
泰迪杯A题通讯产品销售和盈利能力分析一等奖作品
感谢商丘师范学院的高老师,韩老师,陈老师等提供的比赛作品数据
1. A 题 通讯产品销售和盈利能力分析 简介
一、背景
进入本世纪以来,我国通讯产品得到了飞速发展,其技术先进,价格便宜,
深受世界各国和地区尤其是非洲国家的欢迎。某通讯公司在非洲的多个国家深耕多年,产品与服务遍布整个非洲大陆。为了更好地了解公司的销售情况,采用产品的销售额和利润数据,对其盈利能力进行分析和预测,给决策人员提供分析报告,以便为非洲各国提供更好的产品销售策略和服务。
二、目标
- 统计产品在当地的销售数据,预测未来的销售情况。
- 设计可视化数字大屏,展示产品的销售情况,分析产品的盈利能力。
三、任务
请根据附件中提供的数据(其中,金额计量单位:万元;合同数计量单位:
个),自行选择分析工具完成以下任务,并撰写报告。如使用“TipDM-BI 数据分析和可视化平台”实现,使用方式详见附录。
任务 1 数据分析与预测
根据附件“非洲通讯产品销售数据”中的数据,分别实现以下任务:
任务 1.1 统计各个年度/季度中,地区、国家、服务分类的销售额和利润数
据,并计算各国、各服务分类销售额和利润的同比增长率。
任务 1.2 统计各地区、国家有关服务分类销售额和利润数据。
任务 1.3 统计各个销售经理的成交合同数和成交率。
任务 1.4 分别预测各个地区、国家、服务分类 2021 年第一季度销售额和利
润。
任务 2 可视化展示和撰写分析报告
对各地区、国家、服务分类的产品销售额和利润等数据,以及销售经理的业绩数据,进行同比、类比、相关性等分析或预测,发现趋势。根据分析和预测结果,设计一个数字大屏,根据目标,合理布局,展示能够代表产品销售情况和盈利能力的数据指标和可视化图表等。
在下面任务不同的维度分析中,必要时,可以设置选择框,使用联动的方式,根据选择框,查看和展示该选择框范围的数据和可视化图表。例如,设立国家选择框,选项包括“全部”和国家名称,可以查看全部或某个国家的指标数据和可视化图表。其他类推。
数字化大屏至少包括以下任务:
任务 2.1 绘制非洲各国产品的销售地图,并能够查看该国的销售额和利润。
根据销售额的降序排列,绘制非洲各国产品销售额和利润数据的图表。
任务 2.2 根据地区、国家等维度,绘制各服务分类的销售额和利润的年增
长率及各季度同比增长率的图表。
任务 2.3 根据地区、国家等维度,绘制 2021 年第一季度各服务分类的销售
额和利润预测值的图表。
任务 2.4 绘制销售经理的销售合同数前 5 名排行榜。
任务 2.5 绘制销售额后 10 名的国家排行榜。
任务 2.6 分析数字大屏的指标数据和图表,撰写公司产品的销售情况和盈
利能力的分析报告。
四、关于竞赛成果提交的说明
- 登录方式 请使用队长的账号登录数睿思网站(www.tipdm.org),进入**第四届技能赛**页面。为保证成功提交,请使用谷歌浏览器无痕模式。
- 作品提交 报告以 PDF 格式提交,文件名为“report.pdf”,要求逻辑清晰、条理分 明,内容包括每个任务的完成思路、操作步骤、必要的中间过程、任务的结果及分析。 针对任务 1,报告中应包含但不限于如下要点: (1) 任务 1.1 需要展示 2020 年年度销售额前 3 名的国家及其年增长率。 (2) 任务 1.2 需要展示各地区有关服务分类利润数据。 (3) 任务 1.3 需要展示销售经理成交合同数前 3 名的数据。 (4) 任务 1.4 需要给出明确的预测模型,并展示地区、国家、服务分类 销售额预测值最大的 1 条数据。
- 附件提交 3.1 将任务 1、2 所编写的源程序文件,分别用“task1”、“task2”命名,保存在“program”文件夹中;如使用 TipDM-BI 数据分析和可视化平台实现,将使用平台创建的自助仪表盘截图保存到“program”文件夹中。 3.2 将任务 1、2 所产生的结果文件,分别保存到“result1”,“result2”文件夹,然后存放到“result”文件夹中。 3.3 将程序文件夹“program”、结果文件夹“result”以及报告的 word版本打包成“appendix.zip”,作为附件提交。
2. 一等奖作品分享
摘要
进入本世纪以来,我国通讯产品得到了飞速发展,其技术先进,价格便宜,深受世界各国和地区尤其是非洲国家的欢迎。某通讯公司在非洲的多个国家深耕多年,产品与服务遍布整个非洲大陆。为了更好地了解公司的销售情况,采用产品的销售额和利润数据,对其盈利能力进行分析和预测,给决策人员提供分析报告,以便为非洲各国提供更好的产品销售策略和服务。
