
在应用、运维flink集群/作业时,我们需要通过各种flink的运行指标来了解集群/作业的运行状态,必要的时候还会针对关键指标设置监控告警。Flink Web Ui虽然在界面上提供了运行指标入口,但在应用上还是有不少不便之处:
1、每次查看指标时都要重新筛选关注的指标,不能模板化保存。
2、可以查看的数据周期有限,无法进行指标回溯或跟踪。
3、未与监控工具集成,不能告警。
在生产应用时,我们一般把flink的运行指标采集到外部的监控系统,如prometheus,再通过granfana进行指标可视化和告警设置。Flink提供了多种metrics reporter,可以将flink运行指标导出到外部系统,详情可见官方文档Flink Metric Reporters。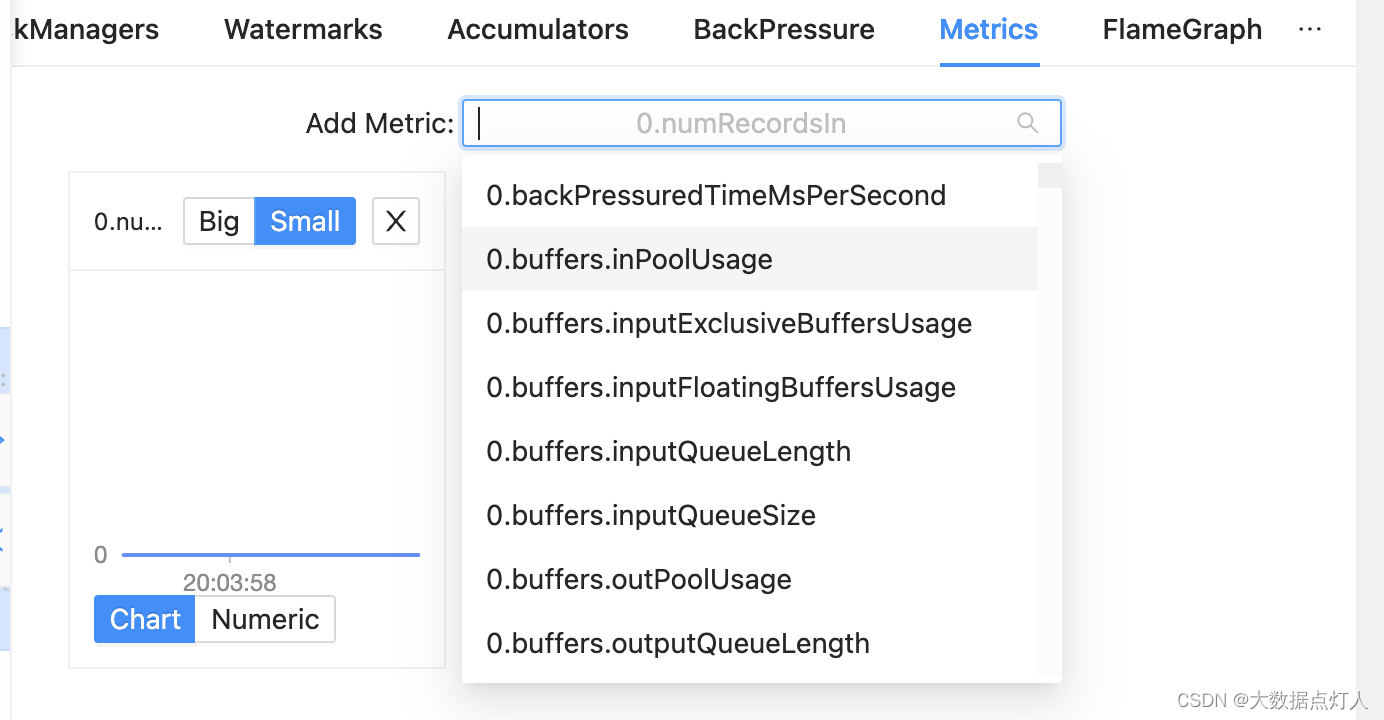
因为生产中,我们更常用的是prometheus+grafana指标监控体系集成。下面简单介绍导出flink运行指标到prometheus+grafana的方法与步骤。
一、Flink配置metric reporter
Flink提供两种reporter导出数据到prometheus,一种是pull方法reporter,这种reporter配置后将作为http服务接收外部请求并返回flink运行指标。另一种是push方法reporter,这种reporter主动写指标到外部的prometheus中。一般我们使用pull方法的reporter,这样可以一次配置即可支持不同的prometheus/服务查询数据。这里介绍的是pull方法的reporter。
Flink支持同时配置多种reporter,metrics.reporters配置不同的reporter名,多种reporter使用逗号分隔。reporter的参数通过"metrics.reporter.${reporter名}.${reporter参数}"这种形式进行配置。
