
一、为什么需要分库分表
生产环境中,随着业务数据量的不断增长,尤其是核心业务数据库和表的数据量达到一定量级的时候,查询性能的瓶颈就会暴露出来,不管是mysql还是其他数据库。如果不对数据库或表进行分库分表,通常可以引入其他的存储,比如es,mongodb,数据量较小的情况下,甚至可以考虑redis等。
在行业规约中,通常来说,单表数据量达到500万时就需要考虑进行分库分表了,当然,提升查询性能的方案,分库分表不是必须的,但是如果系统架构本身不是很复杂的话,与其引入一门新的存储介质,分库分表不失为一种相对简单且容易操作的方案。
1.1 分库分表的优势
理论上讲,分库分表主要用于解决查询的性能问题,使用分库分表之后,可以带来如下好处:
- 分表之后,单表数据量降低,查询性能有一定提升;
- 分表之后,可以合理的对冷热数据进行区分和处理;
- 分表之后,可以使得关键业务字段在数据存储上结构更合理;
- 分库之后,可以充分利用多机器的资源,降低单库的读写性能瓶颈;
- 分库之后,更容易在微服务架构层面进行数据层面的管理,符合微服务总体设计理念;
二、分库分表基本概念
不少同学知道分库分表这个概念,但是在实操的时候却容易混淆,究其原因还是对分库分表的概念没有弄清楚,下面对常用的几种分库分表概念做简单的总结;
2.1 垂直分表
垂直可以形象的理解为从中切开,即宽表拆分多个表,一个30个字段的表拆成2个表,一个表20个字段,一个表11个字段等。
把一张宽表根据字段的访问频率、是否大字段等原则拆成多个表。拆表不仅使得业务清晰,还能提升部分查询性能,拆表后,尽量从业务角度避免联查,否则性能方面反而得不偿失。
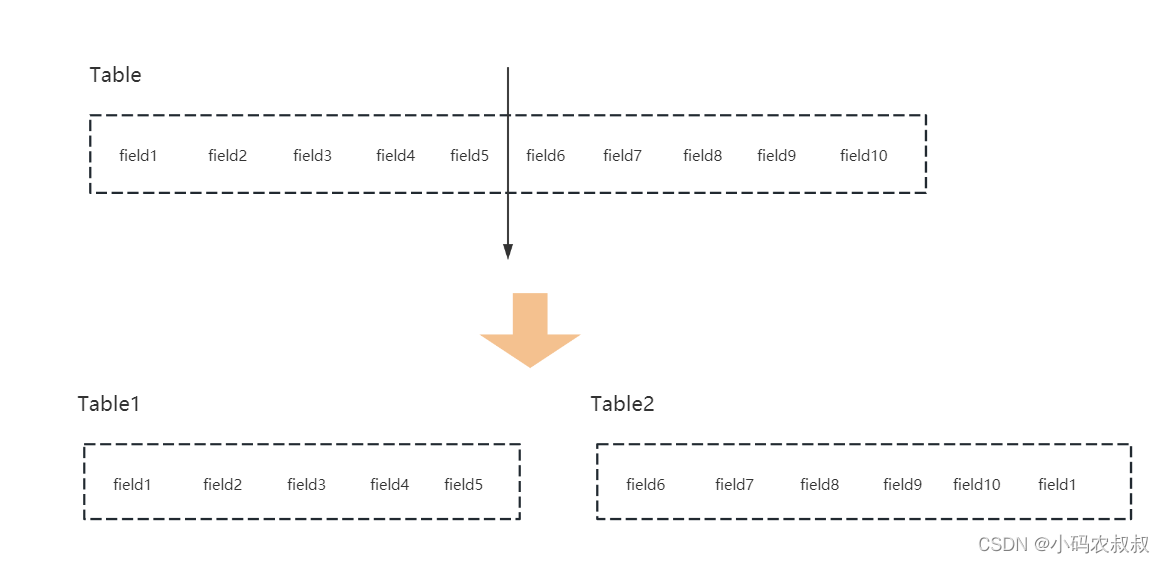
2.2 水平分表
一个表的数据量太大,根据某个关键的业务字段对表进行拆分成多个表共同保存数据,每个表只拥有这个之前这个表的部分数据,这样每个表的数据量就降低了。在一定程度上可以提升查询性能。
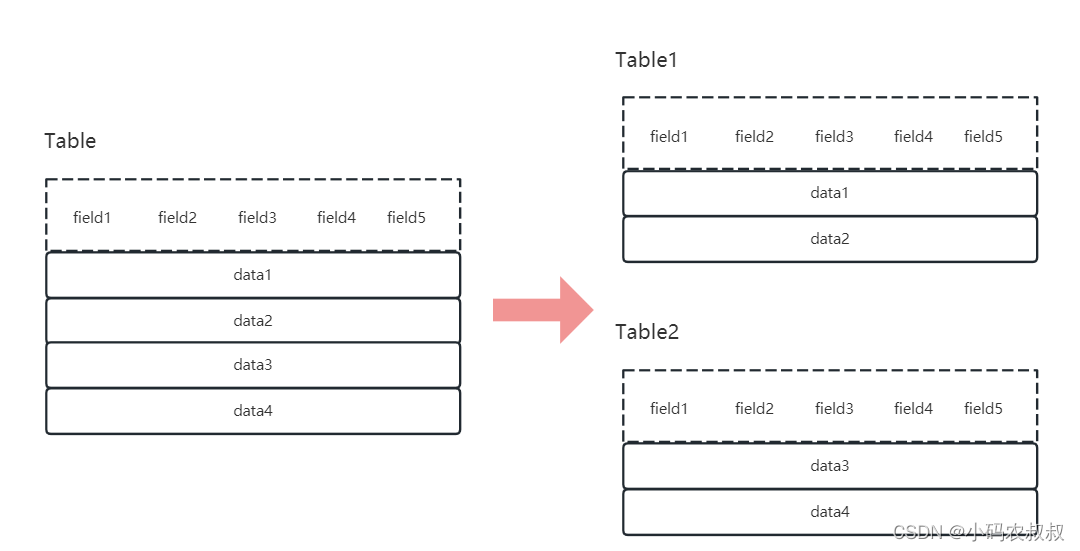
2.3 垂直分库
将一个库中的多个表,分散到多个其他数据库中。一个数据库有100张表,分库之后,一个库60个表,另一个库40张表。
按照业务耦合的松紧程度,将一个库下的多个表,分别放到不同库下。而这些库可以分布在不同服务器,从而使得访问数据库的压力得到分摊和负载,提升性能。同时提高整体架构的业务清晰度,不同的业务库根据自身情况有选择的进行定制化的优化,但是它需要解决垮裤带来的其他复杂问题,比如分布式事务问题。
2.4 水平分库
单表数据量太大,把一个大表的数据按数据行分到不同的数据库,每个库只拥有某个表大数据量的部分数据。比如A表1000万行记录,第一个300万存放第一个库,第二个300万存第二个库,依次等等。
这些库可以分布在不同服务器上,从而使得访问压力被多台服务器分担和负载,提升整体的性能。但这也带来了跨库带来的复杂问题,还要解决查询时的数据路由问题
三、分库分表带来的问题
尽管分库分表能在一定程度上缓解单节点或者单库带来的性能瓶颈和压力,突破网络IO、硬件资源、连接数的瓶颈,但同时也带来了其他问题。
3.1 分布式事务问题
分库之前,应用程序面对的是比较单纯的事务,分库分表后,将数据分不到不同的库甚至不同的服务器,不可避免的带来了分布式事务问题。
3.2 跨节点关联查询问题
分库之后,尤其是水平分库后,为了得到某个查询条件的完整记录行,需要跨库关联查询,如果不在同一个机器上,这是个比较难处理的问题。
3.3 跨节点分页、排序问题
跨节点对多库查询时,使用limit、order by排序时,就变得复杂了。首先需要在多个不同的节点上将数据进行排序并返回,再将不同分片的结果进行汇总和二次排序。