针对任务一,首先对所给数据集进行缺失值、异常值、重复值等 方面的处理。其次通过python中的loc和groupby等函数,对表SalesData进行处理,获取产品在当地的销售数据,分析统计出各年度各国销售额和利润的同比增长率,以及各年度各服务分类的销售额和利润的同比增长列率,利用groupby函数对“地区”,“国家”,“服务分类”进行分组,统计出销售额和利润数据。针对表SalespersonData,首先计算出每个经理的总合同数,再通过各个经理的成交合同数求出各个经理的成交率。根据2017-2020年第一季度的各个地区,国家,服务分类的销售额和利润数据,给出明确的预测模型,预测出2021年第一季度销售额和利润数据。
针对任务二,首先对各个地区,国家,服务分类的产品销售额和利润等数据,以及销售经理的业绩数据进行同比,类比,相关性等分析或预测,发现趋势。绘制不同维度的图表,设计数字大屏,分析公司产品销售情况和盈利能力,并给出指导建议。
目录

正文
任务一:数据分析与预测
1.1.1 缺失值重复值处理和说明
针对数据缺失情况,本次分析将会采用以下的处理方式:针对数据为空值的情况,如果该特征数据缺失情况低于 10%,则结合该特征的重要性进行综合判断。如果字段重要性较低,则考虑直接删除,如果字段重要性较高,则进行插值法或者采用数据均值进行填补。
导入依赖,并设置中文显示:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
%matplotlib inline
font ={'family':'SimHei','weight':'bold','size':12}
matplotlib.rc("font",**font)
matplotlib.rcParams['axes.unicode_minus']=False
导入非洲通讯产品销售数据.xlsx数据并查看SalesData:
salesData = pd.read_excel("./非洲通讯产品销售数据.xlsx",engine='openpyxl', sheet_name ="SalesData")
salesData
输出为:
导入非洲通讯产品销售数据.xlsx数据并查看SalespersonData:
salespersonData = pd.read_excel("./非洲通讯产品销售数据.xlsx",engine='openpyxl', sheet_name ="SalespersonData")
salespersonData
输出为: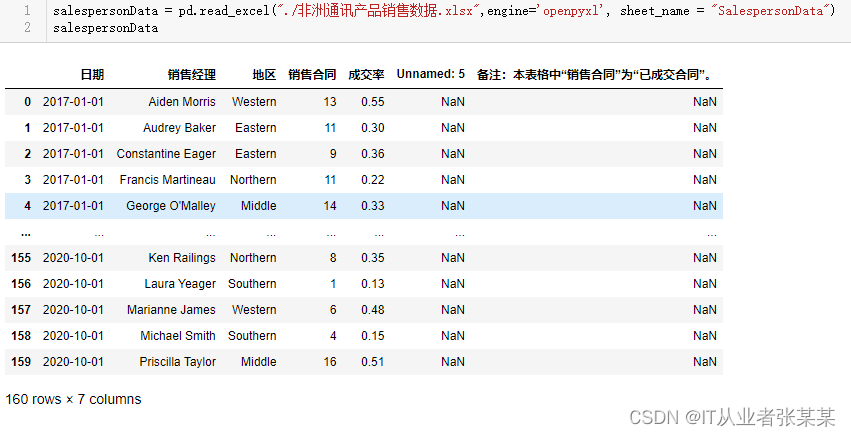
查看SalesData有无缺失值和重复值:
# 对第一张表进行处理
salesData.info()# 无缺失值
输出为:
<class'pandas.core.frame.DataFrame'>
RangeIndex:1056 entries,0 to 1055
Data columns (total 7 columns):# Column Non-Null Count Dtype ----------------------------0 日期 1056 non-null datetime64[ns]1 国家 1056 non-null object2 城市 1056 non-null object3 地区 1056 non-null object4 服务分类 1056 non-null object5 销售额 1056 non-null float64
6 利润 1056 non-null float64
dtypes: datetime64[ns](1), float64(2),object(4)
memory usage:57.9+ KB
查看有无重复值
salesData.duplicated().sum()
输出为:
0
查看salespersonData有无缺失值和重复值:
salespersonData.info()
输出为:
<class'pandas.core.frame.DataFrame'>
RangeIndex:160 entries,0 to 159
Data columns (total 7 columns):# Column Non-Null Count Dtype ----------------------------0 日期 160 non-null datetime64[ns]1 销售经理 160 non-null object2 地区 160 non-null object3 销售合同 160 non-null int64
