
以下是面试时公司最新的面试题,我自己做了一遍,讲了一遍,代码都是亲自测试和编写的,希望对大家有所帮助,有问题欢迎留言,如果对你有用,留个好评,谢谢了!!
- 表如下,请计算每个月每个部门评分大于等于90的人数,评分大于等于90的人数环比增长率,评分有提升的人数。
年月 姓名 部门 评分
202101 张三 销售 90
202101 李四 技术 90
202101 王五 运营 80
202101 赵六 销售 70
202101 孙七 技术 95
202101 周八 运营 93
202101 吴九 销售 84
202101 郑十 技术 83
202102 张三 销售 95
202102 李四 技术 95
202102 王五 运营 95
202102 赵六 销售 95
思路:
1、获取每个月每个部门评分大于等于90的人数 -- t1
2、将 t1 和 t1 自关联,求增长率
3、将自身的表和自身的表关联,求分数有提升的人数
4、将所有的结果展示一下
本地模式:
set hive.exec.mode.local.auto=true;
//开启本地mr
//设置local mr的最大输入数据量,当输入数据量小于这个值时采用local mr的方式,默认为134217728,即128M
set hive.exec.mode.local.auto.inputbytes.max=50000000;
//设置local mr的最大输入文件个数,当输入文件个数小于这个值时采用local mr的方式,默认为4
set hive.exec.mode.local.auto.input.files.max=10;
CREATE TABLE `empgo` (
dt STRING ,
name STRING ,
dept STRING ,
score int
);
set hive.stats.column.autogather=false;
insert into empgo values ('202101','张三','销售','90');
insert into empgo values ('202101','李四','财务','90');
insert into empgo values ('202101','王五','运营','80');
insert into empgo values ('202101','赵六','销售','70');
insert into empgo values ('202101','孙七','技术','95');
insert into empgo values ('202101','周八','运营','93');
insert into empgo values ('202101','吴九','销售','84');
insert into empgo values ('202101','郑十','技术','83');
insert into empgo values ('202102','张三','销售','95');
insert into empgo values ('202102','李四','技术','95');
insert into empgo values ('202102','王五','运营','95');
insert into empgo values ('202102','赵六','销售','95');
启动 spark 的服务:
hive-server-manager.sh stop hiveserver2
