
目录
前言
关于java其他方面的知识点可看我之前的文章:
java框架零基础从入门到精通的学习路线(超全)
以下内容的学习主要来源于:
【尚硅谷】2022版Kafka3.x教程(从入门到调优,深入全面)
1. 入门kafka
应用场景举例:
前端浏览了网站,记录了数据(点赞、评论量等)变成日志,发送到日志服务器,日志服务器(通过Flume时刻监控服务器,只要一有数据变化)上传到Hadoop。
Flume(上传速度为100m/s左右)和Hadoop(采集速度小于100m/s,而且高峰期可能大于200m/s)两者的传输速率不同。可以增加一个kafka的中间件,将其大量的数据都放在kafka,之后将其数据与后面的Hadoop数据的速率保持一致即可
定义:
Kafka传统定义:分布式、基于发布/订阅(发布的消息分为不同类别,订阅者只接受感兴趣的消息,订阅者订阅的速度通过自身决定)的消息队列,主要用于大数据实时处理领域。
最新的定义:开源的分布式事件流平台、数据通道、流分析、数据集成和关键任务应用
消息队列:kafka(大数据)、ActiveMQ(JAVAEE)、RabbitMQ
功能:
- 解耦(只需保证生产者和消费者两侧的接口即可。也就是数据源放到消息队列中,之后消息 列将其对应的消息分发给消费者)
- 异步(例如注册信息,调用发送信息的接口(此处使用消息队列),内部核心的处理结果在后台,先回馈信息给客户)
- 消峰(数据量多,扛不住这么大的消息,可以将其缓存到消息队列中)
两种模式:
- 点对点(消费完之后MQ删除其信息)
- 发布/订阅(每个消费者相互独立、消费数据后不删除数据)
基础架构:(讲讲基本的框架流程)
分区主要是为了方便扩展,提高了吞吐量,一个topic分为多个partition(一个区可能存储不了所有的数据,所以只能分区)
一个分区的数据只能由一个消费者消费
保证数据的可用性,每个partition增加若干副本
生产者的leader挂掉之后,follower有条件升级为leader
还有一些数据是存储在zookeeper中
记录服务器节点的信息
每个分区的相关信息(谁是消费者,谁是生产者)
kafka2.8之后可以不用zookeeper
1.1 安装配置
关于这部分的安装可看我之前的文章:
Kafka在Linux服务器下载安装配置等详细图文版本(全)
多个服务器同时启动kafka,脚本如下:(对应的启动位置还有服务器名称替换成自已的即可)
#!/bin/bashcase$1in"start")foriin x,y,z
doecho"启动"ssh$i"/opt/module/kafka/bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties"done;;"stop")foriin x,y,z
doecho"停止"ssh$i"/opt/module/kafka/bin/kafka-server-stop.sh"done;;esac
1.2 命令操作
本身kafka有生产者、消费者、broker
对应每个模块都有它的启动配置
1.2.1 topic
执行bin/kafka-topics.sh内部有很多的option的操作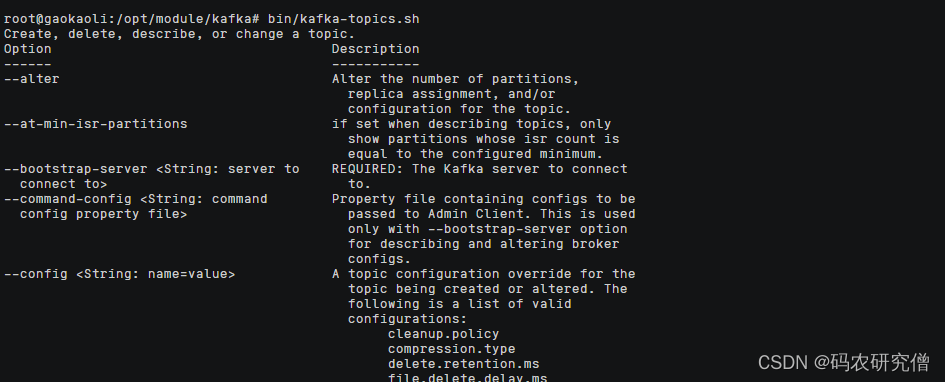
大致的option命令如下:
操作描述bootstrap-server<String: server to connect to>(可以写多个集群)连接kafka broker主机名称和端口号topic<String: topic>(可以执行增删改查)指定topic名称create增加topicdelete删除topicalter修改topiclist显示所有topicdescribe查看某个topic的详细信息partitions<Integer:#of partitions>设置分区数replication-factor<Integer: replication factor>设置分区副本config<String:name == value>更新系统默认的配置
主要的逻辑如下,连接kafka之后,指定某个topic进行增删改查,以及增加分区和副本数量,对某个分区进行升级等
使用的过程中如果出现问题可看这篇文章:
kafka创建、启动topic遇到的bug汇总 解决方法
bin/kafka-topics.sh 模块
- 查看对应的主题:
bin/kafka-topics.sh --bootstrap-server manongkafka:9092 --list(在配置文件中我的别名为manongkafka 也可使用localhost代表本机)
- 创建主题:
bin/kafka-topics.sh --bootstrap-server manongkafka:9092 --create --partitions 1 --replication-factor 1 --topic first(创建完主题之后还要创建分区以及指定副本)
对应查看topic以及详细的信息(副本数量此处我创建了一个)
- 查看topic的详细信息:
bin/kafka-topics.sh --bootstrap-server manongkafka:9092 --topic first --describe
分区数只能增加不能减少(减少的时候原先的混合在一起,导致不知道在哪个分区查找)
- 增加分区:
bin/kafka-topics.sh --bootstrap-server manongkafka:9092 --topic first --alter --partitions 3
副本的数量也可增加(但是此处不能使用命令行增加)
- 删除topic:
bin/kafka-topics.sh --bootstrap-server manongkafka:9092 --delete --topic first
1.2.2 生产者 消费者
具体通过configs目录下的
bin/kafka-console-producer.sh
大致命令:
bin/kafka-console-producer.sh --bootstrap-server manongkafka:9092 --topic first
参数描述–bootstrap-server <String: server toconnect to>连接 Kafka Broker 主机名称和端口号–topic <String: topic>操作的 topic 名称
连接集群,在某个集群中添加数据
生产者的数据打到了topic中,消费者消费对应的topic即可(消费者和生产者参数差不多)
通过configs目录下的
bin/kafka-console-consumer.sh
大致命令:
bin/kafka-console-consumer.sh --bootstrap-server manongkafka:9092 --topic first

一般数据都会保存在topic中,可以将其保存7天的数据都加载过来(但有些数据可能不会使用到),参数为:
--from-beginning
大致命令:
bin/kafka-console-consumer.sh --bootstrap-server manongkafka:9092 --topic first --from-beginning

2. 生产者
生产者如何发送数据到topic中
外部的接收数据发送给生产者,具体操作流程如下:
通过生产者工程的主线程,使用
send(ProducerRecord)
发送,经过拦截器(加工)、序列化器(一般使用自带)、分区器(哪个分区进行存储,一个分区创建一个队列,这些都是存储在内存中,默认缓冲队列是32m,一个batch为16k)
如下所示:
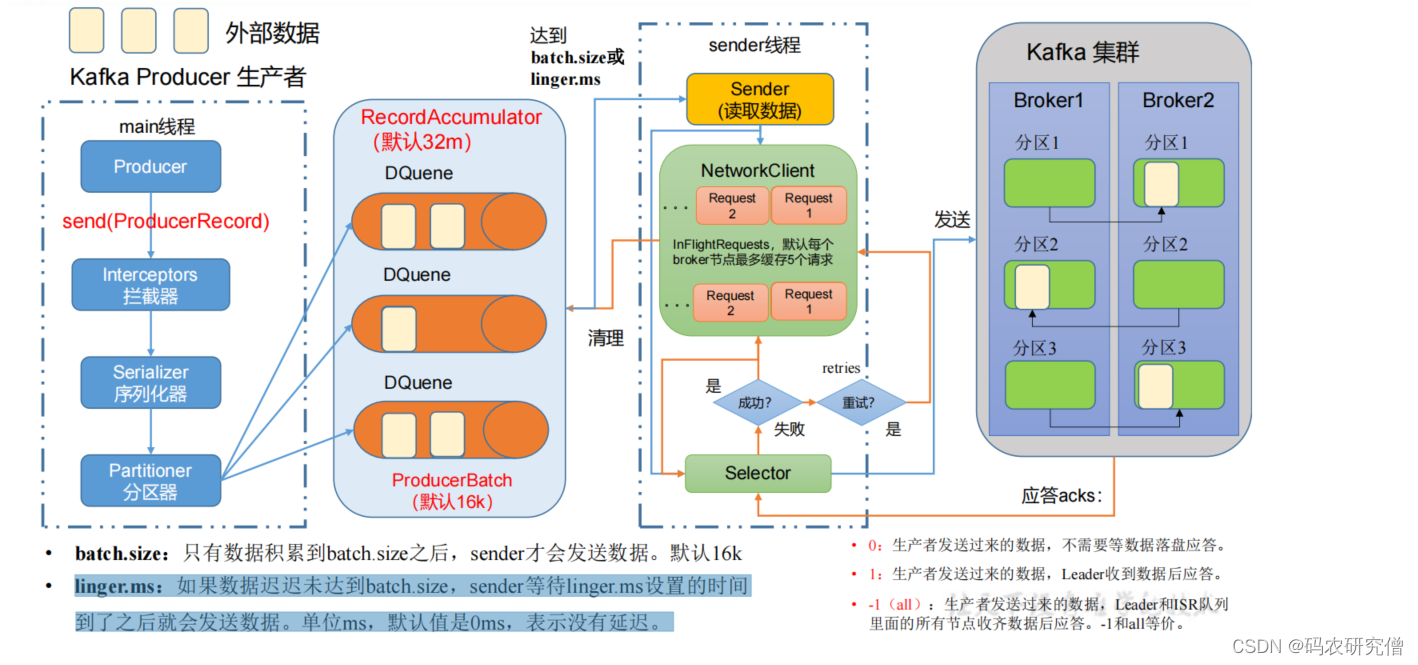
存放在队列中的数据,通过sender线程(拉取数据)
具体数据什么时间点拉取(通过数据量的大小以及等待数据的时间)
- batch.size:只有数据积累到batch.size之后,sender才会发送数据。默认16k
- linger.ms:如果数据迟迟未达到batch.size,sender等待linger.ms设置的时间到了之后就会发送数据。单位ms,默认值是0ms,表示没有延迟,也就是只要有数据,就会拉取数据(batch.size就会失效)
拉取数据到kafka的时候,本身要发送到kafka集群,以每个集群的节点为例,一个队列的数据发送的请求放在一个队列中存储,如果请求接收不到,一般还会在发送(超过5个没接收应答,就不会在拉取)。类似滑动窗口
收到数据之后一般都会有个应答机制(0 、1 和 -1),发送成功之后,会进行副本的复制,以及清除之前队列的数据。发送失败则会进行重试
- 0:生产者发送数据,不需要等数据到达后应答
- 1:生产者发送数据,Leader收到数据后应答
- -1(all):生产者发送过来的数据,Leader和ISR队列里面的所有节点收齐数据后应答,-1和all等价
主要的参数讲解:
参数描述bootstrap.servers连接集群所需的 broker 地址,如果有多个可用逗号隔开(并非需要所有地址,给定一个broker就可找到其他broker)key.serializer 和 value.serializer发送信息的key以及value序列化类型buffer.memoryRecordAccumulator 缓冲区总大小(默认 32m)batch.size缓冲区一批数据的最大值(默认16k),提高值可增加吞吐量,太高延迟会加大linger.ms数据没到达最大值,sender到达时间最大值会发送数据(默认0ms,无延迟)。production建议为5-100msacks默认是-1(all),还有0和1max.in.flight.requests.per.connection最多没返回的ack次数(默认5),开启幂等性要保证该值是 1-5 的数字retries发送错误会重发(设置此处,默认int最大值),若要保证有序性,需设置MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION=1retry.backoff.ms两次重试之间的时间间隔(默认100ms)enable.idempotence是否开启幂等性(默认true开启)compression.type生产者发送的所有数据的压缩方式(默认none不压缩),其他类型有:none、gzip、snappy、lz4 和 zstd
2.1 异步&同步 发送
何为异步通信和同步通信?
同步通信是全部所有任务都完成之后才能返回
异步发送是只要执行接口就可返回,具体核心函数不用执行到结束才返回
在kafka中的异步发送:外部数据发送到队列(不管数据有没到达kafka)
异步接口不带回调函数,(也就是在终端中没有返回值)
示例代码:
引入maven依赖文件
<dependencies><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>3.0.0</version></dependency></dependencies>
核心代码(此处的异步发送是没有回调函数的):
创建kafka生产者对象(再这之前需要配置 、连接服务器对应的topic 以及序列化)
publicclassCustomProducer{publicstaticvoidmain(String[] args){// 0 配置Properties properties =newProperties();// 连接集群 bootstrap.servers// 防止一个挂掉之后还可以启动另外一个//properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092,hadoop103:9092");
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"manongkafka:9092");// 指定对应的key和value的序列化类型 key.serializer,必须要配置这两个参数// StringSerializer.class.getName() 等同于它的全类名 org.apache.kafka.common.serialization.StringSerializer
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());// 1 创建kafka生产者对象// "" helloKafkaProducer<String,String> kafkaProducer =newKafkaProducer<>(properties);// 2 发送数据for(int i =0; i <5; i++){
kafkaProducer.send(newProducerRecord<>("first","码农研究僧"+i));}// 3 关闭资源