4 成交率 160 non-null float64
5 Unnamed:50 non-null float64
6 备注:本表格中“销售合同”为“已成交合同”。 0 non-null float64
dtypes: datetime64[ns](1), float64(3), int64(1),object(2)
memory usage:8.9+ KB
查看重复值
salespersonData.duplicated().sum()
输出为:
0
发现表salesData和salespersonData无重复值
1.1.2 统计各年度各国销售额数据&计算同比增长率
因为统计的是各年度的销售额数据,所有需要对“日期”列进行拆分,取出年份:
# 先对日期列进行处理
year = salesData.loc[:,"日期"].astype("str").str.split("-", expand =True)[0]
year
输出为: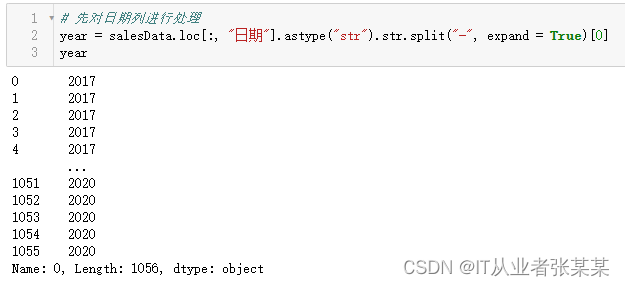
备注:上面代码中对时间数据进行处理,用时间类型会更好一些,所以转变成字符串的方式未必最佳
year_data = salesData.loc[:,["国家","地区","服务分类","销售额","利润"]]
year_data["年份"]= year
year_data
输出为: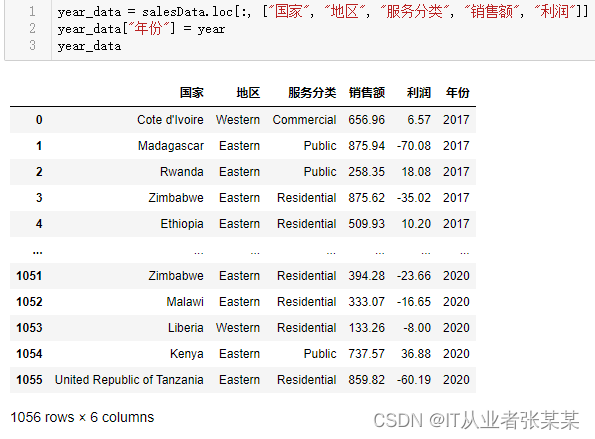
按照不同年份求各地区的销售额
# 按照不同年份求各地区的销售额
year_area_sale = year_data.groupby(["年份","地区"])["销售额"].sum()
year_area_sale.to_csv("./year_area_sale.csv")
year_area_sale
输出为:
通过groupby函数对[“年份”, “国家"]进行分组,对”销售额“进行求和
year_cou_sale = year_data.groupby(["年份","国家"])["销售额"].sum()
year_cou_sale.to_csv("./year_cou_sale.csv")
year_cou_sale
输出为:
计算出各年度各国销售额数据的同比增长率
同比增长率
=
(
今年销售额
−
去年销售额
)
/
去年销售额
同比增长率=(今年销售额-去年销售额)/去年销售额
同比增长率=(今年销售额−去年销售额)/去年销售额
# 各年度各国的销售额的同比增长率
task1 = pd.read_csv("./year_cou_sale.csv")
task1
输出为: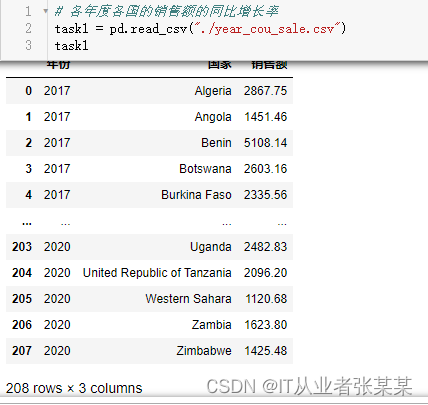
计算同比增长率
temp = pd.merge(task1[task1.loc[:,"年份"]==2017], task1[task1.loc[:,"年份"]==2018], how="inner", left_on ="国家", right_on ="国家")
temp = pd.merge(temp, task1[task1.loc[:,"年份"]==2019],how="inner", left_on ="国家", right_on ="国家")
temp = pd.merge(temp, task1[task1.loc[:,"年份"]==2020],how="inner", left_on ="国家", right_on ="国家")
temp.drop(["年份_x","年份_y"], axis =1, inplace=True)
temp.columns =["国家","2017销售额","2018销售额","2019销售额","2020销售额"]
temp
temp["2017-2018销售额同比增长率"]=(temp["2018销售额"]- temp["2017销售额"])/ temp["2017销售额"]
temp["2018-2019销售额同比增长率"]=(temp["2019销售额"]- temp["2018销售额"])/ temp["2018销售额"]
temp["2019-2020销售额同比增长率"]=(temp["2020销售额"]- temp["2019销售额"])/ temp["2019销售额"]
temp
temp.to_csv("./各年份各国家的销售额同比增长率.csv")
temp
输出为: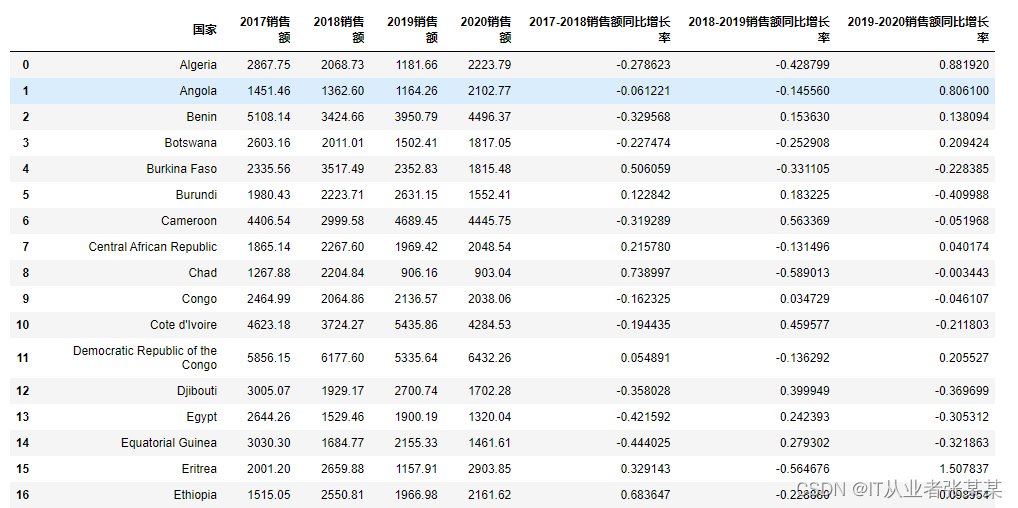
