
🌕写在前面
Hello🤗大家好啊,我是kikokingzz,名字太长不好记,大家可以叫我kiko哦~
从今天开始,我将正式开启一个新的打卡专题——【计算机网络·宇宙计划】,没错!这是今年上半年的一整个系列计划!本专题目的是通过百天刷题计划,通过题目和知识点串联的方式,刷够1000道题!完成对计算机网络相关知识的全方位复习和巩固;同时还配有专门的笔记总结和文档教程哦!想要搞定,搞透计算机网络的同学
🎉🎉欢迎订阅本专栏🎉🎉
🍊博客主页:kikoking的江湖背景🍊
🌟🌟往期必看🌟🌟
🔥【计算机网络】第一话·计算机网络的基本概念
🔥【计算机网络】第二话·计算机网络的体系结构
🔥【计算机网络】第三话·浅谈OSI和TCP/IP模型
🔥【计算机网络】第四话·深入理解物理层の细节
🔥【计算机网络】第五话·物理层的底层设备❥超详解
🔥【计算机网络】第六话·数据的传输方式(上)
🔥【计算机网络】第七话·计算机网络的流量控制



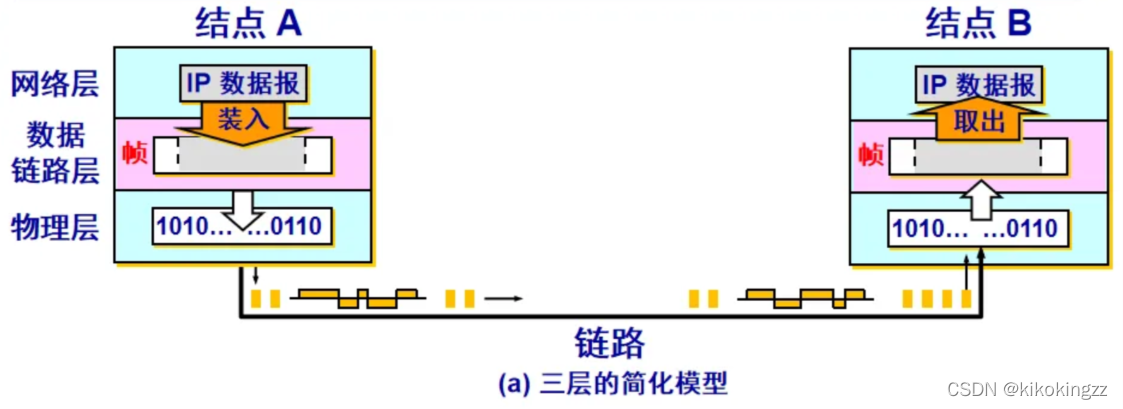
🍺什么是数据链路层?
数据链路层在物理层提供服务的基础上向网络层提供服务,其主要作用是加强物理层传输原始比特流的功能,将物理层提供的可能出错的物理连接改造为逻辑上无差错的数据链路,使之对网络层表现为一条无差错的链路。
🍺知识点8:数据链路层的功能
🥝功能1:为网络层提供服务
对网络层而言,数据链路层的基本任务是将源机器中来自网络层的数据传输到目标机器的网络层。数据链路层通常可为网络层提供如下服务:
(1)无确认的无连接服务
源机器发送数据帧时不需先建立链路连接,目的机器收到数据帧时不需发回确认。对丢失的帧,数据链路层不负责重发而交给上层处理。适用于实时通信或误码率较低的通信信道,如以太网。
(2)有确认的无连接服务
源机器发送数据帧时不需先建立链路连接,但目的机器收到数据帧时必须发回确认。源机器在所规定的时间内未收到确定信号时,就重传丢失的帧,以提高传输的可靠性。该服务适用于误码率较高的通信信道,如无线通信。
(3)有确认的面向连接服务
帧传输过程分为三个阶段:建立数据链路、传输帧、释放数据链路。目的机器对收到的每一帧都要给出确认,源机器收到确认后才能发送下--帧,因而该服务的可靠性最高。该服务适用于通信要求(可靠性、实时性)较高的场合。
注意:有连接就一定要有确认,即不存在无确认的面向连接的服务。
📜127.题目难度 ⭐️⭐️
127.数据链路层为网络层提供的服务不包括( )。 A.无确认的无连接服务 B.有确认的无连接服务 C.无确认的面向连接服务 D.有确认的面向连接服务🍊详细题解:
连接是建立在确认机制的基础上的,因此数据链路层没有无确认的面向连接服务。一般情况下,数据链路层会为网络层提供三种可能的服务:无确认的无连接服务、有确认的无连接服务、有确认的面向连接服务。
✅正确答案:C
📜128.题目难度 ⭐️⭐️⭐️
128.对于信道比较可靠且对实时性要求高的网络,数据链路层采用( )比较合适。 A.无确认的无连接服务 B.有确认的无连接服务 C.无确认的面向连接服务 D.有确认的面向连接服务🍊详细题解:
无确认的无连接服务:源机器发送数据帧时不需先建立链路连接,目的机器收到数据帧时不需发回确认。相比其他服务所做的“事情”少,相应地通信速度更快,当错误率很低时,这一类服务对于实时通信也是非常合适的,因为实时通信中数据的迟到比数据损坏更不好。这时恢复任务可以留给上面的各层来完成。
✅正确答案:A
** ✨✨✨我是分割线✨✨✨**
🥝功能2:封装成帧
🍊1.什么是帧定界?
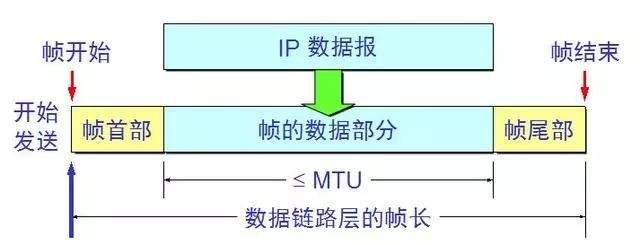
两台主机之间传输信息时,必须将网络层的分组封装成帧,以帧的格式进行传送。将一段数据的前后分别添加首部和尾部,就构成了帧。因此,帧长等于数据部分的长度加上首部和尾部的长度。首部和尾部中含有很多控制信息,它们的一个重要作用是确定帧的界限,即帧定界。
Q1:帧为什么要添加首部和尾部?
A1:因为接收端收到的是一串比特流,没有首部和尾部是不能正确区分帧的,接收端要正确地接收帧,必须要清楚该帧在一串比特流中从哪里开始到哪里结束。
注意:分组(IP数据报)仅是包含在帧中的数据部分,所以不需要加尾部来定界。
Q2:如何提高帧的传输效率?
A2:为了提高帧的传输效率,应当使帧的数据部分的长度尽可能地大于首部和尾部的长度,但每种数据链路层协议都规定了帧的数据部分的长度上限——最大传送单元(MTU)。
🍊2.什么是帧同步?