kafkaProducer.close();}}
启动之后,截图如下:

异步接口带回调函数:
发送函数send有两个,其中一个带有回调参数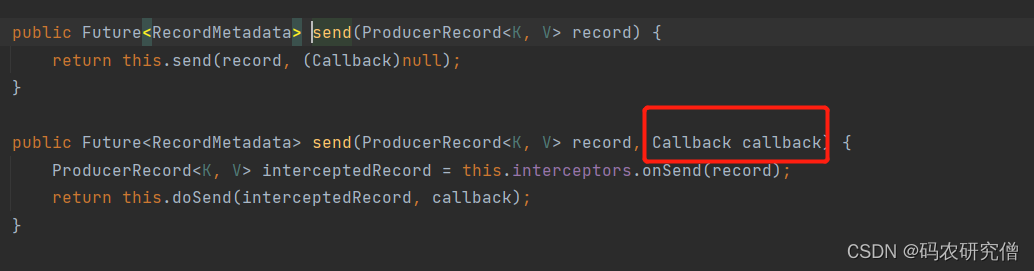
ProducerRecord有大致如下函数,参数有哪个分区哪个key、value等(在下述的分区中会讲这些函数的区别)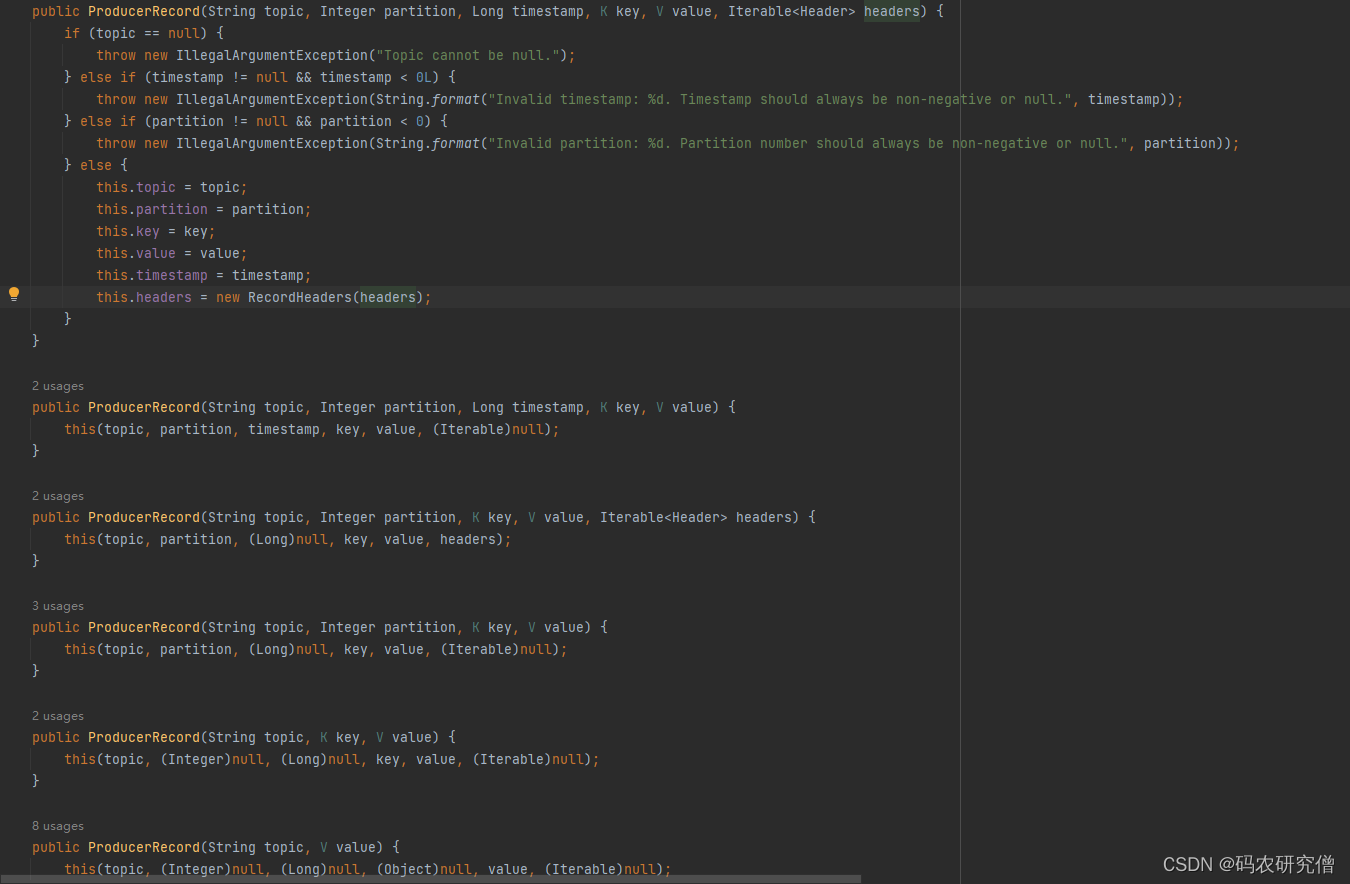
主要修改上面的核心代码:
// 2 发送数据for(int i =0; i <5; i++){
kafkaProducer.send(newProducerRecord<>("first","manongyanjiuseng"+ i),newCallback(){@OverridepublicvoidonCompletion(RecordMetadata metadata,Exception exception){if(exception ==null){System.out.println("主题: "+metadata.topic()+" 分区: "+ metadata.partition());}}});Thread.sleep(2);}
截图如下:
同步发送:
同样修改上面的核心代码,加入get函数捕捉
类似future线程,只不过这里通过get获取,等待异步调用的结果(需要发送完毕数据之后才会返回结果)
通过send函数发送到队列 ,再从队列发送到broker中来返回结果
// 2 发送数据for(int i =0; i <5; i++){
kafkaProducer.send(newProducerRecord<>("first","manongyanjiuseng"+i)).get();}
2.2 分区
数据过大不适合存放在一台服务器上,需要进行分区存储
分区好处:
- 合理使用存储资源:每个分区都在在一个Broker上存储,海量的数据按照分区切割成一块一块数据存储在多台Broker上(合理控制分区,实现负载均衡,容错性)
- 提高并行度(效率增加):生产者可以以分区为单位发送数据;消费者以分区为单位进行消费数据。
分区策略:(先看图)
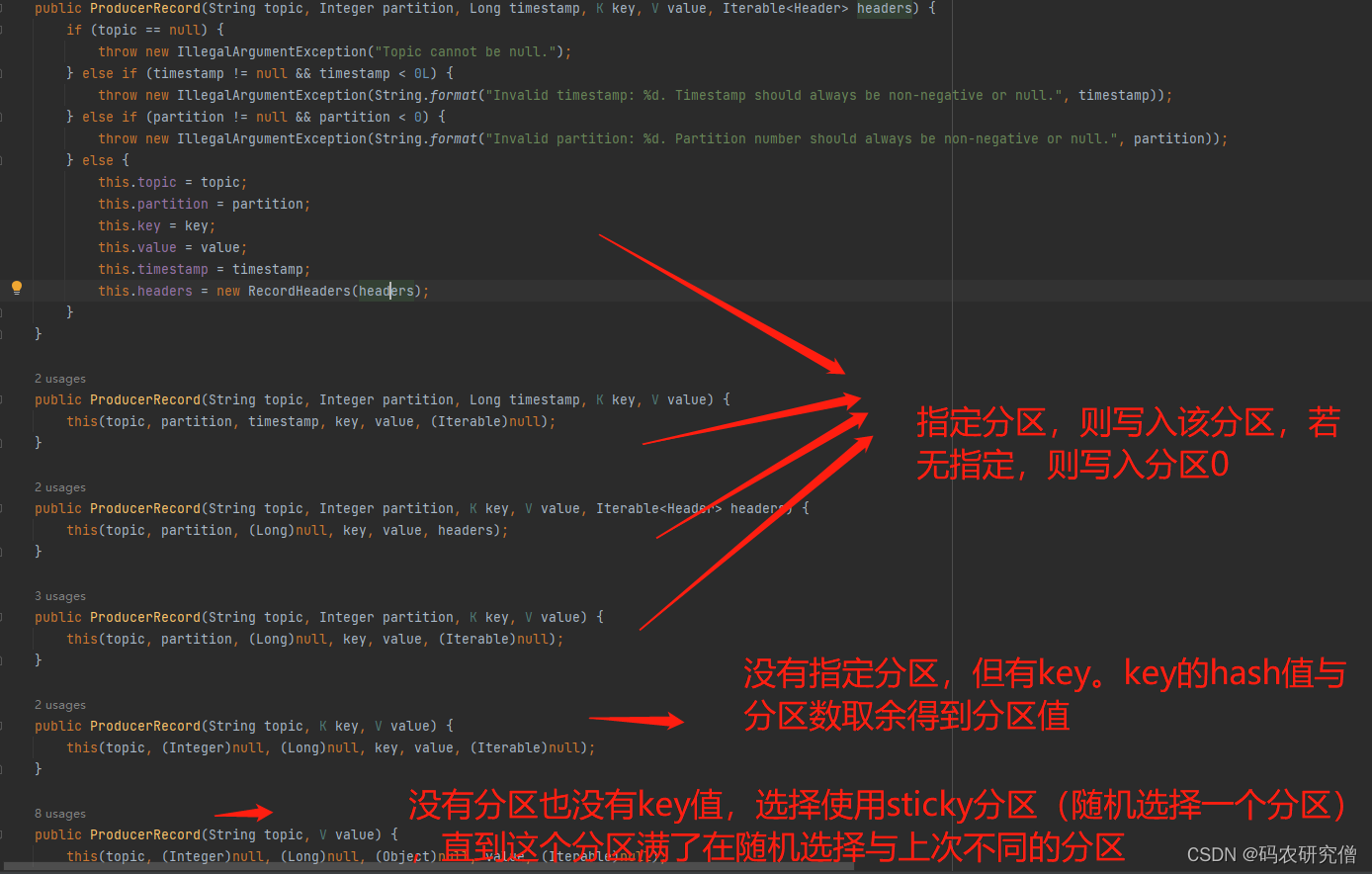
- 指定分区策略使用
比如指定分区数,不指定key(按照指定的分区发送)
// 2 发送数据for(int i =0; i <5; i++){
kafkaProducer.send(newProducerRecord<>("first",1,"","hello"+ i),newCallback(){@OverridepublicvoidonCompletion(RecordMetadata metadata,Exception exception){if(exception ==null){System.out.println("主题: "+metadata.topic()+" 分区: "+ metadata.partition());}}});Thread.sleep(2);}
- 没有指定分区,但是有key,则基于key进行hash(散列) key1的hash为5,key2的hash为6,分区数为2,则5%2为1分区,6%2为0分区
代码:
kafkaProducer.send(new ProducerRecord<>("first", "a","hello" + i),
。(这个在生产环境中用的比较多,将其服务作为key,对应放在同一个分区中)
- 没有分区也没有key,选择sticky分区(当这批数据已经满了) 第一次随机选择0号分区,当批次满了(默认16k)或者时间到了,在随机选择一个分区进行使用
代码:
kafkaProducer.send(new ProducerRecord<>("first", "hello" + i),
自定义分区:
背景:过滤的
码农研究僧
数据放到0分区,没有该数据在1分区
思路:继承Partitioner接口,主要是重写partition方法
publicclassMyPartitionerimplementsPartitioner{// 核心方法是这个// topic 、key、 序列化后的key、value、序列化之后的value@Overridepublicintpartition(String topic,Object key,byte[] keyBytes,Object value,byte[] valueBytes,Cluster cluster){// 获取数据 “码农研究僧”String msgValues = value.toString();// 定义分区变量int partition;if(msgValues.contains("码农研究僧")){
partition =0;}else{
partition =1;}return partition;}@Overridepublicvoidclose(){}@Overridepublicvoidconfigure(Map<String,?> configs){}}
配置kafka生产者对象的时候,需要再这之前将其自定义分区引入
// 关联自定义分区器// 后面的value值带的是 自定义分区的类名
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,"com.manong.kafka.producer.MyPartitioner");
大致插入的位置如下:
2.3 调优参数
代码模板:
// 创建properties,配置必须要的参数// 参数需要是连接kafka参数、key和value的序列化、配置缓冲区参数 批次大小 linger.ms等参数//1. 创建生产者 通过new KafkaProducer ,参数与需要是properties//2. 发送数据// 3. 关闭资源
2.3.1 吞吐量
- 0延迟,有数据就拉取(效率低,无延迟):默认0延迟的时候(linger.ms设置为0,范围为5-100ms),只要有数据就会拉取
- 有延迟,通过批次拉取(效率高,有延迟):设置延迟,结合batch.size(默认为16k),数据批次到达16k的时候,在拉取
基于以上的问题,具体优化如下:
提高吞吐量
- 一般会将其两者进行结合(batch.size设置为32k,默认是16k,linger.ms设置为2ms)
- 将其数据进行压缩(拉取的数据更加多了)
- RecordAccumulatator(缓冲区大小)修改为64m(但也有数据延迟)
对于压缩的方式:默认 none,可配置值 gzip、snappy、lz4 和 zstd
实际代码如下:(异步发送进行修改)
publicclassCustomProducerParameters{publicstaticvoidmain(String[] args){// 0 配置Properties properties =newProperties();// 连接kafka集群
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"manongkafka:9092,hadoop103:9092");// 序列化
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());// 缓冲区大小
properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG,33554432);// 批次大小
properties.put(ProducerConfig.BATCH_SIZE_CONFIG,16384);// linger.ms 毫秒需求
properties.put(ProducerConfig.LINGER_MS_CONFIG,1);// 压缩
properties.put(ProducerConfig.COMPRESSION_TYPE_CONFIG,"snappy");// 1 创建生产者KafkaProducer<String,String> kafkaProducer =newKafkaProducer<>(properties);// 2 发送数据for(int i =0; i <5; i++){
kafkaProducer.send(newProducerRecord<>("first","manongkafka"+i));}// 3 关闭资源
kafkaProducer.close();}}
步骤大致如下:创建生产者、发送数据、关闭资源
创建生产者参数要带入Properties类,所以一开始创建这个类的同时就要连接集群以及配置
2.3.2 可靠性
关于数据可靠的验证: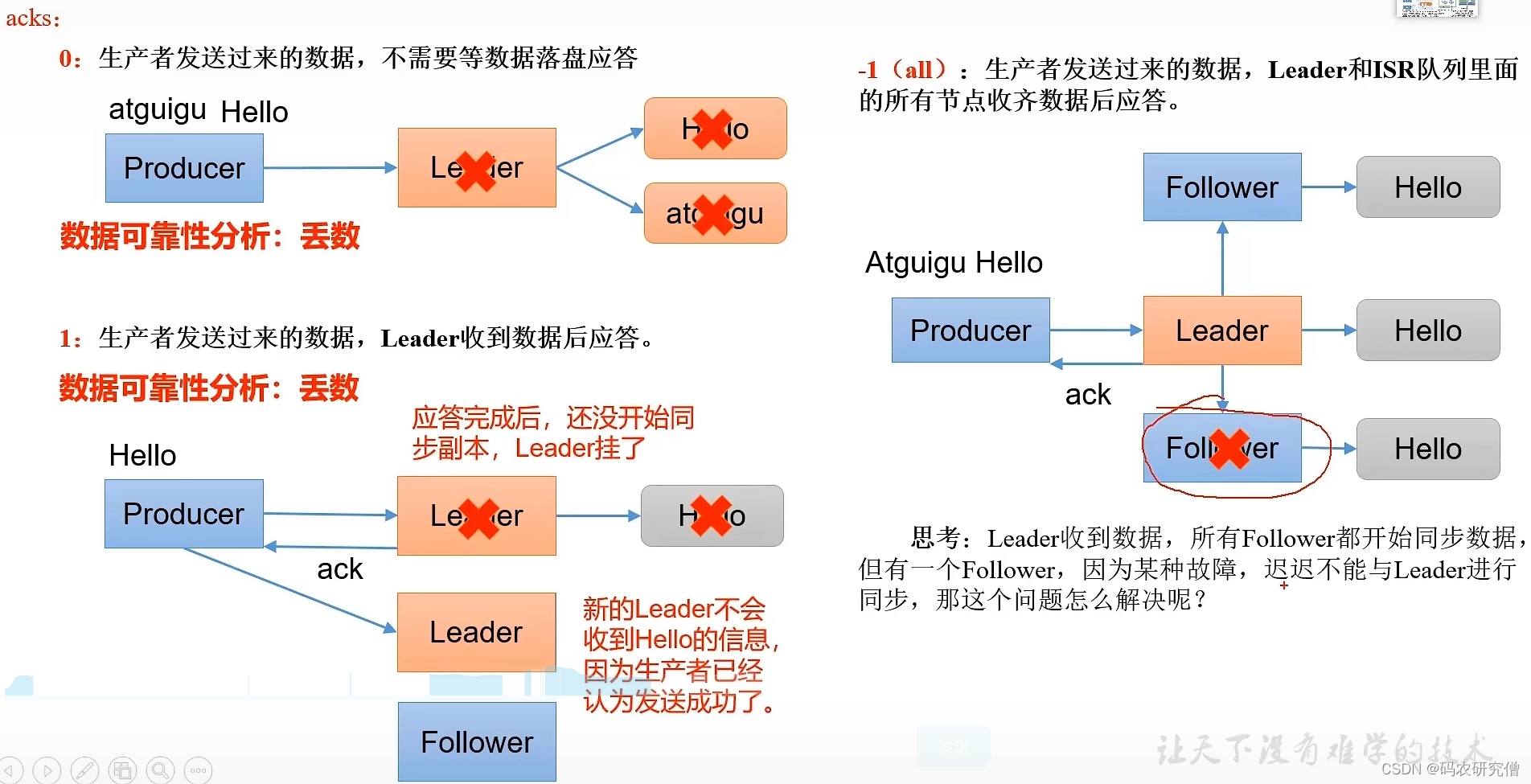
集群收到数据之后,一般会对数据进行应答
应答的方式有-1,0,1
- 0:生产者一直发送数据,不需要应答(可靠性比较低,效率最高)
缺陷:
leader挂掉之后,再次发送之后会出现数据丢失(没有数据的应答验证)
- 1:生产者发送数据,leader收到数据后进行应答
缺陷:
只有leader收到数据才应答,但是应答完之后leader挂了,某个follower变为leader之后(由于之前的数据已经默认收到了),所以新的leader不会再收到数据
- -1(等同于all):生产者发送数据,leader和isr队列里的所有节点收齐后再应答
缺陷:
leader以及ISR队列(所有节点都有这个数据)都收到所有节点才应答。但如果某个follower挂掉之后,所有follower以及leader都在同步数据,却因为某个follower不能与leader进行同步而延迟
解决方案:
对于第三种解决方案如下:·(心跳机制,动态的同步)
维持一种动态的ISR(和leader保持同步的follower+leader集合)
如果follower长时间(replica.lag.time.max.ms设置为30s,类似心跳机制)没有向leader发送请求或者同步数据,则该follower被踢出ISR,不用长时间等待故障节点
特殊情况:分区数副本只有一个,或者ISR副本只有一个。等同于ack=1,都会有丢失的情况
为了保证数据的可靠性,需要
分区副本大于等于2 + ISR里应答的最小副本数量大于等于2
总结
- ack为0,可靠性差,效率高(生产环境很少使用)
- ack为1,只与leader应答,可靠与效率中等(生产环境的应用在普通日志,丢失个别数据可接受)
- ack为-1,发送的数据要与leader以及ISR队列的所有follower应答,可靠性高,效率低(生产环境的应用在可靠性比较强的场景,支付),但是可能会造成数据的重复(数据接收到之后,原本要应答,但是leader挂掉之后,某个follower成为leader,数据又再次发送一遍)
在代码模块中如下:
// 设置ack
properties.put(ProducerConfig.ACKS_CONFIG,"1");// 如果接受不到,会进行重试,默认是int的最大值,2147483647
properties.put(ProducerConfig.RETRIES_CONFIG,3);
2.3.3 幂等性 事务性
- ack为-1,也就是all的时候,最少要发送一次。保证数据不丢失,但是不能保证数据不重复
- ack为0,只要leader应答即可,最多发送一次。保证数据不重复,但是不能保证数据不丢失
生产环境不能重复也不能丢失
kafka0.11版本之后引入了
幂等性和事务
幂等性(只能保证单分区会话的不重复)
幂等性就是指Producer不论向Broker发送多少次重复数据,Broker端都只会持久化一条,保证了不重复。
开启参数 enable.idempotence 默认为 true,false 关闭
通过如下标准判断数据的不重复:(
只能保证单分区的单会话不能重复
,一旦重启之后还是不能保证幂等性,所以下面会引入
事务
)
大致参数如下:
- PID:每次重启的时候都会配置一个新的(宕机之后又是发送一个一样的数据)
- Partition:分区号(分区之间有重复本身不影响)
- Sequence Number:单调自增
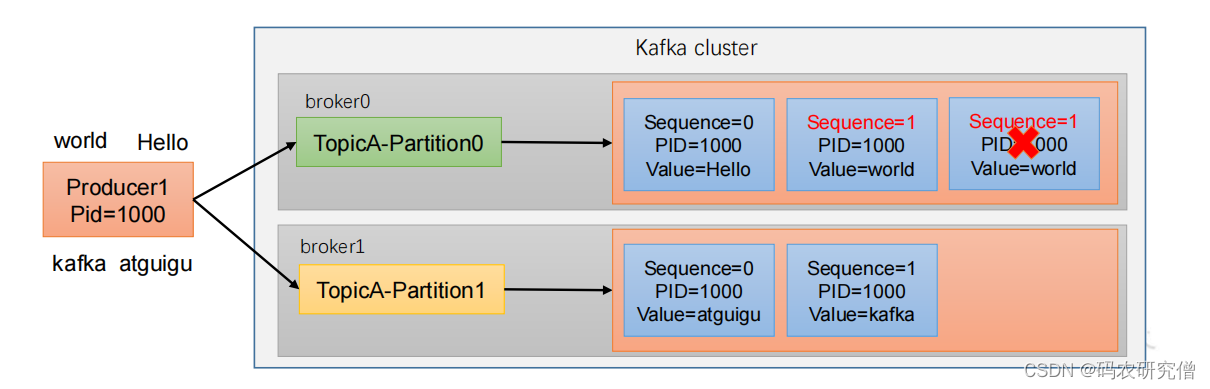
在生产环境中开启幂等性的参数:enable.idempotence默认本身就是true,false为关闭
事务性
不想产生任何一条数据,需通过事务性(前提是开启了幂等性)
宕机之后,pid又是一个新值,为此通过事务的全局id
原理:
kafka生产者 在事务协调器中 请求一个pid,并且返回pid给生产者
协调器会将其请求持久化(这个请求是生产者发送的提交请求),后台发送提交请求到主题分区中(再这之前生产者发送的消息到主题中),主题分区返回成功值之后,协调器会将其成功的信息持久化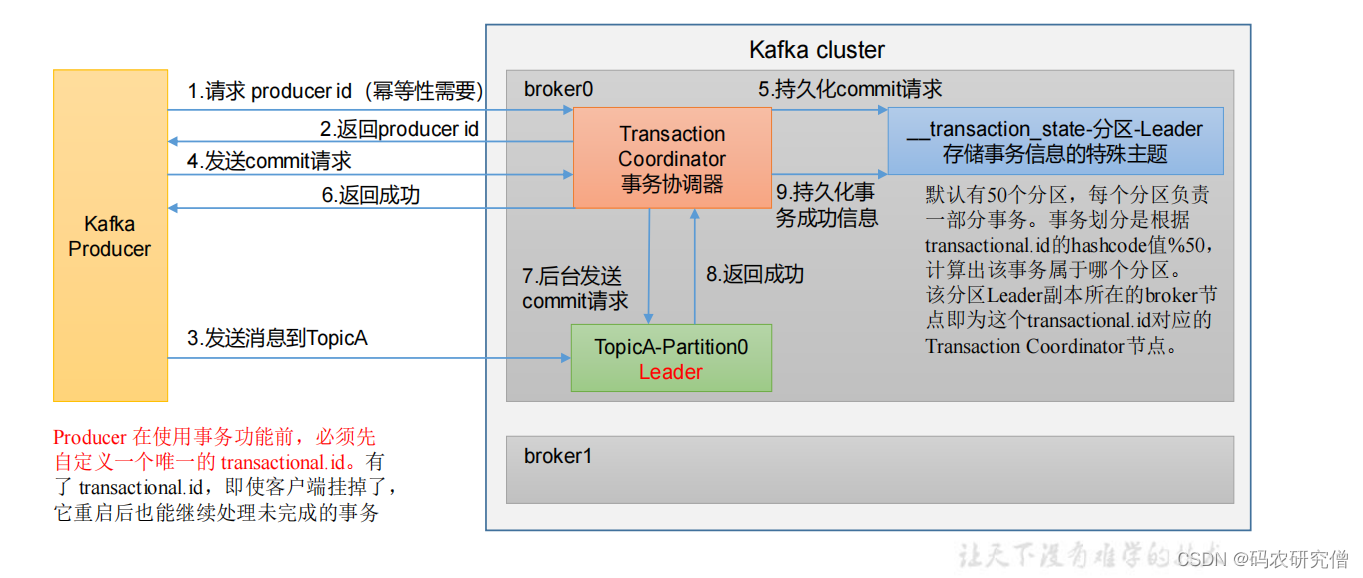