共51个国家
1.1.3显示2020年度销售额Top3的国家及其年增长率
通过sort_values函数对”2020销售额“数据进行降序排序,取出Top3
# 展示2020年年度销售额前3名的国家及其年增长率
temp.loc[:,["国家","2020销售额","2019-2020销售额同比增长率"]].sort_values("2020销售额", ascending =False).head(3)
输出为: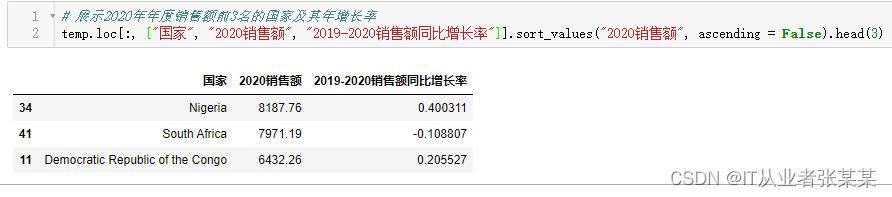
1.1.4 统计各年度各国利润数据&计算同比增长率
通过groupby函数对[“年份”, “国家"]进行分组,对”利润“进行求和
year_cou_pro = year_data.groupby(["年份","国家"])["利润"].sum()
year_cou_pro.to_csv("./year_cou_pro.csv")
year_cou_pro
输出为:
task2 = pd.read_csv("./year_cou_pro.csv")
task2
输出为: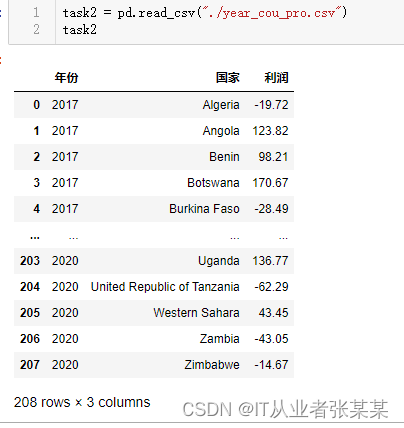
计算出各年度各国利润数据的同比增长率
temp2 = pd.merge(task2[task2.loc[:,"年份"]==2017], task2[task2.loc[:,"年份"]==2018], how="inner", left_on ="国家", right_on ="国家")
temp2 = pd.merge(temp2, task2[task2.loc[:,"年份"]==2019],how="inner", left_on ="国家", right_on ="国家")
temp2 = pd.merge(temp2, task2[task2.loc[:,"年份"]==2020],how="inner", left_on ="国家", right_on ="国家")
temp2.drop(["年份_x","年份_y"], axis =1, inplace=True)
temp2.columns =["国家","2017利润","2018利润","2019利润","2020利润"]# temp2
temp2["2017-2018利润同比增长率"]=(temp2["2018利润"]- temp2["2017利润"])/ temp2["2017利润"]
temp2["2018-2019利润同比增长率"]=(temp2["2019利润"]- temp2["2018利润"])/ temp2["2018利润"]
temp2["2019-2020利润同比增长率"]=(temp2["2020利润"]- temp2["2019利润"])/ temp2["2019利润"]
temp2.to_csv("./各年份各国家的利润同比增长率.csv")
temp2
输出为: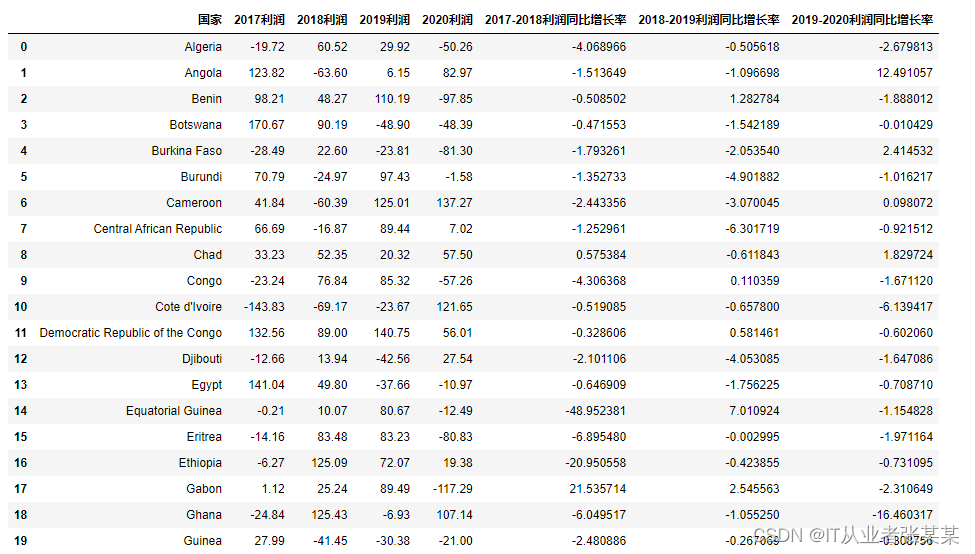
1.1.5统计各年度各服务分类销售额数据&计算同比增长率
通过groupby函数对[“年份”, “服务分类"]进行分组,对”销售额“进行求和
year_sor_sale = year_data.groupby(["年份","服务分类"])["销售额"].sum()
year_sor_sale.to_csv("./year_sor_sale.csv")
year_sor_sale
输出为:
task3 = pd.read_csv("./year_sor_sale.csv")
task3
输出为:
计算出各年度各服务分类销售额数据的同比增长率
temp3 = pd.merge(task3[task3.loc[:,"年份"]==2017], task3[task3.loc[:,"年份"]==2018], how="inner", left_on ="服务分类", right_on ="服务分类")
temp3 = pd.merge(temp3, task3[task3.loc[:,"年份"]==2019],how="inner", left_on ="服务分类", right_on ="服务分类")
temp3 = pd.merge(temp3, task3[task3.loc[:,"年份"]==2020],how="inner", left_on ="服务分类", right_on ="服务分类")
temp3.drop(["年份_x","年份_y"], axis =1, inplace=True)