/opt/installs/spark/sbin/start-thriftserver.sh \
--hiveconf hive.server2.thrift.port=10001 \
--hiveconf hive.server2.thrift.bind.host=shucang \
--master yarn \
--conf spark.sql.shuffle.partitions=2
看 hive 的日志,你觉得需要看什么?
1、hive.log
2、metastore.log hiveserver2.log
3、hadoop 的日志(yarn 的日志)
环比增长率=2月人数/1月人数-1
第一步:
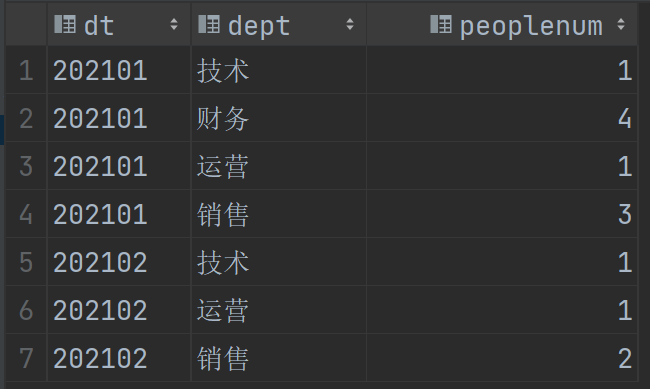
select dt,dept,count(1) peopleNum from empgo where score >=90 group by dt,dept;
第二步:将 t1 和 t1 自关联,求增长率
with t as (
select dt,dept,count(1) peopleNum from empgo where score >=90 group by dt,dept
)
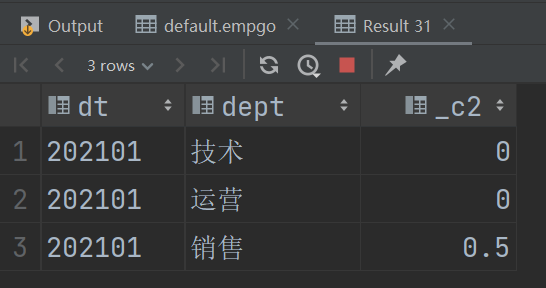
select t2.dt,t2.dept,round((t2.peopleNum-t1.peopleNum)/t1.peopleNum-1,2) from t t1 join t t2 on t1.dept = t2.dept and t1.dt = date_format(add_months(from_unixtime(unix_timestamp(t2.dt,'yyyyMM')),1),'yyyyMM')
;
结果:
还有另一个做法:
with t as (
select dt,dept,count(1) peopleNum from empgo where score >=90 group by dt,dept
),t2 as(
select *,lag(peopleNum,1,peopleNum) over(partition by dept order by dt ) lastMonthNum from t
)
select t2.dept,t2.dt,peopleNum/lastMonthNum-1 from t2 ;
第三步:将自身的表和自身的表关联,求分数有提升的人数
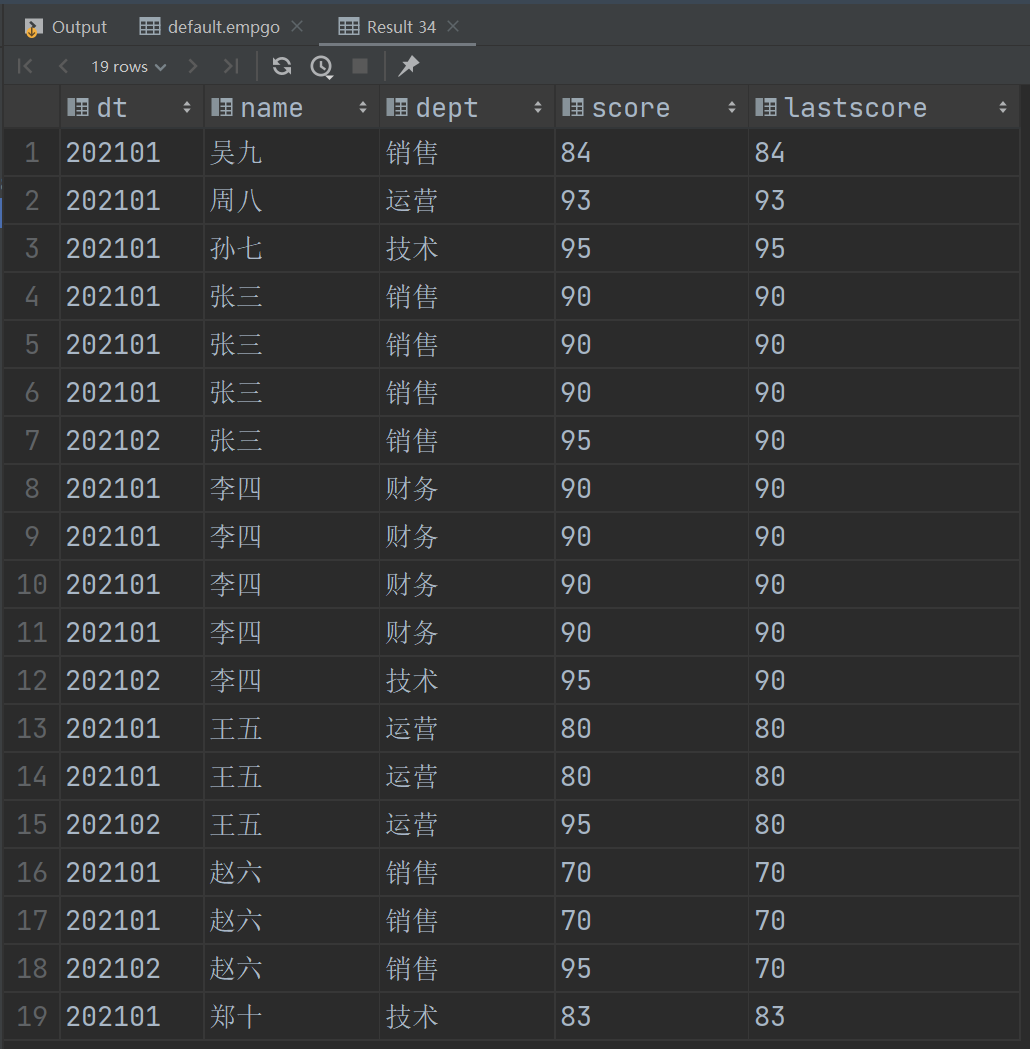
with getlastscore as (
select *,lag(score,1,score) over(partition by name order by dt ) lastScore from empgo
)
select * from getlastscore ;
with getlastscore as (
select *,lag(score,1,score) over(partition by name order by dt ) lastScore from empgo
)
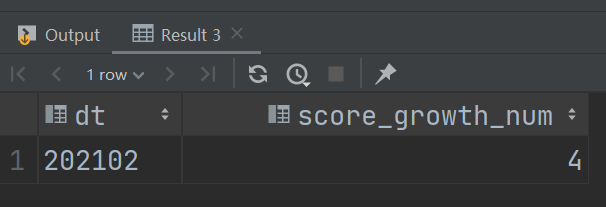
select dt,count(1) score_growth_num from getlastscore where score > lastScore group by dt ;