3.4 主键避重问题
在分库分表环境下,由于表中数据同时存在不同数据库中,主键使用自增的方式将失去用武之地。某个分区数据库生成的全局ID将无法保证唯一,因此需要设计全局的主键避免跨主键重复问题。
四、分库分表常用方案
通过上述的问题的分析不难发现,如果人工设计和开发一套这样的程序实现分库分表,简单的业务也许还能实现,当业务变得复杂起来,人工编码成本将变得异常复杂,这时候就需要一套中间件或开源组件的搭配,来帮助应用程序解决分库分表的规则、策略等问题,以减少分库分表的算法上的实现成本。
在具体实践中,经过这些年技术的沉淀和发展,市面上也出现了不少分库分表的解决方案,这里列举如下几种常用的解决方案。
4.1 sharding-sphere
当当开源的一款中间件,属于client层解决方案。
这个中间件对SQL语法的支持比较多,没有太多限制。2.0版本也开始支持分库分表、读写分离、分布式id生成、柔性事务(最大努力送达型事务、TCC事务)。目前社区也还一直在开发和维护,算是比较活跃,是一个现在也可以选择的方案。
4.2 cobar
是阿里的b2b团队开发和开源的,属于proxy层方案,介于应用服务器和数据库服务器之间。应用程序通过JDBC驱动访问cobar集群,cobar根据SQL和分库规则对SQL做分解,然后分发到MySQL集群不同的数据库实例上执行。
cobar不支持读写分离、存储过程、跨库join和分页等操作。早些年还可以用,但是最近几年都没更新了,基本没啥人用,算是淘汰了。
4.3 TDDL
淘宝团队开发的,属于client层方案。
支持基本的crud语法和读写分离,但是不支持join、多表查询等语法。目前使用的也不多,因为使用还需要依赖淘宝的diamond配置管理系统。
4.4 mycat
mycat是基于cobar改造的,属于proxy层方案。其支持的功能十分完善,是目前非常火的一个数据库中间件,能够满足日常各类分库分表的需求。而且社区很活跃,不断在更新。相比于sharding-jdbc来说,年轻一些,经历的锤炼也少一些。
4.5 建议使用方案
综上所述,建议考量使用的就是sharding-jdbc和mycat。
4.5.1 sharding-jdbc和mycat对比
sharding-jdbc这种client层的优点在于不用部署,直接在应用程序中集成即可,因此运维成本也就比较低。同时因为不需要代理层的二次转发请求,性能很高。但是如果遇到升级的话,需要各个系统都重新升级版本再发布,因为各个系统都需要耦合sharding-jdbc的依赖。
而mycat这种proxy方案的缺点在于需要部署,因此运维成本也就比较高。但是优点在于其对于各个项目是透明(解耦)的,如果要升级的话只需要在中间件处理就行了。
通常来说,这两个方案都是可以选用的。但是建议中小型公司选用sharding-jdbc比较好,因为client层方案轻便,维护成本低;而中大型公司选用mycat比较好,因为proxy层方案可以应对多个系统和项目大量使用,虽然维护成本相对来说会较高。
本文接下来将详细介绍sharding-jdbc的使用。
五、分库分表基本概念
在真正开始学习sharding-jdbc的技术之前,有必要对分库分表中常用的几个概念做一个全面的了解,这将有助于对实际使用中对各种分片规则的深入理解。
5.1 基础概念
逻辑表
水平拆分的数据库(表)的相同逻辑和数据结构表的总称,比如:订单数据库根据主键拆分成10个表,分别是order_0... order9,它们的逻辑表就是:order;
真实表
在分片的数据库中真实存在的物理表,比如上面的order0,order1...