temp3.columns =["服务分类","2017销售额","2018销售额","2019销售额","2020销售额"]
temp3["2017-2018销售额同比增长率"]=(temp3["2018销售额"]- temp3["2017销售额"])/ temp3["2017销售额"]
temp3["2018-2019销售额同比增长率"]=(temp3["2019销售额"]- temp3["2018销售额"])/ temp3["2018销售额"]
temp3["2019-2020销售额同比增长率"]=(temp3["2020销售额"]- temp3["2019销售额"])/ temp3["2019销售额"]
temp3.to_csv("./各年份各服务分类的销售额同比增长率.csv")
temp3
输出为:
1.1.6统计各年度各服务分类利润数据&计算同比增长率
通过groupby函数对[“年份”, “服务分类"]进行分组,对”利润“进行求和
year_sor_pro = year_data.groupby(["年份","服务分类"])["利润"].sum()
year_sor_pro.to_csv("./year_sor_pro.csv")
year_sor_pro
输出为:
加载数据:
task4 = pd.read_csv("./year_sor_pro.csv")
task4
输出为: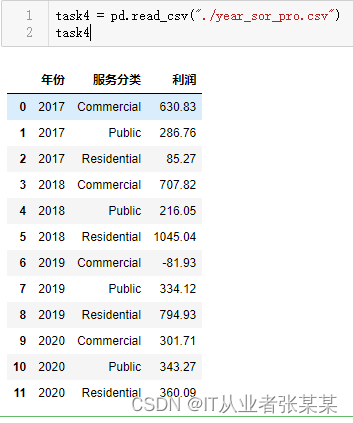
计算出各年度各服务分类销售额数据的同比增长率
temp4 = pd.merge(task4[task4.loc[:,"年份"]==2017], task4[task4.loc[:,"年份"]==2018], how="inner", left_on ="服务分类", right_on ="服务分类")
temp4 = pd.merge(temp4, task4[task4.loc[:,"年份"]==2019],how="inner", left_on ="服务分类", right_on ="服务分类")
temp4 = pd.merge(temp4, task4[task4.loc[:,"年份"]==2020],how="inner", left_on ="服务分类", right_on ="服务分类")
temp4.drop(["年份_x","年份_y"], axis =1, inplace=True)
temp4.columns =["服务分类","2017利润","2018利润","2019利润","2020利润"]
temp4["2017-2018利润同比增长率"]=(temp2["2018利润"]- temp2["2017利润"])/ temp2["2017利润"]
temp4["2018-2019利润同比增长率"]=(temp2["2019利润"]- temp2["2018利润"])/ temp2["2018利润"]
temp4["2019-2020利润同比增长率"]=(temp2["2020利润"]- temp2["2019利润"])/ temp2["2019利润"]
temp4.to_csv("./各年份各服务分类的利润同比增长率.csv")
temp4
输出为:
1.2.1统计各地区,国家有关服务分类销售额和利润数据
job2 = salesData.loc[:,["国家","地区","服务分类","销售额","利润"]]
job2
输出为:
通过groupby函数对[“地区”, “国家”, “服务分类”]进行分组,分别求出"销售额"和”利润“的总和
a = job2.groupby(["地区","国家","服务分类"])["销售额"].sum()
a
输出为: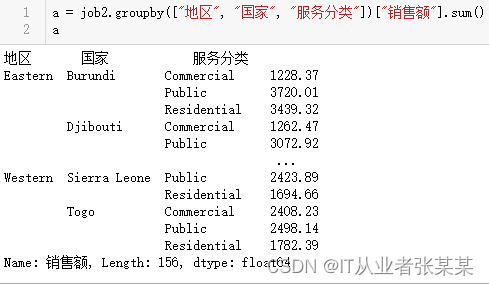
b = job2.groupby(["地区","国家","服务分类"])["利润"].sum()
b
输出为: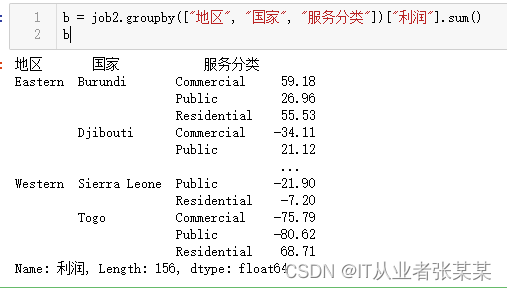
1.2.2展示各地区有关服务分类利润数据
合并销售额和利润
a = pd.DataFrame(a)
b = pd.DataFrame(b)
a["利润"]= b["利润"].values
a.to_csv("./各地区各国家有关服务分类销售额和利润数据.csv")
a
输出为: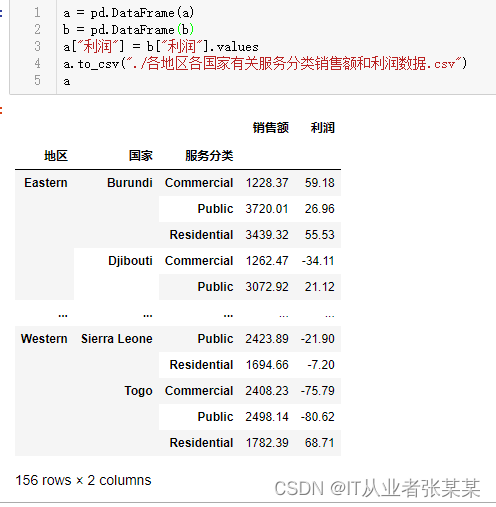
1.3.1统计各个销售经理的成交合同数和成交率
