
1、什么是kafka?它能解决什么问题?
简介
Apach Kafka是一款分布式流处理平台,用于实时构建流处理应用。它有一个核心的功能广为人知,即作为企业级的消息引擎被广泛使用。作用
- 解耦:短信发送成功后,需要通知A、B、C、D等服务,我们只管发送到MQ不用耦合一个个通知其他服务。通道商回调通知短信发送情况,需要通知A、B、C、D等服务,我们只管发送到MQ不用耦合一个个通知其他服务。
- 异步:用户注册后,发送短信和邮件,通过发送MQ异步消费的形式实现,可以减少接口的耗时。用户购买后,发送push通知和券激励,通过发送MQ异步消费的形式实现,可以减少接口的耗时。
- 削峰:秒杀保护服务
2、kafka整体架构?
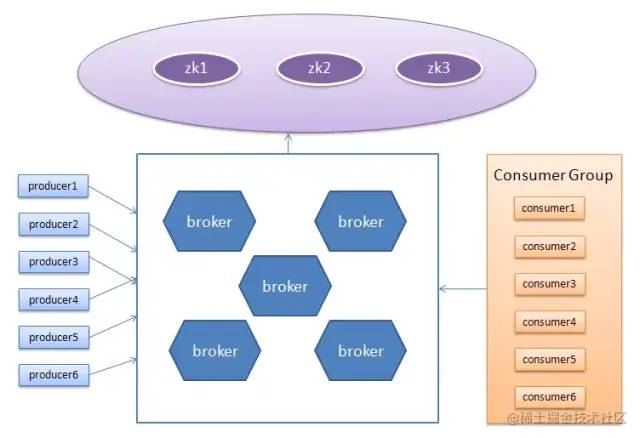
0.8版本之前的架构图
在 0.8版本之后,consumer 不会再与zookeeper直接通信了
- broker集群(可以有多个) - 每个kafka server称为一个Broker,多个borker组成 Kafka Cluster。
- 生产者组(可以有多个)
- 消费者组(可以有多个)
- Topic(可以包含多个分区,同时每个分区可以有多个副本) - 创建时需要选择存储在哪个broker cluster- 需要指定分区partition的数量,默认4
消费组中的消费数目与主题中的分区数目关系?
- 消费者数小于分区数,此时一个消费者会消费多个分区
- 消费者数大于分区数,此时一个消费者会消费一个分区,多余消费者会空闲
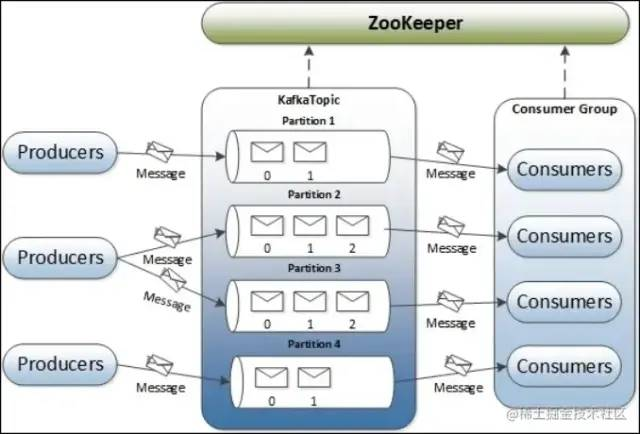
3、Topic的分区是如何存储在broker的磁盘?请描述知道offset从broker检索消息的过程?
逻辑 message 属于 topic 的哪个 partition。
日志采用分段存储
- 索引文件分段
- 存储文件分段
日志分段配置
server.properties
log.segment.bytes=1073741824(1G) log.dirs=/tmp/kafka-logs日志内容解读【下面是一行物理日志信息】
baseOffset: 1778276 lastOffset: 1778362 count: 87 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 0 CreateTime: 1645765269680 size: 44169 magic: 2 compresscodec: NONE crc: 1917853349 isvalid: true
一条批消息(Record Batch)日志记录,包含多条的实际数据 lastOffset - baseOffset + 1 = count
- baseOffset和lastOffset为批消息中第一条记录和最后一条记录的偏移量,在整个topic分区中的偏移量
- count为批消息中包含的记录数
- position为批消息的起始位置(这里应该是物理地址),每个log文件中,position 都是从0开始的
- CreateTime在批消息中为批消息中最后一条记录的创建时间,在记录中为记录的创建时间
- size为批消息的大小,从内容可以看出,前一条批消息的position,加上前一条消息的size,结果为后一条消息的position
- offset为记录的偏移量,整个topic分区中的偏移量
- size为一条记录的大小
- 其他字段有些没有用到,所以显示-1,有些暂时也不清楚
偏移量索引文件
偏移量索引(.index)项的格式如下图所示。每个索引项占用8个字节,分为两个部分。
- relativeOffset:相对偏移量,表示消息相对于baseOffset 的偏移量,即消息的offset - baseOffset,占用4个字节,当前索引文件的文件名即为 baseOffset 的值。消息的 offset 占用8个字节,也可以称为绝对偏移量。索引项中没有直接使用绝对偏移量而改为只占用4个字节的相对偏移量(relativeOffset =offset - baseOffset),这样可以减小索引文件占用的空间。
- position:物理地址,也就是消息在日志分段文件中对应的物理位置(即 .log 文件的 position 字段),占用4个字节。
如果要查找偏移量为268的消息,过程应该是:首先是定位到 baseOffset 为251的日志分段,然后计算相对偏移量relativeOffset = 268 - 251 = 17 ,之后再在对应的索引文件中找到不大于17的索引项,最后根据索引项中的 position 定位到具体的日志分段文件位置开始查找目标消息。
偏移量索引文件
时间戳索引(.timeindex)项的格式,每个索引项占用12 个字节,分为两个部分。
- timestamp : 当前日志分段最大的时间戳。
- relativeOffset :时间戳所对应的消息的相对偏移量。
时间戳索引文件中包含若干时间戳索引项,每个追加的时间戳索引项中的 timestamp 必须大于之前追加的索引项的 timestamp ,否则不予追加。


4、消费者如何利用零拷贝技术提高效率?
消息消费的基本流程
- broker收到consumer的消费请求
- broker从磁盘读取消息
- broker通过网络将消息发送给consumer
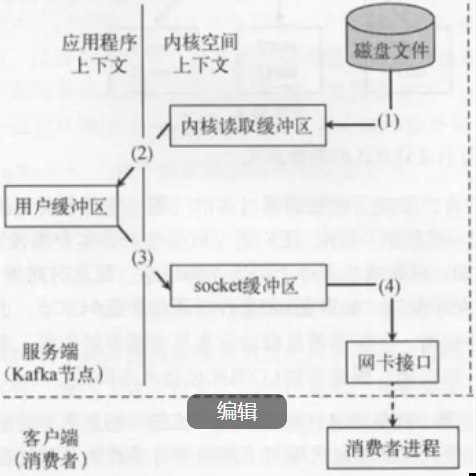
传统的消息消费流程
默认有4次拷贝
- 磁盘到内核缓存冲区
- 内核缓存冲区到用户缓冲区
- 用户缓冲区到socket缓冲区
- socket缓冲区到网卡
零拷贝方式消费流程
版权归原作者 写的更好 所有, 如有侵权,请联系我们删除。