具体逻辑代码如下:
- 手动指定事务id(保证全局唯一)
- 初始化事务
- 开启事务
- 通过try 发送数据 来 提交事务
- 出现catch 则放弃事务
// 指定事务id,随便取,保证事务唯一即可
properties.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG,"tranactional_id_01");// 1 创建kafka生产者对象// 再这之前还有连接的一些参数KafkaProducer<String,String> kafkaProducer =newKafkaProducer<>(properties);// 初始化事务
kafkaProducer.initTransactions();// 开启事务
kafkaProducer.beginTransaction();try{// 2 发送数据for(int i =0; i <5; i++){
kafkaProducer.send(newProducerRecord<>("first","manong"+ i));}// 成功的话提交事务
kafkaProducer.commitTransaction();}catch(Exception e){// 失败的话放弃事务
kafkaProducer.abortTransaction();}finally{// 3 关闭资源
kafkaProducer.close();}
2.3.4 顺序性
本身生产者给broker发送的时候,消费者在拉取
单分区是有序的(有条件)
多分区的分区间是无序的
单分区有序的条件:
- kafka1.x版本以前:
max.in.flight.requests.per.connection=1(不需要考虑是否开启幂等性) - kafka1.新版本之后: 未开启幂等性:
max.in.flight.requests.per.connection=1开启幂等性:max.in.flight.requests.per.connection需要设置小于等于5
之所以开启幂等性之后可以保持有序,在kafka会缓存生产者发来的最近5个请求的元数据,之后发送的时候会对比当前的5个数据,保证最近5个请求的数据都是有序的
3. Broker
以下章节做了整体顺序的调换
3.1 工作原理
kafka中是如何存储数据的,以及如何和zookeeper之间通信
关于zookeeper的补充知识点可看我这篇文章:Zookeeper从入门到精通(全)
对应环境的安装可看这篇文章:Zookeeper的安装配置详解(window / linux)
安装好zookeeper之后通过
bin/zkCli.sh
启动客户端,使用
ls /kafka
查看kafka相关信息
- 记录有哪些服务器:
ls /kafka/brokers/ids - 谁是leader以及服务器可用:
ls /kafka/brokers/topics/节点/partitions/分区号/state例子:ls /kafka/brokers/topics/first/partitions/0/state - 辅助选举leader:
ls /kafka/controller(每一个节点的信息都有controller)
broker的总体流程,也可以说是选举流程
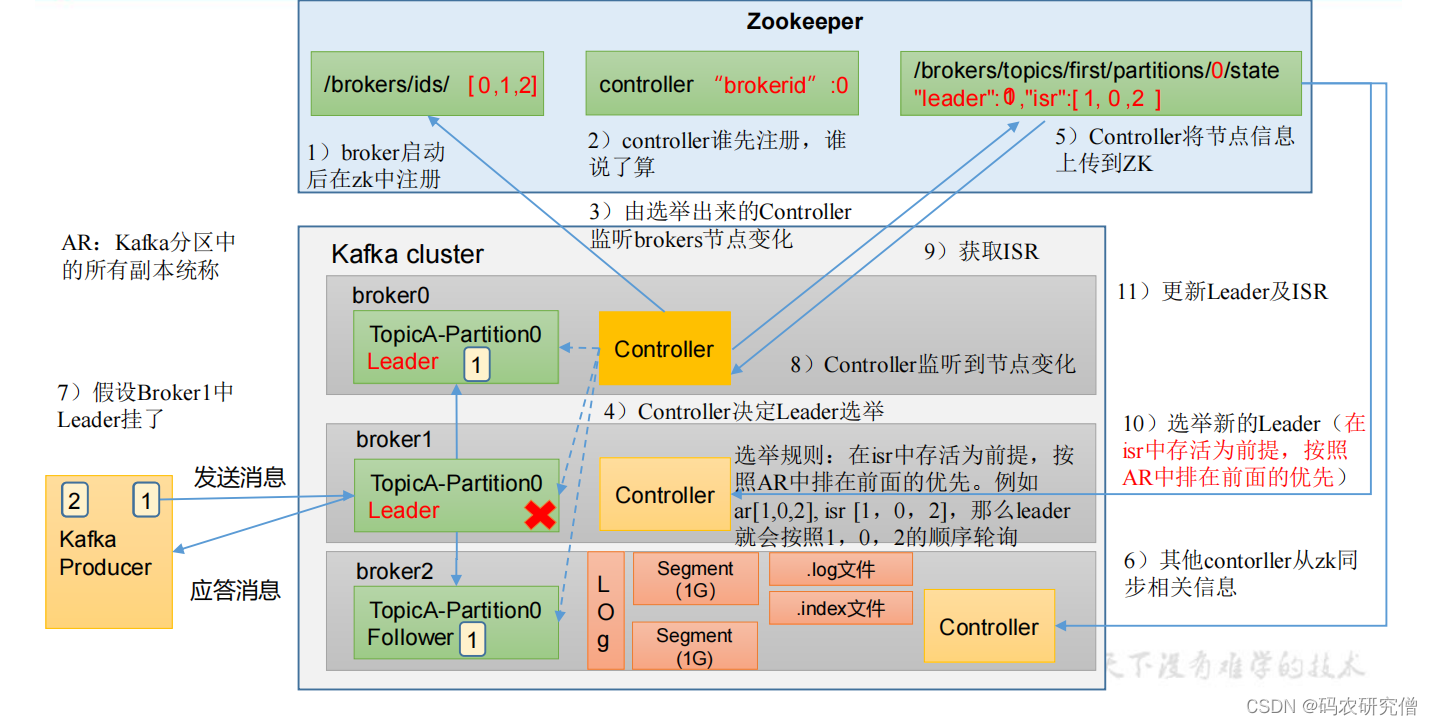
- 启动broker后再zookeeper中注册,将其对应的节点都放在/brokers/ids
- controller节点(controller节点谁先注册谁是leader),选举为leader之后,将其放置在controller节点的brokerid中,选举出来的节点通过controller监听brokers节点变化
- controller节点决定leader选举(选举规则,以isr队列存活为前提,按照AR(分区中的所有副本统称)排在前面的优先,比如AR【1,0,2】,ISR【1,0,2】,则leader按照102的顺序轮询)
- controller将其节点上传到zookeeper节点,后其他controller节点从zookeeper节点同步相关信息
如果broker节点的leader节点挂了,则controller节点监听到节点变化,会获取ISR先关信息,选取新的leader(isr存活为前提,按照AR前面的优先)
具体的测试:
将其对应的服务器节点关闭,通过describe查看节点的leader以及follower信息
- 开启:
bin/kafka-server-start.sh -daemon config/server.properties - 关闭:
bin/kafka-server-stop.sh - 查看:
bin/kafka-topics.sh --bootstrap-server manongkafka:9092 --describe --topic first
大致broker的参数如下:
参数名称描述replica.lag.time.max.ms默认30s,ISR 中,Follower 未向 Leader 发送通信请求或同步数据,会被被踢出 ISRauto.leader.rebalance.enable默认是 true, 自动 Leader Partition 平衡leader.imbalance.per.broker.percentage默认是 10%,每个 broker 允许的不平衡的 leader的比率。超出会发出不平衡值leader.imbalance.check.interval.seconds默认300 秒,检查 leader 负载是否平衡的间隔时间log.segment.byteslog 日志是分成一块块存储的,默认 1G(块状大小)log.index.interval.bytes默认 4kb,写入 4kb 大小的日志(.log),往 index 文件记录一个索引log.retention.hours数据保存的时间,默认 7 天log.retention.minutes分钟级别,默认关闭log.retention.ms毫秒级别,默认关闭log.retention.check.interval.ms检查数据是否保存超时的间隔,默认是 5 分钟log.retention.bytes默认等于-1,表示无穷大。超过设置的所有日志总大小,删除最早的 segmentlog.cleanup.policy默认是 delete,表示所有数据启用删除策略;为 compact,表示所有数据启用压缩策略num.io.threads默认是 8。负责写磁盘的线程数。整个参数值要占总核数的 50%num.replica.fetchers副本拉取线程数,占总核数的 50%的 1/3num.network.threads默认是 3。数据传输线程数,占总核数的50%的 2/3log.flush.interval.messages强制页缓存刷写到磁盘的条数,默认是 long 的最大(不建议修改)log.flush.interval.ms每隔多久,刷数据到磁盘,默认是 null(不建议修改)
3.2 节点增删
节点新增:
克隆服务器相关节点的信息或者重新开设一个服务器(安装jdk、zookeeper、kafka)
以下为克隆某个节点的信息:
- 需要修改ip地址:
vim /etc/sysconfig/network-scripts/ifcfg-ens33,(云服务器忽视这一选项) - 修改主机名:
vim /etc/hostname(修改主机名) - 删除kafka目录下的datas以及logs日志(否则会与克隆节点相冲突)
- 修改brokers.id,通过
vim /config/server.properties
之后启动克隆的这个节点机器
但是节电机器启动之后,不知道要负载均衡那个topic,所以有了如下操作
选择已经启动的旧节点,将其新机器加入:
vim topics-to-move.json
{"topics":[{"topic":"first"},......],"version":1}
生成负载均衡计划:
bin/kafka-reassign-partitions.sh --bootstrap-server manongkafka:9092 --topics-to-move-json-file
topics-to-move.json --broker-list "0,1,2,3" --generate
执行这条命令之后会生成对应的均衡计划,将其也存储一份在副本中:
vim increase-replication-factor.json
类似的模板(根据实际情况):
{"version":1,"partitions":[{"topic":"first","partition":0,"replicas":[2,3,0],"log_dirs":["any","any","any"]},{"topic":"first","partition":1,"replicas":[3,0,1],"log_dirs":["any","any","any"]},{"topic":"first","partition":2,"replicas":[0,1,2],"log_dirs":["any","any","any"]}]}
执行副本的存储计划:
bin/kafka-reassign-partitions.sh --bootstrap-server manongkafka:9092 --reassignment-json-file
increase-replication-factor.json --execute
验证副本存储计划:
bin/kafka-reassign-partitions.sh --bootstrap-server manongkafka:9092 --reassignment-json-file
increase-replication-factor.json --verify
节点退出:(与节点新增大致思路)
服务器建立要退出topic:
vim topics-to-move.json
{"topics":[{"topic":"first"},......],"version":1}
创建执行计划:(生成对应的计划要用在副本计划中)
bin/kafka-reassign-partitions.sh --bootstrap-server manongkafka:9092 --topics-to-move-json-file
topics-to-move.json --broker-list "0,1,2" --generate
创建副本计划json(使用上面的生成的计划):
vim increase-replication-factor.json
{"version":1,"partitions":[{"topic":"first","partition":0,"replicas":[2,0,1],"log_dirs":["any","any","any"]},{"topic":"first","partition":1,"replicas":[0,1,2],"log_dirs":["any","any","any"]},{"topic":"first","partition":2,"replicas":[1,2,0],"log_dirs":["any","any","any"]}]}
执行副本存储计划:
bin/kafka-reassign-partitions.sh --bootstrap-server manongkafka:9092--reassignment-json-file
increase-replication-factor.json --execute
验证副本计划:
bin/kafka-reassign-partitions.sh --bootstrap-server manongkafka:9092 --reassignment-json-file
increase-replication-factor.json --verify
之后别忘记关闭对应服务器的节点信息:
bin/kafka-server-stop.sh
3.3 副本
副本保证可靠性,默认副本只有一个,生产环境一般配置2个
副本节点不能过多(增加磁盘存储空间也增加了传输数据传输)
副本分为leader以及follower,生产者数据只会发送leader,follower从leader同步数据
分区中所有的副本统称为AR(AR = ISR + OSR)
何为ISR以及OSR
- ISR:和leader同步的follower,如果长时间未同步,则会提出。默认30s(参数由replica.lag.time.max.ms)。如果leader未同步,则会从ISR选取新的leader
- OSR:未同步的follower,多数都是延迟过多的副本
分区副本分配:
如果设置的分区数大于副本数,对于的leader以及follower怎么分配各个节点(保证leader以及follower要负载均衡在对于的服务器节点)
创建一个新的topic(16个分区,3个副本):
bin/kafka-topics.sh --bootstrap-server manongkafka:9092 --create --partitions 16 --replication-factor 3 --topic second
查看对应的节点分配情况:
bin/kafka-topics.sh --bootstrap-server manongkafka:9092 --describe --topic second
发现16个分区的节点,会在对应的分区显示3个节点的各自信息(负载轮询)
部分截图如下: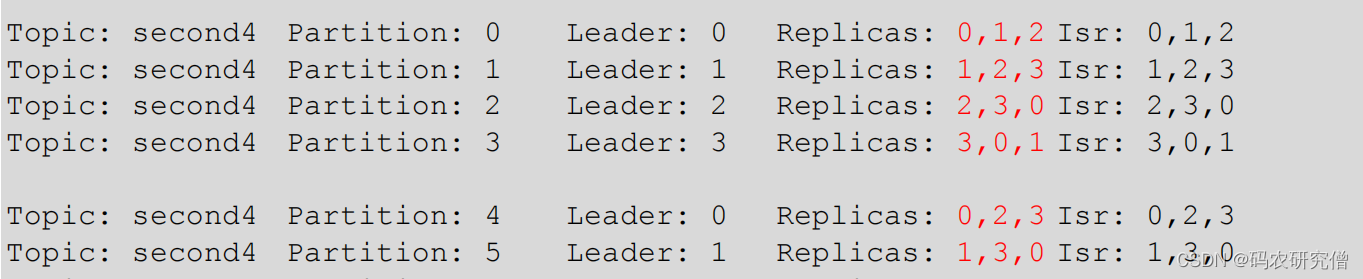
在生产环境下,对应的各个机器容量或者性能不一样(不能负载均衡在一些性能差的节点当leader,所以要手动调整)
默认这个是走不同的
# 一开始原始增加
bin/kafka-topics.sh --bootstrap-server manongkafka:9092 --create --partitions 4 --replication-factor 2 --topic three
# 后面又直接通过alter修改,这种行不通(×)
bin/kafka-topics.sh --bootstrap-server manongkafka:9092 --alter--partitions 4 --replication-factor 4 --topic three
正确答案是:
创建4个分区,2个副本。要平均分配在broker0以及broker1两台服务器
示例代码如下:
bin/kafka-topics.sh --bootstrap-server manongkafka:9092 --create --partitions 4 --replication-factor 2 --topic three
先查看各分区情况(负载轮询的分配):
bin/kafka-topics.sh --bootstrap-server manongkafka:9092 --describe --topic three
指定对应所有的副本到broker0以及broker1节点中:
vim increase-replication-factor.json
{"version":1,"partitions":[{"topic":"three","partition":0,"replicas":[0,1]},{"topic":"three","partition":1,"replicas":[0,1]},{"topic":"three","partition":2,"replicas":[1,0]},{"topic":"three","partition":3,"replicas":[1,0]}]}
执行上面的副本信息:
bin/kafka-reassign-partitions.sh --bootstrap-server manongkafka:9092 --reassignment-json-file increase-replication-factor.json --execute
验证其信息:
bin/kafka-reassign-partitions.sh --bootstrap-server manongkafka:9092 --reassignment-json-file increase-replication-factor.json --verify
3.4 故障处理
故障处理一般就是follower挂或者leader挂,如何恢复对应的数据节点
补充两个前沿知识:
- LEO(log end offset):每个副本最后一个offset,指向下一个offset+1。LEO = offset + 1
- HW(high watermark):所有副本中最小的LEO位置
follower故障: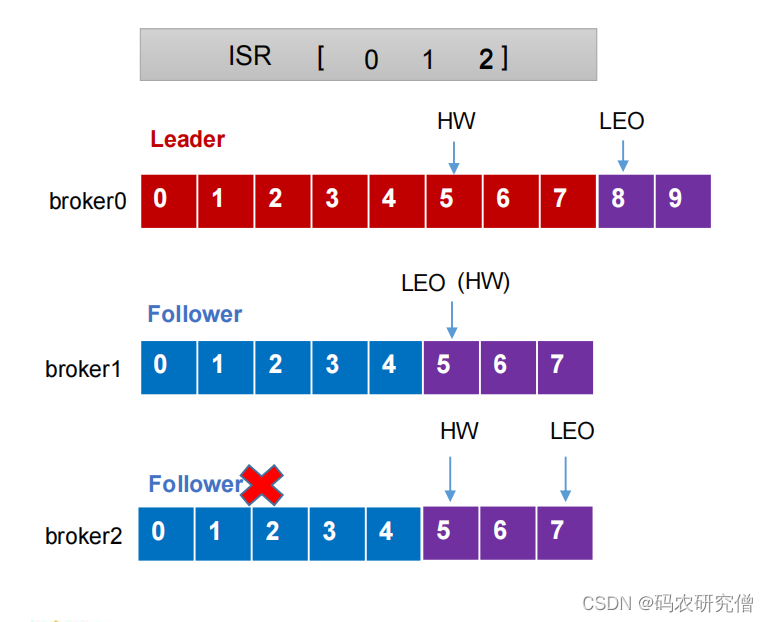
- broker2(follower)故障会被剔除ISR
- leader和broker1还是继续接收数据节点(leader的8 9 对应broker1的5 6 7)
- broker2恢复的时候,该节点会读取本地磁盘记录中上次的HW节点,并将log文件中高于HW的节点都截取掉(将位置为5 6 7截取),从HW开始向leader进行同步(同步信息5 6 7)
- 等到broker2的LEO大于等于该分区的HW(follower与leader差不多位置的时候),broker2才可以加入ISR
leader故障:
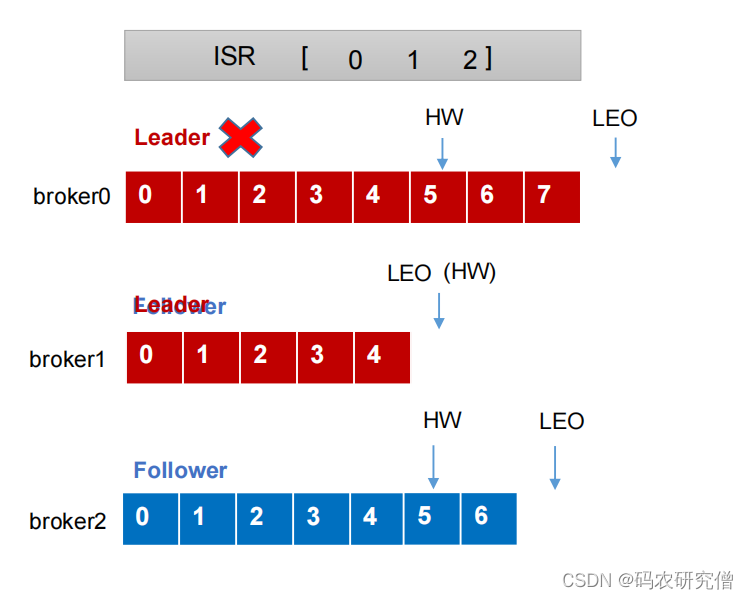
- leader故障之后,会在ISR选取一个新的leader出来
- 如果broker1节点被选为leader,则其余的follower会对应将各自log文件高于HW的部分截取掉(将 5 6截取),然后从新的leader同步数据
(只能保证数据的各个节点一致性,但不能保证数据的不丢失)
3.5 leader partition负载平衡
正常情况下,kafka默认会把leader分区均匀分布在各个机器,保证机器吞吐量均匀
如果broker宕机过后,leader就会一直在那几台broker,即使宕机之后恢复,也不会被选为leader,导致少数的leader那几台读写请求压力过高
参数描述auto.leader.rebalance.enable默认为true,自动自动Leader Partition 平衡。生产环境中,leader 重选举的代价比较大,可能会带来性能影响,建议设置为 false 关闭leader.imbalance.per.broker.percentage不平衡比率。默认为10%,超过就会触发调整leader.imbalance.check.interval.seconds检查是否平衡间隔时间,默认300秒
3.6 文件存储机制
Topic是逻辑上的概念,而partition是物理上的概念
每个partition对应于一个log文件,该log文件中存储的就是Producer生产的数据
- Producer生产的数据会被不断追加到该log文件末端,为防止log文件过大导致数据定位效率低下,Kafka采取了分片和索引机制, 将每个partition分为多个segment
- 每个segment包括:
“.index”文件、“.log”文件和.timeindex等文件。这些文件位于一个文件夹下,该文件夹的命名规则为:topic名称+分区序号,例如:first-0
大致文件意思如下:
文件名描述.log日志文件(以当前的segment的第一条消息的offset命名).index偏移量索引文件(以当前的segment的第一条消息的offset命名).timeindex时间戳索引文件,超过7天会删除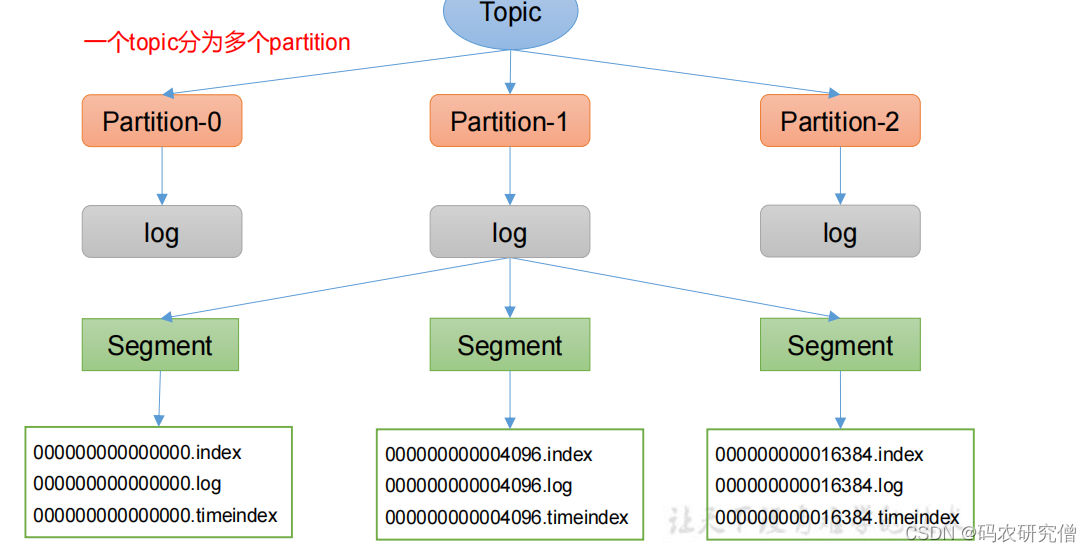
查看对应文件的信息的时候,发现log文件是序列化之后的(乱码)
具体查看对应文件通过如下:
kafka-run-class.sh kafka.tools.DumpLogSegments --files 文件名

本身index文件就是稀疏索引,往log文件超过4kb就会引入一条索引(参数log.index.interval.bytes默认4kb)
index保存的offset为相对offset,确保占用空间不会过大,将其值控制在固定大小
对于日志的存储参数如下:
参数描述log.segment.byteslog 日志是分块存储,块的大小默认为1Glog.index.interval.bytes默认 4kb,稀疏索引,超4kb加一条索引
3.7 文件清理策略
默认保存的日志时间为7天
参数描述log.retention.hours最低优先级,默认 7 天log.retention.minutes分钟log.retention.ms最高优先级毫秒log.retention.check.interval.ms设置的检查周期,默认 5 分钟(特别是毫秒以及分钟的话可能要更改下),权衡检查时间和保存时间
清理的策略有两种:
- delete (log.cleanup.policy = delete) 所有数据启用删除策略
基于时间:默认打开。以 segment 中所有记录中的最大时间戳作为该文件时间戳(旧的有一部分过期了,但是新的没过期,以新的时间戳为主)
基于大小:默认关闭。超过设置的所有日志总大小,删除最早的 segment。
log.retention.bytes
,默认等于-1,表示无穷大
- compact (log.cleanup.policy = compact) 用在日志压缩 同个key不同value,保存最后一个版本
这种策略适合特殊场景,因为会被覆盖掉原先的数据,比如年龄的增长可以使用这种,新的为主
3.8 高效读写数据
- 分布式集群,采用分区技术,并行度高
- 读取数据采用稀疏索引,快速定位数据
- 顺序写磁盘(写入log文件,写过程通过追加文件末尾,之所以顺序写快,省去了大量磁头寻址的时间)
- 页缓存+零拷贝技术
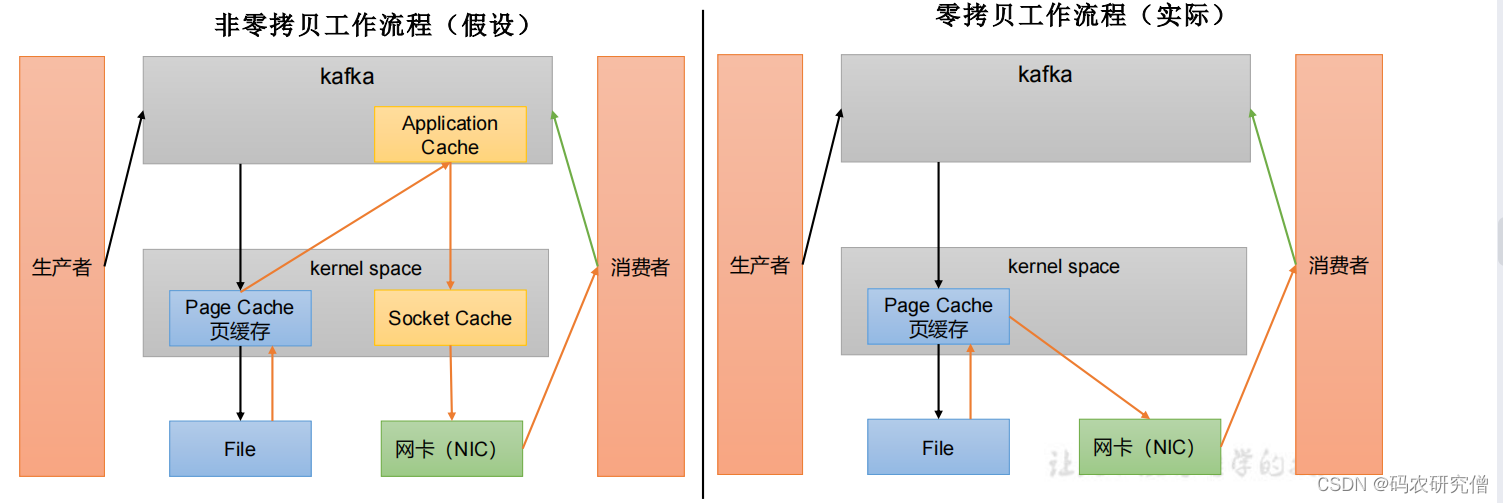
补充:
零拷贝:数据加工交给生产者消费者,不交给broker(不走应用层)
页缓存:依赖操作系统提供的PageCache功能。
上层写操作,操作系统将数据写入PageCache
读操作先从PageCache中查找,找不到再去磁盘中读取。实际上PageCache是把尽可能多的空闲内存都当做了磁盘缓存来使用
4. 消费者
消费的方式有两种,一种是拉取,一种是推送。而kafka选用了拉取的方式
之所以选择拉取,各个消费者消费的水平不一样,不一样的速率从broker拉取数据,如果选择推送的话,速率都一致就很难适应各个消费者的消费速率
但是拉取方式也有一些弊端,kafka没有数据的时候,消费者可能会陷入循环一直返回空数据
总体而言拉取的方式优于推送!
4.1 消费者组
消费者消费的流程是?
以往版本中将其偏移量放置在zookeeper,大量的数据都需要跟zookeeper交易,对此新版本kafka将其偏移量放置在系统主题保存(解耦)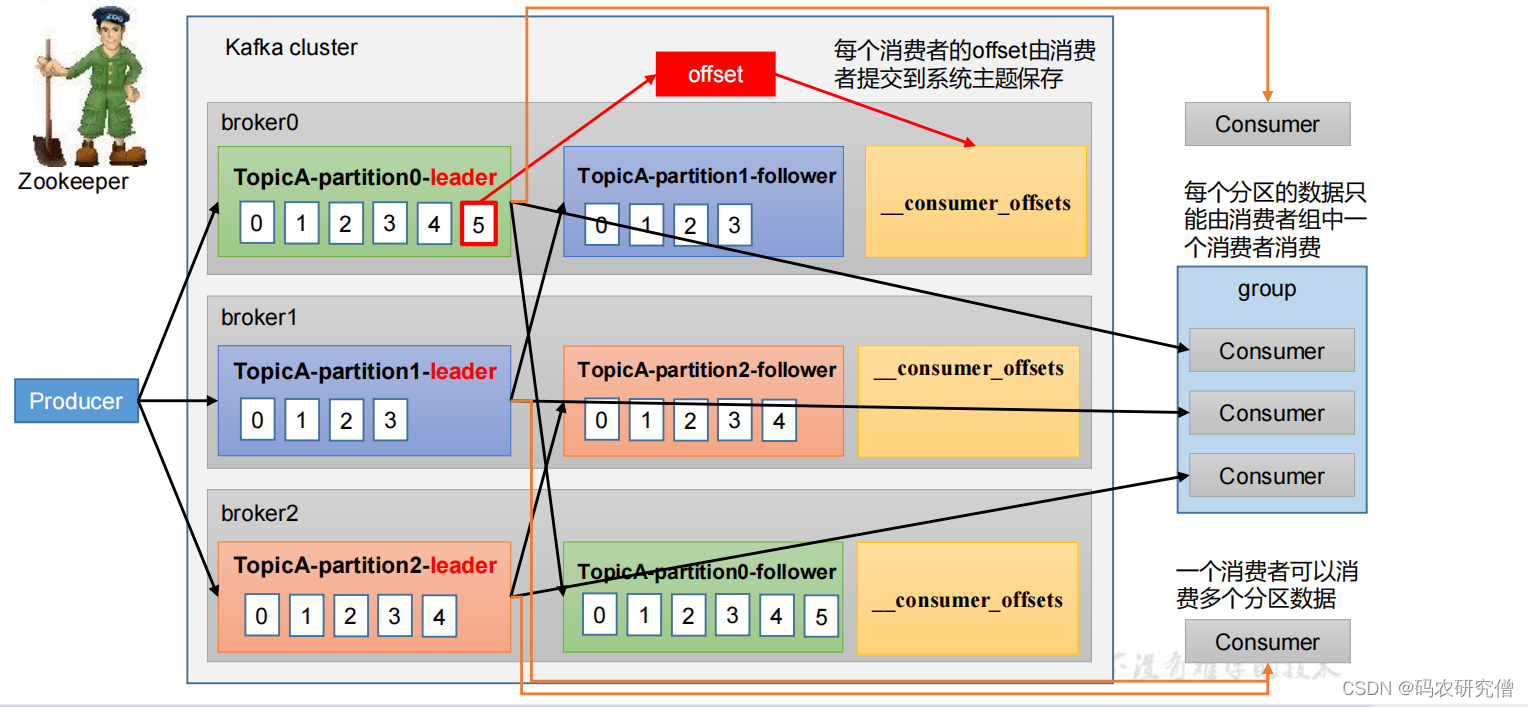
大致流程:
生产者发送数据到kafka,kafka的各个分区的leader接收数据,follower同步leader的数据。消费者消费leader的数据
具体消费到哪里,通过每个消费者的offset(偏移量)由消费者提交到系统主题保存
此处需要注意的点是:
- 多个消费者组可以消费同个分区
- 每个分区的数据只能由消费组中的其中一个消费者消费
何为消费者组CG(consumer group)
形成一个消费者组的条件,是所有消费者的groupid相同。
- 消费者组由多个消费者组成(也可以是一个),消费者组之间互不影响
- 如果向消费者组添加更多的消费者,超过了主题分区数量,有一部分的消费者组就会空闲,不会接受任何的消息
消费组初始化的流程是?(消费组选择消费哪个topic数据)
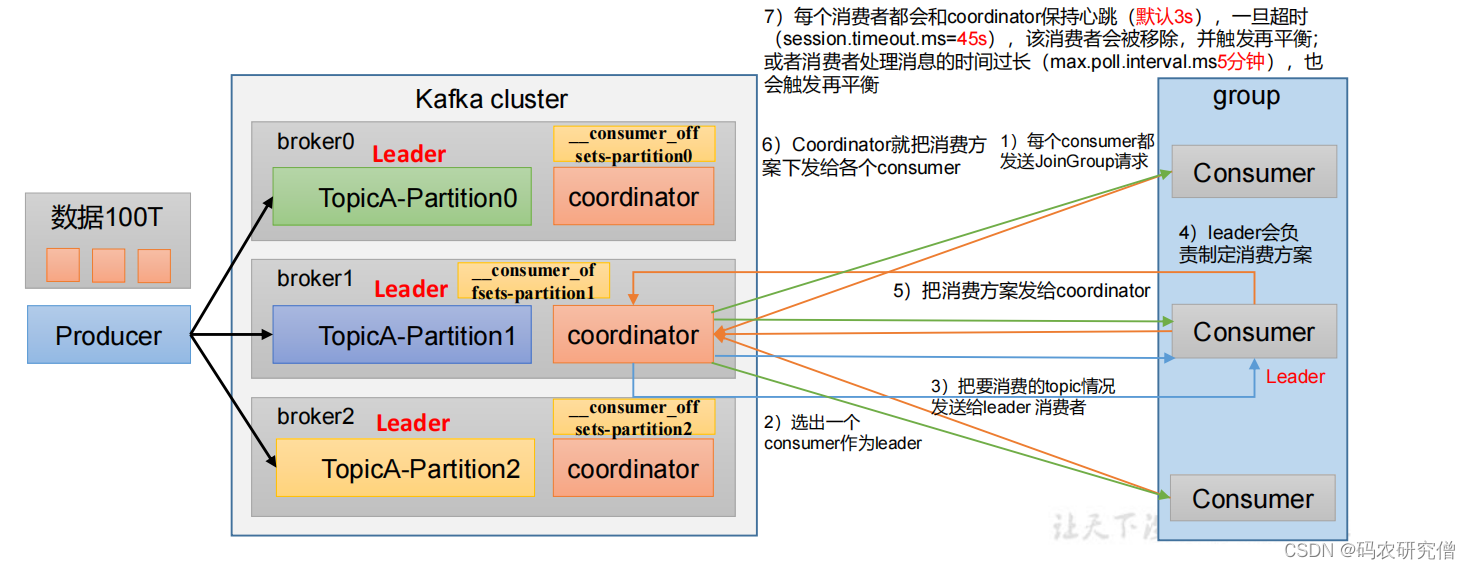
主要的选择通过coordinator这个模块
coordinator = groupid的hashcode%50(_consumer_offsets的分区数量默认为50,如果更改这个数字,对应也会更改)
大致逻辑如下:
- 消费者发送请求到kafka(coordinator在kafka)
- coordinator对应这个消费者组选择出一个leader,并且将其消费的topic情况发送给leader消费者
- leader指定消费方案发送给coordinator
- coordinator转而转发这个消费方案给各个消费者
- 每个消费者回合coordinator保持心跳(默认3s),一旦超时(默认session连接为45s),消费者被移除,触发再平衡 消费者处理时间过长(默认5分钟),也会触发再平衡
对应的参数策略有如下:
参数名称描述heartbeat.interval.ms消费者和 coordinator 之间的心跳时间,默认 3s。该条目的值必须小于 session.timeout.ms,也不应该高于session.timeout.ms 的 1/3。session.timeout.ms消费者和 coordinator 之间连接超时时间,默认 45s。超过该值,该消费者被移除,消费者组执行再平衡。max.poll.interval.ms消费者处理消息的最大时长,默认是 5 分钟。超过该值,该消费者被移除,消费者组执行再平衡。partition.assignment.strategy消费者分区分配策略,默认策略是Range +CooperativeSticky。
消费者组消费的流程?
