
问题解决方案:
步骤一:
在jdbc url 后面追加参数 ,设定各种超时时间参数设置为1800秒,因为hive任务可能会执行比较久,所以超时时间设置长一点
hive.metastore.client.socket.timeout=1800&hive.server.read.socket.timeout=1800&hive.server.write.socket.timeout=1800&hive.server.thrift.socket.timeout=1800&hive.client.thrift.socket.timeout=1800
以下是我追加参数后的url
jdbc:hive2://bigdata-test:10000/test?mapreduce.job.queuename=root.test&hive.metastore.client.socket.timeout=1800&hive.server.read.socket.timeout=1800&hive.server.write.socket.timeout=1800&hive.server.thrift.socket.timeout=1800&hive.client.thrift.socket.timeout=1800,username=hdfs,password=hdfs
步骤二:
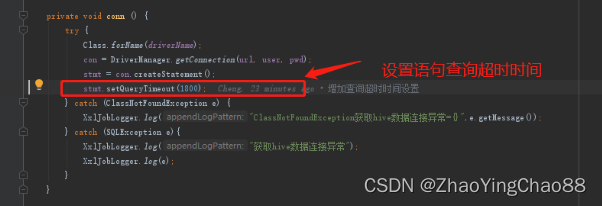
在通过jdbc 创建 Statement 语句对象时,设置语句对象的查询超时时间为1800秒,由于执行hive sql 比较耗时,所以一定要设置一个合理的时间,等待hive sql 返回结果(此步骤非常关键!!!)
对应的api 方法如下: stmt为 java.sql.Statement 对象实例
stmt.setQueryTimeout(1800);
对应的截图如下:
本文转载自: https://blog.csdn.net/ZYC88888/article/details/127132608
版权归原作者 ZhaoYingChao88 所有, 如有侵权,请联系我们删除。
版权归原作者 ZhaoYingChao88 所有, 如有侵权,请联系我们删除。