数据节点
数据分片的最小单元,通常由数据源名称和数据表组成,比如:ds0.t_user_0
绑定表
指的是分片规则一致的主表和子表,比如t_user表和t_user_detail表,这两个表均按照user_id进行分片,则可以说这两个表互为绑定关系,绑定表之间的关联查询不会出现笛卡尔积关联,这样关联查询的效率就很高。
广播表
指所有的分片数据源中都存在的表,表结构和表中的数据在每个数据库中完全一致,适用于数据量不大但是需要与大表进行关联查询的场景,也可以理解为业务中的公共表。
5.2 分片以及分片策略
5.2.1 分片键
用于分片的数据库的字段,是将数据库(表)进行水平拆分的关键业务字段,比如将订单表中订单主键按照尾数取模分片,则订单主键可认为是分片字段,SQL中如果没有分片字段,将会执行全路由,性能较差,除了对单字段支持分片,sharding-jdbc也支持对多字段进行分片。
5.2.2 常用的分片算法
通过分片算法将实际的数据进行分片,支持通过=、>=、<=、>、<、between和IN进行分片,分片算法需要开发者自行实现,灵活的较高。目前主要提供4种分片算法。
由于分片算法和业务实现紧密相关,因此并未提供内置分片算法,而是通过分片策略将常用的各种场景提炼出来,提供更高层级的抽象,并提供接口给开发者自行实现分片算法。
精准分片算法
即PreciseShardingAlgorithm ,用于处理使用单一键作为分片键的=与IN进行分片的场景,需要配合StandardShardingStrategy使用。
范围分片算法
即RangeShardingAlgorithm,用于处理使用单一键作为分片键的between and ,>,<,>=,<=,进行分片的场景,需要配合StandardShardingStrategy使用。
复合分片算法
即ComplexKeysShardingAlgorithm,用于处理多个键作为分片键进行分片的场景,包含多个分片键的逻辑往往比较复杂,需要开发者自行处理其中的逻辑,需要配合ComplexShardingStrategy使用。
Hint分片算法
对应于HintShardingAlgorithm,用于处理使用Hint行分片场景,需要配合HintShardingStrategy使用。
5.2.3 常用分片策略
分片策略包含分片键和分片算法,由于分片算法的独立性,将其独立抽离,真正可用于分片的操作是分片键+分片算法,也就是分片策略,目前主要提供5种常用的分片策略。
标准分片策略
标准分片策略。提供对SQL语句中的=, IN和BETWEEN AND的分片操作支持。StandardShardingStrategy只支持单分片键,提供PreciseShardingAlgorithm和RangeShardingAlgorithm两个分片算法。
1、PreciseShardingAlgorithm是必选的,用于处理=和IN的分片;
2、RangeShardingAlgorithm是可选的,用于处理BETWEEN AND分片,如果不配置RangeShardingAlgorithm,SQL中的BETWEEN AND将按照全库路由处理;
复合分片策略
提供对SQL语句中的=, IN和BETWEEN AND的分片操作支持。
ComplexShardingStrategy支持多分片键,由于多分片键之间的关系复杂,因此Sharding-JDBC并未做过多的封装,而是直接将分片键值组合以及分片操作符交于算法接口,完全由应用开发者实现,提供最大的灵活度。
行表达式分片策略
Inline表达式分片策略。使用Groovy的Inline表达式,提供对SQL语句中的=和IN的分片操作支持。
InlineShardingStrategy只支持单分片键,对于简单的分片算法,可以通过简单的配置使用,从而避免繁琐的Java代码开发,如: tuser${user_id % 8} 表示t_user表按照user_id按8取模分成8个表,表名称为t_user_0到t_user_7。
Hint分片策略
通过Hint指定分片值而非SQL解析的方式分片的策略。
不分片策略
对应于NoShardingStrategy,即不分片测策略。
六、springboot整合sharding-jdbc
6.1 前置准备
6.1.1 创建数据库表
创建一个数据库db_user_0,在该库下创建两个表,tb_user_0和tb_user_1,里面两个字段,建表sql如下,user_id可以使用自增或使用都可以;
CREATE TABLE `tb_user_0` (
`user_id` int(11) NOT NULL AUTO_INCREMENT,
`user_name` varchar(32) DEFAULT NULL,
PRIMARY KEY (`user_id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8;
6.1.2 搭建springboot父子模块
工程目录如下
父模块引入如下必要依赖
<!-- 统一管理jar包版本 -->
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<springboot-version>2.3.7.RELEASE</springboot-version>
<swagger.version>2.9.2</swagger.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.16</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.2</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.0.5</version>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.4</version>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>2.3.7.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
具体的代码和逻辑将在子模块中进行实现
6.2 sharding-jdbc分表实现
以下的操作将在子模块中进行
6.2.1 基础配置文件
这里配置的是分表的相关策略,请结合注释进行理解,还是比较简单的,主要配置有3点:
- 数据库连接信息,配置数据源;
- 配置原始的物理表;
- 配置分表规则策略,即使用表的什么字段作为分片键,即分表的依据,分片算法如何等;
spring.application.name=sharding-start01
server.port=8081
#mybatis配置
mybatis.type-aliases-package=com.congge.entity
mybatis.mapper-locations=classpath:mybatis/*.xml
mybatis.configuration.map-underscore-to-camel-case=true
#配置第一个数据源
spring.shardingsphere.datasource.names=ds1
#第一个数据源连接相关信息
