
3D Gaussian Splatting Linux端部署指南
朋友浩哥说环境是最难配的,配好环境,你就成功了一半!
项目地址
- windows部署版本:https://github.com/jonstephens85/gaussian-splatting-Windows
- windows和linux部署版本:https://github.com/graphdeco-inria/gaussian-splatting
部署记录
- 根据官方的环境配置environment.yml配置好环境,发现出了种种问题,先不管。
- 按教程准备好图片数据:【AI生成场景新突破】3D Gaussian Splatting入门指南_哔哩哔哩_bilibili+[视频文章],由于我电脑没有gpu,linux服务器(rtx4090-24G)有,自己准备数据集需要用windows的colmap程序进行相机位姿计算,虽然可以下载no cuda版本,但是比较慢,于是直接使用官方数据集,建议先试用小型单物体数据集,训练速度快,如官方的卡车图片,这里使用官方covert好的tuck数据集,然后进行训练:
python train.py -s data/truck/
报错:没有子模块,原因其一,git clone添加了--recursive,但是由于网络原因没将子模块下载下来,原因二,实验时间2024年1月25官方源码缺少一个子模块,找不到了,在之前网友网盘备份那里复制一份。
3. 子模块有了,手动继续安装子模块:
pip install submodules/diff-gaussian-rasterizatio/
pip install submodules/simple_knn/
又有报错:cuda和pytorch不匹配的问题,看来必须处理环境配置问题了。由于环境限制:linux服务器使用的是nvidia545显卡驱动,cuda12.3,备用cuda11.8,不能随便更改显卡驱动版本,对应的cuda版本应为11.8以上才能调用显卡。在使用官方环境配置environment.yml发现出现问题,在下载子模块时总是报错,由于安装子模块
pip install
使用的也是服务器系统环境的cuda库,更改bashrc环境变量选择服务器系统安装的cuda12.3和cuda11.8,都无法编译官方的pytorch1.12.1
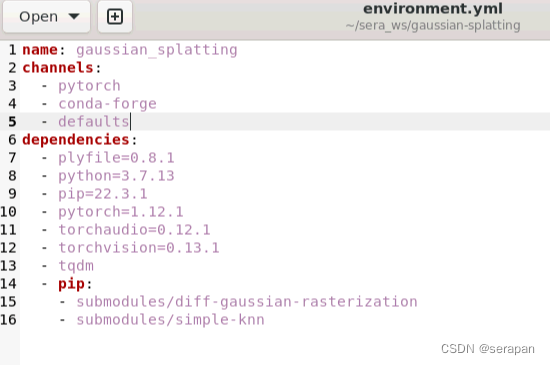
4. 于是不用官方的,根据pytorch官方文档,使用pip方式,而非conda方式下载包,自己手动下载符合系统cuda环境的pytorch:(下面任选其一)
#torch 2.1.2
pip install --pre torch torchvision torchaudio -i https://pypi.tuna.tsinghua.edu.cn/simple
# CUDA 11.8
pip install torch==2.1.1 torchvision==0.16.1 torchaudio==2.1.1 --index-url https://download.pytorch.org/whl/cu118
# CUDA 12.1
pip install torch==2.1.1 torchvision==0.16.1 torchaudio==2.1.1 --index-url https://download.pytorch.org/whl/cu121
5. 发现不管下载CUDA 11.8的pytorch还是CUDA 12.1版本的pytorch,都需要cuda12.1,于是下载cuda12.1,**系统允许存在多个cuda版本,实际使用时按需选择,更改bashrc****环境变量****或者为执行的代码添加一个环境路径参数就行。**下面是有效的一种安装cuda12.1的方式,**注意的是,安装时不要勾选下载驱动,否则会将545的****显卡****驱动覆盖掉。**
wget https://developer.download.nvidia.com/compute/cuda/12.1.1/local_installers/cuda_12.1.1_530.30.02_linux.run
sudo sh cuda_12.1.1_530.30.02_linux.run