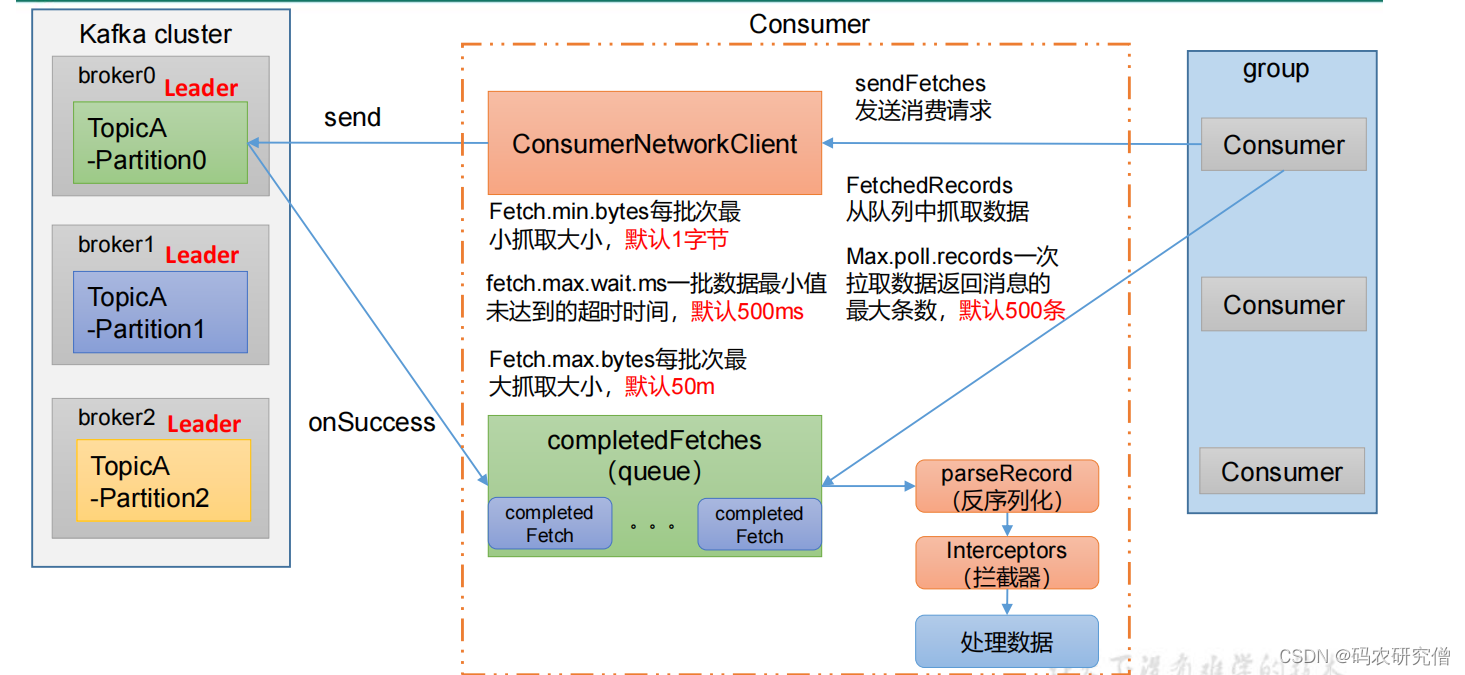
- 消费者组group通过发送消费请求(sendFetches),建立连接发送到kafka
- 此处Fetches的相关信息:每批次最小抓取大小默认1字节,最大为50m。一批数据最小值未达到的超时时间默认500ms
- 发送成功之后会返回一个回调函数(从该队列中抓取数据,一次拉取的数据最大条数默认500条)
- 还需要对应反序列化,以及拦截器(对应一开始生产者)
4.2 API
代码中一些重要的参数
参数名称描述bootstrap.servers连接的host以及端口主机key.deserializer 以及 value.deserializer接收消息的 key 和 value 的反序列化类型(全类名)group.id消费者所属的消费者组enable.auto.commit默认值为 true,消费者会自动周期性地向服务器提交偏移量auto.commit.interval.ms如果设置了 enable.auto.commit 的值为 true, 则该值定义了消费者偏移量向 Kafka 提交的频率,默认 5s。auto.offset.reset当 Kafka 中没有初始偏移量或当前偏移量在服务器中不存在(如,数据被删除了),该如何处理? earliest:自动重置偏移量到最早的偏移量。 latest:默认,自动重置偏移量为最新的偏移量。 none:如果消费组原来的(previous)偏移量不存在,则向消费者抛异常。 anything:向消费者抛异常offsets.topic.num.partitions__consumer_offsets 的分区数,默认是 50 个分区heartbeat.interval.msKafka 消费者和 coordinator 之间的心跳时间,默认 3s。该条目的值必须小于 session.timeout.ms ,也不应该高于session.timeout.ms 的 1/3。session.timeout.msKafka 消费者和 coordinator 之间连接超时时间,默认 45s。超过该值,该消费者被移除,消费者组执行再平衡max.poll.interval.ms消费者处理消息的最大时长,默认是 5 分钟。超过该值,该消费者被移除,消费者组执行再平衡fetch.min.bytes默认 1 个字节。消费者获取服务器端一批消息最小的字节数fetch.max.wait.ms默认 500ms。没有从服务器端获取到一批数据的最小字节数。时间到了,仍会返回数据fetch.max.bytes默认52428800(50 m)。消费者获取服务器端一批消息最大的字节数。如果服务器端一批次的数据大于该值(50m)仍然可以拉取回来这批数。一批次的大小受 message.max.bytes (broker config)or max.message.bytes (topic config)影响max.poll.records一次 poll 拉取数据返回消息的最大条数,默认是 500 条
独立的消费者也必须配置消费者组id,通过命令行启动的消费者不填写消费者组id会被自动随机的填写消费者组id
4.2.1 订阅主题
消费的数据是一个集合类型(代表可以传入多个topic)
代码如下:
publicclassCustomConsumer{publicstaticvoidmain(String[] args){// 0 配置Properties properties =newProperties();// 连接 bootstrap.servers
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"manongkafka:9092");// 反序列化
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());// 配置消费者组id
properties.put(ConsumerConfig.GROUP_ID_CONFIG,"test5");// 1 创建一个消费者 "", "hello"KafkaConsumer<String,String> kafkaConsumer =newKafkaConsumer<>(properties);// 2 订阅主题 firstArrayList<String> topics =newArrayList<>();
topics.add("first");
kafkaConsumer.subscribe(topics);// 3 消费数据while(true){ConsumerRecords<String,String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(1));for(ConsumerRecord<String,String> consumerRecord : consumerRecords){System.out.println(consumerRecord);}}}}
4.2.2 订阅分区
消费主题下的某个分区,注意其中的区别
publicclassCustomConsumerPartition{publicstaticvoidmain(String[] args){// 0 配置Properties properties =newProperties();// 连接
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"manongkafka:9092");// 反序列化
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());// 组id
properties.put(ConsumerConfig.GROUP_ID_CONFIG,"test");// 1 创建一个消费者KafkaConsumer<String,String> kafkaConsumer =newKafkaConsumer<>(properties);// 2 订阅主题对应的分区ArrayList<TopicPartition> topicPartitions =newArrayList<>();
topicPartitions.add(newTopicPartition("first",0));
kafkaConsumer.assign(topicPartitions);// 3 消费数据(拉取数据)while(true){ConsumerRecords<String,String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(1));for(ConsumerRecord<String,String> consumerRecord : consumerRecords){System.out.println(consumerRecord);}}}}
4.2.3 消费者案例
同个主题的分区数据只能有一个消费者组的消费者消费
消费者组id都是一样的,说明这些消费者都是同属于同个消费者组
// 配置消费者组id
properties.put(ConsumerConfig.GROUP_ID_CONFIG,"test5");
4.3 分区平衡再分配
四种主流的分区分配策略: Range、RoundRobin、Sticky、CooperativeSticky。
通过配置参数partition.assignment.strategy,修改分区的分配策略。默认策略是Range + CooperativeSticky。Kafka可以同时使用
多个分区分配策略
统一设置成7个分区,3个消费者观察各个分区策略
4.3.1 range
(针对同一个topic)
对同一个 topic 里面的分区按照序号进行排序,并对消费者按照字母顺序进行排序
通过 partitions数/consumer数 来决定每个消费者应该消费几个分区
对于1个topic来说影响不是很大,如果topic过多的话,C0消费者会比其他消费者要多消费N个分区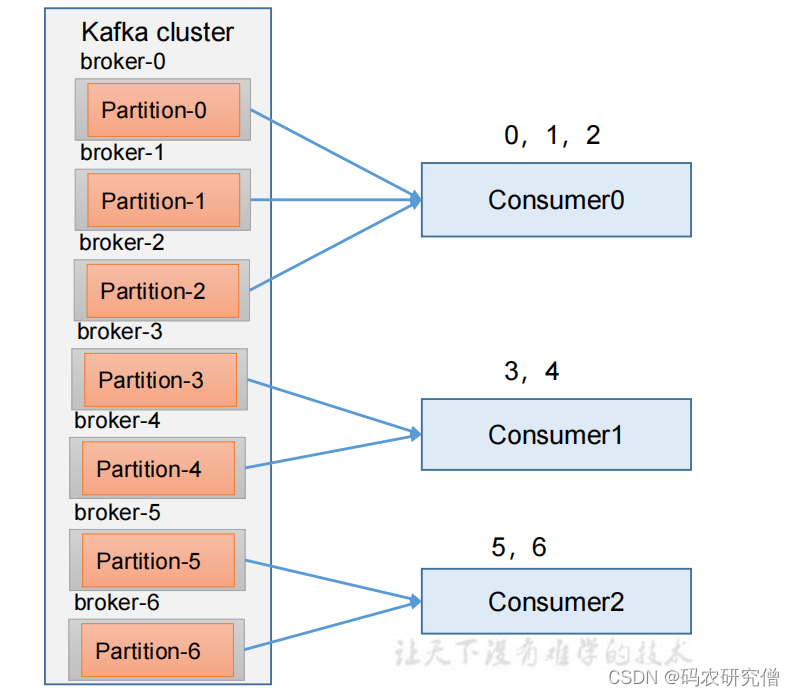
通过命令和代码层面的结合:(分区可以增加不能减少)
命令:
bin/kafka-topics.sh --bootstrap-server manongkafka:9092 --alter --topic first --partitions 7
之后启动生产者以及三个消费者,结果如上所示,消费者消费的分区如上所述
在平衡分配:
如果其中0号消费者宕机(45秒内检测才能看到效果)
0 号消费者挂掉后,消费者组需要按照超时时间 45s 来判断它是否退出,所以需要等待,时间到了 45s 后,判断它真的退出就会把任务分配给其他 broker 执行(0号退出,之后1和2按照range进行分配。1号消费者为0 1 2 3,2号消费者为4 5 6)
4.3.2 RoundRobin
(针对所有topic而言)
通过轮询分区策略,将其所有的分区和consumer列举,按照hashcode进行排序,最后通过轮询分配到各个消费者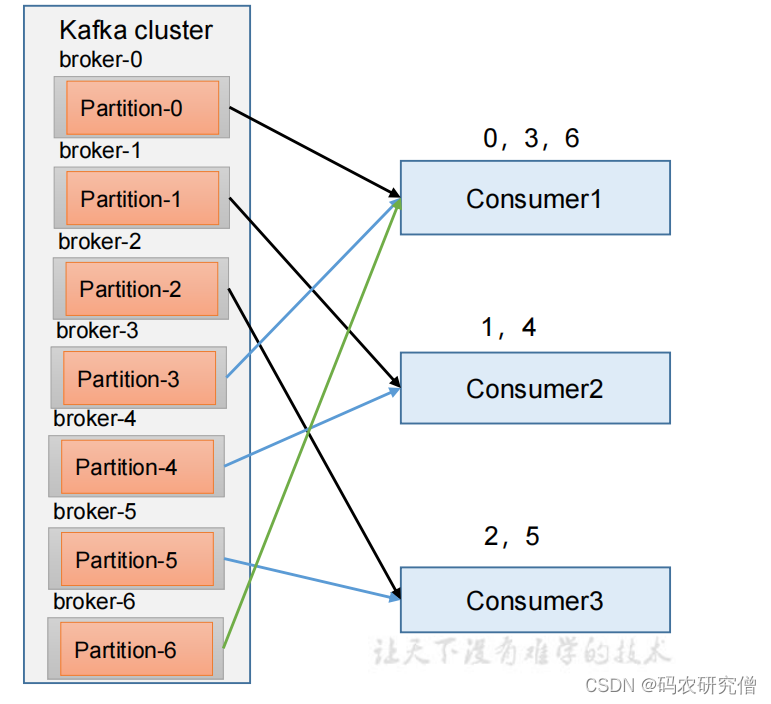
需要调整默认的分区策略(在消费者中设置分区策略)
代码如下:
// 设置分区分配策略
properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG,"org.apache.kafka.clients.consumer.RoundRobinAssignor");
默认的分区如上所示
如果把1号消费者停止,默认会把其0 3 6的数据防止在2号和3号的消费者中(还是按照轮询策略分配 0 3 6的数据分配)
也就是2号:0 1 4 6
3号:2 3 5
再平衡:
1号彻底宕机之后(超过45秒),消费者组通过超时的45秒最后判定为已经退出,就会将其任务分配给其他的broker
重新发送消息,数据的消息如下:
1 号消费者:消费到 0、2、4、6 号分区数据
2 号消费者:消费到 1、3、5 号分区数据
4.3.3 Sticky
粘性分配,执行分配之前会考虑上次的分配结果,减少分配调整(消费的数据区不是固定的,每次都是这个消费者都消费固定数值的数据,但数据跟上次不一致)
修改分区策略为如下:(每个消费者都需要加上)
// 设置分区分配策略
properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG,"org.apache.kafka.clients.consumer.StickyAssignor");
触发再平衡:
停掉0号消费者的时候 (0号消费者会将其 0 1的数据分给1和2号消费者)
1 号消费者:消费到 2、5、3 号分区数据。 2 号消费者:消费到 4、6 号分区数据
在数据彻底宕机之后(超过45秒内重新发送结果)
1 号消费者:消费到 2、3、5 号分区数据。 2 号消费者:消费到 0、1、4、6 号分区数据
4.4 offset(位移)
在kafka0.9的版本,原本这个位移是放在zookeeper,但是跟zookeeper交互太多
后续版本将其解耦,consumer将其offset放置在了kafka的topic中,该topic为__consumer_offsets
__consumer_offsets 主题里面采用 key 和 value 的方式存储数据。key 是 group.id+topic+分区号,value 就是当前 offset 的值。每隔一段时间,kafka 内部会对这个 topic 进行compact,也就是每个 group.id+topic+分区号就保留最新数据
默认是不消费系统主题的,如果要查看通过如下:
配置文件中的 config/consumer.properties 中添加配置 exclude.internal.topics=false
- 创建topic:
bin/kafka-topics.sh --bootstrap-server manognkafka:9092 --create --topic manong--partitions 2 --replication-factor 2 - 启动生产者:
bin/kafka-console-producer.sh --topic manong--bootstrap-server manongkafka:9092 - 启动消费者:
bin/kafka-console-consumer.sh --bootstrap-server manongkafka:9092 --topic manong--group test - 查看消费主题:
bin/kafka-console-consumer.sh --topic __consumer_offsets --bootstrap-server manongkafka:9092--consumer.config config/consumer.properties --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter"--from-beginning
4.4.1 指定提交方式
kafka一般专注于自身的业务,所以提交offset不用管
提交offset可以分为自动提交以及手动提交
大致的参数如下:
参数描述enable.auto.commit是否开启自动提交offset功能,默认是trueauto.commit.interval.ms自动提交offset的时间间隔,默认是5s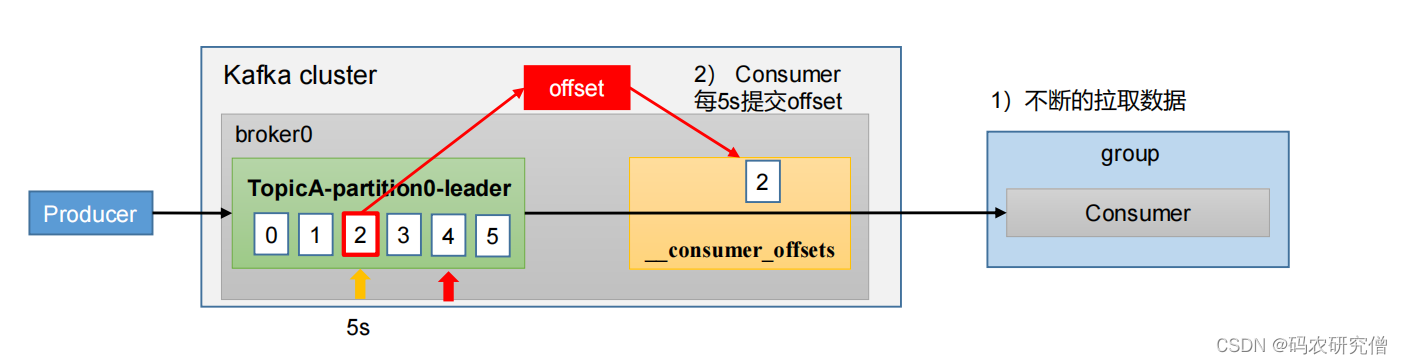
如果要专门配置,代码如下(默认系统已经写好了)
// 自动提交
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,true);// 提交时间间隔,1000为1秒
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,1000);
截图如下: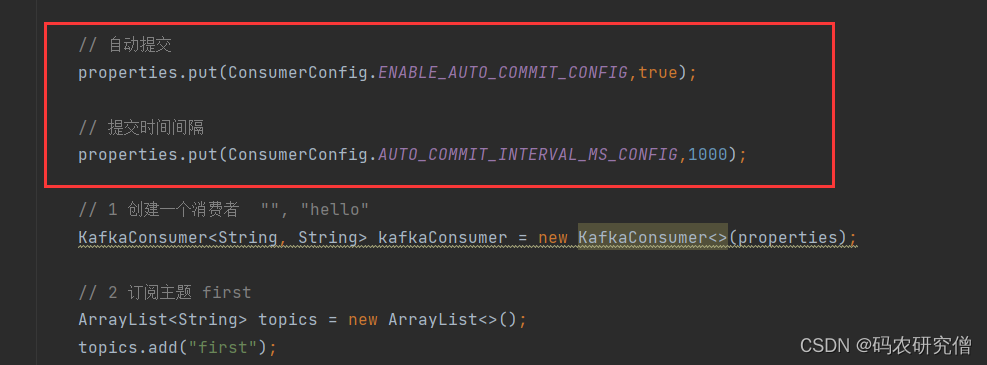
以下为手动提交
手动提交分为同步提交和异步提交
差异描述相同点都会将本次提交的一批数据最高的偏移量提交不同点同步提交阻塞而且他提交不成功还会重试,异步提交无重试可能会失败
整体来说,同步提交等待offset提交完毕才可消费下一批,异步提交提交offset之后就可消费下一批数据
完整代码如下:
publicclassCustomConsumerByHandSync{publicstaticvoidmain(String[] args){// 0 配置Properties properties =newProperties();// 连接 bootstrap.servers
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"manongkafka:9092");// 反序列化
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());// 配置消费者组id
properties.put(ConsumerConfig.GROUP_ID_CONFIG,"test");// 手动提交
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,false);// 1 创建一个消费者 "", "hello"KafkaConsumer<String,String> kafkaConsumer =newKafkaConsumer<>(properties);// 2 订阅主题 firstArrayList<String> topics =newArrayList<>();
topics.add("first");
kafkaConsumer.subscribe(topics);// 3 消费数据while(true){ConsumerRecords<String,String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(1));for(ConsumerRecord<String,String> consumerRecord : consumerRecords){System.out.println(consumerRecord);}// 手动提交offset
kafkaConsumer.commitSync();}}}
如果变为异步提交,将其提交方式改为
kafkaConsumer.commitAsync();
总结:
以上两种提交方式都可能引发一种情况:
- 重复消费:已经消费了数据,但是 offset 没提交(自动提交引起)

- 漏消费:先提交 offset 后消费,有可能会造成数据的漏消费(手动提交引起) 当offset被提交时,数据还在内存中未落盘,此时刚好消费者线 程被kill掉,那么offset已经提交,但是数据未处理,导致这部分内存中的数据丢失

如何控制才能不出现这种情况,需要结合消费者的事务(原子性)
将其消费过程和提交offset过程做原子绑定,将其保存到事务的mysql中(下游消费者必须支持事务,带能精确的一次性消费)
4.4.2 指定位置消费
原本默认是最新的消费,如果指定消费偏移量,通过设置
auto.offset.reset
=
earliest | latest | none
,默认是 latest
订阅数据之后 消费数据之前,放置指定offset的代码模块:
// 指定位置进行消费Set<TopicPartition> assignment = kafkaConsumer.assignment();// 保证分区分配方案已经制定完毕// 可能还没指定分配位置的时候,就开始消费offset,导致无数据,在此处判定一下,自动拉取数据while(assignment.size()==0){
kafkaConsumer.poll(Duration.ofSeconds(1));
assignment = kafkaConsumer.assignment();}// 指定消费的offsetfor(TopicPartition topicPartition : assignment){
kafkaConsumer.seek(topicPartition,600);}
4.4.3 指定时间消费
核心代码如下:
// 指定位置进行消费Set<TopicPartition> assignment = kafkaConsumer.assignment();// 保证分区分配方案已经制定完毕while(assignment.size()==0){
kafkaConsumer.poll(Duration.ofSeconds(1));
assignment = kafkaConsumer.assignment();}// 希望把时间转换为对应的offsetHashMap<TopicPartition,Long> topicPartitionLongHashMap =newHashMap<>();// 封装对应集合for(TopicPartition topicPartition : assignment){
topicPartitionLongHashMap.put(topicPartition,System.currentTimeMillis()-1*24*3600*1000);}Map<TopicPartition,OffsetAndTimestamp> topicPartitionOffsetAndTimestampMap = kafkaConsumer.offsetsForTimes(topicPartitionLongHashMap);// 指定消费的offsetfor(TopicPartition topicPartition : assignment){OffsetAndTimestamp offsetAndTimestamp = topicPartitionOffsetAndTimestampMap.get(topicPartition);
kafkaConsumer.seek(topicPartition,offsetAndTimestamp.offset());}
4.5 数据积压
对于这方面的处理问题,如果调整有如下方案
通过提高消费者的吞吐量
- kafka消费能力不足:通过增加topic分区,并且提升消费组的消费者数量
- 下游消费数据处理不及时:提高每一批次拉取的数据(默认是500条) 批次拉取数据过少(拉取数据/处理时间 < 生产速度),使处理的数据小于生产的数据,也会造成数据积压
5. Kafka-Eagle监控
详情链接可看我这篇文章:kafka-eagle详细安装配置图文教程
6. Kafka-Kraft模式
kafka在2.8之后的版本丢弃了zookeeper,两个团队维护,对此解耦了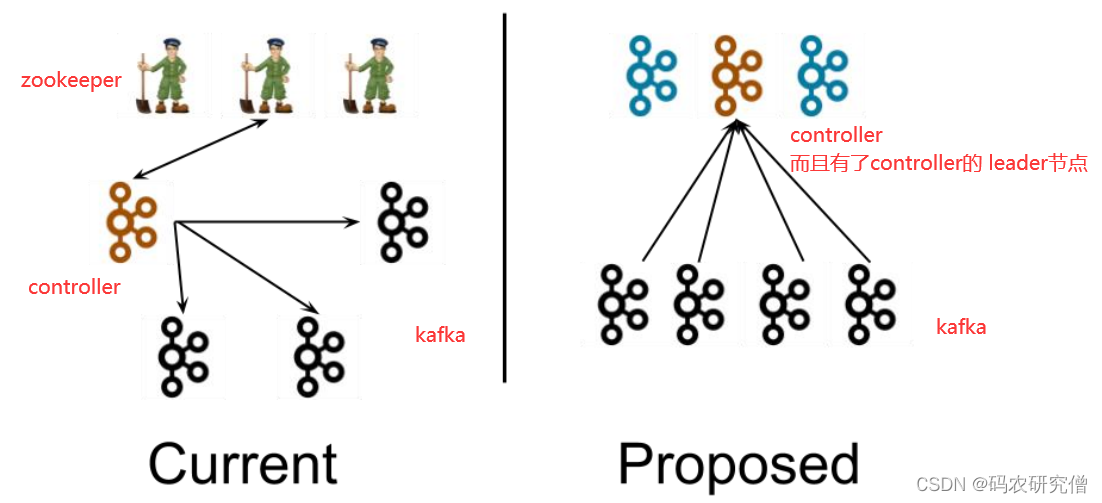
好处:
- 解耦,不依赖外部框架
- controller管理集群,不许从zookeeper读取数据(性能上升)
- controller不再动态选举,由配置文件规定(以前对随机的controller节点高负载无办法)
与原先安装kafka一样,目前的版本为2.12-3.0.0:
tar -zxvf kafka_2.12-3.0.0.tgz -C /opt/module/
查看其配置文件的具体信息:(对比差异不同)
- node.id类似brokerid(全局唯一)
- 对外暴露的网络端口(改成当前的名称)
#kafka 的角色(controller 相当于主机、broker 节点相当于从机,主机类似 zk 功 能)
process.roles=broker, controller
#节点 ID
node.id=2#controller 服务协议别名
controller.listener.names=CONTROLLER
#全 Controller 列表
controller.quorum.voters=2@manongkafka:9093,3@manong:9093#不同服务器绑定的端口
listeners=PLAINTEXT://:9092,CONTROLLER://:9093#broker 服务协议别名
inter.broker.listener.name=PLAINTEXT
#broker 对外暴露的地址
advertised.Listeners=PLAINTEXT://manongkafka:9092#协议别名到安全协议的映射
listener.security.protocol.map=CONTROLLER:PLAINTEXT,PLAINTEXT:PLA
INTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL
#kafka 数据存储目录
log.dirs=/opt/module/kafka2/data
对应其他机器的id、主机名称以及advertised.Listeners 地址都要修改
启动集群要先初始化数据目录:
bin/kafka-storage.sh random-uuid
之后将其的对应机器用该ID格式化:
bin/kafka-storage.sh format -t J7s9e8PPTKOO47PxzI39VA -c
启动 kafka 集群:
- 启动对应的集群:
bin/kafka-server-start.sh -daemon config/kraft/server.properties - 关闭对应的集群:
bin/kafka-server-stop.sh
集成化的分发启动脚本:(kf2.sh 文件)
#! /bin/bashcase$1in"start"){foriin hadoop102 hadoop103 hadoop104
doecho" --------启动 $i Kafka2-------"ssh$i"/opt/module/kafka2/bin/kafka-server-start.sh -
daemon /opt/module/kafka2/config/kraft/server.properties"done};;"stop"){foriin hadoop102 hadoop103 hadoop104
doecho" --------停止 $i Kafka2-------"ssh$i"/opt/module/kafka2/bin/kafka-server-stop.sh "done};;esac
通过chmod修改为777权限
- 启动集群:
kf2.sh start - 关闭集群:
kf2.sh stop
7. 实战调优参数(总结)
- 服务器台数:通过峰值生产速率跟副本的数量结合
- 磁盘:kafka按照顺序写(固态和机械顺序写差不多),直接买普通的机械键盘 通过数据量选择磁盘的硬盘大小
- 内存:kafka内存 = 【堆内存(修改bin目录下的kafka-server-start,生产环境一般10-15g) + 页缓存(segment大小,默认是1G,缓存25%即可)】
通过jps查看kafka进程号
查看kafka GC情况:
jstat -gc 进程号 ls 10
(YGC参数:年轻代垃圾回收的次数)
查看kafka 堆内存:
jmap -heap 进程号
cpu选择:(建议32个CPU)
参数描述num.io.threads可选8,负责写磁盘的线程数,整个参数值要占总核数的 50%num.replica.fetchers可选1, 副本拉取线程数,这个参数占总核数的 50%的 1/3num.network.threads可选3, 数据传输线程数,这个参数占总核数的 50%的 2/3网络选择 通过峰值/8来选择什么样的兆网络
以下调优参数上面已经讲过,此处总结:
7.1 生产者
核心配置参数:
参数名称描述bootstrap.servers生产者所需的broker,并非需要全部写上,可以 从给定的 broker 里查找到其他 broker 信息key.serializer 和 value.serializerkey 和 value 的序列化类型buffer.memoryRecordAccumulator 缓冲区总大小,默认 32mbatch.size缓冲区一批数据最大值,默认 16k。适当增加该值,可以提高吞吐量,但是如果该值设置太大,会导致数据传输延迟增加linger.ms如果数据迟迟未达到 batch.size,sender 等待 linger.time之后就会发送数据。默认值是 0ms,表示没有延迟。生产环境建议该值大小为 5-100ms 之间acks0:生产者发送过来的数据,不需要等数据落盘应答。1:生产者发送过来的数据,Leader 收到数据后应答。-1(all):生产者发送过来的数据,Leader+和 isr 队列里面的所有节点收齐数据后应答。默认值是-1,-1 和 all是等价的。max.in.flight.requests.per.connection允许最多没有返回 ack 的次数,默认为 5,开启幂等性要保证该值是 1-5 的数字retries当消息发送出现错误的时候,系统会重发消息。retries 表 示重试次数。默认是 int 最大值,2147483647。如果设置了重试,还想保证消息的有序性,需要设置MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION=1否则在重试此失败消息的时候,其他的消息可能发送成功了。retry.backoff.ms两次重试之间的时间间隔,默认是 100ms。enable.idempotence是否开启幂等性,默认 true,开启幂等性。compression.type生产者发送的所有数据的压缩方式。默认是 none。支持压缩类型:none、gzip、snappy、lz4 和 zstd
- 提高吞吐量,可以从buffer.memory(缓冲区大小)、batch.size(一批次的最大值)、linger.ms(延迟时间)、compression.type(压缩类型)
- 提高可靠性,从ack的设计角度思考
- 提高去重,从enable.idempotence(是否开启幂等性)
7.2 broker
参数名称描述replica.lag.time.max.ms默认30s,ISR 中,Follower 未向 Leader 发送通信请求或同步数据,会被被踢出 ISRauto.leader.rebalance.enable默认是 true, 自动 Leader Partition 平衡leader.imbalance.per.broker.percentage默认是 10%,每个 broker 允许的不平衡的 leader的比率。超出会发出不平衡值leader.imbalance.check.interval.seconds默认300 秒,检查 leader 负载是否平衡的间隔时间log.segment.byteslog 日志是分成一块块存储的,默认 1G(块状大小)log.index.interval.bytes默认 4kb,写入 4kb 大小的日志(.log),往 index 文件记录一个索引log.retention.hours数据保存的时间,默认 7 天log.retention.minutes分钟级别,默认关闭log.retention.ms毫秒级别,默认关闭log.retention.check.interval.ms检查数据是否保存超时的间隔,默认是 5 分钟log.retention.bytes默认等于-1,表示无穷大。超过设置的所有日志总大小,删除最早的 segmentlog.cleanup.policy默认是 delete,表示所有数据启用删除策略;为 compact,表示所有数据启用压缩策略num.io.threads默认是 8。负责写磁盘的线程数。整个参数值要占总核数的 50%num.replica.fetchers副本拉取线程数,占总核数的 50%的 1/3num.network.threads默认是 3。数据传输线程数,占总核数的50%的 2/3log.flush.interval.messages强制页缓存刷写到磁盘的条数,默认是 long 的最大(不建议修改)log.flush.interval.ms每隔多久,刷数据到磁盘,默认是 null(不建议修改)
broker一般都会有所变动(具体代码看上面broker讲解回顾)
- 新旧节点上下线
- 增加分区(只能增)
- 增加副本
- leader负载平衡,通过auto.leader.rebalance.enable(是否自动平衡)+ leader.imbalance.per.broker.percentage(平衡的百分比)+ leader.imbalance.check.interval.seconds(测试平衡间隔时间)
7.3 消费者
核心参数:
参数名称描述bootstrap.servers连接的host以及端口主机key.deserializer 以及 value.deserializer接收消息的 key 和 value 的反序列化类型(全类名)group.id消费者所属的消费者组enable.auto.commit默认值为 true,消费者会自动周期性地向服务器提交偏移量auto.commit.interval.ms如果设置了 enable.auto.commit 的值为 true, 则该值定义了消费者偏移量向 Kafka 提交的频率,默认 5s。auto.offset.reset当 Kafka 中没有初始偏移量或当前偏移量在服务器中不存在(如,数据被删除了),该如何处理? earliest:自动重置偏移量到最早的偏移量。 latest:默认,自动重置偏移量为最新的偏移量。 none:如果消费组原来的(previous)偏移量不存在,则向消费者抛异常。 anything:向消费者抛异常offsets.topic.num.partitions__consumer_offsets 的分区数,默认是 50 个分区heartbeat.interval.msKafka 消费者和 coordinator 之间的心跳时间,默认 3s。该条目的值必须小于 session.timeout.ms ,也不应该高于session.timeout.ms 的 1/3。session.timeout.msKafka 消费者和 coordinator 之间连接超时时间,默认 45s。超过该值,该消费者被移除,消费者组执行再平衡max.poll.interval.ms消费者处理消息的最大时长,默认是 5 分钟。超过该值,该消费者被移除,消费者组执行再平衡fetch.min.bytes默认 1 个字节。消费者获取服务器端一批消息最小的字节数fetch.max.wait.ms默认 500ms。没有从服务器端获取到一批数据的最小字节数。时间到了,仍会返回数据fetch.max.bytes默认52428800(50 m)。消费者获取服务器端一批消息最大的字节数。如果服务器端一批次的数据大于该值(50m)仍然可以拉取回来这批数。一批次的大小受 message.max.bytes (broker config)or max.message.bytes (topic config)影响max.poll.records一次 poll 拉取数据返回消息的最大条数,默认是 500 条
- 消费者再平衡:通过heartbeat.interval.ms(心跳时间)+ session.timeout.ms(心跳连接超时时间)+ max.poll.interval.ms(消费者处理时长)+ partition.assignment.strategy(分区策略)
- 提高吞吐量:通过fetch.max.bytes(拉取数据的最大字节数)+ max.poll.records(拉取数据的最大条数)
7.4 总体调优
生产者:
- 提高吞吐量,可以从buffer.memory(缓冲区大小)、batch.size(一批次的最大值)、linger.ms(延迟时间)、compression.type(压缩类型)
- acks 设置为-1 以及 幂等性 和 事务
broker:
- 增加分区(合理设置)
- 分区副本大于等于 2 (–replication-factor 2),ISR 里应答的最小副本数量大于等于 2(min.insync.replicas = 2)
消费者:
- 提高吞吐量,通过fetch.max.bytes(拉取数据的最大字节数)+ max.poll.records(拉取数据的最大条数)
- 提高下游的处理能力,支持事务(MySQL、Kafka)
- 事务 + 手动提交
8. 集群压测
默认在bin目录下自带有test测试脚本
- 生产者压测:kafka-producer-perf-test.sh
- 消费者压测:kafka-consumer-perf-test.sh
生产者压测:
默认通过创建topic以及分区分区副本:
bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --create --replication-factor 3 --partitions 3 --topic test
截图如下:
测试的命令如下:
bin/kafka-producer-perf-test.sh --topic test --record-size 1024 --num-records 1000000 --throughput 10000 --producer-props bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092 batch.size=16384 linger.ms=0
大致截图如下:
参数如下:
参数描述record-size一条信息有多大,单位是字节num-records总共发送多少信息throughput每秒多少条信息,设成-1,表示不限流,可测出生产者最大吞吐量
关于producer-props的参数
命令参数producer-props可配置生产者相关参数batch.size批次数据, 配置为 16klinger.ms延迟compression.type压缩方式buffer.memory缓存大小
消费者压测:
在config/consumer.properties配置文件中增加:
max.poll.records=500(代表一次拉取的条数)fetch.max.bytes=104857600(拉取一批数据的大小为100m)
测试命令如下:
bin/kafka-consumer-perf-test.sh --bootstrap-server hadoop102:9092,hadoop103:9092,hadoop104:9092 --topic test --messages 1000000 --consumer.config config/consumer.properties
参数messages代表总共要消费的消息个数
反复修改拉取数据的条数数量以及一批数据的大小测试
9. 集成化
大数据框架不熟悉 = - =
关于下面涉及到的公共知识点补充:
maven对应知识点可看我之前的文章:
Maven详细配置(全)
Maven实战从入门到精通(全)
日志配置的相关信息
对应知识点看我之前的文章:java常见log日志的使用方法详细解析
9.1 集成Flume
大数据开发的框架,暂时还未熟悉(以后有时间补充下)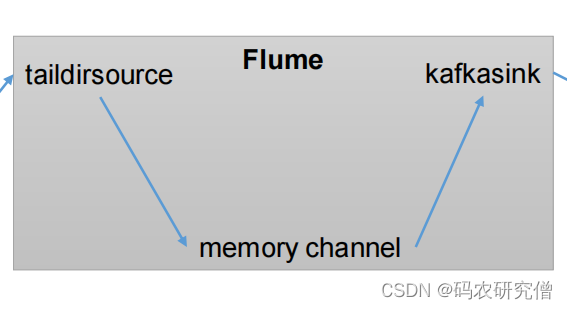
- 启动kafka集群、生产者
- 配置Flume,配置对应的信息,通过
vim jobs/file_to_kafka.conf
# 1 组件定义
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 2 配置 source
a1.sources.r1.type= TAILDIR
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 =/opt/module/applog/app.*
a1.sources.r1.positionFile =/opt/module/flume/taildir_position.json
# 3 配置 channel
a1.channels.c1.type= memory
a1.channels.c1.capacity =1000
a1.channels.c1.transactionCapacity =100# 4 配置 sink
a1.sinks.k1.type= org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.bootstrap.servers = manongkafka:9092
a1.sinks.k1.kafka.topic =first
a1.sinks.k1.kafka.flumeBatchSize =20
a1.sinks.k1.kafka.producer.acks =1
a1.sinks.k1.kafka.producer.linger.ms =1# 5 拼接组件
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
正常配置启动:
bin/flume-ng agent -c conf/ -n a1 -f jobs/file_to_kafka.conf &
向/opt/module/applog/app.log 里追加数据
echo hello >>/opt/module/applog/app.log
,查看消费情况
以上为生产者,以下为消费者:
配置信息:
# 1 组件定义
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 2 配置 source
a1.sources.r1.type= org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize =50
a1.sources.r1.batchDurationMillis =200
a1.sources.r1.kafka.bootstrap.servers = manongkafka:9092
a1.sources.r1.kafka.topics =first
a1.sources.r1.kafka.consumer.group.id = custom.g.id
# 3 配置 channel
a1.channels.c1.type= memory
a1.channels.c1.capacity =1000
a1.channels.c1.transactionCapacity =100# 4 配置 sink
a1.sinks.k1.type= logger
# 5 拼接组件
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动Flume:
bin/flume-ng agent -c conf/ -n a1 -f jobs/kafka_to_file.conf -Dflume.root.logger=INFO,console
启动kafka生产者发送数据观察输出日志:
bin/kafka-console-producer.sh --bootstrap-server manongkafka:9092 --topic first
9.2 集成Flink
对于Flink大数据开发的框架,暂时还未熟悉(以后有时间补充下)
创建maven项目,依赖文件如下:
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>1.13.0</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java_2.12</artifactId><version>1.13.0</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients_2.12</artifactId><version>1.13.0</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka_2.12</artifactId><version>1.13.0</version></dependency>
日志配置信息(log4j.properties):
log4j.rootLogger=error, stdout,R
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{yyyy-MM-dd
HH:mm:ss,SSS} %5p --- [%50t] %-80c(line:%5L) : %m%n
log4j.appender.R=org.apache.log4j.RollingFileAppender
log4j.appender.R.File=../log/agent.log
log4j.appender.R.MaxFileSize=1024KB
log4j.appender.R.MaxBackupIndex=1
log4j.appender.R.layout=org.apache.log4j.PatternLayout
log4j.appender.R.layout.ConversionPattern=%d{yyyy-MM-dd
HH:mm:ss,SSS} %5p --- [%50t] %-80c(line:%6L) : %m%n
生产者:
publicclassFlinkKafkaProducer1{publicstaticvoidmain(String[] args)throwsException{// 0 初始化 flink 环境StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(3);// 1 读取集合中数据ArrayList<String> wordsList =newArrayList<>();
wordsList.add("hello");
wordsList.add("world");DataStream<String> stream = env.fromCollection(wordsList);// 2 kafka 生产者配置信息Properties properties =newProperties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"manongkafka:9092");// 3 创建 kafka 生产者FlinkKafkaProducer<String> kafkaProducer =newFlinkKafkaProducer<>("first",newSimpleStringSchema(),
properties
);// 4 生产者和 flink 流关联
stream.addSink(kafkaProducer);// 5 执行
env.execute();}}
消费者:
publicclassFlinkKafkaConsumer1{publicstaticvoidmain(String[] args)throwsException{// 0 初始化 flink 环境StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(3);// 1 kafka 消费者配置信息Properties properties =newProperties();