spring.shardingsphere.datasource.ds1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds1.url=jdbc:mysql://IP:3306/db_user_0?useUnicode=true&characterEncoding=utf-8
spring.shardingsphere.datasource.ds1.username=用户名
spring.shardingsphere.datasource.ds1.password=密码
#配置物理表
spring.shardingsphere.sharding.tables.tb_user.actual-data-nodes=ds1.tb_user_$->{0..1}
#配置分表策略,根据 user_id作为分片依据(分片键)
spring.shardingsphere.sharding.tables.tb_user.table-strategy.inline.sharding-column=user_id
spring.shardingsphere.sharding.tables.tb_user.table-strategy.inline.algorithm-expression=tb_user_$->{user_id%2}
#打开sql输出日志
spring.shardingsphere.props.sql.show=true
6.2.2 实体类
添加一个实体类,与数据库表进行映射
@Data
public class TbUser {
private Integer userId;
private String userName;
}
6.2.3 接口层
public interface TbUserMapper extends BaseMapper<TbUser> {
}
5.2.4 业务实现
添加业务实现类,里面添加一个插入数据的方法
@Service
public class TbUserService {
@Autowired
private TbUserMapper tbUserMapper;
public String save(TbUser tbUser) {
if(StringUtils.isEmpty(tbUser.getUserName())){
throw new RuntimeException("用户名为空");
}
tbUserMapper.insert(tbUser);
return "success";
}
}
6.2.4 接口层
添加一个测试接口
@Api(tags = "用户管理")
@RestController
public class TbUserController {
@Autowired
private TbUserService tbUserService;
@PostMapping("/save")
public String save(@RequestBody TbUser tbUser) {
return tbUserService.save(tbUser);
}
}
6.2.5 添加swagger配置类
使用swagger方便后面的测试
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import springfox.documentation.builders.ApiInfoBuilder;
import springfox.documentation.builders.PathSelectors;
import springfox.documentation.builders.RequestHandlerSelectors;
import springfox.documentation.service.ApiInfo;
import springfox.documentation.spi.DocumentationType;
import springfox.documentation.spring.web.plugins.Docket;
import springfox.documentation.swagger2.annotations.EnableSwagger2;
@Configuration
@EnableSwagger2
public class Swagger2 {
@Bean
public Docket createRestApi() {
return new Docket(DocumentationType.SWAGGER_2)
.apiInfo(apiInfo())
.select()
.apis(RequestHandlerSelectors.basePackage("com.congge.web"))
.paths(PathSelectors.any())
.build();
}
private ApiInfo apiInfo() {
return new ApiInfoBuilder()
.title("分库分表测试")
.version("1.0")
.build();
}
}
6.2.6 启动类
@SpringBootApplication
@MapperScan("com.congge.mapper")
public class StartApp01 {
public static void main(String[] args) {
SpringApplication.run(StartApp01.class,args);
}
}
6.2.7 效果测试
启动上述工程,然后在swagger中调用接口进行测试
第一条数据测试

第二条数据测试
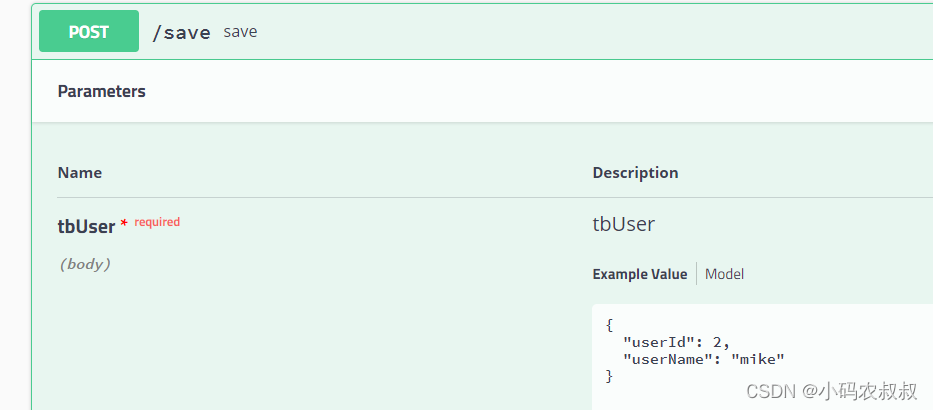
执行成功后,通过数据表查询发现,两条数据分别分布在两个表中;
同时,为了更清楚的搞清楚使用sharding-jdbc的执行过程,在控制台可以查看其执行日志,应该不难理解;

6.3 sharding-jdbc分库实现
上述演示了分表的编码操作实现,接下来演示分库的实现步骤;
6.3.1 准备另一个数据库
创建一个新的数据库,db_user1,里面包括两张表,与上面的表一样
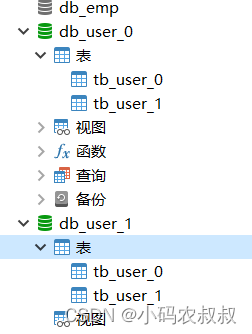
6.3.2 修改配置文件
对上面的配置文件进行修改,完整的配置如下,相比上一个配置,这里多了数据库的分片策略规则;
spring.application.name=sharding-start02
server.port=8082
#mybatis配置
mybatis.type-aliases-package=com.congge.entity
mybatis.mapper-locations=classpath:mybatis/*.xml
mybatis.configuration.map-underscore-to-camel-case=true
#配置第一个数据源
spring.shardingsphere.datasource.names=ds0,ds1
#第1个数据源连接相关信息
spring.shardingsphere.datasource.ds0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds0.url=jdbc:mysql://IP:3306/db_user_0?useUnicode=true&characterEncoding=utf-8