6. 更改bashrc环境变量,然后把cudnn的东西也复制到cuda12.1中,确保深度学习的部分也能用: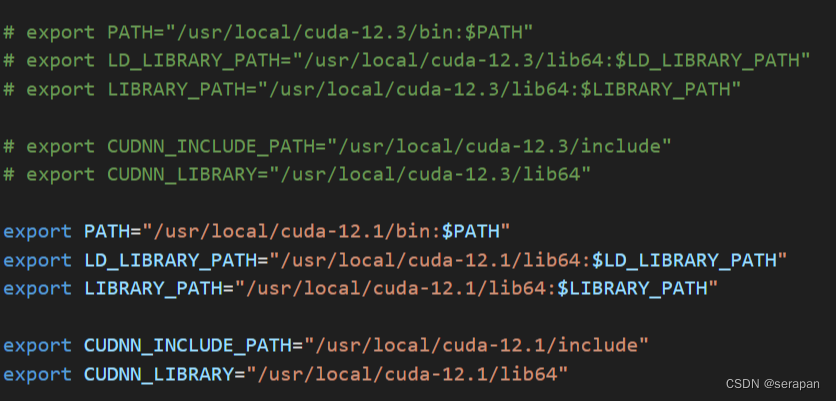
export PATH="/usr/local/cuda-12.1/bin:$PATH"
export LD_LIBRARY_PATH="/usr/local/cuda-12.1/lib64:$LD_LIBRARY_PATH"
export LIBRARY_PATH="/usr/local/cuda-12.1/lib64:$LIBRARY_PATH"
export CUDNN_INCLUDE_PATH="/usr/local/cuda-12.1/include"
export CUDNN_LIBRARY="/usr/local/cuda-12.1/lib64
最终的环境配置如下environment_sera.yml,但未试验:
name: gaussian_splatting
channels:
- pytorch
- conda-forge
- defaults
dependencies:
- plyfile=0.8.1
- python=3.10.12
- pip=22.3.1
- pytorch=2.1.1
- torchaudio=2.1.1
- torchvision=0.16.1
- tqdm
- pip:
- submodules/diff-gaussian-rasterization
- submodules/simple-knn
7. bashrc里更改环境变量使用cuda12.1库,重新下载子模块
pip install submodules/diff-gaussian-rasterization
,提示没有glm:fatal error: glm/glm.hpp: No such file or directory
sudo apt-get install libglm-dev
8. 重新下载子模块
submodules/diff-gaussian-rasterization
,提示成功下载子模块
进行训练,发现又少了一个子模块
submodules/simple_knn
:
9. 继续下载该子模块,下载成功
pip install submodules/simpe_knn/

10. 至此,环境问题就解决掉了,继续训练数据,15分钟训练成功:
python train.py -s data/truck/

L1是L1损失,PSNR是图像峰值信噪比,单位是dB,数值越大表示失真越小。因为数值越大代表MSE越小。MSE越小代表两张图片越接近,失真就越小。
好家伙,gpu利用率直接100: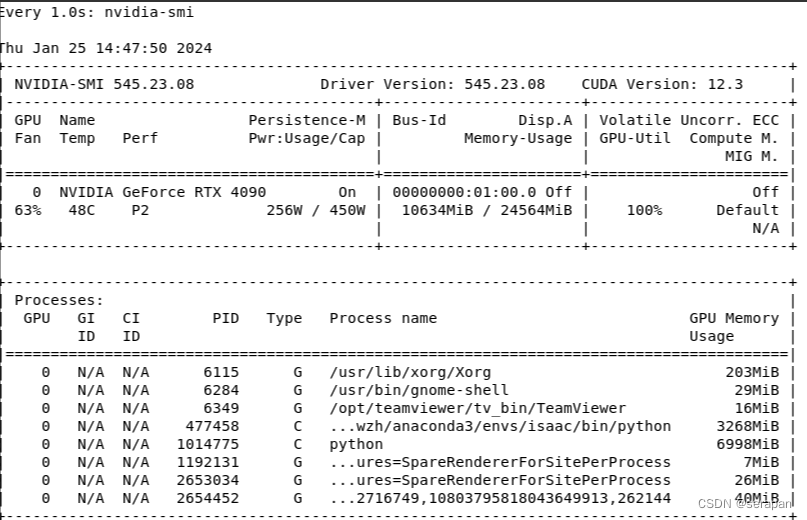
由于训练未用
-m
参数指定用模型导出路径,生成的模型文件在训练的模型结构如下: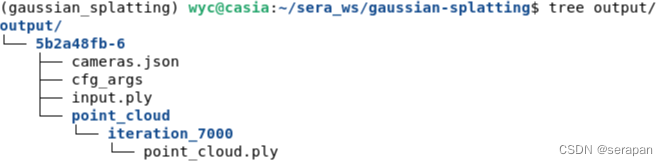
若用
-m
参数指定用模型导出路径,再进行训练,模型文件有如下结构:
python train.py -s data/truck/ -m data/output
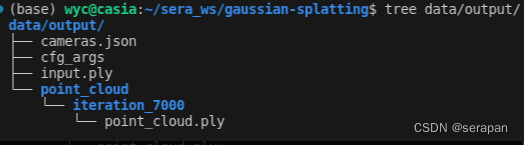
10分钟训练完了train,23分钟训练完了drjohnson
事后实验,使用cuda12.3也可以进行训练,说明训练跟使用哪个cuda版本没有关系,而下载子模块需要对应的cuda版本,因为pip下载子模块时,构建 PyTorch C++ 扩展的 Python setuptools 脚本需要使用CUDA来加速运算,系统环境中需要使用pytorch对应的cuda版本才能顺利安装。
11. Linux端在线远程可视化训练进程
由于我的windows电脑没有gpu,不能用SIBR_gaussianViewer_app的windows版本,于是选择使用官方文档中的第二种方案:网络远程可视化,即linux自行构建SIBR_gaussianViewer_app,由于官方源码缺少SIBR_viewers的文件,再从网友网盘备份中拷贝一份进行构建:
Ubuntu的 22.04在运行项目安装程序之前,需要安装一些依赖项。
# