
目录:导读
前言
一般我们在刚介入一个项目时,我认为可以从如下几个方面来快速的上手压测工作。
熟悉业务特性
无论是做什么类型的测试工作,都脱离不了业务。
我们的被测对象,也是基于系统架构的用代码实现的高度具象的业务系统。
如果是专职做性能测试,或者刚介入一个全新的系统进行压测,想要短时间内了解业务细节是几乎不可能的。
但为了更好的快速开展工作,我个人的经验是快速熟悉业务特性,结合自己的经验对系统有个大致的了解。
什么是业务特性呢?可以参照下面几个例子:
电商下单业务:典型的先读后写类型,要考虑库存、事务的一致性,还有响应时间的范围;
大数据&报表业务:典型的读场景,可能会涉及到缓存或者消息队列,甚至是批处理;
金融风控信审业务:这种业务对响应时间没有太高的要求,但业务链路较长,不同系统间的交互要考虑;
语音识别搜索业务:涉及到语音文字的识别转换、准确率和命中率,计算密集型业务要更关注内存资源;
上述几个例子只是参考,其实最核心的思路在于:了解业务有什么特点,对响应时间、事务一致性的要求,可能的技术实现方式是什么,用到了什么技术组件,压测时要关注哪些指标。
熟悉系统架构
聊完业务特性后,被测系统的系统架构是一定要了解的。
因为我们的工作对象是具体的系统,而且压测要关注技术指标,关注请求处理的过程以及耗时等情况。
一般来说要了解被测系统的系统架构,可以通过如下几种方式:
系统架构图&网络拓扑图;
模拟几个请求,借助链路追踪工具来绘制请求链路;
如果都没有,通过监控观察请求的变化,挨个摸底;
看业务需求的prd,了解业务之间的关系,然后映射到具体的服务和接口;
在具体工作中要灵活变通,而且这种对系统架构摸底和请求链路的了解过程,也是个人快速学习和成长的过程。
团队工作方式
团队工作方式,不仅限于性能测试团队或者测试团队,而是从需求到发布整个软件研发过程各个团队是如何协同配合的。
刚进入一个新的团队或者介入一个新项目时,可以从下面几个方面去熟悉。
主要包括:
流程:包含需求评审、提测、UAT、灰度和生产发布等主要流程以及时间节点;
环境:开发环境、测试环境、UAT环境以及生产环境,主要涉及域名、权限、负责人等;
基础工具:配置中心、注册中心、需求&缺陷管理平台、CICD流水线工具、监控分析工具等;
测试工具:包含压测工具、抓包工具、造数工具、mock工具、文档管理工具、协作办公沟通工具等;
测试方法:之前怎么做压测?对指标有没有标准或定义?测试方案测试报告的撰写要求等;
协作人员:不同业务域或者业务系统的研发/运维/DBA是谁,跨团队的沟通协作方式等;
测试环境
以日常的压测场景展开来说,正常压测都是在测试环境展开的。
那么是选择功能测试环境,还是独立的性能测试环境呢?
功能测试环境通常具备这几个特点:
发布频繁;
功能&服务不稳定;
测试场景较多且交叉影响较大;
而性能测试一次压测运行的时间相对较长(短则10min长则12小时甚至几天),且为了获得误差较小的压测结果,性能测试对服务的稳定性要求较高。
因此我建议如果有条件,还是搭建一套独立的性能测试环境更好。
搭建独立的性能测试环境要注意如下几点:
独立的域名或请求入口;
应用服务器配置和生产保持一致;
应用服务数量可以最小化(生产是集群,测试环境1台服务器部署1个服务);
边缘服务&弱依赖服务&高性能服务(全读缓存,rt几毫秒)可以考虑1台服务器部署多个应用服务或者mock解决;
缓存、消息队列、数据库配置按比例降低(比如一个mysql实例,4C8G/8C16G足以满足日常压测需要);
服务的发布版本要注意如下亮点:
本次测试范围内的服务,发布对应的分支;
本次测试范围外的服务,和生产版本保持一致;
测试数据
从某种程度上来说,测试数据也可以归纳到测试环境这个大的范畴中。
压测所涉及的数据,主要分为如下几种类型:
1、铺底数据
铺地数据可以理解为冷数据,因为正常的线上业务,数据库的表中一般是要存在一定的铺底数据的,如电商的库存数据,用户基础数据如电话号码、收货地址等。
在独立的性能测试环境中,也需要准备对应的铺底数据,因为SQL执行过程中,空表和大表对性能的影响还是很大的。
准备铺底数据,最常见的有如下2种方式:
从生产环境同步(需要进行敏感数据脱敏处理);
调用业务接口,用脚本批量生成写入(无需脱敏,符合业务逻辑即可);
2、热点数据
什么是热点数据?
比如用户的登录态信息(token)、比如优惠券、比如商品图片(常存储于CDN)。
我见过很多同学在压测时先压测登录接口,然后将登录后的token拿出来再传递给下一个请求,完全没必要这么麻烦。
可以先准备一批虚拟的测试账号,跑批登录,然后将token预热到缓存中,过期时间设置的比较长即可。
在后续的测试工作中,只需要在请求头中将token和userid按照对应顺序参数化到请求中即可。
压测的场景要符合实际的业务场景,但要考虑到效率和实现成本。
其他热点数据的准备也可以参照上述的方式,提前生成,然后预热到缓存(也有本地缓存或jar包方式)。
3、参数化数据
参数化数据指的是压测过程中脚本中需要引用到的数据。以电商业务来说,常见的有用户id、商品数据、库存数据、订单数据等。
准备参数化数据,最常见的有如下3种方式:
业务逻辑上强验证的,通过脚本跑批提前生成,再从数据库中拿出来使用;
简单的自增逻辑(如订单编号),可以通过压测工具提供的插件自增生成或写代码实现;
只校验字符串位数或不为空的场景,用随机数或uuid生成即可;
做完了上述的几点数据准备工作,最后要做的就是对数据可用性进行验证,看看它是否如预期满足压测需要。
下面是我整理的2023年最全的软件测试工程师学习知识架构体系图
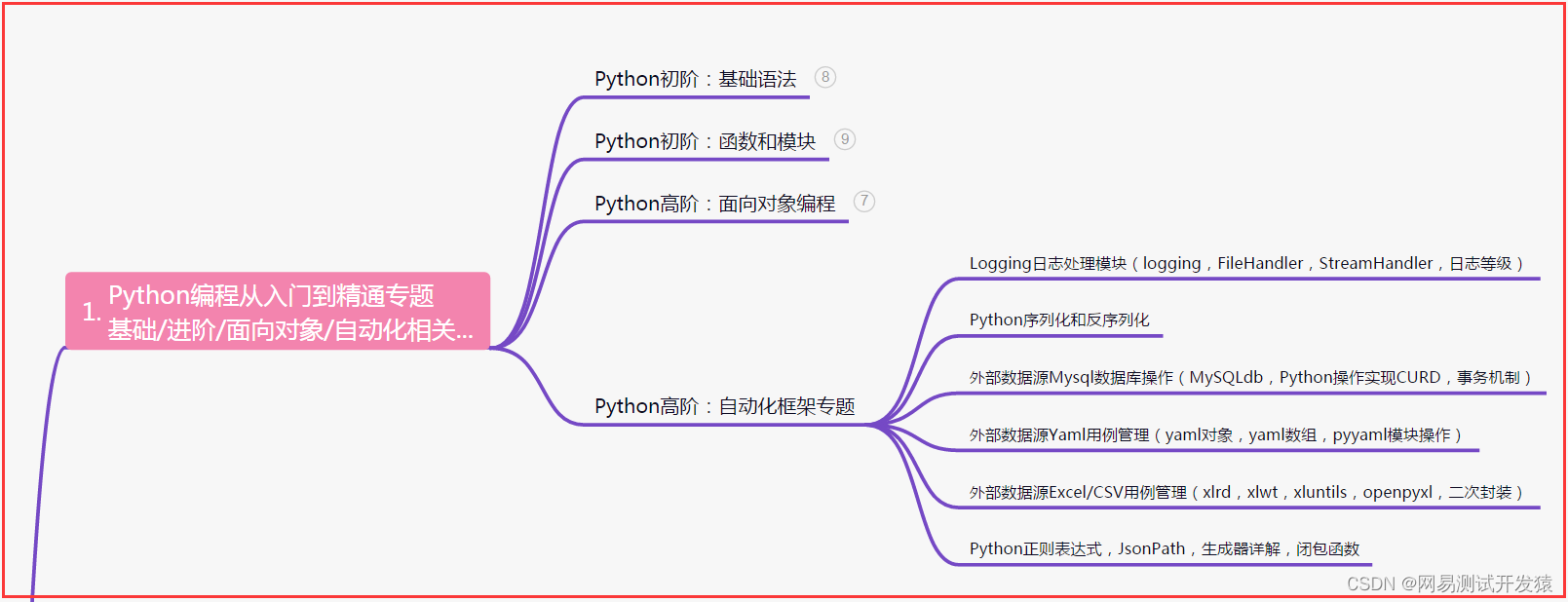
一、Python编程入门到精通
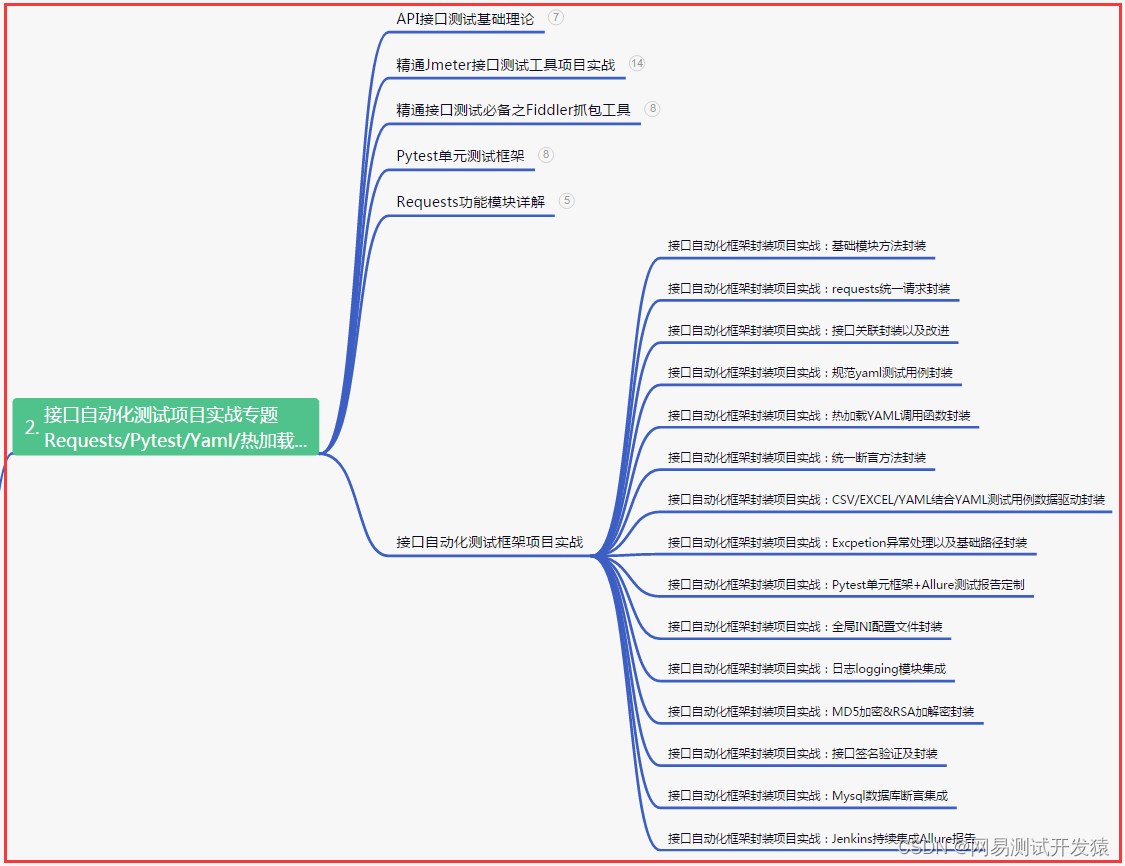
二、接口自动化项目实战
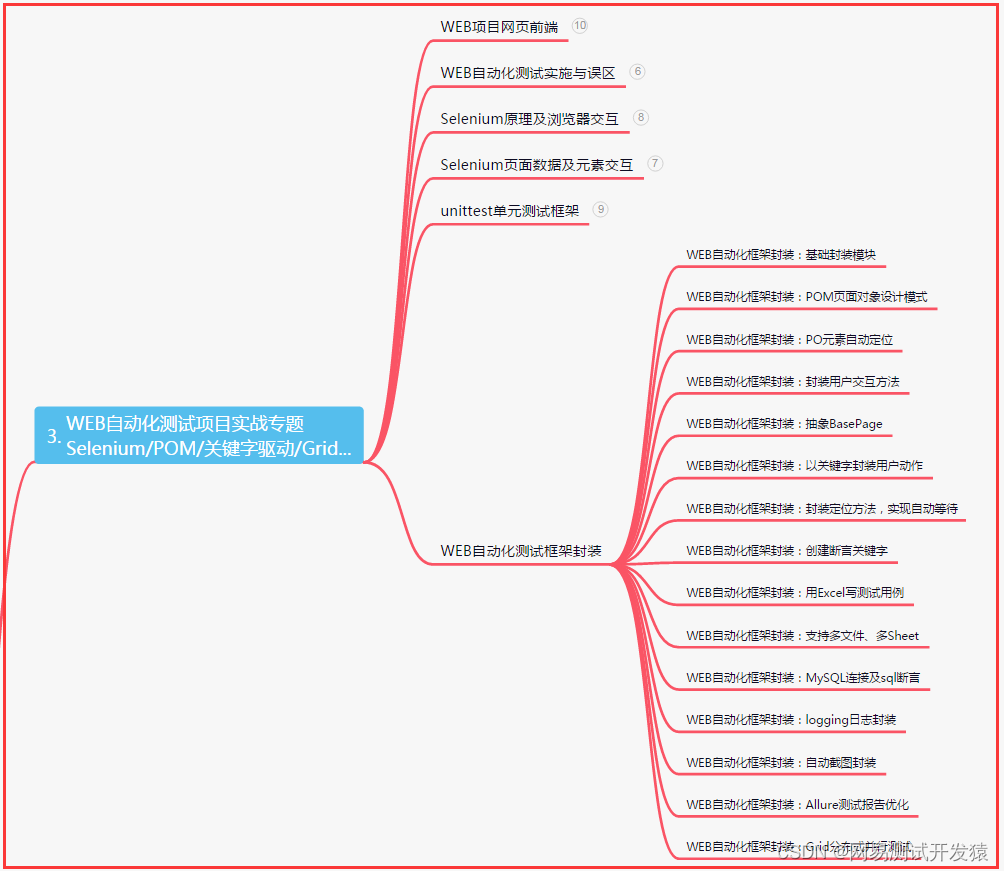