spring.shardingsphere.datasource.ds0.username=用户
spring.shardingsphere.datasource.ds0.password=密码
#第2个数据源连接相关信息
spring.shardingsphere.datasource.ds1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds1.url=jdbc:mysql://IP:3306/db_user_1?useUnicode=true&characterEncoding=utf-8
spring.shardingsphere.datasource.ds1.username=用户名
spring.shardingsphere.datasource.ds1.password=密码
#配置物理表的分片策略
spring.shardingsphere.sharding.tables.tb_user.actual-data-nodes=ds$->{0..1}.tb_user_$->{0..1}
#配置数据库的分片策略
spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column=user_id
spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression=ds$->{user_id%2}
#配置分表策略,根据 user_id作为分片依据(分片键)
spring.shardingsphere.sharding.tables.tb_user.table-strategy.inline.sharding-column=user_id
spring.shardingsphere.sharding.tables.tb_user.table-strategy.inline.algorithm-expression=tb_user_$->{user_id%2}
#打开sql输出日志
spring.shardingsphere.props.sql.show=true
6.3.3 添加测试接口
为了看到效果,添加一个测试接口,模拟10条数据,看看最后两个库的不同的表分表保存了哪些数据;
@PostMapping("/batch/save")
public String batchSave() {
for (int i = 0; i < 10; i++) {
TbUser tbUser = new TbUser();
tbUser.setUserId(i);
tbUser.setUserName("user:" + i);
tbUserMapper.insert(tbUser);
}
return "success";
}
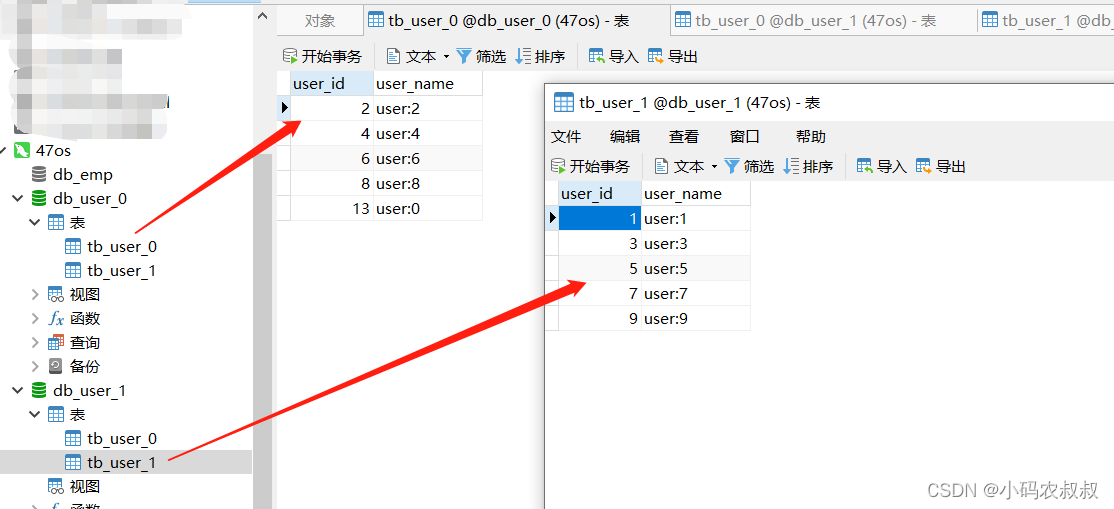
运行程序,调用一下上面的批量插入接口,看到数据库数据表的数据如下效果,这个正好和我们在配置文件中配置的数据库和数据表的分片规则符合,数据分布如下:
- user_id为偶数的分布在第一个数据库db_user_0,同时数据落在tb_user_0这个表;
- user_id为奇数的分布在第二个数据库db_user_1,同时数据落在tb_user_1这个表;
也可以通过控制台的输出日志了解其详细的数据插入过程

6.3.4 查询接口数据测试
看到了数据入库的过程,下面再来看看查询的效果,添加一个查询接口,看看是否能够正确获取到结果
@GetMapping("/query")
public TbUser queryById(@RequestParam Integer id) {
QueryWrapper<TbUser> queryWrapper = new QueryWrapper<>();
queryWrapper.eq("user_id",id);
List<TbUser> tbUsers = tbUserMapper.selectList(queryWrapper);
return tbUsers.get(0);
}
测试一下接口,传入id为3的参数,可以看到能够正确返回结果
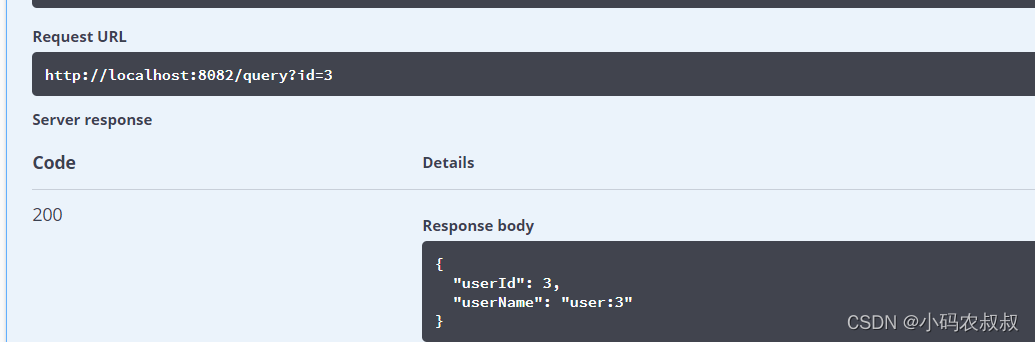
从后台日志来看,这个过程和我们在使用单库查询时并没有什么区别,底层具体路由到哪个库,哪个表完全交给框架来实现;

七、常用分片算法的使用
上文从理论上详细的阐述了常用的分片策略以及分片算法,并通过一个案例快速了解了一下分库分表的使用,接下来将通过具体的代码详细了解下常用的分片算法的使用。
7.1 标准分片算法
在上面提到,由于分片算法和业务实现紧密相关,因此sharding-jdbc并未提供内置分片算法,而只是提供了接口,由开发者自行实现分片算法。
仍然以上面的两个数据库和数据表为例,如果使用标准分片算法改造,只需要做两步操作:
- 自定义分片算法策略的实现类(数据库,数据表);
- 将实现类配置到配置文件中;
如果要实现和第6章节中同样的分库分表的效果,按照下面的步骤操作;
7.1.1 自定义数据库分片实现类
自定义分片策略类,实现PreciseShardingAlgorithm接口,重写里面的doSharding方法;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingValue;
import java.util.Collection;
public class MyDbStandardAlgorithm implements PreciseShardingAlgorithm<Integer> {
/**
* 精确分片
* @param collection 物理数据库集合
* @param preciseShardingValue 分片参数
* @return 本次定位到的数据库
*/
@Override
public String doSharding(Collection<String> collection, PreciseShardingValue<Integer> preciseShardingValue) {
//逻辑表名称
String logicTableName = preciseShardingValue.getLogicTableName();
System.out.println("logicTableName :" + logicTableName);
//分片键
String columnName = preciseShardingValue.getColumnName();
System.out.println("columnName :" + columnName);
//分片键值
Integer value = preciseShardingValue.getValue();
System.out.println("value :" + value);
//数据库真实名称
String dbName = "ds" + (value % 2);
if(!collection.contains(dbName)){
throw new RuntimeException("数据库:" + dbName + "不存在");
}
return dbName;
}
}
7.1.2 自定义表的分片实现类
