
增删查改进阶版
数据库的约束
数据库的约束就是数据库在使用的时候,对于里面的数据能够提出要求和限制。可以借助约束来完成更好的体验。这里的约束都是针对列来操作的。
NOT NULL 约束
NOT NULL 就是某列不能插入空值。如果插入空值,就会报错。代码如下:
createtable student (id intnotnull, name varchar(20)notnull);
这里就是 id 和 name 都不能为 null 。不然就会报错。
UNIQUE 约束
UNIQUE 约束就是保证每行必须有唯一的值,插入重复的值,就会报错。代码如下:
createtable student (id intunique, name varchar(20));
这里创建的表,学生 id 是不能一样的,不然就会报错。运行结果如下: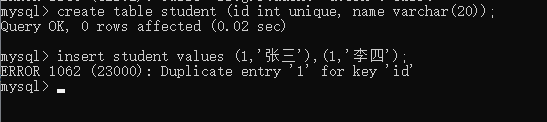
而且这里报错的话,一条数据都插入不进去。将 id 变得不一样的时候,就可以插入了。代码如下:
insert student values(1,'张三'),(2,'李四');
运行结果如下:
DEFAULT 约束
DEFAULT 就是在没有给列赋值的时候约定一个默认值。代码如下:
createtable student(id int, name varchar(20)default'匿名');
这里就是,如果没有给 name 赋值的时候,就使用默认值 ‘匿名’。代码如下:
insertinto student(id)values(1);
运行结果如下:
PRIMARY KEY 主键约束
PRIMARY KEY 主键约束,相当于数据的唯一身份标识,类似于身份证。是日常开发当作最常使用的约束!!! 最重要的约束。 创建表的时候,很多时候都需要指定主键。对于一个表来说,只能有一个列被列为主键。 设为主键之后,不能为 null 不能重复。代码如下:
createtable student (id intprimarykey, name varchar(20));
主键自增
主键典型的用法就是直接使用 1,2,3,4 整数递增的方式来表示,在设置好自增主键之后,此时插入记录,就可以不指定自增主键的值了(直接使用 null),交给 MySQL 自行分配即可。每次新增一个新的记录,都会产生一个自增的 id。代码如下:
createtable student (id intprimarykeyauto_increment, name varchar(20));
然后插入记录:
insertinto student values(null,'张三');insertinto student values(null,'李四');
运行结果如下:
如果在 自增主键 当中输入一个 id 之后,那么原来自增的 id 到输入的 id 之间的值就不能用了。代码如下:
insertinto student values(6,'王五');insertinto student values(null,'赵六');
运行结果如下:
FOREIGN KEY 约束
FOREIGN KEY 是描述两个表之间的关联关系,表1 里的数据,必须在 表2 中存在。
高阶查询
聚合查询是数据库查询当中经常用到的查询方法。就是把多行之间的数据,给进行聚合了,把多个行的数据进行了关联。MySQL 提供了内置的聚合函数,可以直接来使用,在使用的时候加一个 distinct 达到去重效果。我们使用已有的表 exam_result 来测试:
数据库设计
设计数据库的时候,设计表的时候,有两个步骤:先找实体,然后再找实体之间的关系。实体:关键性名词。
实体间的关系:
- 一对一的关系
- 一对多的关系
- 多对多的关系
- 不存在关系
一对一关系
以教务系统为例,student:包含了学生的 姓名,id,班级。user:包含了 用户的账户,密码等。所以就是:一个账户对应一个学生,一个学生对应一个账户。
数据库当中表示一对一的关联关系
方法一:把两个实体用一张表来表示。
方法二:用两张表来表示,其中一张表包含了另一个表的 id。比如说在学生表当中加入 uesrId 用户表当中加入 studentId。
一对多关系
以教务系统为例。student:包含了学生的 id,姓名,班级。user:用户的账户,密码。一个学生应该处于一个班级中,一个班级可以包含多个学生。
数据库当中表示一对多关系
方法一:在班级表中,新增一例,表示这个班级里的学生 id 都有啥。
- student 表(学号,姓名) class 表(班级编号,班级名称,学生列表)。
- 班级编号 1 :计算机一班,计算机二班 学生列表:1,2,3,4,5
- 班级编号 2 :计算机三班,计算机四班 学生列表:6,7,8,9,10
方法二:班级表不变,在学生表当中,新增一列:classId
- class 表(班级编号,班级名称)
- student 表(学号,学生姓名,所在班级) 通过这种方式也能知道一个学生对应到哪个班级
对于 MySQL 来说,表示一对多的时候,只能采用 方案二,因为 MySQL 不支持方案一这样的类型。一个列既可以当主键,也可以当外键。
多对多的关系
就像 student:学号,班级。课程表:课程编号,课程名字.学生和课程就是多对多的关系。一个学生可以选多门课,一门课可以包含多个学生。M 个学生,可以选 N 门课。多对多关系:在数据库设计的时候,只有一个方法:使用一个关联表,来表示两个实体之间的关系