-- 请计算每个月每个部门评分大于等于90的人数,评分大于等于90的人数环比增长率,评分有提升的人数。
with t as (
select dt,dept,count(1) peopleNum from empgo where score >=90 group by dt,dept
),rate_growth as(
select t2.dt,t2.dept,round((t2.peopleNum/t1.peopleNum)-1,2) grow_rate,t1.dt tt from t t1 join t t2 on t1.dept = t2.dept and t1.dt = date_format(add_months(from_unixtime(unix_timestamp(t2.dt,'yyyyMM')),1),'yyyyMM')
),getlastscore as (
select *,lag(score,1,score) over(partition by name order by dt ) lastScore from empgo
),score_growth as (
select dt,count(1) score_growth_num from getlastscore where score > lastScore group by dt
)
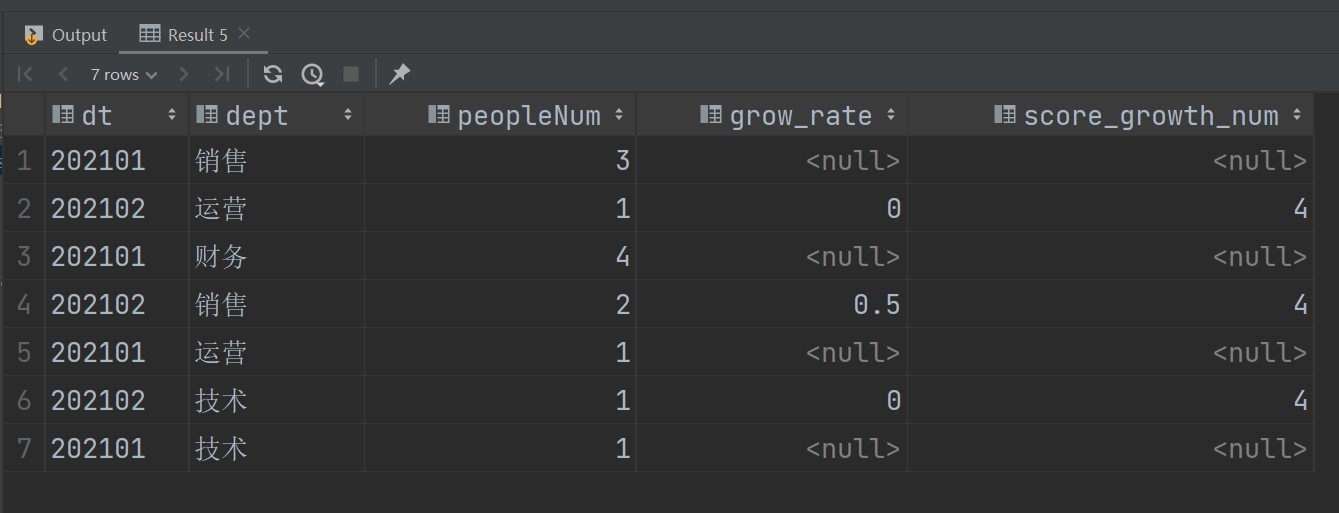
select
t.dt,
t.dept,
t.peopleNum,
rate_growth.grow_rate,
score_growth_num
from t left join rate_growth on t.dt=rate_growth.tt and t.dept = rate_growth.dept
left join score_growth on t.dt = score_growth.dt
;
最终结果:
2.交易记录表,表结构如下,请计算每个月各产品的购货人数,购货金额,购货金额排名,复购人数
(复购:前5个月曾购买此产品,本月有购买;购买: 购货金额大于0)
年月 订单号 原定单号 是否退货单 产品 购货人 金额 数量
202101 s100000 s100000 0 苹果 A 10 2
202101 s100001 s100000 1 苹果 A -10 2
202101 s100002 s100002 0 西瓜 C 50 1
202106 s100003 s100003 0 西瓜 C 50 1
202102 ... ... ... ... ... ... ...
create table deal (
dt string,
orderId string,
oldOrderId string,
isReturn int,
producee string,
customer string,
money int,
num int
);
insert into deal values ('202101','s100000','s100000',0,'苹果','A',10,2);
insert into deal values ('202101','s100001','s100000',1,'苹果','A',-10,2);
insert into deal values ('202101','s100002','s100002',0,'西瓜','C',50,1);