在flink-conf.yaml中,增加以下配置开启prometheus reporter。
metrics.reporters: prom
metrics.reporter.prom.factory.class: org.apache.flink.metrics.prometheus.PrometheusReporterFactory
metrics.reporter.prom.port: 9020-9040
以上配置需要重启flink集群、作业生效。metrics.reporter.prom.port可以指定单个端口或范围端口。JM/TM混布需要使用范围端口以避免端口占用异常。
重启集群后可以地jm/tm的日志中看到reporter的信息。集群启动后可以通过curl flink_host:port查看指标。port是配置的9020-9040,可以通过netstats查看实际使用的是哪个端口。
curl localhost:9021 |head -3
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0# HELP flink_taskmanager_Status_JVM_Memory_Metaspace_Used Used (scope: taskmanager_Status_JVM_Memory_Metaspace)
# TYPE flink_taskmanager_Status_JVM_Memory_Metaspace_Used gauge
flink_taskmanager_Status_JVM_Memory_Metaspace_Used{host="flink1",tm_id="tm_01",} 9.9001824E7
二、prometheus配置指标读取
Flink配置成功后,需要在prometheus中配置指标读取。在prometheus.yml增加以下配置。
global:
scrape_interval: 15s # 全局的采集间隔,默认是 1m,这里设置为 15s
evaluation_interval: 15s # 全局的规则触发间隔,默认是 1m,这里设置 15s
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped - job_name: 'Flink'
static_configs:
- targets: ['flink01:9020']
labels:
group: jm
- targets: ['flink02:9021', 'flink02:9022']
labels:
group: tm
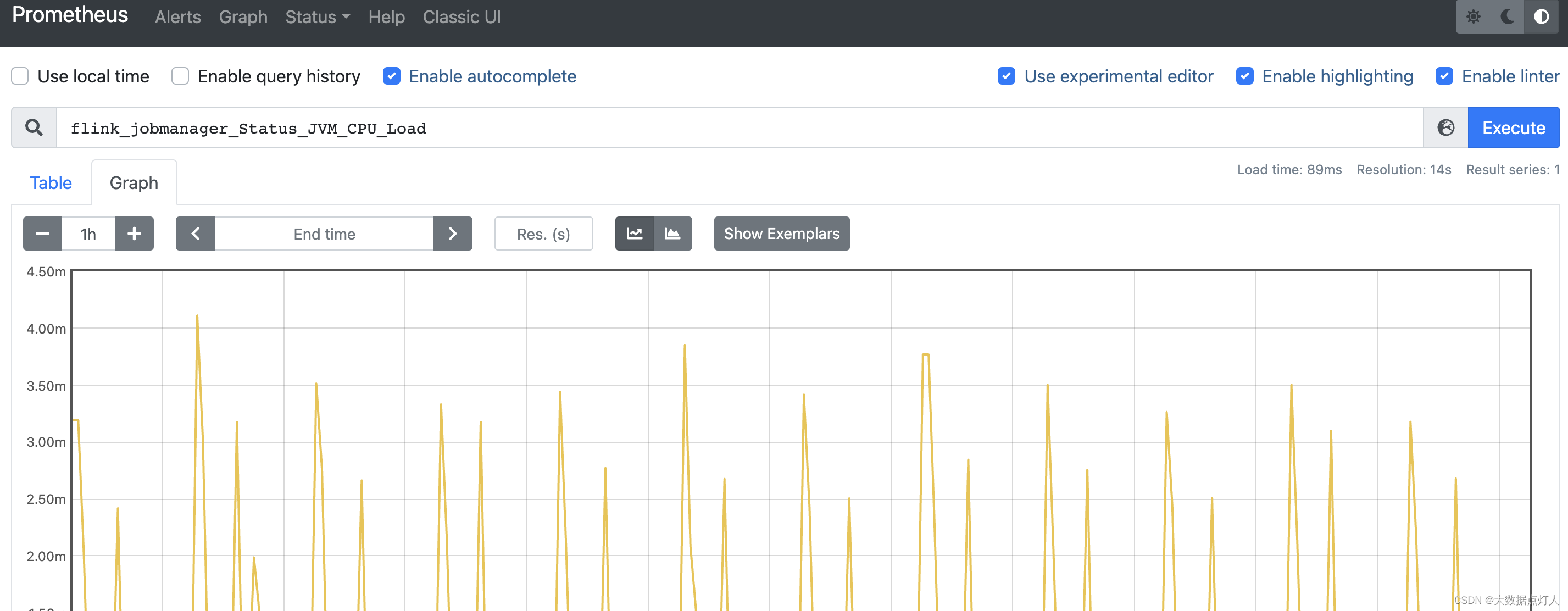
上面的配置中,将jobmanager和taskmanager分为不同的标签组,targets是我们在步骤一中配置的reporter地址和端口。配置完成后,需要重启prometheus以使配置生效,生效后可以在prometheus的ui上进行指标查询。
三、grafana配置Flink面板
在grafana上选择prometheus的数据源,创建指标面板。可以根据需要自行配置面板,或引用公开模型,直接import生成新的面板。Flink Grafana开发面板配置下载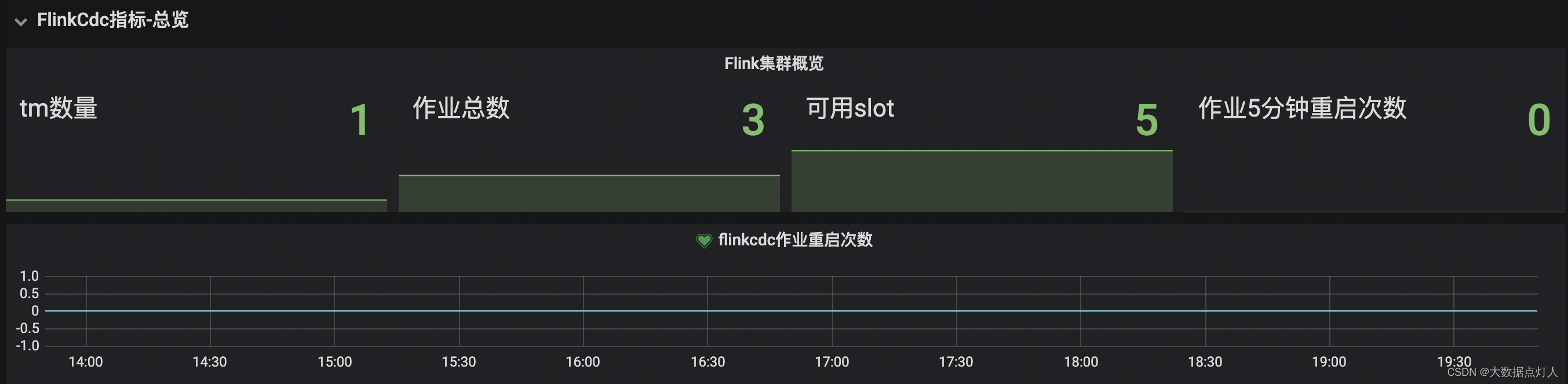
版权归原作者 大数据点灯人 所有, 如有侵权,请联系我们删除。