自定义分片策略类,实现PreciseShardingAlgorithm接口,重写里面的doSharding方法;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingValue;
import java.util.Collection;
public class MyTableStandardAlgorithm implements PreciseShardingAlgorithm<Integer> {
@Override
public String doSharding(Collection<String> collection, PreciseShardingValue<Integer> preciseShardingValue) {
Integer value = preciseShardingValue.getValue();
String tbName = preciseShardingValue.getLogicTableName() + "_" + (value % 2);
if(!collection.contains(tbName)){
throw new RuntimeException("数据表:" + tbName + "不存在");
}
return tbName;
}
}
7.1.3 完整配置文件
将上面的两个实现类的全路径配置到配置文件中,注意分片策略那里选择standard;
spring.application.name=sharding-start02
server.port=8082
#mybatis配置
mybatis.type-aliases-package=com.congge.entity
mybatis.mapper-locations=classpath:mybatis/*.xml
mybatis.configuration.map-underscore-to-camel-case=true
#配置第一个数据源
spring.shardingsphere.datasource.names=ds0,ds1
#第1个数据源连接相关信息
spring.shardingsphere.datasource.ds0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds0.url=jdbc:mysql://IP:3306/db_user_0?useUnicode=true&characterEncoding=utf-8
spring.shardingsphere.datasource.ds0.username=用户名
spring.shardingsphere.datasource.ds0.password=密码
#第2个数据源连接相关信息
spring.shardingsphere.datasource.ds1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds1.url=jdbc:mysql://IP:3306/db_user_1?useUnicode=true&characterEncoding=utf-8
spring.shardingsphere.datasource.ds1.username=用户
spring.shardingsphere.datasource.ds1.password=密码
#配置物理表的分片策略
spring.shardingsphere.sharding.tables.tb_user.actual-data-nodes=ds$->{0..1}.tb_user_$->{0..1}
#配置数据库分片策略
spring.shardingsphere.sharding.default-database-strategy.standard.sharding-column=user_id
spring.shardingsphere.sharding.default-database-strategy.standard.precise-algorithm-class-name=com.congge.algorithm.db.MyDbStandardAlgorithm
#配置分表策略,根据 user_id作为分片依据(分片键) 标准分片算法 使用自定义的实现类
spring.shardingsphere.sharding.tables.tb_user.table-strategy.standard.sharding-column=user_id
spring.shardingsphere.sharding.tables.tb_user.table-strategy.standard.precise-algorithm-class-name=com.congge.algorithm.tables.MyTableStandardAlgorithm
#打开sql输出日志
spring.shardingsphere.props.sql.show=true
7.1.4 添加测试接口
添加一个查询接口
@GetMapping("/query")
public TbUser queryById(@RequestParam Integer id) {
QueryWrapper<TbUser> queryWrapper = new QueryWrapper<>();
queryWrapper.eq("user_id", id);
List<TbUser> tbUsers = tbUserMapper.selectList(queryWrapper);
return tbUsers.get(0);
}
运行工程后,测试该接口,和上面的效果一样仍然可以得到正确的数据,说明上述的自定义标准分片策略生效了;
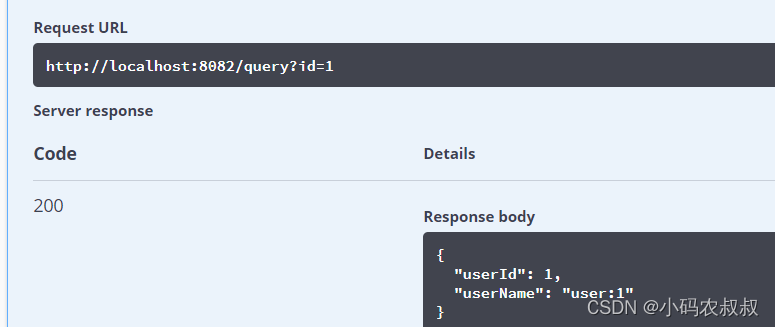
7.2 标准分片算法之范围分片
如果SQL中要查询一个指定范围的数据,比如 user_id in (1,2,3,4,5...),直接使用上面的标准分片就不行了,这时可以使用标准分片中的范围分片算法,请按照下面的步骤操作;
7.2.1 添加数据库自定义分片策略类
public class MyDbStandardRangeAlgorithm implements RangeShardingAlgorithm<Integer> {
/**
* 分库分片策略
* @param collection 具体的物理数据库集合信息
* @param rangeShardingValue
* @return
*/
@Override
public Collection<String> doSharding(Collection<String> collection, RangeShardingValue<Integer> rangeShardingValue) {
//直接将多个数据源返回即可
return collection;
}
}
7.2.2 添加表自定义分片策略类
public class MyTableStandardRangeAlgorithm implements RangeShardingAlgorithm<Integer> {
/**
* 返回真实表的名称集合
* @param collection
* @param rangeShardingValue
* @return
*/
@Override