salespersonData
输出为:
通过对列”销售经理“进行分组,求出”销售合同“的总和
set(salespersonData.loc[:,"销售经理"].values)
输出为:
total_sus = salespersonData.groupby(["销售经理"])["销售合同"].sum()
total_sus
输出为:
因为“销售合同”为“已成交合同”。我们可以通过销售经理在某地区某日期的成就率,求出该时销售经理的总销售合同即以成交的合同和非成交的合同,再通过成交合同比上总合同数求出该经理的成交率:
job3 = salespersonData.loc[:,["销售经理","销售合同","成交率"]]
job3
输出为: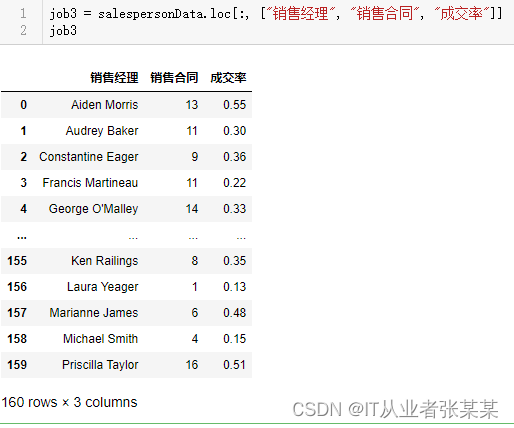
job3["合同数"]= job3["销售合同"]/ job3["成交率"]
job3["合同数"]= job3["合同数"].astype("int")
job3
输出为:
total = job3.groupby(["销售经理"])["合同数"].sum()
total
输出为: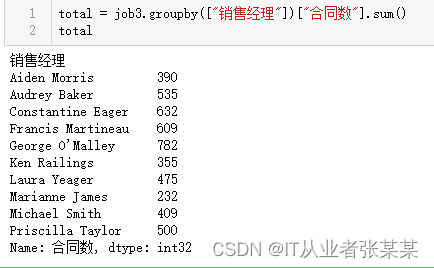
man_rate = pd.concat([total, total_sus], axis =1)
man_rate
输出为:
man_rate["成交率"]= man_rate["销售合同"]/ man_rate["合同数"]
man_rate
输出为:
1.3.2展示销售经理成交合同数Top3的数据
通过sort_values函数对列"销售合同"进行排序
man_rate.sort_values("销售合同", ascending =False).head(3)
输出为: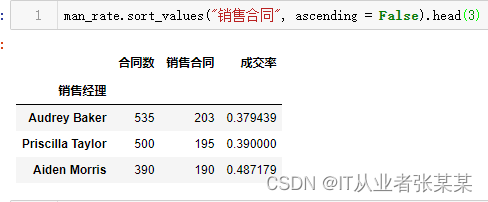
man_rate.to_csv("./各经理的成交率.csv")
man_rate
输出为: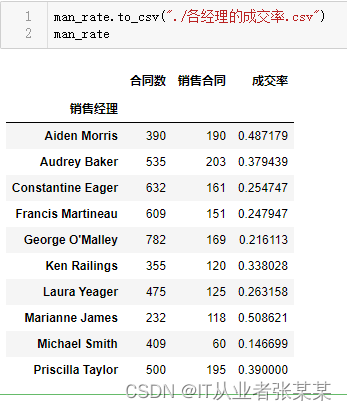
1.4.1对数据进行预处理及编码, 给出明确的预测模型
对列”日期“进行处理,计算出该日期属于第几季度
# 获取年份列
year = salesData.loc[:,"日期"].astype("str").str.split("-", expand =True)[0]
year
输出为:
# 获取月份
month = salesData.loc[:,"日期"].astype("str").str.split("-", expand =True)[1]
month
输出为:
获得季度
quarter =[]for i inlist(month.values):
q =(int(i)-1)//3+1
quarter.append(q)" ".join([str(i)for i in quarter])
输出为:
year_quarter = salesData.loc[:,["地区","国家","服务分类","销售额","利润"]]
year_quarter["年度"]= year
year_quarter["季度"]= quarter
year_quarter
输出为: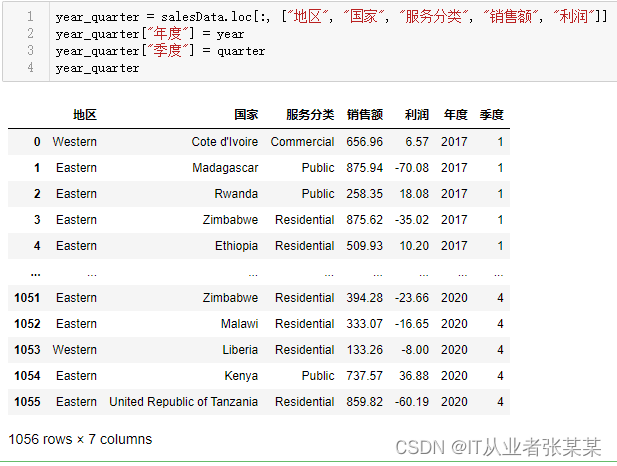
通过对[“年度”, “季度”, “地区”, “国家”, “服务分类”]进行分组,求出”销售额"和”利润“总值
sale = year_quarter.groupby(["年度","季度","地区","国家","服务分类"])["销售额"].sum()
sale = pd.DataFrame(sale)
sale
输出为:
profit = year_quarter.groupby(["年度","季度","地区","国家","服务分类"])["利润"].sum()
profit = pd.DataFrame(profit)
profit
输出为:
# 拼接销售额与利润
sale["利润"]= profit["利润"].values
sale.to_csv("./第一题.csv")
sale
输出为: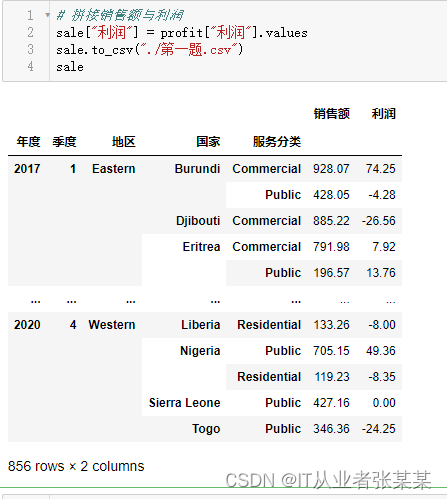
# 查看保存的数据
n1 = pd.read_csv("./第一题.csv")
n1
输出为:
获取第一季度数据
forecast_data = n1[n1.loc[:,"季度"]==1]# 拿出第一季度
forecast_data