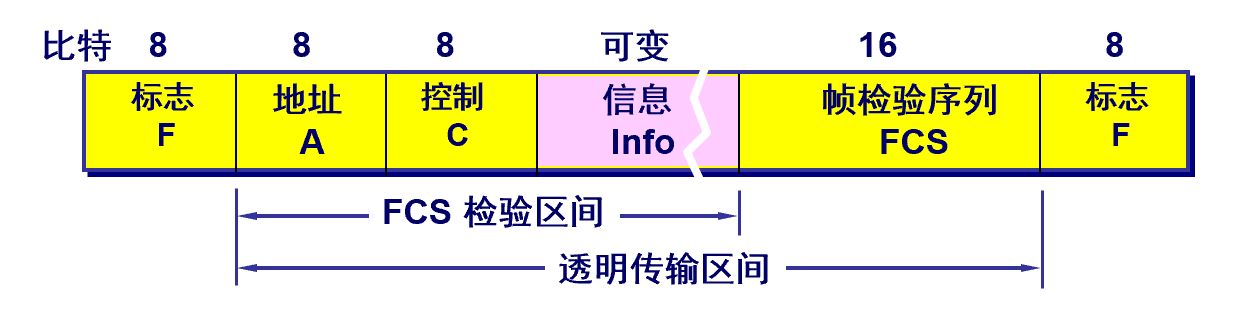
帧同步指的是接收方应能从接收到的二进制比特流中区分出帧的起始与终止。如在HDLC协议中,用标识位F(01111110)来标识帧的开始和结束。通信过程中,检测到帧标识位F即认为是帧的开始,然后一旦检测到帧标识位F即表示帧的结束。
🍊3.什么是透明传输?
透明传输是指不管所传数据是什么样的比特组合,都应当能够在链路上传送。当所传数据中的比特组合恰巧与某一个控制信息完全一样时,就必须采取适当的措施,使收方不会将这样的数据误认为是某种控制信息。这样才能保证数据链路层的传输是透明的。
🍊4.为什么要组帧?
数据链路层之所以要把比特组合成帧为单位传输,是为了在出错时只重发出错的帧,而不必重发全部数据,从而提高效率。为了使接收方能正确地接收并检查所传输的帧,发送方必须依据一定的规则把网络层递交的分组封装成帧(称为组帧)。组帧主要解决帧定界、帧同步、透明传输等问题。
🍊5.组帧有哪些方法?
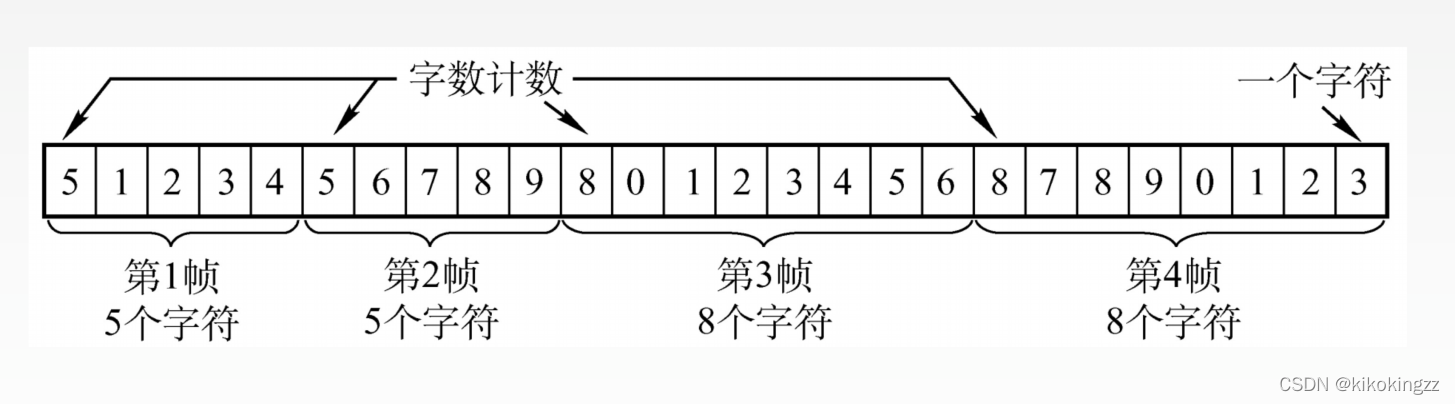
(1)字符计数法
字符计数法是指在帧头部使用一个计数字段来标明帧内字符数。目的结点的数据链路层收到字节计数值时,就知道后面跟随的字节数,从而可以确定帧结束的位置(计数字段提供的字节数包含自身所占用的一个字节)。
缺点:这种方法最大的问题在于如果计数字段出错,即失去了帧边界划分的依据,那么接收方就无法判断所传输帧的结束位和下一帧的开始位,收发双方将失去同步,从而造成灾难性后果。
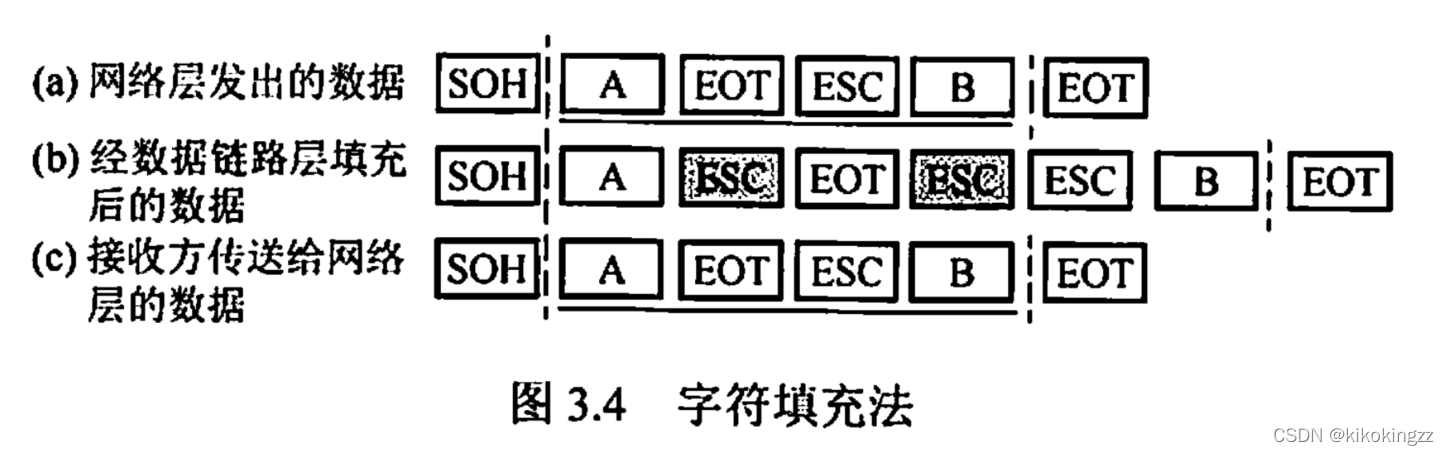
(2)字符填充法
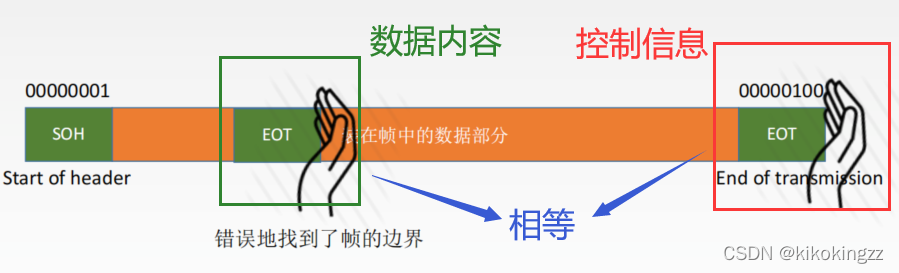
字符填充法使用特定字符来定界一帧的开始与结束,在下面例子中,控制字符SOH放在帧的最前面,表示帧的首部开始,控制字符EOT表示帧的结束。为了使信息位中出现的特殊字符不被误判为帧的首尾定界符,可在特殊字符前面填充一个转义字符(ESC)来加以区分,以实现数据的透明传输。
接收方收到转义字符后,就知道其后面紧跟的是数据信息,而不是控制信息。因此会自己删除这个插入的ESC字符,结果仍得到原来的数据[见图3.4(c)]。
注意:转义字符是ASCII码中的控制字符,是一个字符,而非“E”“S"“C”三个字符的组合;如果转义字符 ESC也出现在数据中,那么解决方法仍是在转义字符前插入一个转义字符。
(3)零比特填充法
如下图所示,零比特填充法允许数据帧包含任意个数的比特,也允许每个字符的编码包含任意个数的比特。它使用一个特定的比特模式,即01111110来标志一帧的开始和结束。
为了不使信息位中出现的比特流01111110被误判为帧的首尾标志,发送方的数据链路层在信息位中遇到5个连续的“1”时,将自动在其后插入一个“0”;而接收方做该过程的逆操作,即每收到5个连续的“1”时,自动删除后面紧跟的“0”,以恢复原信息。
(4)违规编码法
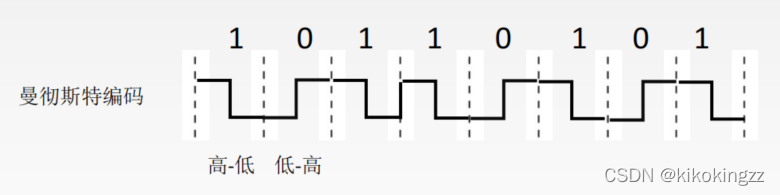
在物理层进行比特编码时,通常采用违规编码法。例如,曼彻斯特编码方法将数据比特“1”编码成“高-低”电平对,将数据比特“0”编码成“低-高”电平对,而“高-高”电平对和“低-低”电平对在数据比特中是违规的(即没有采用)。可以借用这些违规编码序列来定界帧的起始和终止。局域网IEEE 802标准就采用了这种方法。
由于字节计数法中计数字段的脆弱性和字符填充法实现上的复杂性与不兼容性,目前较常用的组帧方法是比特填充法和违规编码法。

📜习题检测
📜129.题目难度 ⭐️⭐️
129.在一个数据链路协议中使用下列字符编码: A 01000111; B 11100011; ESC 11100000; FLAG 01111110 在使用下列成帧方法的情况下,说明为传送4个字符A、B、ESC、FLAG所组织的帧而实际发送的 二进制位序列(使用FLAG作为首尾标志,ESC作为转义字符)。 1)字符计数法。 2)使用字符填充的首尾定界法。 3)使用比特填充的首尾标志法。🍊详细题解:
(1)使用字符计数法:帧头部使用一个计数字段来标明帧内字符数,此处要传送4个字符,如果包括帧头部的计数字段,则一共是5个字符,转换为二进制00000101,后面依次为A、B、ESC、FLAG的二进制编码。
00000101 01000111 11100011 11100000 01111110(2)使用字符填充法:字符填充法使用特定字符来定界一帧的开始与结束,使用FLAG作为首位标志,为了使信息位中出现的特殊字符不被误判为帧的首尾定界符,可在特殊字符前面填充一个转义字符(ESC)来加以区分,以实现数据的透明传输。
01111110 01000111 11100011 11100000 11100000 11100000 01111110 01111110 FLAG A B ESC ESC ESC FLAG FLAG(3)使用字符填充法:使用一个特定的比特模式,即01111110来标志一帧的开始和结束。为了不使信息位中出现的比特流01111110被误判为帧的首尾标志,发送方的数据链路层在信息位中遇到5个连续的“1”时,将自动在其后插入一个“0”。
01111110 01000111 11_100011 111_00000 011111_10 01111110 连续5个1后插入1个0 01111110 01000111 110100011 111000000 011111010 01111110
** ✨✨✨我是分割线✨✨✨**
🥝功能3:差错控制
差错控制:由于信道噪声等各种原因,帧在传输过程中可能会出现错误。用以使发送方确定接收方是否正确收到由其发送的数据的方法称为差错控制。通常,这些错误可分为位错和帧错。
帧错:帧错指帧的丢失、重复或失序等错误。在数据链路层引入定时器和编号机制,能保证每一帧最终都能有且仅有一次正确地交付给目的结点。
比特差错(位错):位错指帧中某些位出现了差错。实际通信链路都不是理想的,比特在传输过程中可能会产生差错,1可能会变成0,0也可能会变成1,这就是比特差错,比特差错是传输差错中的一种。
通常采用循环冗余校验(CRC)方式发现位错,通过自动重传请求(Automatic Repeat reQuest,ARQ)方式来重传出错的帧。具体做法是:让发送方将要发送的数据帧附加一定的CRC冗余检错码一并发送,接收方则根据检错码对数据帧进行错误检测,若发现错误则丢弃,发送方超时重传该数据帧。这种差错控制方法称为ARQ法。ARQ法只需返回很少的控制信息就可有效地确认所发数据帧是否被正确接收。
🍊1.差错从何而来****?