public Collection<String> doSharding(Collection<String> collection, RangeShardingValue<Integer> rangeShardingValue) {
String tableName = rangeShardingValue.getLogicTableName();
return Arrays.asList(tableName+"_0",tableName+"_1");
}
}
7.2.3 将上述的类配置到配置文件中
完整配置如下,此时,当前的配置策略下,即支持标准的分片,也支持范围分片;
spring.application.name=sharding-start02
server.port=8082
#mybatis配置
mybatis.type-aliases-package=com.congge.entity
mybatis.mapper-locations=classpath:mybatis/*.xml
mybatis.configuration.map-underscore-to-camel-case=true
#配置第一个数据源
spring.shardingsphere.datasource.names=ds0,ds1
#第1个数据源连接相关信息
spring.shardingsphere.datasource.ds0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds0.url=jdbc:mysql://IP:3306/db_user_0?useUnicode=true&characterEncoding=utf-8
spring.shardingsphere.datasource.ds0.username=用户名
spring.shardingsphere.datasource.ds0.password=密码
#第2个数据源连接相关信息
spring.shardingsphere.datasource.ds1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds1.url=jdbc:mysql://IP:3306/db_user_1?useUnicode=true&characterEncoding=utf-8
spring.shardingsphere.datasource.ds1.username=用户名
spring.shardingsphere.datasource.ds1.password=密码
#配置物理表的分片策略
spring.shardingsphere.sharding.tables.tb_user.actual-data-nodes=ds$->{0..1}.tb_user_$->{0..1}
#配置数据库分片策略
spring.shardingsphere.sharding.default-database-strategy.standard.sharding-column=user_id
spring.shardingsphere.sharding.default-database-strategy.standard.precise-algorithm-class-name=com.congge.algorithm.db.MyDbStandardAlgorithm
#支持范围分片
spring.shardingsphere.sharding.default-database-strategy.standard.range-algorithm-class-name=com.congge.algorithm.db.MyDbStandardRangeAlgorithm
#配置分表策略,根据 user_id作为分片依据(分片键) 标准分片算法 使用自定义的实现类
spring.shardingsphere.sharding.tables.tb_user.table-strategy.standard.sharding-column=user_id
spring.shardingsphere.sharding.tables.tb_user.table-strategy.standard.precise-algorithm-class-name=com.congge.algorithm.tables.MyTableStandardAlgorithm
spring.shardingsphere.sharding.tables.tb_user.table-strategy.standard.range-algorithm-class-name=com.congge.algorithm.tables.MyTableStandardRangeAlgorithm
#打开sql输出日志
spring.shardingsphere.props.sql.show=true
7.2.4 添加测试接口
@GetMapping("/query/range")
public List<TbUser> queryRange(@RequestParam Integer from, Integer to) {
QueryWrapper<TbUser> queryWrapper = new QueryWrapper<>();
queryWrapper.between("user_id", from, to);
List<TbUser> tbUsers = tbUserMapper.selectList(queryWrapper);
return tbUsers;
}
执行查询,可以看到,查询1到3范围内的数据都可以查到,说明上述的配置策略生效了
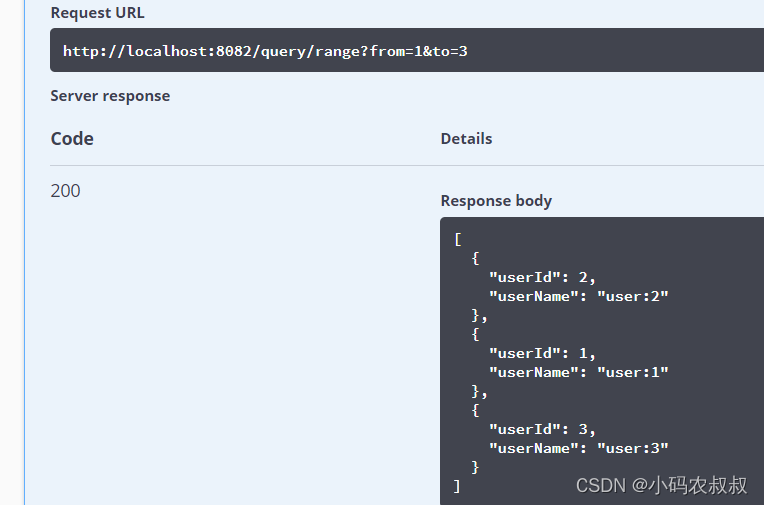
7.3 复合分片算法
7.3.1 标准分片问题
实际业务查询中,查询条件是很复杂的,比如下面的这个接口
@GetMapping("/complex/query")
public List<TbUser> complexQuery(@RequestParam Integer from, @RequestParam Integer to ,@RequestParam String name) {
QueryWrapper<TbUser> queryWrapper = new QueryWrapper<>();
queryWrapper.between("user_id", from, to);
queryWrapper.eq("user_name",name);
List<TbUser> tbUsers = tbUserMapper.selectList(queryWrapper);
return tbUsers;
}
如果继续使用上面的分片策略算法,执行一下接口测试
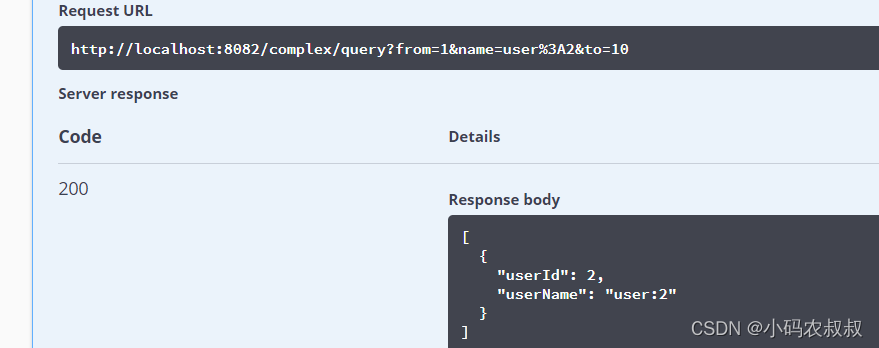
尽管也能查到数据,但是从后台日志来看,却把所有的数据库和表都查了一遍,而我们的目标数据只是在一号库的一号表中,
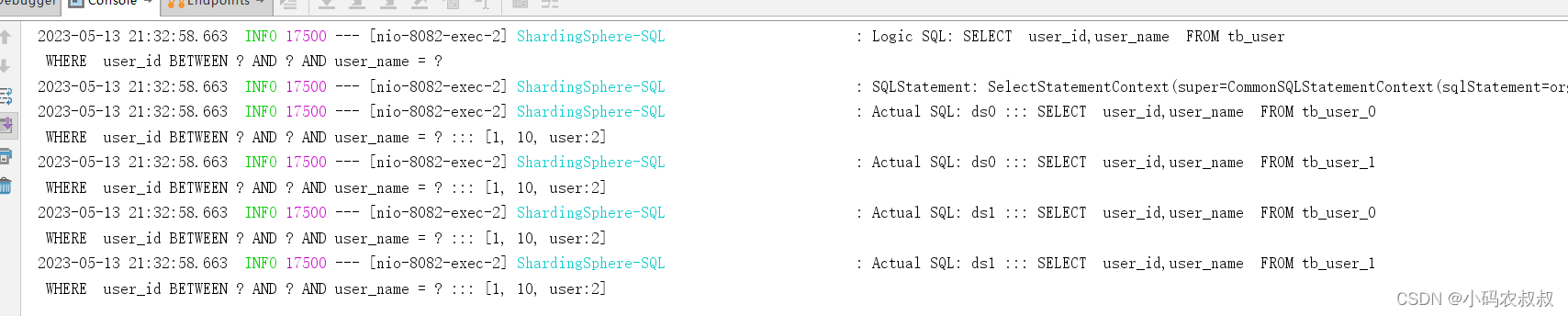
综上来说,在当前的分片策略下,这种方式是低效的,所以需要更换分片策略,在这种情况下,可以考虑使用复合分片算法,下面来看看如何使用复合分片来优化这个问题;
7.3.2 前置准备
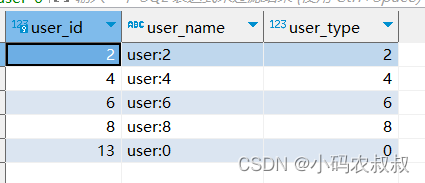