- 学生表(学号,姓名):1 张三,2 李四,3 王五 课程表(编号,名称):1 语文,2 数学,3 英语。
- 创建一个关联表:学生-课程表(学号,课程编号)
- 假设是 1,1 意思就是:学号为 1 的学生,选了课程编号为 1 的课程。就是:张三选了语文课
将一个表的数据插入到另外一个表
先创建一个表,并且插入数据:
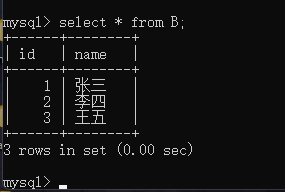
createtable A (id int,name varchar(50));insertinto A values(1,'张三'),(2,'李四'),(3,'王五');
再创建另外一个表:
createtable B (id int, name varchar(50));
把 A 的数据插入到 B 当中:先执行查找,然后针对查到的结果都插入 B 当中,要保证从 A 当中查到的数据类型和 B 当中的数据类型一样。
insertinto B select*from A;
 当然 B 也可以这样创建:
当然 B 也可以这样创建:
createtable B (name varchar(50), id int);
这样的话,再插入的时候就是这样的语句,先找出 name,然后再找出 id 进行插入就好了。
insertinto B select name, id from A;
聚合查询
把多行之间的数据,给进行聚合了,把多个行的数据进行了关联。MySQL 提供了内置的聚合函数,可以直接来使用,在使用的时候加一个 distinct 达到去重效果。
count
count 就是计算行的值,不算 null,这里查询的是有多少行:
selectcount(*)from exam_result;
运行结果如下: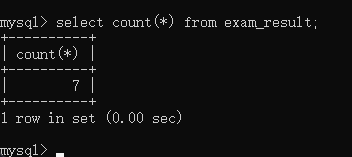
查询语文成绩有多少行:
selectcount(chinese)from exam_result;
运行结果如下: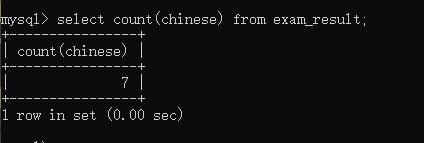
sum
把这一列的若干行相加 也不算 null 只能针对数字进行运算,不能对字符串进行运算。这里查询语文成绩的总和,代码如下:
selectsum(chinese)from exam_result;
运行结果如下: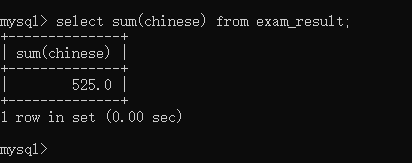
当然,sum 也可以表达式相加:
selectsum(chinese+english)from exam_result;
这里求的就是语文和英语的总成绩: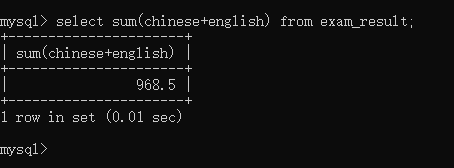
聚合函数搭配条件
聚合函数是可以搭配 where 来使用的。就是先执行筛选,后执行求和:
selectsum(english)from exam_result where english >70;
这里求的就是英语 > 70 的和,运行结果如下: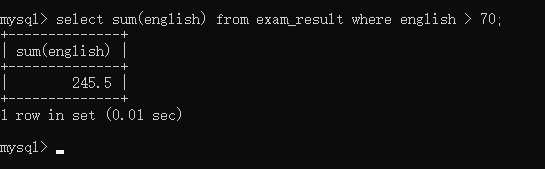
group by
group by 就是先分组,然后在针对每个组来使用聚合函数。先创建一个表,然后插入数据:
createtable emp(
id intprimarykeyauto_increment,
name varchar(20)notnull,
role varchar(20)notnull,
salary numeric(11,2));insertinto emp(name, role, salary)values('A','服务员',1000.20),('B','游戏陪玩',2000.99),('C','游戏角色',999.11),('D','游戏角色',333.5),('E','游戏角色',700.33),('F','董事长',12000.66);
表中结果如下:
通过 group by 分组,这里来查询不同角色对应的 sum,min,avg 的值。代码如下:
select role,max(salary),min(salary),avg(salary)from emp groupby role;
运行结果如下: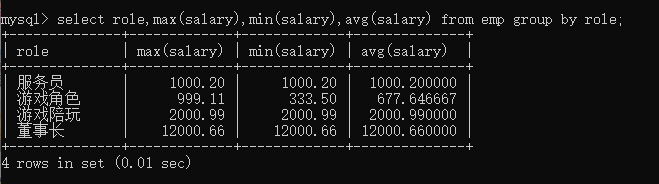
当然,在查询的时候,也可以给对应的列起别名:
select role,max(salary)as max,min(salary)as min,avg(salary)as avg from emp groupby role;
运行结果如下: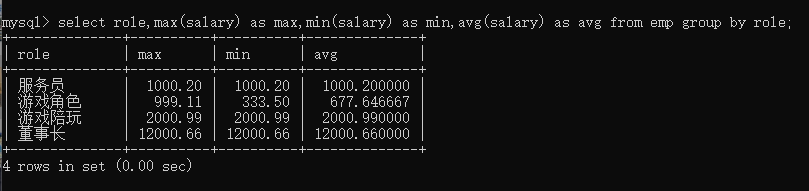
group by 搭配 where 和 having 来使用
where:对分组前的数据进行操作。例如:求平均工资的时候,去掉 E 求的结果就不包含 E 的数据了,代码如下:
select role,avg(salary)from emp where name !='E'groupby role;
对比结果如下:
having:对分组之后的数据进行操作。例如:求平均工资,然后再筛选。代码如下:
select role,avg(salary)from emp groupby role havingavg(salary <10000);
这里的意思就是先求到平均工资,然后再筛选出平均工资小于 10000 的。运行结果如下:
上面的部分就是筛选出来的,平均工资小于 10000 的。
版权归原作者 Lockey-s 所有, 如有侵权,请联系我们删除。