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092");// 2 创建 kafka 消费者FlinkKafkaConsumer<String> kafkaConsumer =newFlinkKafkaConsumer<>("first",newSimpleStringSchema(),
properties
);// 3 消费者和 flink 流关联
env.addSource(kafkaConsumer).print();// 4 执行
env.execute();}}
9.3 集成springboot
对于springboot的知识点可看我之前的文章补充:springboot从入门到精通(全)
以及类中的get set的生成,需要使用到lomok插件(上文也有对应讲解)
这个创建的过程和springboot项目启动差不多,只不过多了一个勾选项(勾选messaging中的spring for apache kafka)
勾选成功之后会对应生成一个配置文件
<dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId></dependency>
生产者
修改springboot中的application.properties配置
# 应用名称
spring.application.name=manongkafka_springboot_kafka
# 指定 kafka 的地址
spring.kafka.bootstrapservers=manongkafka:9092#指定 key 和 value 的序列化器
spring.kafka.producer.keyserializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.valueserializer=org.apache.kafka.common.serialization.StringSerializer
生产者的代码:
@RestControllerpublicclassProducerController{// Kafka 模板用来向 kafka 发送数据@AutowiredKafkaTemplate<String,String> kafka;// 外界访问的接口@RequestMapping("/manongkafka")publicStringdata(String msg){
kafka.send("first", msg);return"ok";}}
消费者:
# 指定 kafka 的地址
spring.kafka.bootstrapservers=manongkafka:9092# 指定 key 和 value 的反序列化器
spring.kafka.consumer.keydeserializer=org.apache.kafka.common.serialization.StringDeserial
izer
spring.kafka.consumer.valuedeserializer=org.apache.kafka.common.serialization.StringDeserial
izer
#指定消费者组的 group_id
spring.kafka.consumer.group-id=manongkafka
消费者代码
@ConfigurationpublicclassKafkaConsumer{// 指定要监听的 topic@KafkaListener(topics ="first")publicvoidconsumeTopic(String msg){// 参数: 收到的 valueSystem.out.println("收到的信息: "+ msg);}}
9.4 集成spark
此框架为大数据用到的框架,之后如果学习大数据的话,会对应补充这些框架(以下代码还未运行使用,之后慢慢在深入该框架)
预先需要的环境:scala
通过官网下载并且配置环境变量即可(与jdk安装差不多简易)
- 创建maven项目
- 对应项目右键Add Framework Support=》勾选 scala
- main下的src创建scala,右键勾选 Mark Directory as Sources Root
添加xml文件:(pom.xml)
<!--生产者的依赖--><dependencies><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming-kafka-0-10_2.12</artifactId><version>3.0.0</version></dependency></dependencies><!--消费者的依赖--><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.12</artifactId><version>3.0.0</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming_2.12</artifactId><version>3.0.0</version></dependency>
添加配置 主要打印日志,log4j.properties(放置resources下)
log4j.rootLogger=error, stdout,R
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{yyyy-MM-dd
HH:mm:ss,SSS} %5p --- [%50t] %-80c(line:%5L) : %m%n
log4j.appender.R=org.apache.log4j.RollingFileAppender
log4j.appender.R.File=../log/agent.log
log4j.appender.R.MaxFileSize=1024KB
log4j.appender.R.MaxBackupIndex=1
log4j.appender.R.layout=org.apache.log4j.PatternLayout
log4j.appender.R.layout.ConversionPattern=%d{yyyy-MM-dd
HH:mm:ss,SSS} %5p --- [%50t] %-80c(line:%6L) : %m%n
对应的生产者:
object SparkKafkaProducer {def main(args: Array[String]):Unit={// 0 kafka 配置信息val properties =new Properties()
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"manongkafka:9092")
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,classOf[StringSerializer])
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,classOf[StringSerializer])// 1 创建 kafka 生产者var producer =new KafkaProducer[String,String](properties)// 2 发送数据for(i <-1 to 5){
producer.send(new ProducerRecord[String,String]("first","atguigu"+ i))}// 3 关闭资源
producer.close()}}
对应的消费者:
object SparkKafkaConsumer {def main(args: Array[String]):Unit={//1.创建 SparkConf val sparkConf: SparkConf =new
SparkConf().setAppName("sparkstreaming").setMaster("local[*]")//2.创建 StreamingContextval ssc =new StreamingContext(sparkConf, Seconds(3))//3.定义 Kafka 参数:kafka 集群地址、消费者组名称、key 序列化、value 序列化val kafkaPara: Map[String, Object]= Map[String, Object](ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG ->"manongkafka:9092",
ConsumerConfig.GROUP_ID_CONFIG ->"atguiguGroup",
ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG ->classOf[StringDeserializer],
ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG ->classOf[StringDeserializer])//4.读取 Kafka 数据创建 DStreamval kafkaDStream: InputDStream[ConsumerRecord[String,String]]= KafkaUtils.createDirectStream[String,String](ssc,
LocationStrategies.PreferConsistent,//优先位置
ConsumerStrategies.Subscribe[String,String](Set("first"), kafkaPara)// 消费策略:(订阅多个主题,配置参数))//5.将每条消息的 KV 取出val valueDStream: DStream[String]= kafkaDStream.map(record => record.value())//6.计算 WordCount
valueDStream.print()//7.开启任务
ssc.start()
ssc.awaitTermination()}}
10. ----kafka源码分析----
以下代码为源码分析
具体源码通过官网进行下载
客户端为生产者和消费者(java)
服务端为broker(scala)
10.1 生产者(java源码)
总体流程:
生产者客户端发送给kafka,先创建一个main线程,调用send发送函数(拦截器、key和value的序列化)将其数据发送到分区器,默认每一批次是16k,分区容量默认为32m。
由其sender线程发送数据,条件是批次的数据达到上限,或者时间到达上限
通过发送的数据到达缓存(默认是缓存5个请求),调用是selector发送到服务端(涉及ack,ack有 0 -1 和 1)
如果发送成功会对缓存进行清理,发送失败会进行重试
main线程初始化: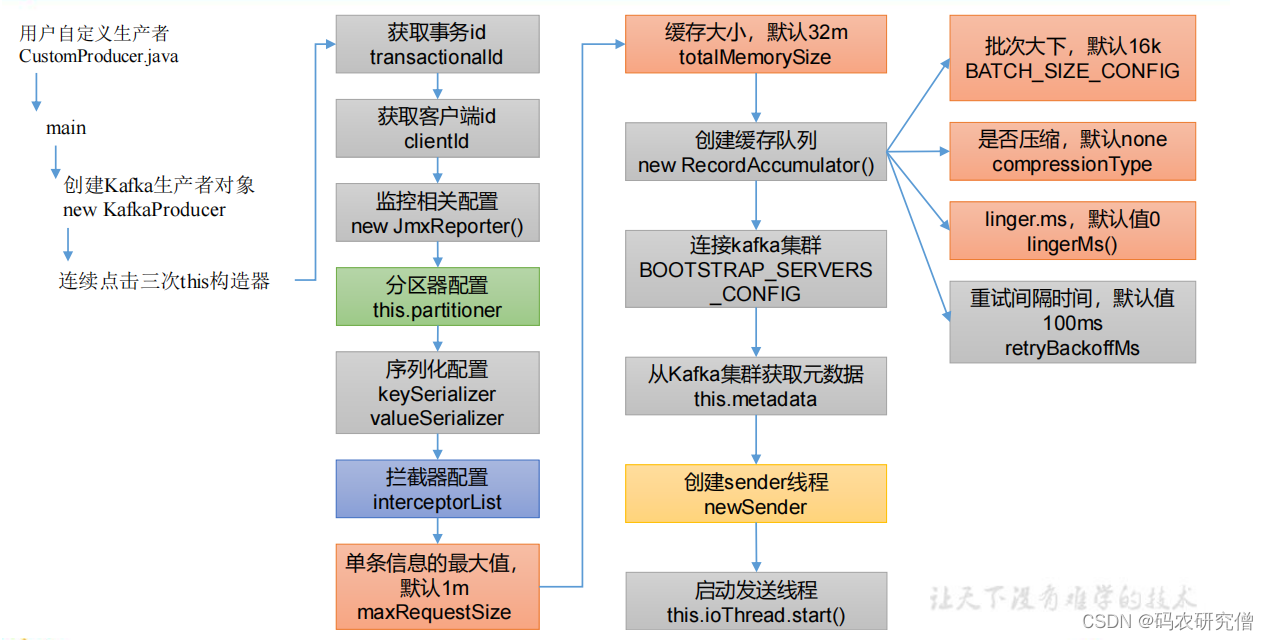
sender线程初始化: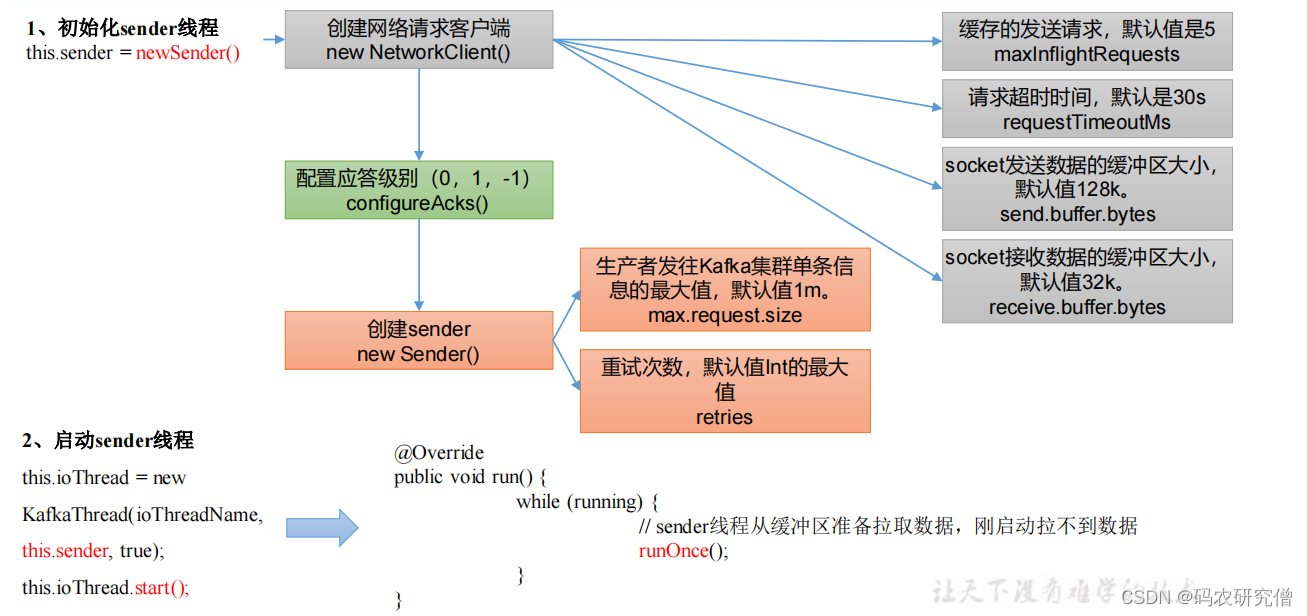
底层的源码配置信息跟客户端生产者的逻辑差不多一样
10.1.1 初始化
入口的函数:
producer = new KafkaProducer<>(props);
基本的配置信息:(main函数初始化过程的一些参数)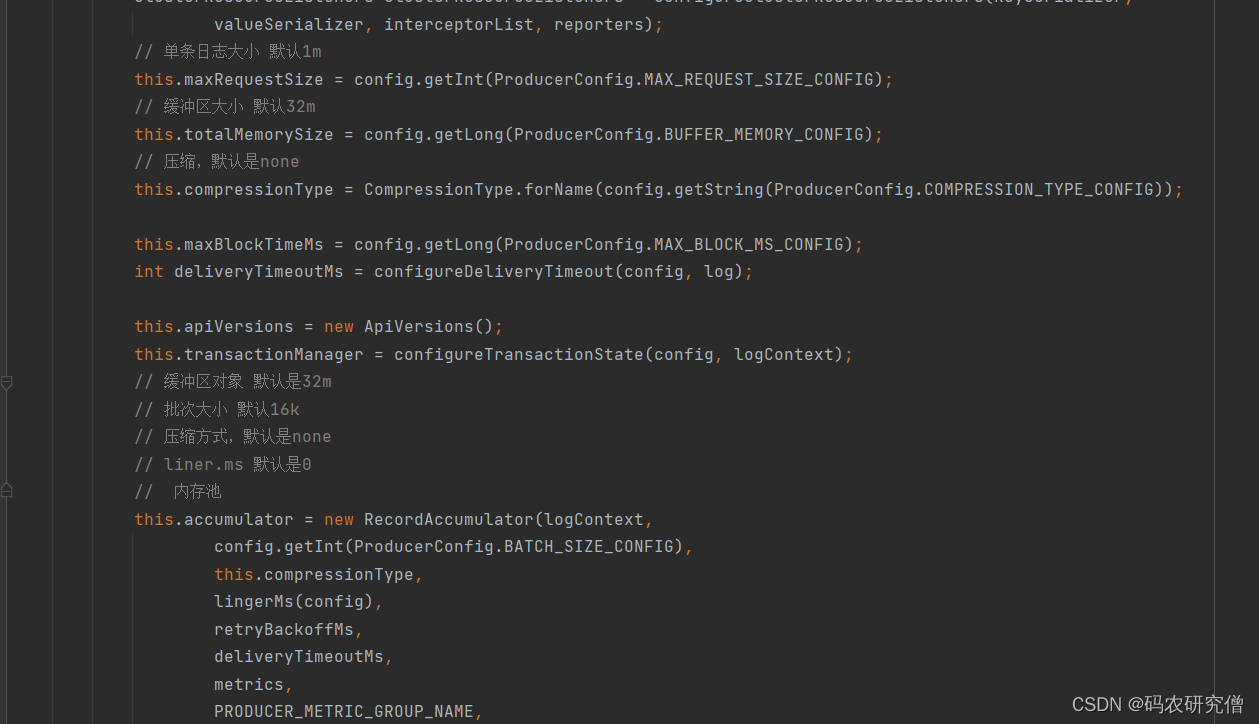
new sender线程的初始化配置:
SendernewSender(LogContext logContext,KafkaClient kafkaClient,ProducerMetadata metadata){// 缓存请求的个数 默认是5个int maxInflightRequests =configureInflightRequests(producerConfig);// 请求超时时间,默认30sint requestTimeoutMs = producerConfig.getInt(ProducerConfig.REQUEST_TIMEOUT_MS_CONFIG);ChannelBuilder channelBuilder =ClientUtils.createChannelBuilder(producerConfig, time, logContext);ProducerMetrics metricsRegistry =newProducerMetrics(this.metrics);Sensor throttleTimeSensor =Sender.throttleTimeSensor(metricsRegistry.senderMetrics);// 创建一个客户端对象// clientId 客户端id// maxInflightRequests 缓存请求的个数 默认是5个// RECONNECT_BACKOFF_MS_CONFIG 重试时间// RECONNECT_BACKOFF_MAX_MS_CONFIG 总的重试时间// 发送缓冲区大小send.buffer.bytes 默认128kb// 接收数据缓存 receive.buffer.bytes 默认是32kbKafkaClient client = kafkaClient !=null? kafkaClient :newNetworkClient(newSelector(producerConfig.getLong(ProducerConfig.CONNECTIONS_MAX_IDLE_MS_CONFIG),this.metrics, time,"producer", channelBuilder, logContext),
metadata,
clientId,
maxInflightRequests,
producerConfig.getLong(ProducerConfig.RECONNECT_BACKOFF_MS_CONFIG),
producerConfig.getLong(ProducerConfig.RECONNECT_BACKOFF_MAX_MS_CONFIG),
producerConfig.getInt(ProducerConfig.SEND_BUFFER_CONFIG),
producerConfig.getInt(ProducerConfig.RECEIVE_BUFFER_CONFIG),
requestTimeoutMs,
producerConfig.getLong(ProducerConfig.SOCKET_CONNECTION_SETUP_TIMEOUT_MS_CONFIG),
producerConfig.getLong(ProducerConfig.SOCKET_CONNECTION_SETUP_TIMEOUT_MAX_MS_CONFIG),
time,true,
apiVersions,
throttleTimeSensor,
logContext);// 0 :生产者发送过来,不需要应答; 1 :leader收到,应答; -1 :leader和isr队列里面所有的都收到了应答short acks =configureAcks(producerConfig, log);// 创建sender线程returnnewSender(logContext,
client,
metadata,this.accumulator,
maxInflightRequests ==1,
producerConfig.getInt(ProducerConfig.MAX_REQUEST_SIZE_CONFIG),
acks,
producerConfig.getInt(ProducerConfig.RETRIES_CONFIG),
metricsRegistry.senderMetrics,
time,
requestTimeoutMs,
producerConfig.getLong(ProducerConfig.RETRY_BACKOFF_MS_CONFIG),this.transactionManager,
apiVersions);}
10.1.2 发送数据
本身主题的函数是继承了Thread
重写了run方法
在run方法中通过
producer.send
截图如下: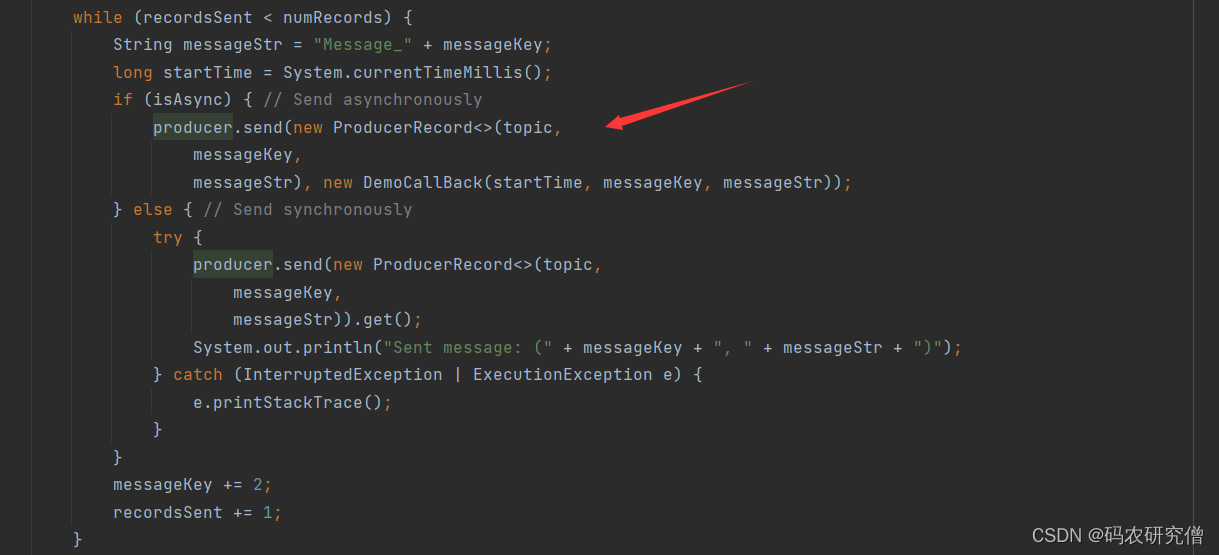
进入send函数之后,走的是拦截器函数
@OverridepublicFuture<RecordMetadata>send(ProducerRecord<K,V>record,Callback callback){// intercept the record, which can be potentially modified; this method does not throw exceptions// 拦截器相关操作ProducerRecord<K,V> interceptedRecord =this.interceptors.onSend(record);returndoSend(interceptedRecord, callback);}
通过拦截器中的onsend函数对应对数据进行加工,之后处理完数据之后返回上层函数的doSend函数
publicProducerRecord<K,V>onSend(ProducerRecord<K,V>record){ProducerRecord<K,V> interceptRecord =record;for(ProducerInterceptor<K,V> interceptor :this.interceptors){try{// 拦截器对数据进行加工
interceptRecord = interceptor.onSend(interceptRecord);}catch(Exception e){// do not propagate interceptor exception, log and continue calling other interceptors// be careful not to throw exception from hereif(record!=null)
log.warn("Error executing interceptor onSend callback for topic: {}, partition: {}",record.topic(),record.partition(), e);else
log.warn("Error executing interceptor onSend callback", e);}}return interceptRecord;}
doSend函数截图如下:
(获取元数据、key value的序列化、分区)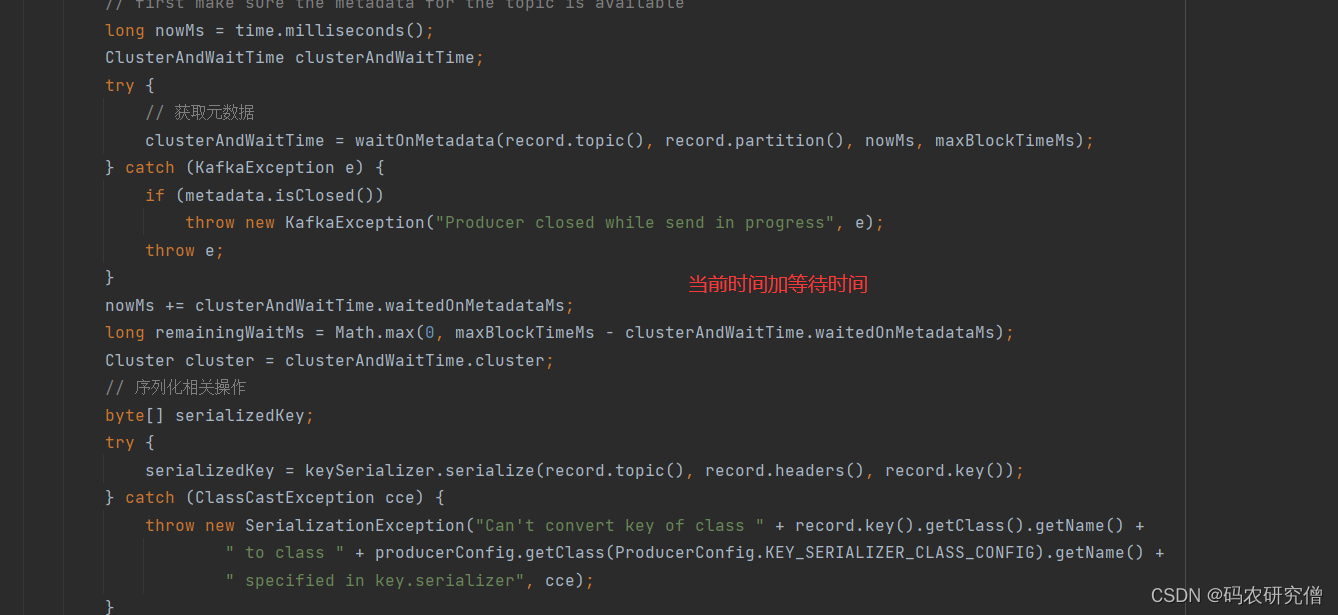
细节处理(比如为了保证序列化后的数据可以传输):
ensureValidRecordSize(serializedSize);
内部函数的实现方法:
privatevoidensureValidRecordSize(int size){// 单条信息最大值 maxRequestSize 1mif(size > maxRequestSize)thrownewRecordTooLargeException("The message is "+ size +" bytes when serialized which is larger than "+ maxRequestSize +", which is the value of the "+ProducerConfig.MAX_REQUEST_SIZE_CONFIG +" configuration.");// totalMemorySize 缓存大小 默认32mif(size > totalMemorySize)thrownewRecordTooLargeException("The message is "+ size +" bytes when serialized which is larger than the total memory buffer you have configured with the "+ProducerConfig.BUFFER_MEMORY_CONFIG +" configuration.");}
细节处理追加数据:
try{// check if we have an in-progress batch// 获取或者创建一个队列(按照每个主题的分区)Deque<ProducerBatch> dq =getOrCreateDeque(tp);synchronized(dq){if(closed)thrownewKafkaException("Producer closed while send in progress");// 尝试向队列里面添加数据(正常添加不成功)RecordAppendResult appendResult =tryAppend(timestamp, key, value, headers, callback, dq, nowMs);if(appendResult !=null)return appendResult;}// we don't have an in-progress record batch try to allocate a new batchif(abortOnNewBatch){// Return a result that will cause another call to append.returnnewRecordAppendResult(null,false,false,true);}byte maxUsableMagic = apiVersions.maxUsableProduceMagic();// this.batchSize 默认16k 数据大小17kint size =Math.max(this.batchSize,AbstractRecords.estimateSizeInBytesUpperBound(maxUsableMagic, compression, key, value, headers));
log.trace("Allocating a new {} byte message buffer for topic {} partition {} with remaining timeout {}ms", size, tp.topic(), tp.partition(), maxTimeToBlock);// 申请内存 内存池分配内存 双端队列
buffer = free.allocate(size, maxTimeToBlock);// Update the current time in case the buffer allocation blocked above.