总体来说,传输中的差错是由于噪声引起的。
130.通过提高信噪比可以减弱其影响的差错是( )。 A.随机差错 B.突发差错 C.数据丢失差错 D.干扰差错kiko🎃:一般来说,数据的传输差错是由噪声引起的。通信信道的噪声可以分为两类:热噪声和冲击噪声。热噪声一般是信道固有的,引起的差错是随机差错,可以通过提高信噪比来降低它对数据传输的影响。冲击噪声一般是由外界电磁干扰引起的,引起的差错是突发差错,它是引起传输差错的主要原因,无法通过提高信噪比来避免;因此本题选A。
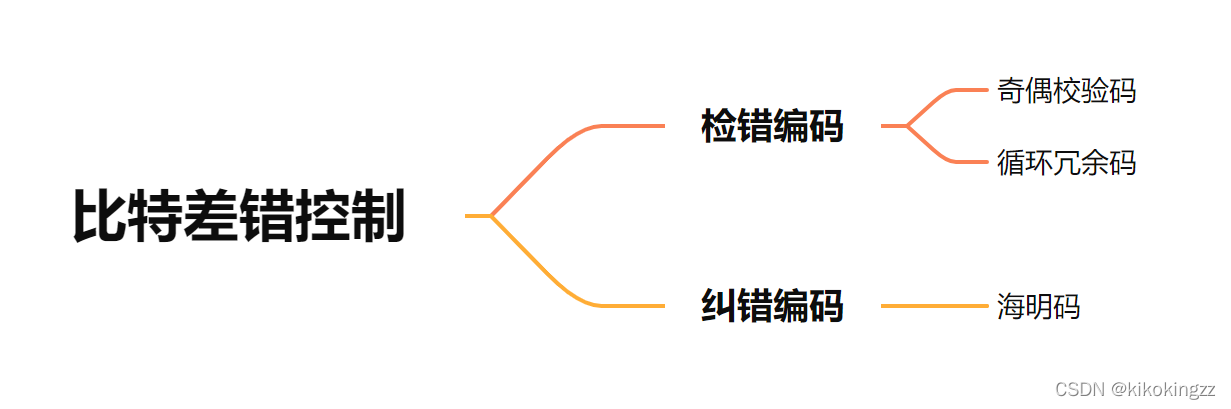
🍊2.什么是检错编码****?
检错编码都采用冗余编码技术,其核心思想是在有效数据(信息位)被发送前,先按某种关系附加一定的冗余位,构成一个符合某一规则的码字后再发送。当要发送的有效数据变化时,相应的冗余位也随之变化,使得码字遵从不变的规则。接收端根据收到的码字是否仍符合原规则来判断是否出错。常见的检错编码有奇偶校验码和循环冗余码。
Q1:数据链路层的编码与物理层的编码有什么区别?
A1:数据链路层编码和物理层的数据编码与调制不同:
- 物理层编码:物理层编码是针对单个比特的(0/1),解决传输过程中比特的同步等问题,如曼彻斯特编码。
- 数据链路层编码:数据链路层的编码针对的是一组比特,它通过冗余码的技术实现一组二进制比特串在传输过程是否出现了差错。
🍊3.奇偶校验码
奇偶校验码是奇校验码和偶校验码的统称,是一种最基本的检错码。它由n-1位信息元和1位校验元组成。它只能检测奇数位的出错情况,但并不知道哪些位错了,也不能发现偶数位的出错情况。
- 如果是奇校验码,那么在附加一个校验元后,码长为n的码字中“1”的个数为奇数;
- 如果是偶校验码,那么在附加一个校验元以后,码长为n的码字中“1”的个数为偶数。
例如下图中的A、B、C选项都有1位bit出错,即出现奇数个错误;而D选项有2位bit出错,即偶数个错误,奇偶校验码无法检测出来。
131.下列属于奇偶校验码特征的是( )。 A.只能检查出奇数个比特错误 B.能查出长度任意一个比特的错误 C.比CRC检验可靠 D.可以检查偶数个比特的错误kiko🎃:奇偶校验的原理是通过增加冗余位来使得码字中“1”的个数保持为奇数或偶数的编码方法,它只能发现奇数个比特的错误;因此本题选A。
