(增加分区数,服务实例数不变):分区数 = 部署的服务实例数 * N 承接上一个场景,假设服务实例数为4,需要申请12个分区,那么单机 并行度 = 3,并行度在消费者注解中添加,如下
concurrency = "3":
但设置并行度的场景存在一个弊端:服务实例扩容时,可能会出现消费者总数大于分区数,从而导致负载不均衡。
顺序消费
在Kafka中,Topic在单个分区的生产消费是有序的。通常我们申请多个分区是为了提高生产消费的吞吐量,但多个分区就会导致消费消息时无序。保证顺序消费的方法有:
要想保证顺序消费,就必须要保证顺序消费的消息在同一个队列。
1.只申请1个分区:仅推荐在吞吐量低的顺序场景下用
2.这种场景申请多个分区,生产时使用消息Key:生产者发送消息时如果指定了Key,则这条消息会根据Key的Hash发送到对应的分区,也就是说带有相同Key的消息会被发送到相同的分区。(如果不携带Key的话是轮询发送到所有分区)
顺序消费典型的应用场景:
1,用于同步数据库和redis之间的数据(单个消费者)
2,某些电商场景必须严格遵守消息的执行顺序,比如说待支付--已支付---开始发货---订单完成----评价。如果开始发货在已支付之前面执行,就会产生业务问题。
在使用消息key来确保消息发布到多个分区时,要注意key的hash,尽量避免大多数消息发布到一个分区,否则会出现流量倾斜。
批量消费
批量消费可以一次性消费到多条消息,如果是顺序不敏感的业务,可以另外开启线程池多线程处理这批消息。但是需要特别注意的是:
1,当这批消息里有个别消息处理失败,有可能会导致其他没处理失败的消息重试,处理逻辑需要做好业务幂等;
2,触发重试必须在 @KafkaListener 注解的方法中抛出 BatchListenerFailedException 这个异常(默认重试9次后打印错误日志),并在异常中设置这批消息中索引最小的消费失败的消息(后面会给出示例);
import org.apache.kafka.clients.consumer.ConsumerConfig; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory; import org.springframework.kafka.core.ConsumerFactory; import java.util.Properties; @Configuration public class Aaa { @Bean public ConcurrentKafkaListenerContainerFactory<?, ?> batchFactory(ConsumerFactory<Object, Object> kafkaConsumerFactory) { ConcurrentKafkaListenerContainerFactory<Object, Object> factory = new ConcurrentKafkaListenerContainerFactory<>(); factory.setConsumerFactory(kafkaConsumerFactory); // 表示开启批量消费 factory.setBatchListener(true); Properties properties = new Properties(); // 表示批量消费时最大批次为50条 properties.setProperty(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, "50"); // 禁用轮询自动提交offset,而是每消费完一批消息提交一次offset properties.setProperty(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false"); factory.getContainerProperties().setKafkaConsumerProperties(properties); return factory; } }
import javafx.util.Pair; import lombok.extern.slf4j.Slf4j; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.springframework.kafka.annotation.KafkaListener; import org.springframework.kafka.listener.BatchListenerFailedException; import org.springframework.stereotype.Service; import java.util.List; import java.util.Optional; import java.util.Random; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; @Slf4j @Service public class KafkaConsumer { private final ExecutorService executorService = Executors.newFixedThreadPool(10); @KafkaListener(topics = "arch-kafka-admin", groupId = "kafka-admin", containerFactory = "batchFactory") public void consume(List<ConsumerRecord<String, DataDTO>> records) { // 提交到线程池处理并获取处理结果 Optional<Pair<ConsumerRecord<String, DataDTO>, Exception>> firstFailRecord = records.stream() .map(record -> new Pair<>(record, executorService.submit(() -> process(record)))) .map(fp -> { Exception e; try { e = fp.getValue().get(); } catch (Exception ex) { e = ex; } return new Pair<>(fp.getKey(), e); }) .filter(fp -> fp.getValue() != null) .findFirst(); // 批量消费有异常的, 获取第一个产生异常的消息, 并抛出 BatchListenerFailedException 触发重试 if (firstFailRecord.isPresent()) { Pair<ConsumerRecord<String, DataDTO>, Exception> pair = firstFailRecord.get(); ConsumerRecord<String, DataDTO> record = pair.getKey(); log.error(pair.getValue().getMessage(), pair.getValue()); throw new BatchListenerFailedException(String.format("批量消费失败: 分区: %s, 偏移量: %s", record.partition(), record.offset()), record); } } // 模拟业务处理 public Exception process(ConsumerRecord<String, DataDTO> record) { try { // 模拟业务处理 Thread.sleep(new Random().nextInt(100)); return null; } catch (Exception e) { return e; } } }
重试需要在 consume 方法所在的线程中抛出
BatchListenerFailedException 异常才能触发正确的重试,抛出其他异常会导致无限重试。
提交策略
1,自动提交:默认配置(配置中心公共配置)为自动提交,即每隔一段时间(默认5s)提交一次,自动提交可以很大程度上降低Kafka服务端的压力,并且减少客户端的网络开销,如果消费逻辑做好了业务幂等,尽可能选择自动提交。 实际上自动提交并不是严格地每间隔一段时间提交一次偏移量(旧版的客户端是有一个AutoCommitTask进行轮询提交),而是每次在调用 KafkaConsumer.poll()时判断当前时间距离上次提交时间是否超过了配置了提交间隔,如果超过了就进行提交,所以实际上的提交时间会超过配置的提交间隔。另外由于KafkaConsumer.poll()方法会返回多条消息(由配置项,max.poll.records控制),因此如果上一批消息消费耗时超过提交间隔,也会导致实际提交时间推迟。
2,手动提交:即spring.kafka.consumer.enable-auto-commit=false,设置手动提交时需要主动调用提交方法,具体方法根据使用的客户端而定。当消息量较大时使用手动提交会给Kafka服务端带来压力,并增加客户端的网络开销,不过还是建议重要消息或者是无法保证业务幂等的消费逻辑使用手动提交。
使用kafka-client:Kafka自带的客户端,需要主动调用KafkaConsumer.commitSync()或KafkaConsumer.commiAsync()进行偏移量提交。
使用spring-kafka:基于spring和kafka-client封装的高阶API,当是否自动提交设置为false时,每消费完一条消息就会自动提交一次偏移量(同步提交),无需手动调用API提交。
kafka如何保证高并发
kafka的高并发依赖于页缓存技术和磁盘顺序写。
有研究表名,在磁盘中的顺序读写要比在内存中的随机读写要快。
页缓存技术是操作系统级别的缓存(page cache),即先将数据写入到系统缓存中(内存),并且是只写入到内存中,由操作系统决定什么时候写入磁盘。

kafka在写数据的时候,是以顺序写的方式来刷盘的,即只在文件末尾来追加数据,而不是在文件的随机位置写入数据。
上面那个图里,Kafka 在写数据的时候,一方面基于 OS 层面的 Page Cache 来写数据,所以性能很高,本质就是在写内存。
另外一个,它是采用磁盘顺序写的方式,所以即使数据刷入磁盘的时候,性能也是极高的,也跟写内存是差不多的。
零拷贝技术(netty)
操作系统层面的技术。操作系统里面的进程有两种类型,一个是操作系统级别的,一个是用户级别的。其中操作系统级别的可以直接访问内存,直接对系统内存进行读写。用户级别的进程(咱们的java项目,或者redis等等第三方应用)是不能直接操作内存和硬盘等硬件的,必须由操作系统去操作。于是就有了两个缓冲区,一个是用户缓冲区,一个是内核缓冲区。第三方应用程序先通过操作系统将想要拿到的数据告诉操作系统,然后操作系统放到用户缓冲区,这个时候咱们的程序才可以拿到数据。
采用常规的思路,kafka获取数据的流程:
1,操作系统从磁盘中拿到数据,放到内核缓冲区,2,然后再从内核缓冲区复制数据到用户缓冲区,3,然后再用用户缓冲区放到socket缓冲区(也是系统级别的,用户进程无法直接操作),4,最后再从socket缓冲区通过网卡发送出去。
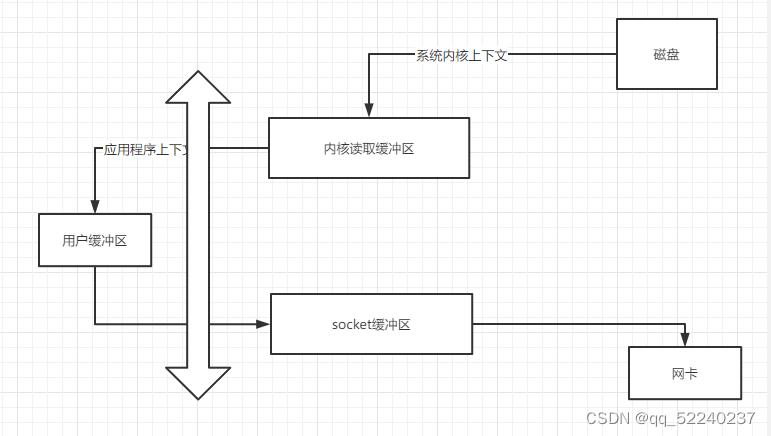
可以看到从磁盘到内核读取缓冲区复制了一次,从内核缓冲区复制到用户缓冲区,复制了一次,从用户缓冲区复制到socket缓冲区复制了一次,从socket缓冲区复制到nicbuffer复制了一次。一共是复制了4次,期间还进行了2次上下文切换
但是使用了零拷贝技术,网卡可以直接从内核缓冲区去读取数据。这样就可以实现内核空间和应用空间之间的零拷贝了。
拷贝步骤:
1,操作系统将磁盘中的数据放到内核读取缓冲区
2,网卡直接从内核读取缓冲区获取数据发送。
以上是kafka 的读和写,当我们的kafka集群如果经过调优,可以达到写的时候写入到oscache中,读的时候也从oscache中读。
版权归原作者 qq_52240237 所有, 如有侵权,请联系我们删除。