输出为: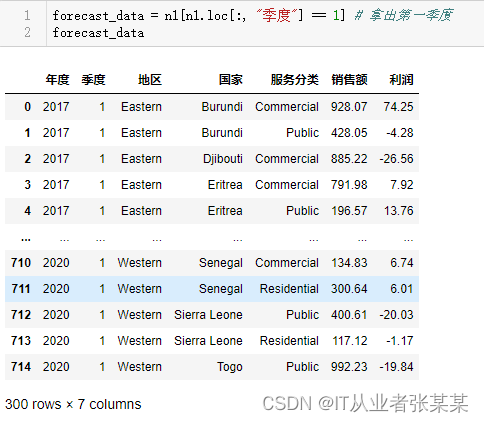
因为列”地区“,”国家“,”服务分类"中存在汉字,而逻辑回归只能够处理数值型数据,不能处理文字,在sklearn当中,除了专用来处理文字的算法,其他算法在fit的时候全部要求输入数组或矩阵,也不能够导入文字型数据(其实手写决策树和普斯贝叶斯可以处理文字,但是sklearn中规定必须导入数值型)。然而在现实中,许多标签和特征在数据收集完毕的时候,都不是以数字来表现的。比如说,学历的取值可以是[“小 学”,“初中”,“高中”,“大学”],付费方式可能包含[“支付宝”,“现金”,“微信”]等等。在这种情况下,为了让数据适应算法和库,我们必须将数据进行编码,即是说,将文字型数据转换为数值型。
这里我们采用preprocessing.LabelEncoder将汉字进行编码
# 对列地区,国家,服务分类 进行编码from sklearn.preprocessing import LabelEncoder
y1 = forecast_data.loc[:,"地区"]# 要输入的是标签,不是特征矩阵,所以允许一维数据
y2 = forecast_data.loc[:,"国家"]
y3 = forecast_data.loc[:,"服务分类"]
le1 = LabelEncoder()# 实例化
le1 = le1.fit(y1)# 导入数据
label1 = le1.transform(y1)# transform接口调取结果
forecast_data.loc[:,"地区"]= label1
le2 = LabelEncoder()# 实例化
le2 = le2.fit(y2)# 导入数据
label2 = le2.transform(y2)# transform接口调取结果
forecast_data.loc[:,"国家"]= label2
le3 = LabelEncoder()# 实例化
le3 = le3.fit(y3)# 导入数据
label3 = le3.transform(y3)# transform接口调取结果
forecast_data.loc[:,"服务分类"]= label3
forecast_data
输出为:
备注:这里的警告问题可以参考博客https://blog.csdn.net/weixin_42575020/article/details/98846427
from sklearn.linear_model import LogisticRegression as LR # 逻辑回归from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score # 精确性分数
X1 = forecast_data.loc[:,["年度","地区","国家","服务分类","利润"]]
X1
X2 = forecast_data.loc[:,["年度","地区","国家","服务分类","销售额"]]
X2
输出为:
建模
正则化是用来防止模型过拟合的过程,常用的有L1正则化和L2正则化两种选项penalty:可以输入”l1“或者”l2“来指定使用哪一种正则化方式,不填写默认使用”l2“,注意:若选择”l1“正则化,参数solver仅能够使用的求解方式”liblinear“和”sage“
C:C正则化强度的倒数,必须是一个大于0的浮点数,不填写默认是1.0,即默认正则化与损失函数的比值是1:1,C越小,损失函数会越小,模型对损失函数的惩罚越重,正则化的效果越强,参数θ会逐渐被压缩得越来越小。
L1正则化和L2正则化虽然都可以控制过拟合,但它们的效果并不相同。当正则化强度逐渐增大(即C逐渐变小),参数θ 的取值会逐渐变小,但L1正则化会将参数压缩为0,L2正则化只会让参数尽量小,不会取到0。
y = forecast_data.loc[:,"销售额"]
y2 = forecast_data.loc[:,"利润"]
lrl1 = LR(penalty ="l1", solver ="liblinear", C =0.5, max_iter =1000)
lrl2 = LR(penalty ="l1", solver ="liblinear", C =0.5, max_iter =1000)# 逻辑回归的重要属性coef_, 查看某个特征所对应的参数
lrl1 = lrl1.fit(X1, y.astype("int"))
lrl2 = lrl2.fit(X2, y2.astype("int"))