nowMs = time.milliseconds();synchronized(dq){// Need to check if producer is closed again after grabbing the dequeue lock.if(closed)thrownewKafkaException("Producer closed while send in progress");RecordAppendResult appendResult =tryAppend(timestamp, key, value, headers, callback, dq, nowMs);if(appendResult !=null){// Somebody else found us a batch, return the one we waited for! Hopefully this doesn't happen often...return appendResult;}// 封装内存bufferMemoryRecordsBuilder recordsBuilder =recordsBuilder(buffer, maxUsableMagic);// 再次封装(得到真正的批次大小)ProducerBatch batch =newProducerBatch(tp, recordsBuilder, nowMs);FutureRecordMetadata future =Objects.requireNonNull(batch.tryAppend(timestamp, key, value, headers,
callback, nowMs));// 向队列的末尾添加批次
dq.addLast(batch);
incomplete.add(batch);// Don't deallocate this buffer in the finally block as it's being used in the record batch
buffer =null;returnnewRecordAppendResult(future, dq.size()>1|| batch.isFull(),true,false);}}finally{if(buffer !=null)
free.deallocate(buffer);
appendsInProgress.decrementAndGet();}
发送数据的函数: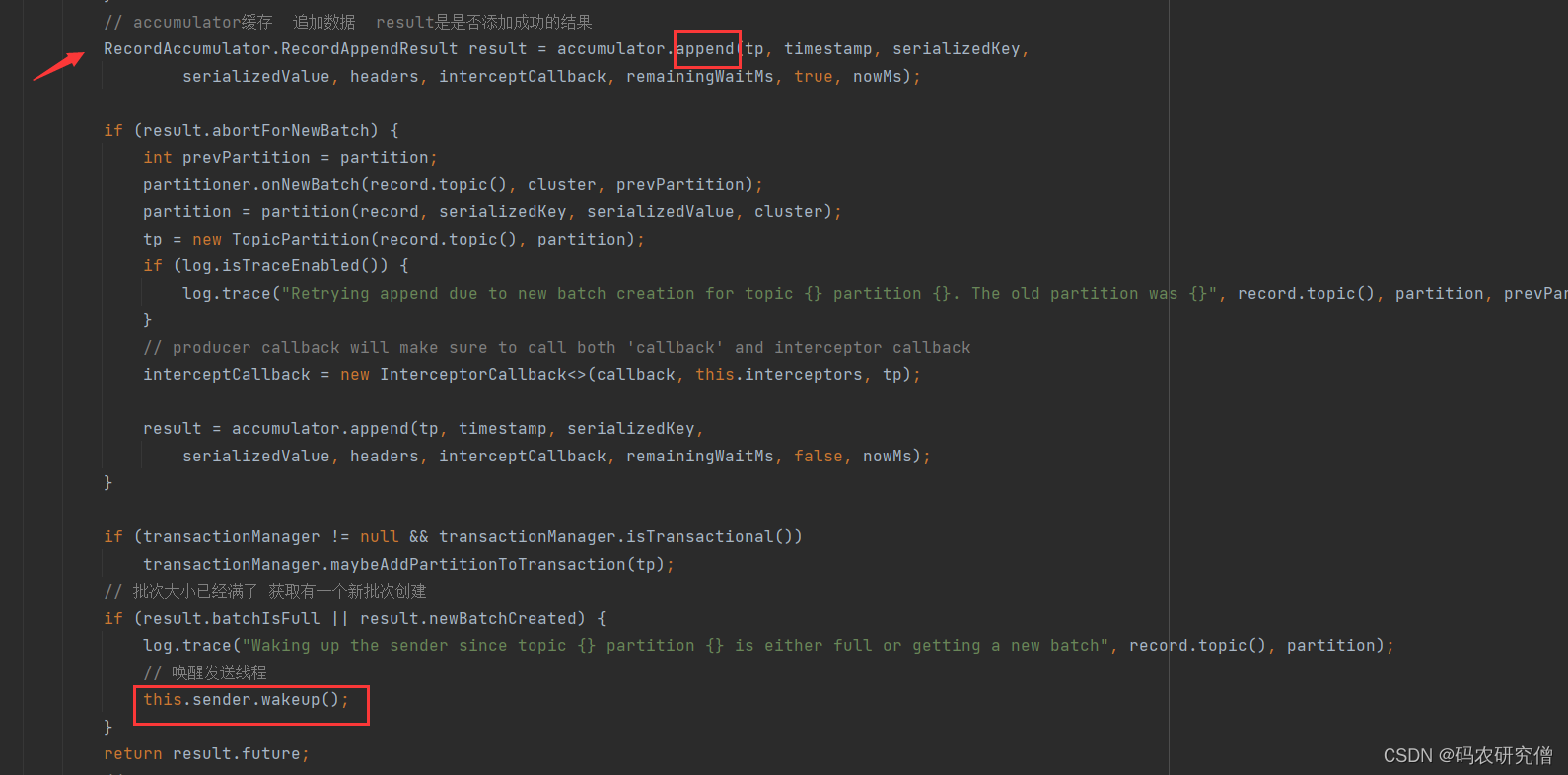
10.1.3 sender线程
通过事务操作,之后通过发送数据以及发送数据结果
特别是临界判断条件: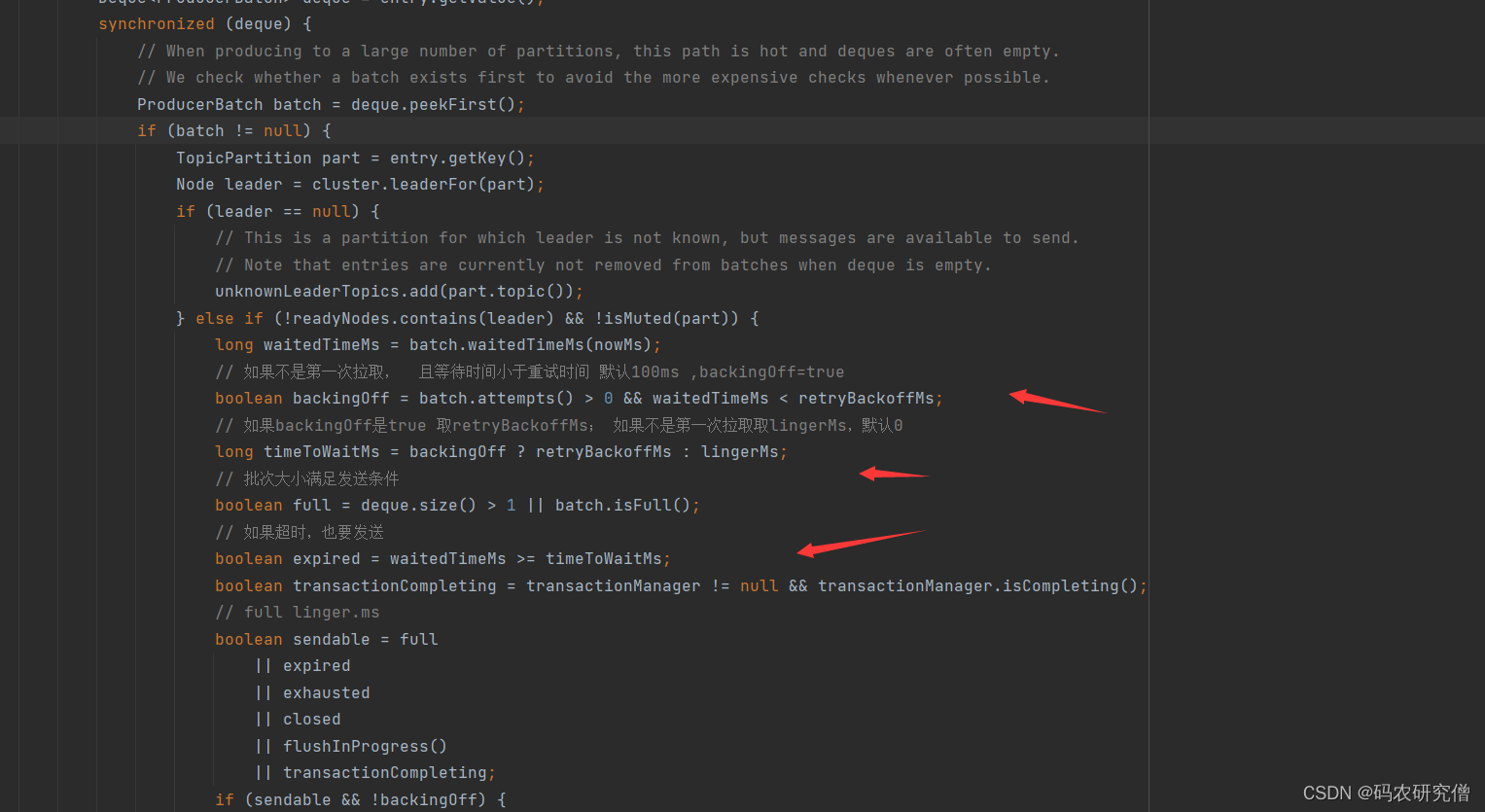
10.1.4 分区函数
专门挑个重点函数讲解下
privateintpartition(ProducerRecord<K,V>record,byte[] serializedKey,byte[] serializedValue,Cluster cluster){Integer partition =record.partition();// 如果指定分区,按照指定分区配置return partition !=null?
partition :
partitioner.partition(record.topic(),record.key(), serializedKey,record.value(), serializedValue, cluster);}
如果为null。则走默认的分区:
partitioner.partition
默认的分区如下:
publicintpartition(String topic,Object key,byte[] keyBytes,Object value,byte[] valueBytes,Cluster cluster,int numPartitions){// 没有指定keyif(keyBytes ==null){// 按照粘性分区处理return stickyPartitionCache.partition(topic, cluster);}// 如果指定key,按照key的hashcode值 对分区数求模// hash the keyBytes to choose a partitionreturnUtils.toPositive(Utils.murmur2(keyBytes))% numPartitions;}
10.2 消费者(java源码)
总体流程:(每一个过程消费者都会和coordinator保持心跳(默认3s),一旦超时(45s),触发消费者平衡。消费者处理时间(超过5分钟)也会触发再平衡)
- 消费者发送一个joingroup的请求
- coordinator选出一个消费者作为leader以及要消费的topic情况发送给leader
- 消费者leader负责指定消费方案并且发送给coordinator
- coordinator分发消费方案给其他消费者
10.2.1 初始化
入口函数
consumer = new KafkaConsumer<>(props);
dowork函数(订阅拉取数据)
核心代码(截取核心模块)
// 消费组平衡GroupRebalanceConfig groupRebalanceConfig =newGroupRebalanceConfig(config,GroupRebalanceConfig.ProtocolType.CONSUMER);// 获取消费者组idthis.groupId =Optional.ofNullable(groupRebalanceConfig.groupId);// 客户端idthis.clientId = config.getString(CommonClientConfigs.CLIENT_ID_CONFIG);// log函数// 客户端请求服务端等待时间request.timeout.ms 默认是30sthis.requestTimeoutMs = config.getInt(ConsumerConfig.REQUEST_TIMEOUT_MS_CONFIG);// 重试时间 100this.retryBackoffMs = config.getLong(ConsumerConfig.RETRY_BACKOFF_MS_CONFIG);// 拦截器,key valkue反序列化
之后配置相关信息,连接集群: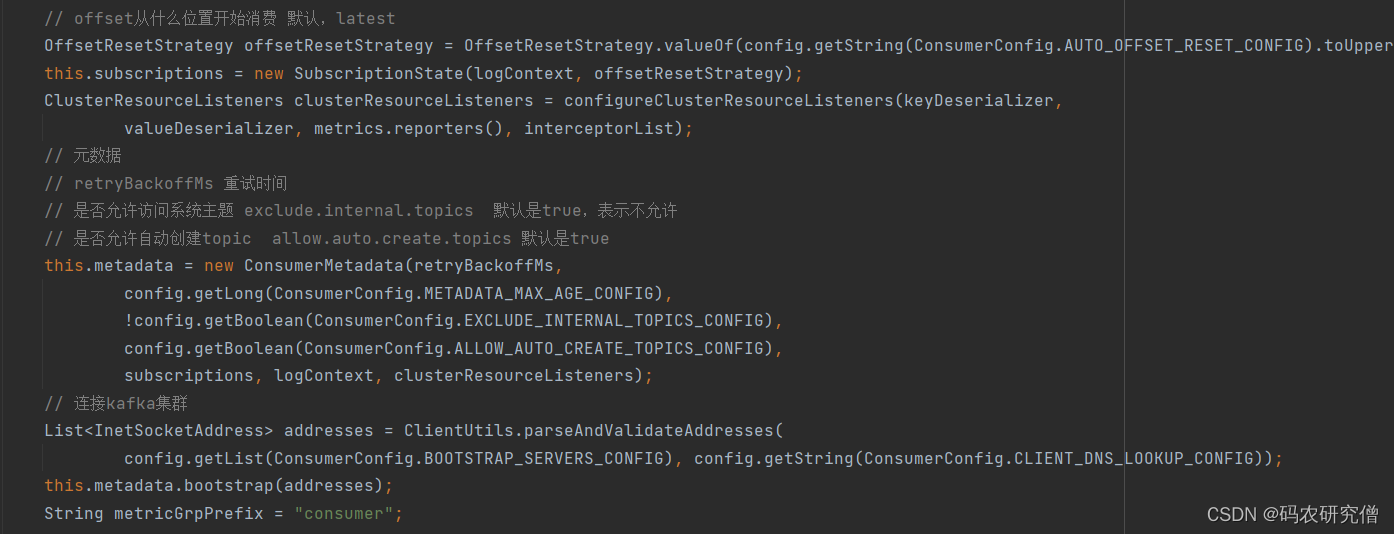
参数:
// 创建客户端对象// 连接重试时间 默认50ms// 最大连接重试时间 默认1s// 发送缓存 默认128kb// 接收缓存 默认64kb// 客户端请求服务端等待时间request.timeout.ms 默认是30sNetworkClient netClient =newNetworkClient(// 消费者客户端// 客户端请求服务端等待时间request.timeout.ms 默认是30sthis.client =newConsumerNetworkClient(// 消费者分区分配策略this.assignors =ConsumerPartitionAssignor.getAssignorInstances(
config.getList(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG),
config.originals(Collections.singletonMap(ConsumerConfig.CLIENT_ID_CONFIG, clientId)));// no coordinator will be constructed for the default (null) group id// 为消费者组准备的// auto.commit.interval.ms 自动提交offset时间 默认5sthis.coordinator =!groupId.isPresent()?null:newConsumerCoordinator(groupRebalanceConfig,// 配置抓数据的参数// fetch.min.bytes 默认最少一次抓取1个字节// fetch.max.bytes 默认最多一次抓取50m// fetch.max.wait.ms 抓取等待最大时间 500ms// max.partition.fetch.bytes 默认是1m// max.poll.records 默认一次处理500条this.fetcher =newFetcher<>(
logContext,
10.2.1 订阅主题
通过dowork函数
核心代码如下:
@Overridepublicvoidsubscribe(Collection<String> topics,ConsumerRebalanceListener listener){acquireAndEnsureOpen();try{maybeThrowInvalidGroupIdException();// 要订阅的主题如果为null ,直接抛异常if(topics ==null)thrownewIllegalArgumentException("Topic collection to subscribe to cannot be null");// 要订阅的主题如果为空if(topics.isEmpty()){// treat subscribing to empty topic list as the same as unsubscribingthis.unsubscribe();}else{// 正常的处理操作for(String topic : topics){// 如果为空 抛异常if(Utils.isBlank(topic))thrownewIllegalArgumentException("Topic collection to subscribe to cannot contain null or empty topic");}throwIfNoAssignorsConfigured();
fetcher.clearBufferedDataForUnassignedTopics(topics);
log.info("Subscribed to topic(s): {}",Utils.join(topics,", "));// 订阅主题(判断你是否需要更新订阅的主题; 主题了一个监听器listener)if(this.subscriptions.subscribe(newHashSet<>(topics), listener))// 更新订阅信息
metadata.requestUpdateForNewTopics();}}finally{release();}}
监听器函数如下:
publicsynchronizedbooleansubscribe(Set<String> topics,ConsumerRebalanceListener listener){// 注册负载均衡监听器registerRebalanceListener(listener);// 按照主题自动订阅模式setSubscriptionType(SubscriptionType.AUTO_TOPICS);// 判断是否需要更改订阅的主题returnchangeSubscription(topics);}
判断是否需要更改:
privatebooleanchangeSubscription(Set<String> topicsToSubscribe){// 如果传入的topics 和以前订阅的主题一致,那就不需要更改对应订阅的主题if(subscription.equals(topicsToSubscribe))returnfalse;
subscription = topicsToSubscribe;returntrue;}
10.3 broker (scala源码)
总体流程:
broker启动一个注册一个,controller谁先注册谁就是leader节点,谁抢占到了leader节点,第一时间就会监听broker节点的相关变化,由controller节点决定leader(主要通过isr为存活前提,排在AR前面节点则为leader),之后controller将其节点的相关信息上传到zookeeper,其他controller从zookeeper同步相关信息
核心代码如下:
def main(args: Array[String]):Unit={try{// 获取相关参数val serverProps = getPropsFromArgs(args)// 创建服务val server = buildServer(serverProps)try{if(!OperatingSystem.IS_WINDOWS &&!Java.isIbmJdk)new LoggingSignalHandler().register()}catch{case e: ReflectiveOperationException =>
warn("Failed to register optional signal handler that logs a message when the process is terminated "+s"by a signal. Reason for registration failure is: $e", e)}// attach shutdown handler to catch terminating signals as well as normal termination
Exit.addShutdownHook("kafka-shutdown-hook",{try server.shutdown()catch{case _: Throwable =>
fatal("Halting Kafka.")// Calling exit() can lead to deadlock as exit() can be called multiple times. Force exit.
Exit.halt(1)}})// 启动服务try server.startup()catch{case _: Throwable =>// KafkaServer.startup() calls shutdown() in case of exceptions, so we invoke `exit` to set the status code
fatal("Exiting Kafka.")
Exit.exit(1)}
server.awaitShutdown()}catch{case e: Throwable =>
fatal("Exiting Kafka due to fatal exception", e)
Exit.exit(1)}
Exit.exit(0)}
版权归原作者 码农研究僧 所有, 如有侵权,请联系我们删除。