132.字符S的ASCII编码从低到高依次为1100101,采用奇校验,在下述收到的传输后字符 中,错误( )不能检测。 A.11000011 B.11001010 C.11001100 D.11010011kiko🎃:既然采用奇校验,那么传输的数据中1的个数若是偶数个则可检测出错误,若1的个数是奇数个,则检测不出错误,因此选D。
🍊4.CRC循环冗余码
循环冗余码(Cyclic Redundancy Code,CRC)又称多项式码。
Q1:给定一个多项式G(X),如何计算其对应的二进制位串呢?
A1:任何一个由二进制数位串组成的代码都可以与一个只含有0和1两个系数的多项式建立对应关系。一个k位帧可以视为从
到
的k次多项式的系数序列。
Q2:如何计算循环冗余码?
A2:给定一个m bit的帧或报文,发送器生成一个r bit的序列,称为帧检验序列(FCS)。这样所形成的帧将由m+r比特组成。发送方和接收方事先商定一个多项式G(X)(最高位和最低位必须为1),使这个带检验码的帧刚好能被预先确定的多项式G(X)整除。接收方用相同的多项式去除收到的帧,如果无余数,那么认为无差错。
注意:FCS的生成以及接收端CRC检验都是由硬件实现,处理很迅速, 因此不会延误数据的传输。
Q3:接收端如何检测帧的正确性?
A3:接收端把收到的每一个帧(d+r位数据)都除以同样的除数(生成多项式),然后检查得到的余数R:
- 余数为0:判定这个帧没有差错,接受。
- 余数非0:判定这个帧有差错(无法确定到位),丢弃。
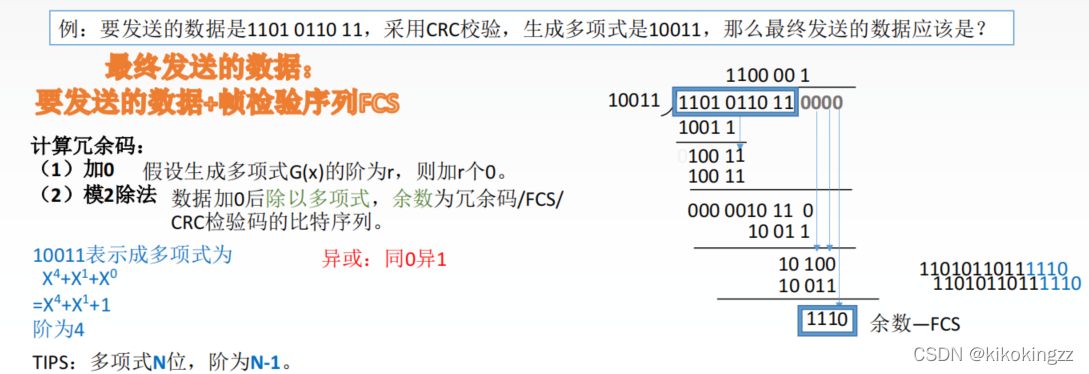
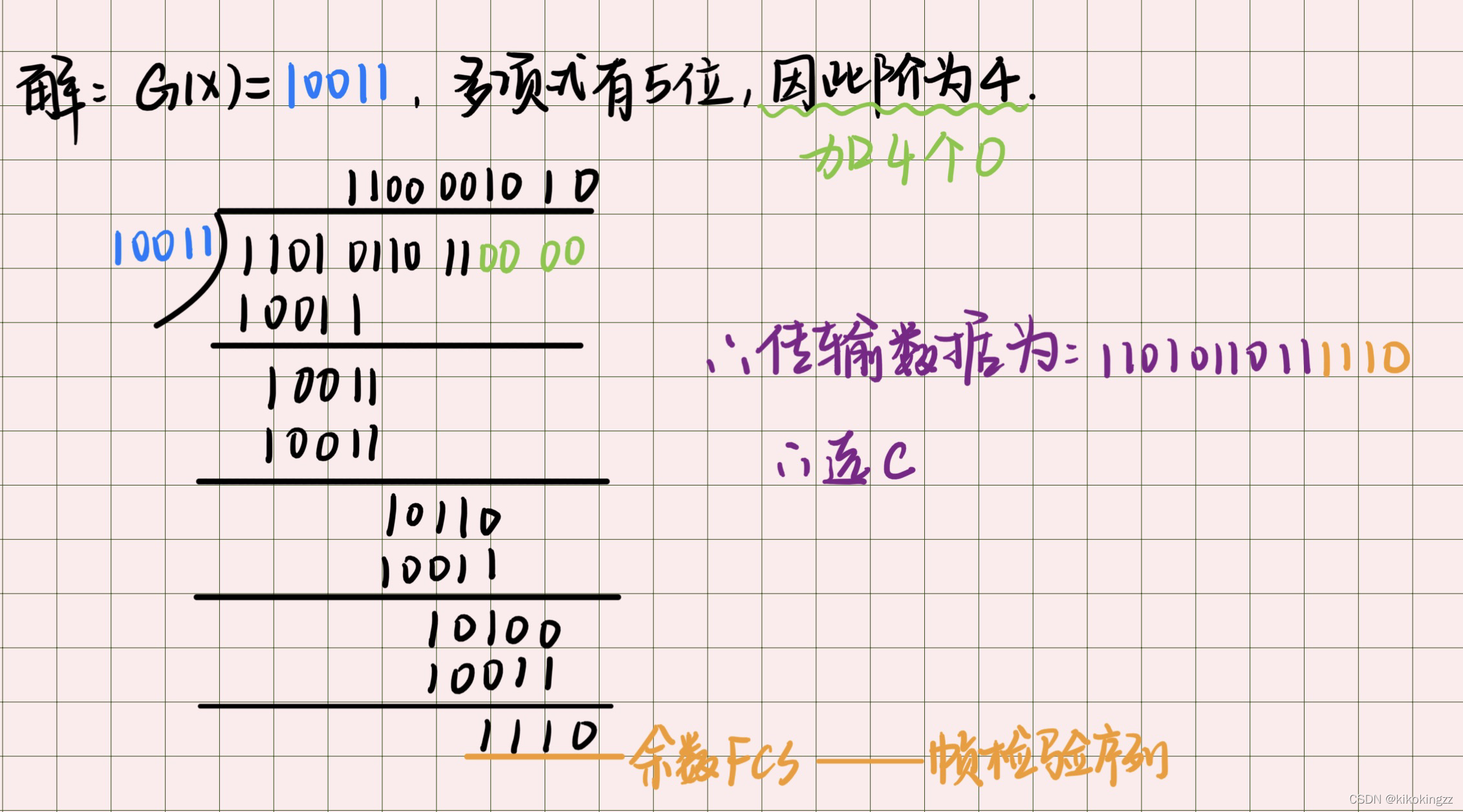
133.要发送的数据是1101 0110 11,采用CRC校验,生成多项式是10011,那么最终发送的 数据应是( )。 A. 1101 0110 1110 10 B. 1101 0110 1101 10 C. 1101 0110 1111 10 D. 1111 0011 0111 00
🍊5.海明码
在数据通信的过程中,解决差错问题的一种方法是在每个要发送的数据块上附加足够的冗余信息,使接收方能够推导出发送方实际送出的应该是什么样的比特串。最常见的纠错编码是海明码,其实现原理是在有效信息位中加入几个校验位形成海明码,并把海明码的每个二进制位分配到几个奇偶校验组中。当某一位出错后,就会引起有关的几个校验位的值发生变化,这不但可以发现错位,而且能指出错位的位置,为自动纠错提供依据。
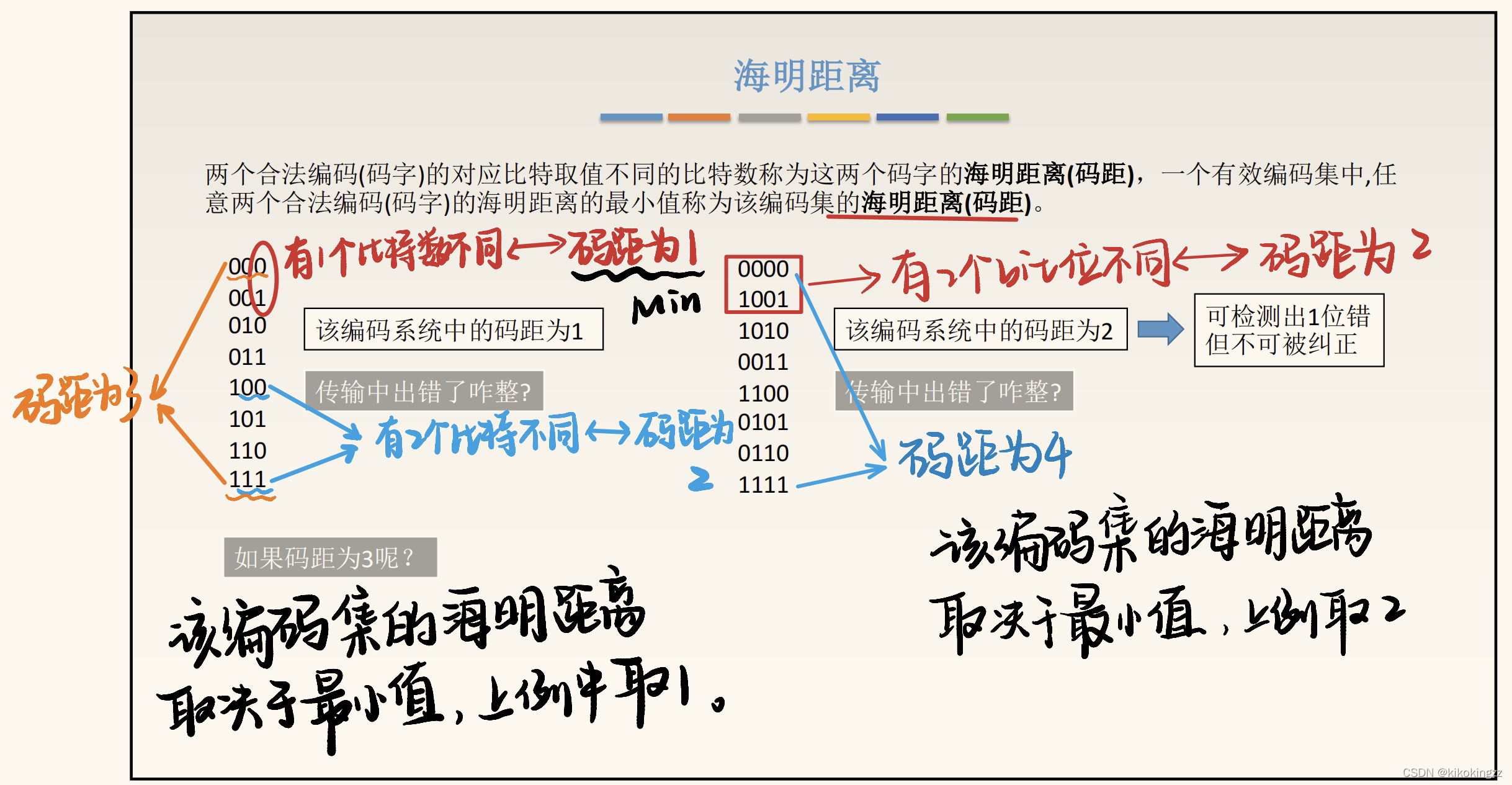
Q1:什么是海明码距?