insert into deal values ('202106','s100003' ,'s100003',0,'西瓜','C', 50,1);
insert into deal values ('202101','s100004' ,'s100004',0,'西瓜','A', 50,1);
-- 请计算每个月各产品的购货人数,购货金额,购货金额排名,复购人数
-- (复购:前5个月曾购买此产品,本月有购买;购买: 购货金额大于0)
-- 第一步:求每个月各产品的购货人数,购货金额
select dt,producee,sum(money) from deal where money > 0 group by dt,producee ;
-- 第二步:每个月每个产品的购货排名
with t as (
select dt,producee,sum(money) summoney from deal where money > 0 group by dt,producee
),t2 as(
select dt,producee,dense_rank() over(partition by dt order by summoney desc) paiming from t
)
select * from t2;
-- 第三步:求每一个月每个产品的复购人数
-- 复购人数 (复购:前5个月曾购买此产品,本月有购买;购买: 购货金额大于0)
select d1.dt,d1.producee,count(1) fugou from deal d1 left join deal d2
on d1.customer = d2.customer and d1.producee = d2.producee
where d2.dt >= date_format(add_months(from_unixtime(unix_timestamp(d1.dt,'yyyyMM')),-5),'yyyyMM')
and d2.dt < d1.dt group by d1.dt,d1.producee;
-- 综合一下sql语句即可:
-- 请计算每个月各产品的购货人数,购货金额,购货金额排名,复购人数
-- -- (复购:前5个月曾购买此产品,本月有购买;购买: 购货金额大于0)
with t as (
select dt,producee,sum(money) summoney,count(distinct customer) peopleNum from deal where money > 0 group by dt,producee
),t2 as(
select dt,producee,dense_rank() over(partition by dt order by summoney desc) paiming from t
),t3 as (
select d1.dt,d1.producee,count(1) fugou from deal d1 left join deal d2
on d1.customer = d2.customer and d1.producee = d2.producee
where d2.dt >= date_format(add_months(from_unixtime(unix_timestamp(d1.dt,'yyyyMM')),-5),'yyyyMM')