三、Web自动化项目实战
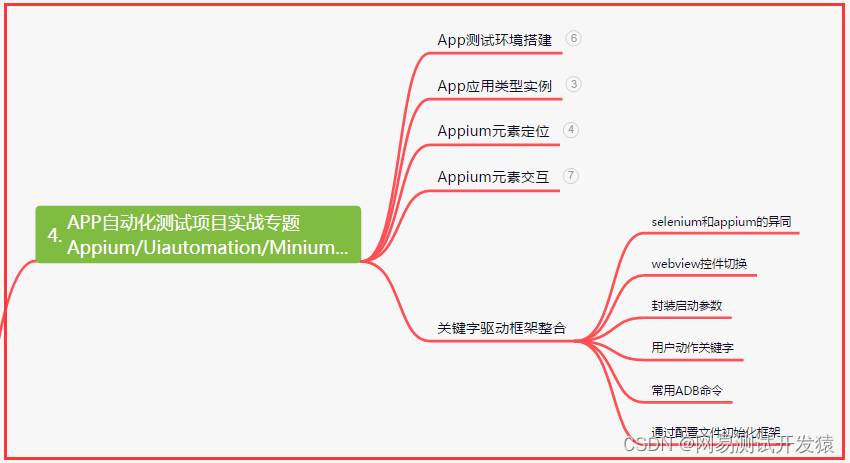
四、App自动化项目实战
五、一线大厂简历
六、测试开发DevOps体系
七、常用自动化测试工具

八、JMeter性能测试
九、总结(尾部小惊喜)
只要肯拼搏,天道酬勤。挫折和失败只是暂时的,不放弃才有机会成功。迎难而上,超越极限,拥抱未来,成就辉煌人生。
每一次努力都值得尊重,每一次坚持都值得赞扬。不要怕困难,不要怕失败,只要保持坚定的信念和毅力,成功就在不远处等待着你。
每个人都有无限的潜能,只是需要不断挑战自己才能发掘出来。不要因为失败而停下脚步,让每一次跌倒都成为你前进的动力,最终迎接成功的喜悦。
版权归原作者 网易测试开发猿 所有, 如有侵权,请联系我们删除。