1.4.2预测2021年第一季度各个地区,国家,服务分类的销售额和利润
通过模型预测2021年第一季度各个地区,国家,服务分类的销售额和利润
X_test1 = X1
X_test1["年度"]=[2021for i inrange(X1.shape[0])]
X_test1
输出为:
X_test2 = X2
X_test2
输出为:
查看预测结果:
lrl_pro1 = lrl1.predict(X_test1)
lrl_pro1[0:5]
输出为:
lrl_pro2 = lrl2.predict(X_test2)
lrl_pro2[0:5]
输出为:
X_test = X_test1.loc[:,["年度","地区","国家","服务分类"]]
X_test
输出为:
X_test["预测销售额"]= lrl_pro1
X_test["预测利润"]= lrl_pro2
X_test
输出为:
X_test["地区"]= le1.inverse_transform(label1)
X_test["国家"]= le2.inverse_transform(label2)
X_test["服务分类"]= le3.inverse_transform(label3)
X_test
输出为: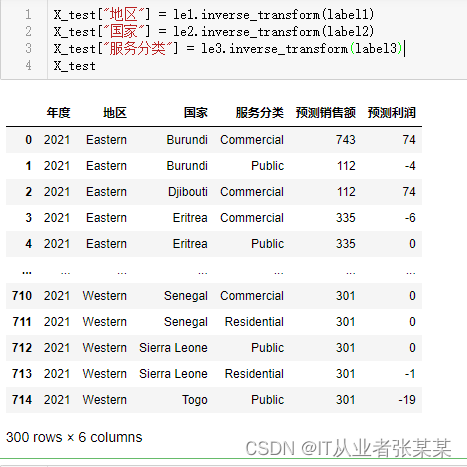
X_test.drop_duplicates(inplace=True)
X_test.index =range(X_test.shape[0])
X_test
输出为:
1.4.3展示地区,国家,服务分类销售额预测的最大值
X_test.to_csv("./2021年第一季度预测.csv")
X_test.sort_values("预测销售额", ascending =False).head(1)
输出为:
任务2:可视化展示及分析
2.1.1绘制非洲各国产品销售地图
利用Tableau绘制非洲各国产品销售地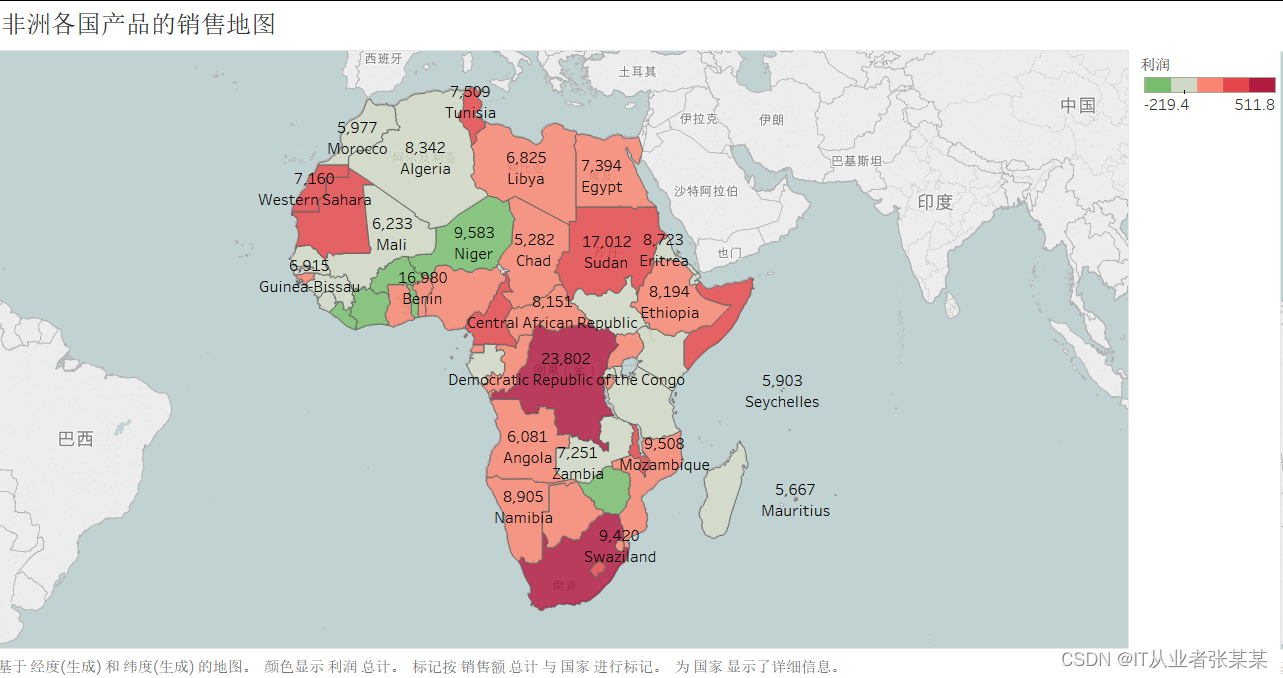
由绘制出的非洲各国产品销售地图可知,Neiger、BurkinaFaso、Zimbia等几个国家的利润严重亏损、没有盈利能力而处于非洲中部的一些国家如Congo、Centra以及南非的Swailand等国家有高额利润。
2.1.2绘制非洲各国产品销售额和利润数据图表

其中颜色深浅表示利润,发现国家South Africa的销售额和利润都显著高于其他,而Coted’lvoire的销售额排第四,但是却处于严重的亏损状态,建议降低成本、费用,下移保本点,指定目标战略、政策规划,降低固定工资部分,加大弹性工资部分,提提升人效。
2.2.1绘制各服务分类的销售额和利润的年增长率
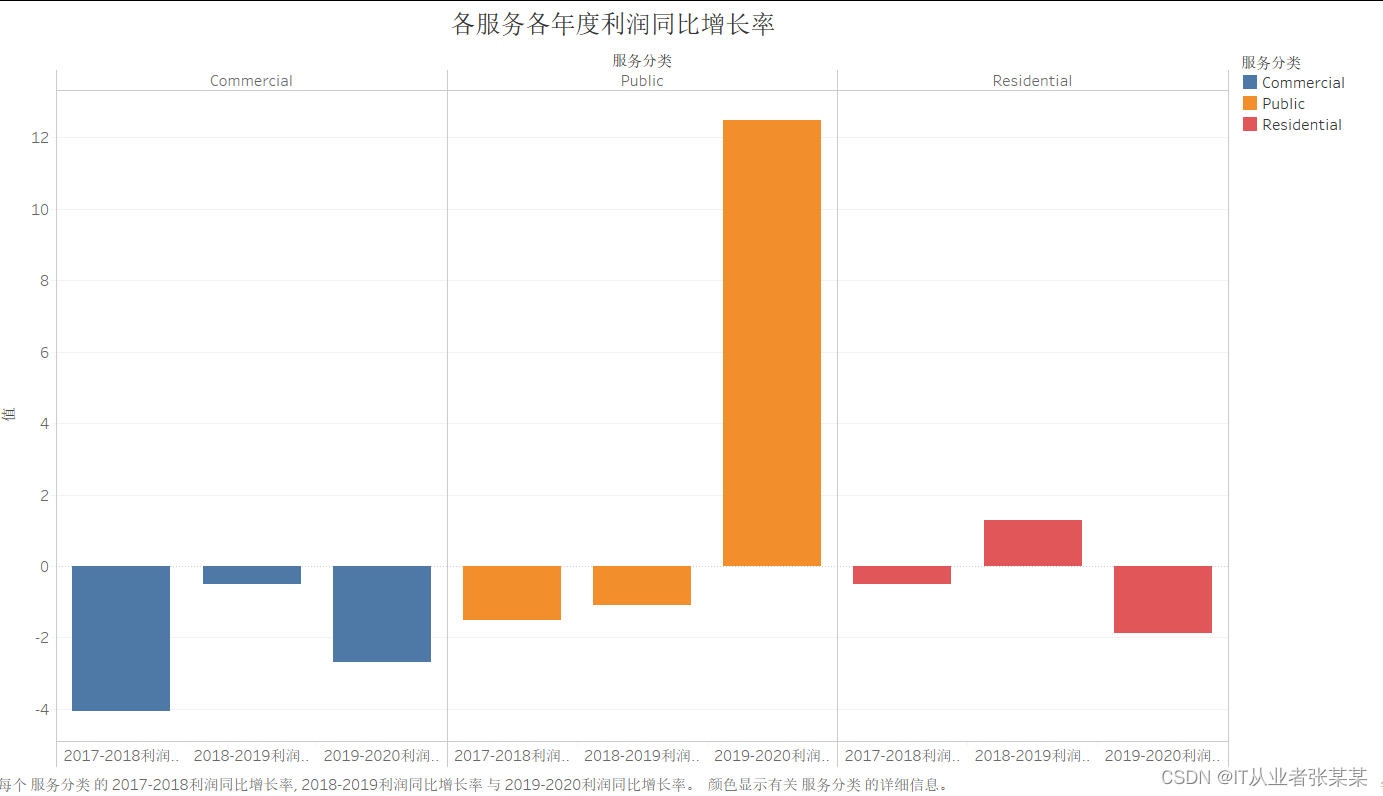
其中Commercial服务,三年来利润持续下降,而Public在2019-2020年度显著提升。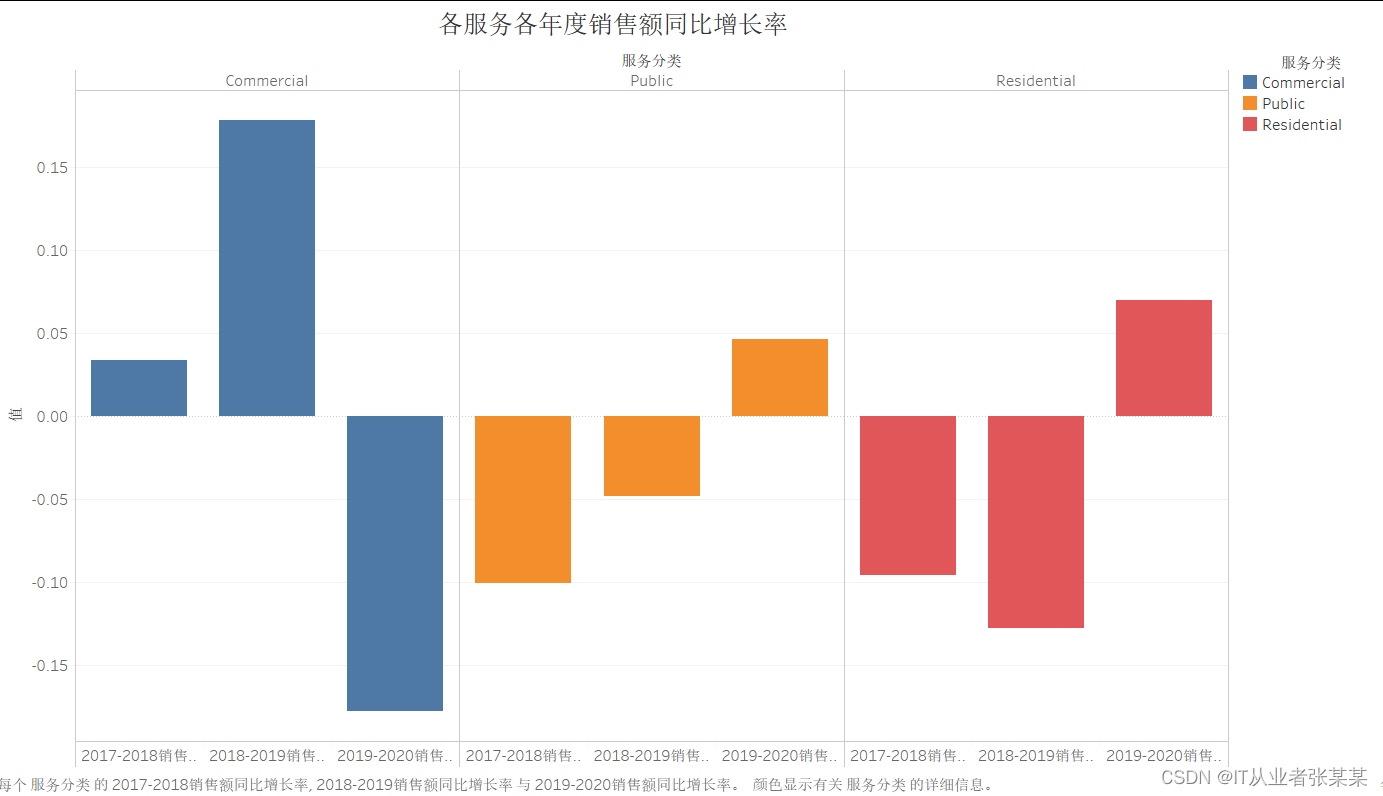
其中Public在2019-2020年度销售额有明显提升,与该年度的利润增长相符合
2.2.2绘制各服务分类的销售额和利润的季度增长率
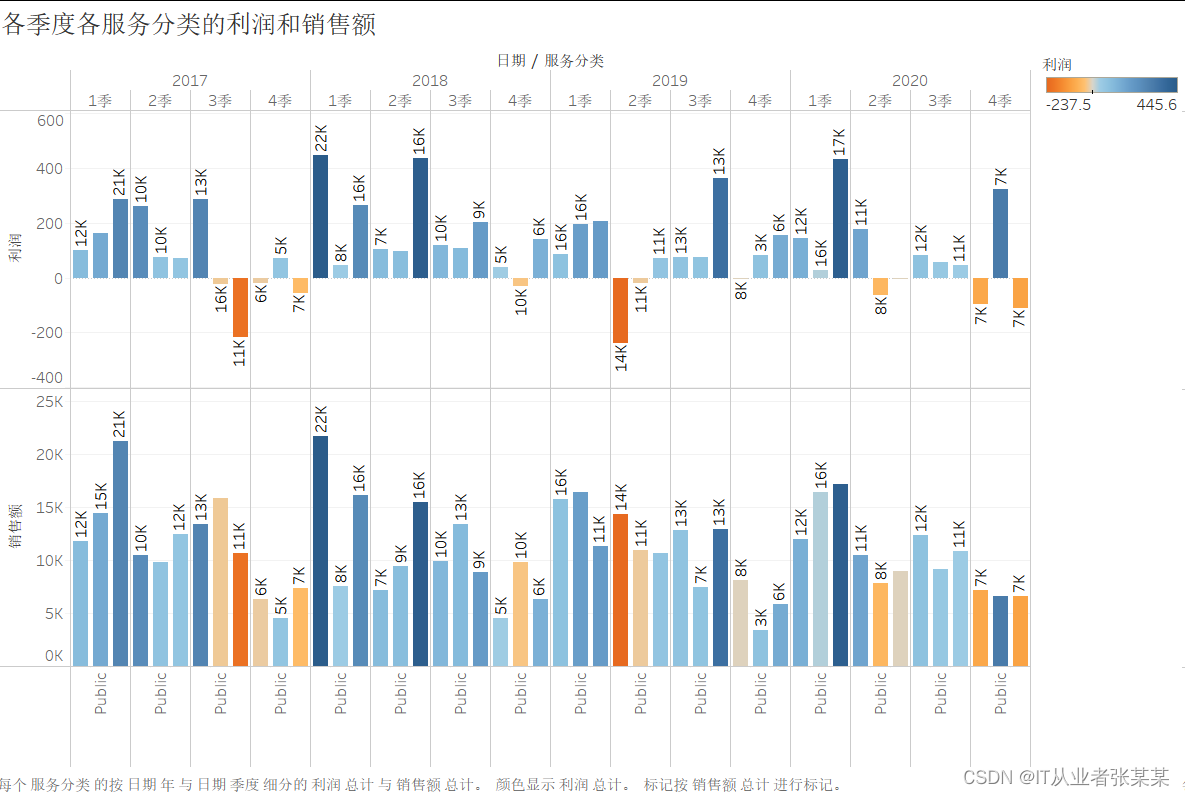
2.3绘制2021年第一季度各服务分类的销售额和利润预测值的图标

2.4绘制销售经理销售合同数Top5

2.5绘制国家销售额后10名

2.6.1设计数字大屏
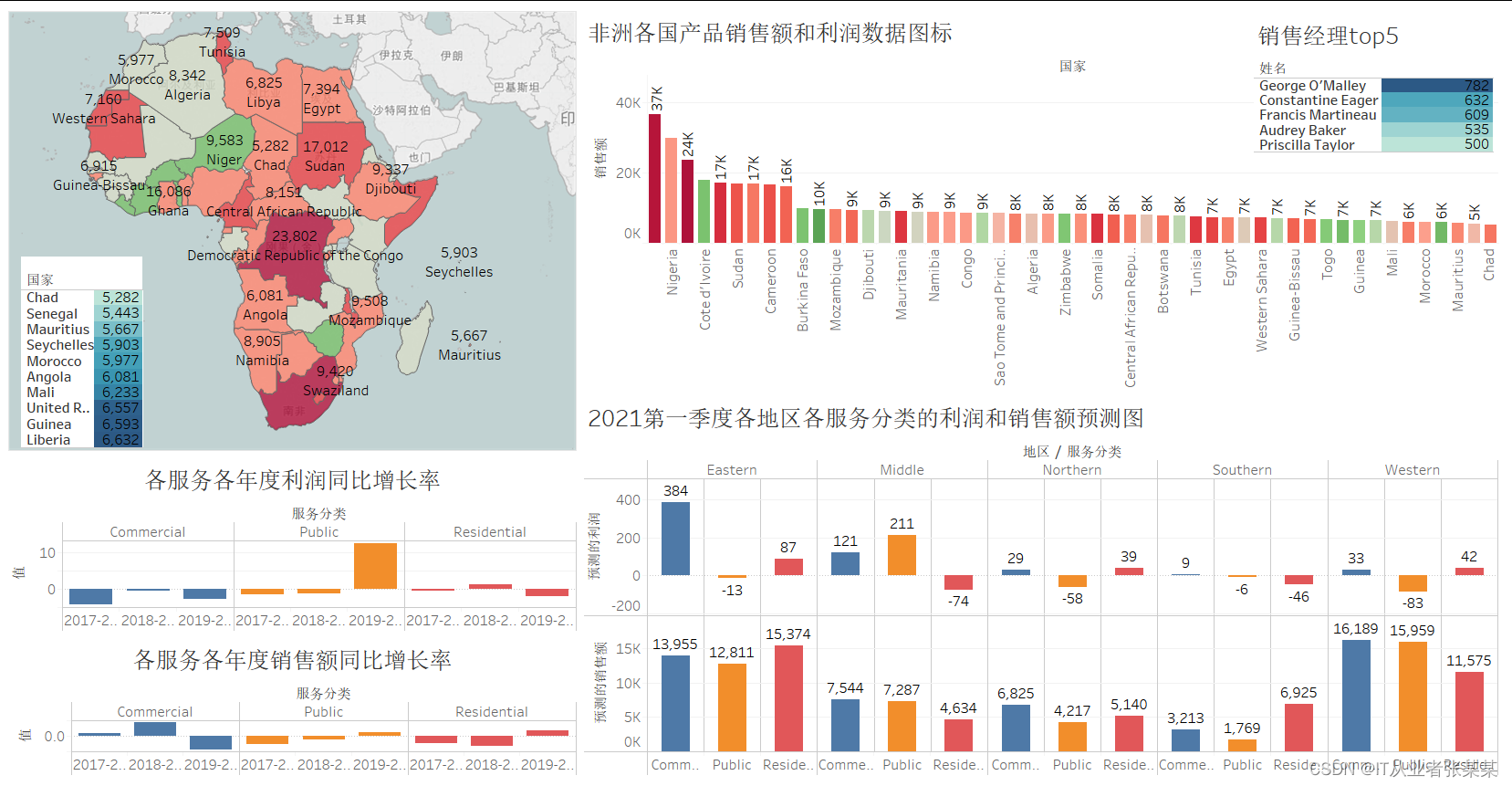
2.6.1分析公司产品销售情况和盈利能力,并给出指导建议
对企业来说,从事经营活动最大的目的就是赚取利润并维持企业不断地发展。因此对盈利能力的分析就显得尤为重要,要想获取利润,持续稳定的经营与发展是基础,而获取利润优势是企业持续发展的保证。从盈利的角度来看,应着重对那些低销售额高利润的地区加大产品推广,对那些高销售额负利润的地区,应调整经营思路,提高企业收益水平。
从不同地区收益情况以及年份季度分析出,对于服务类型说,Commercial类型的服务需求量逐年放缓,说明该类型的服务已达到饱和,应着重于产品的售后服务,适量减少该类型的生产量。充分利用媒体设备,将产品需求量较少的产品广播宣传,调查当地用户习惯,有针对性的改良不同类型的产品在该地区的适应性。在非洲东部地区有高销售额和高收益,其他地区应该多向该地区学习。控制成本,实现利润最大化,使企业在竞争中立于不败之地。
版权归原作者 IT从业者张某某 所有, 如有侵权,请联系我们删除。