and d2.dt < d1.dt group by d1.dt,d1.producee
)
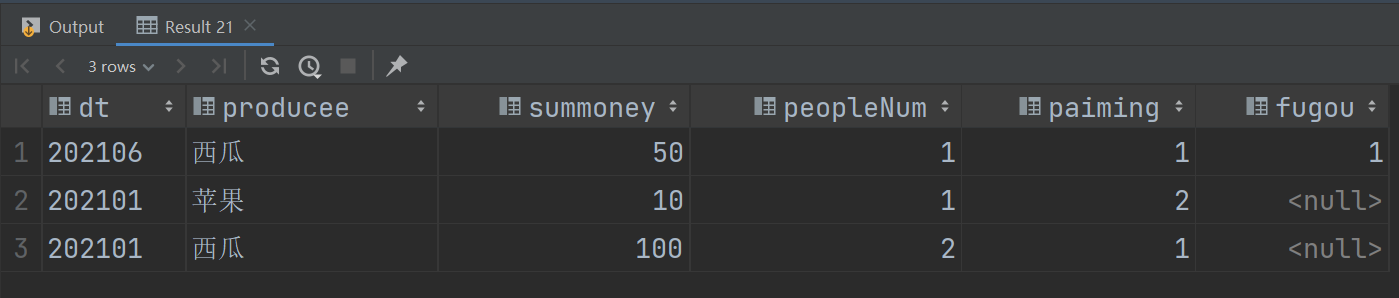
select t.dt,
t.producee,
t.summoney,
t.peopleNum,
t2.paiming,
nvl(t3.fugou,0)
from t join t2 on t.dt=t2.dt and t.producee=t2.producee left join t3 on t.dt=t3.dt and t.producee=t3.producee;
最终结果:
3、交易记录表,表结构如下,请计算每个月购货人同时购买苹果和西瓜的金额(购货人单月只购买其中一样不计算,需在一个月内两个都购买)
年月 订单号 原定单号 是否退货单 产品 购货人 金额 数量
202101 s100000 s100000 0 苹果 A 10 2
202101 s100001 s100000 1 苹果 A -10 2
202101 s100002 s100002 0 西瓜 C 50 1
202101 s100003 s100003 0 苹果 C 10 1
202102 ... ... ... ... ... ... ...
CREATE TABLE IF NOT EXISTS orders_info (
year_month string,
order_number string,
original_order_number string,
is_return_order int,
product string,
purchaser string,
amount double,
quantity int
);
INSERT INTO TABLE orders_info
VALUES
('202101','s100000','s100000',0,'苹果','A',10.0,2),
('202101','s100001','s100000',1,'苹果','A',-10.0,2),
('202101','s100002','s100002',0,'西瓜','C',50.0,1),
('202101','s100003','s100003',0,'苹果','C',10.0,1);
思路:
1、先获取购买西瓜或者苹果的人的信息
2、将两个表关联,谁的条数等于 2 就是谁
with t as (
select year_month,purchaser,product,sum(amount) total_money from orders_info where product='西瓜' or product='苹果' and amount >0 group by year_month,purchaser,product
)
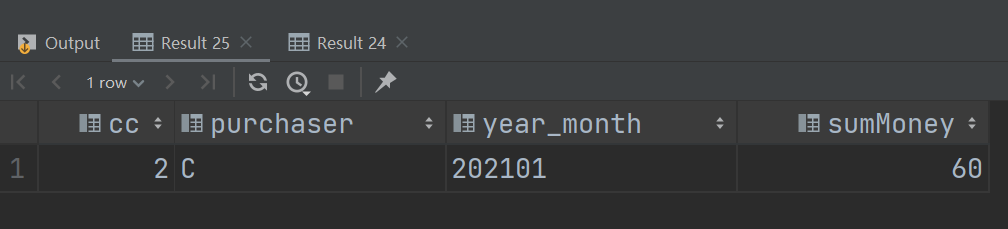
select count(product) cc,purchaser,year_month,sum(total_money) sumMoney from t group by year_month,purchaser having cc = 2;

本文转载自: https://blog.csdn.net/wozhendeyumenle/article/details/143824109
版权归原作者 二进制_博客 所有, 如有侵权,请联系我们删除。
版权归原作者 二进制_博客 所有, 如有侵权,请联系我们删除。