A1:两个合法编码(码字)的对应比特取值不同的比特数称为这两个码字的海明距离(码距),一个有效编码集中,任意两个合法编码(码字)的海明距离的最小值称为该编码集的海明码距。
注意:对于海明码距,要检测d位错时,海明码距需要d+1;要纠正d位错时,海明码距要2d+1。
134.为了纠正2比特的错误,编码的海明距应该为( )。 A.2 B.3 C.4 D.5kiko🎃:海明码“纠错”d位,需要码距为2d+1的编码方案;“检错”d位,则只需码距为d+1,由于本题是要求纠错,海明码距应当为2*2+1=5;因此本题选D。
Q2:海明码是如何编码的?
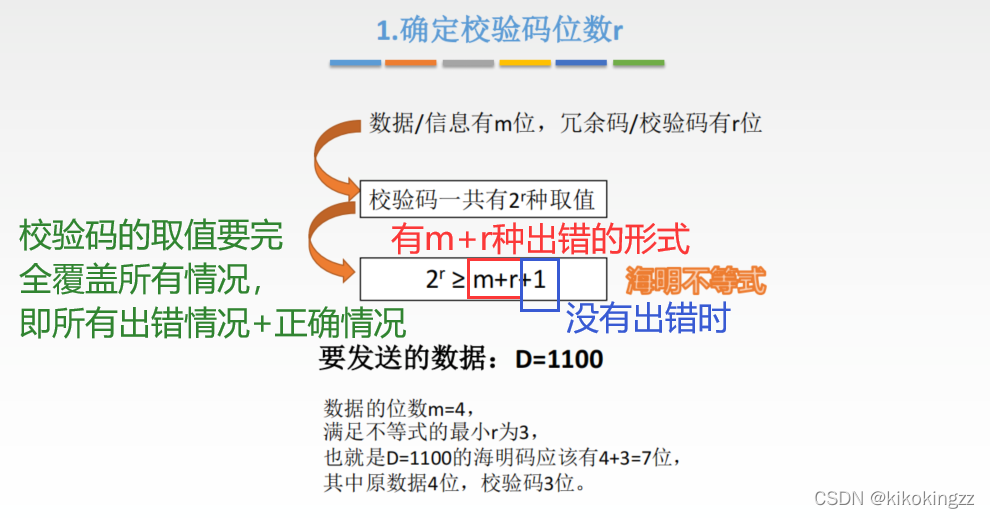
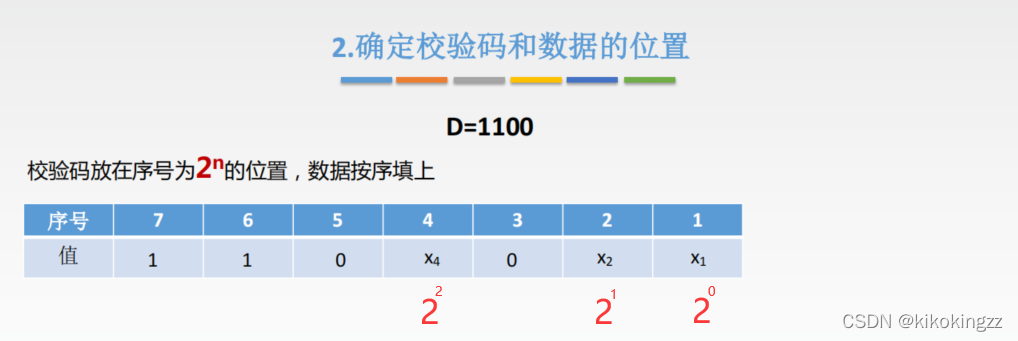
A2:海明码的编码主要有3个步骤:
135.对于10位要传输的数据,如果采用汉明校验码,那么需要增加的冗余信息位数是( )。 A.3 B.4 C.5 D.6kiko🎃:本题考察的是上述步骤中的第一步。在k比特信息位上附加r比特冗余信息,为了满足海明不等式,因此可以计算得出当r=4时就可以满足海明不等式了,因此增加的冗余信息数是4;本题选B。
Q3:海明码是如何纠错的?
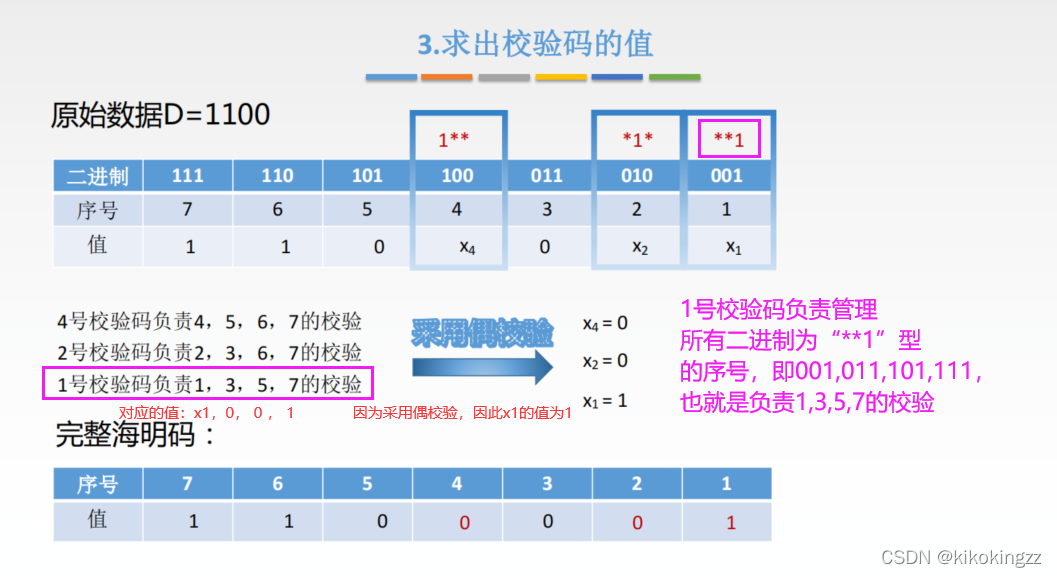
A3:海明码的纠错是利用校验位与参与形成该校验位的信息位进行奇偶校验检查进行纠错的,主要的操作方式可以有以下两种:
方法1:采用分组取差集的方式
方法2:将校验码负责的信息位相异或


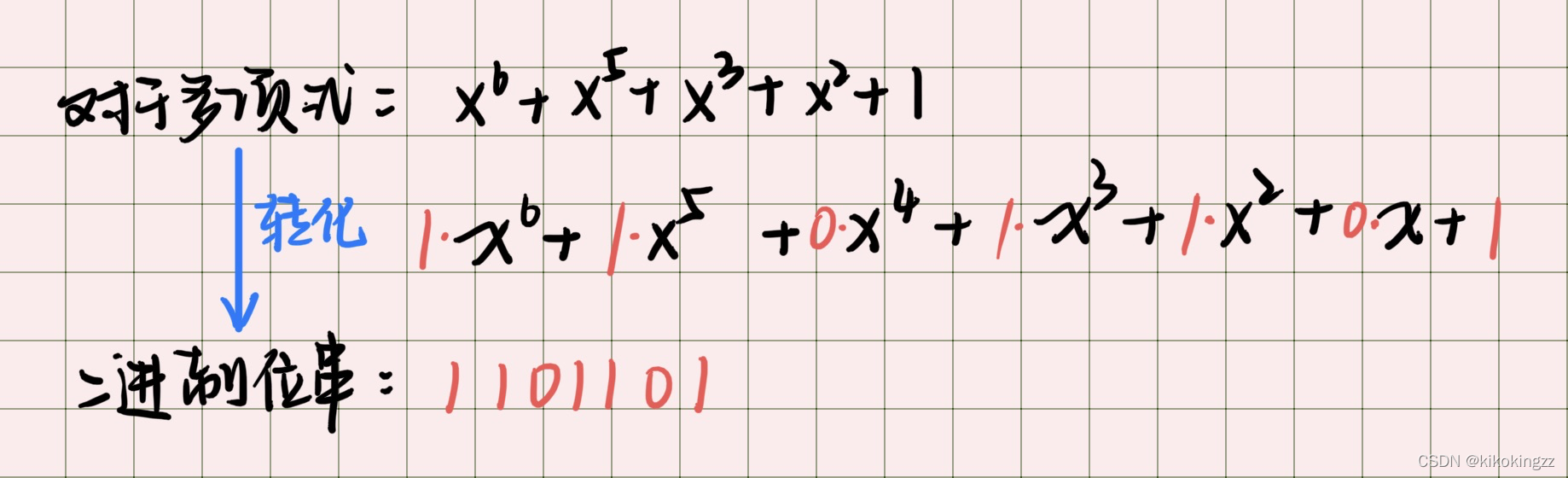

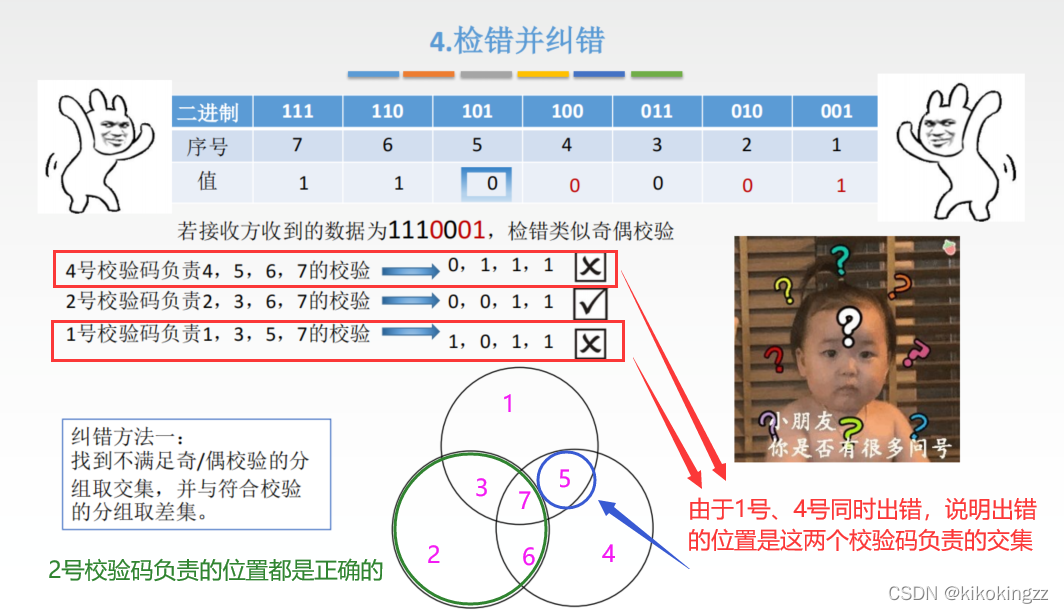
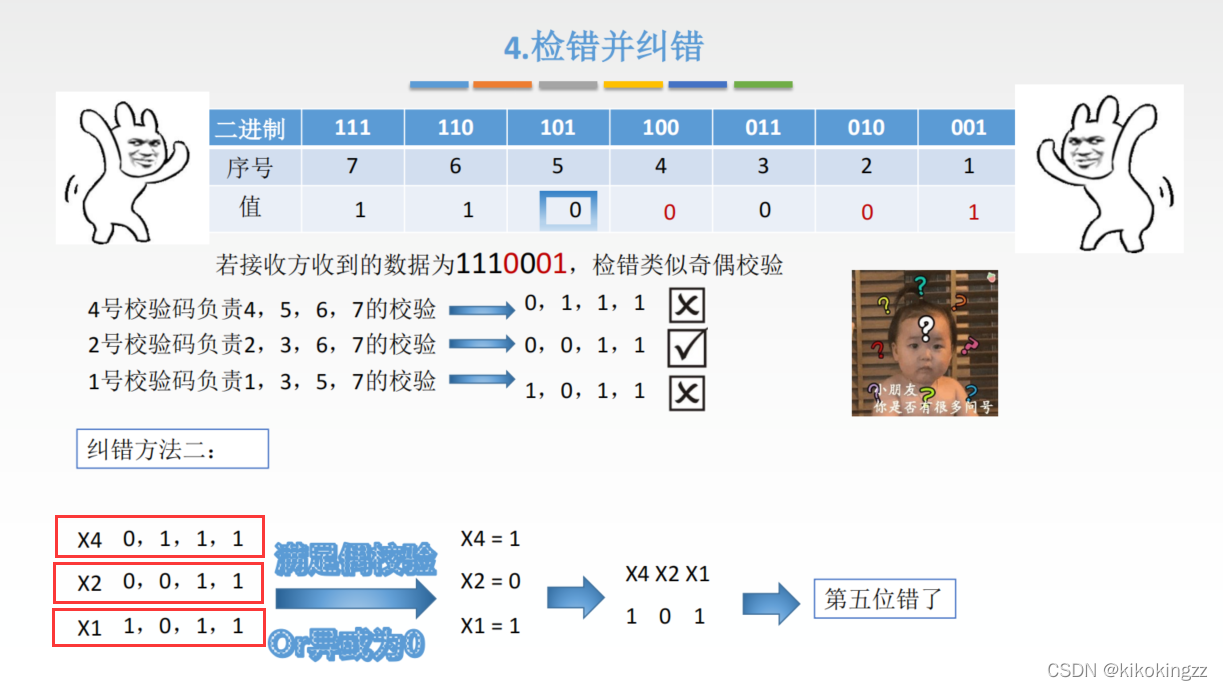
📜习题检测
** 📜136.题目难度 ⭐️⭐️**
136.为了避免传输过程中帧的丢失,数据链路层采用的方法是( )。 A.帧编号机制 B.循环冗余校验码 C.汉明码 D.计时器超时重发🍊详细题解:
A:为保证接收方不会接收到重复帧,需要对每个发送的帧进行编号。
B/C:汉明码和循环冗余校验码都用于差错控制。
D:为防止在传输过程中帧丢失,在可靠的数据链路层协议中,发送方对发送的每个数据帧设计一个定时器,当计时器到期而该帧的确认帧仍未到达时,发送方将重发该帧。
✅正确答案:D
📜137.题目难度 ⭐️
137.下列有关数据链路层差错控制的叙述中,错误的是( )。 A.数据链路层只能提供差错检测,而不提供对差错的纠正 B.奇偶校验码只能检测出错误而无法对其进行修正,也无法检测出双位错误 C.CRC校验码可以检测出所有的单比特错误 D.海明码可以纠正一位差错🍊详细题解:
A:链路层的差错控制有两种基本策略:检错编码和纠错编码。常见的纠错码有海明码,它可以纠正一位差错。
B:奇偶校验码只能发现单比特错,无法检测出双比特错误。
C:CRC校验码可以发现单比特错。
D:海明码发现双比特错,纠正单比特错。
✅正确答案:A
📜138.题目难度 ⭐️⭐️
138.下列关于循环冗余校验的说法中,( )是错误的。 A.带r个校验位的多项式编码可以检测到所有长度小于等于r的突发性错误 B.通信双方可以无须商定就直接使用多项式编码 C.CRC校验可以使用硬件来完成 D.有一些特殊的多项式,因为其有很好的特性,而成了国际标准🍊详细题解:
在使用多项式编码时,发送端和接收端必须预先商定一个生成多项式。发送端按照模2除法,得到校验码,在发送数据时把该校验码加在数据后面。接收端收到数据后,也需要根据该生成多项式来验证数据的正确性。因此B选项错误。
✅正确答案:B
📜139.题目难度 ⭐️⭐️
139.在数据传输过程中,若接收方收到的二进制比特序列为10110011010,接收双方采用的 生成多项式为G(x)=X^4+X^3+1,则该二进制比特序列在传输中是否出错? 如果未出现差错,那么发送数据的比特序列和CRC检验码的比特序列分别是什么?🍊详细题解:


** ✨✨✨我是分割线✨✨✨**
🥝功能4:流量控制
🍊1.什么是流量控制?
由于收发双方各自的工作速率和缓存空间的差异,可能出现发送方的发送能力大于接收方的接收能力的现象,如若此时不适当限制发送方的发送速率(即链路上的信息流量),前面来不及接收的帧将会被后面不断发送来的帧“淹没”,造成帧的丢失而出错。因此,流量控制实际上就是限制发送方的数据流量,使其发送速率不超过接收方的接收能力。
140.流量控制实际上是对( )的控制。 A.发送方的数据流量 B.接收方的数据流量 C.发送、接收方的数据流量 D.链路上任意两结点间的数据流量kiko🎃:流量控制是通过限制发送方的数据流量而使发送方的发送速率不超过接收方接收速率的一种技术;因此本题选A。
🍊2.为什么会产生流量控制机制?
这个过程需要通过某种反馈机制使发送方能够知道接收方是否能跟上自己,即需要有一些规则使得发送方知道在什么情况下可以接着发送下一帧,而在什么情况下必须暂停发送,以等待收到某种反馈信息后继续发送。
kiko🎃:讲道理,停等协议、滑动窗口协议的本质都是接收方返回一个ACK来告知接收方“我跟得上你,我现在可以接受你的下一帧”,或者“我跟不上你了,有一帧我没收到,后面的就别再发啦~”等这类信息。
🍊3.与传输层的流量控制的区别
流量控制并不是数据链路层特有的功能,许多高层协议中也提供此功能,只不过控制的对象不同而已:
- 对于数据链路层来说,控制的是相邻两结点之间数据链路上的流量
- 对于运输层来说,控制的则是从源端到目的端之间的流量。
更多关于流量控制内容请看:【计算机网络】第七话·计算机网络的流量控制
📜习题检测
📜141.题目难度 ⭐️
141.下述协议中,( )不是数据链路层的标准。 A.ICMP B.HDLC C.PPP D.SLIP🍊详细题解:
A:网际控制报文协议(ICMP)是网络层协议。
B:HDLC一般指高级数据链路控制。
C/D:PPP是在SLIP基础上发展而来的,都是数据链路层协议。
✅正确答案:A
📜142.题目难度 ⭐️⭐️
142.假设物理信道的传输成功率是95%,而平均一个网络层分组需要10个数据链路层帧来 发送。若数据链路层采用无确认的无连接服务,则发送网络层分组的成功率是( )。 A.40% B.60% C.80% D.95%🍊详细题解:
✅正确答案:B
📜143.题目难度 ⭐️⭐️⭐️
143.数据链路层协议的功能不包括( )。 A.定义数据格式 B.提供结点之间的可靠传输 C.控制对物理传输介质的访问 D.为终端结点隐蔽物理传输的细节🍊详细题解:
A:数据链路层的主要功能包括组帧,组帧即定义数据格式,A正确。
B:数据链路层在物理层提供的不可靠的物理连接上实现结点到结点的可靠性传输,B正确。C:控制对物理传输介质的访问由数据链路层的介质访问控制(MAC)子层完成,C正确。
D:数据链路层不必考虑物理层如何实现比特传输的细节,因此D错误。
✅正确答案:D

** ✨✨✨我是分割线✨✨✨**
🥝功能5:链路管理
数据链路层连接的建立、维持和释放过程称为链路管理,它主要用于面向连接的服务。
链路两端的结点要进行通信,必须首先确认对方已处于就绪状态,并交换一些必要的信息以对帧序号初始化,然后才能建立连接,在传输过程中则要能维持连接,而在传输完毕后要释放该连接。在多个站点共享同一物理信道的情况下(如在局域网中)如何在要求通信的站点间分配和管理信道也属于数据链路层管理的范畴。
📜144.题目难度 ⭐️⭐️
144.下列不属于数据链路层功能的是( )。 A.帧定界功能 B.电路管理功能 C.差错控制功能 D.流量控制功能🍊详细题解:
B:电路管理功能由物理层提供,数据链路层应当是“链路管理”。
✅正确答案:B

🌕写在最后
计算机网络世界是相当丰富的,内容方向繁多,但只要一步一个脚印,跟随【宇宙计划】,吃透、搞懂、拿捏住计算机网络内容是完全没有问题的!后期该系列还会有视频教程和经验分享,关于更多这方面的内容,请关注本专栏哦!
热爱所热爱的, 学习伴随终生,kikokingzz与你同在!❥(^_-)

版权归原作者 kikokingzz 所有, 如有侵权,请联系我们删除。