复合分片这种模式下,允许开发者根据实际情况指定多个分片字段,在本例中,对上述使用的用户表,新增一个user_type的字段,并重新初始化数据进去,其他的保持不变;
7.3.3 添加自定义复合分片策略类
和上面自定义标准分片策略类似,先分别自定义数据库和表的复合分片策略类,实现ComplexKeysShardingAlgorithm接口;
数据库复合分片策略类
public class MyDbComplexAlgorithm implements ComplexKeysShardingAlgorithm<Integer> {
/**
* @param collection
* @param complexKeysShardingValue
* @return 这一次查找到的数据节点(数据库)集合
*/
@Override
public Collection<String> doSharding(Collection<String> collection, ComplexKeysShardingValue<Integer> complexKeysShardingValue) {
Collection<Integer> userTypes = complexKeysShardingValue.getColumnNameAndShardingValuesMap().get("user_type");
Collection<String> dbNames = new ArrayList<>();
for (Integer userType : userTypes) {
String dbName = "ds" + (userType % 2);
dbNames.add(dbName);
}
return dbNames;
}
}
表复合分片策略类
public class MyTableComplexAlgorithm implements ComplexKeysShardingAlgorithm<Integer> {
@Override
public Collection<String> doSharding(Collection<String> collection, ComplexKeysShardingValue<Integer> complexKeysShardingValue) {
Collection<Integer> userTypes = complexKeysShardingValue.getColumnNameAndShardingValuesMap().get("user_type");
Collection<String> tableNames = new ArrayList<>();
for (Integer userType : userTypes) {
String tbName =complexKeysShardingValue.getLogicTableName() + "_" + (userType % 2);
tableNames.add(tbName);
}
return tableNames;
}
}
7.3.4 将自定义策略类配置到配置文件
spring.application.name=sharding-start02
server.port=8082
#mybatis配置
mybatis.type-aliases-package=com.congge.entity
mybatis.mapper-locations=classpath:mybatis/*.xml
mybatis.configuration.map-underscore-to-camel-case=true
#配置第一个数据源
spring.shardingsphere.datasource.names=ds0,ds1
#第1个数据源连接相关信息
spring.shardingsphere.datasource.ds0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds0.url=jdbc:mysql://IP:3306/db_user_0?useUnicode=true&characterEncoding=utf-8
spring.shardingsphere.datasource.ds0.username=用户名
spring.shardingsphere.datasource.ds0.password=密码
#第2个数据源连接相关信息
spring.shardingsphere.datasource.ds1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds1.url=jdbc:mysql://IP:3306/db_user_1?useUnicode=true&characterEncoding=utf-8
spring.shardingsphere.datasource.ds1.username=用户名
spring.shardingsphere.datasource.ds1.password=密码
#配置物理表的分片策略
spring.shardingsphere.sharding.tables.tb_user.actual-data-nodes=ds$->{0..1}.tb_user_$->{0..1}
### complex 分库策略
# user_type,user_id 同时作为分库分片健
spring.shardingsphere.sharding.tables.tb_user.database-strategy.complex.sharding-columns=user_id,user_type
spring.shardingsphere.sharding.tables.tb_user.database-strategy.complex.algorithm-class-name=com.congge.algorithm.db.MyDbComplexAlgorithm
#complex 表分片策略
spring.shardingsphere.sharding.tables.tb_user.table-strategy.complex.sharding-columns=user_id,user_type
spring.shardingsphere.sharding.tables.tb_user.table-strategy.complex.algorithm-class-name=com.congge.algorithm.tables.MyTableComplexAlgorithm
#打开sql输出日志
spring.shardingsphere.props.sql.show=true
7.3.5 接口测试
再来调用一下上述的接口
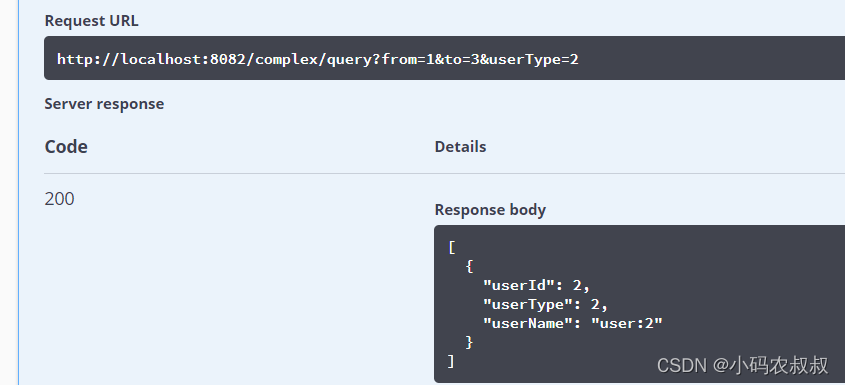
虽然得到的结果是一样的,但是当查看控制台sql的输出日志时发现,这一次明显查询的总次数减少了,如果在数据量较大的情况下,这样做明显可以减少应用程序与数据库的IO,提升整体的性能;

八、写在文末
在实际使用的时候,可以多种分片算法配合使用,往往需要自定义分片规则,根据业务需要的不同,有的规则逻辑甚至很复杂,这个对编码有一定的要求,所以不到万不得已,一般不要轻易使用分库分表。由于篇幅有限,更多的分片规则算法可以参照上面的案例类似的进行研究。
版权归原作者 小码农叔叔 所有, 如有侵权,请联系我们删除。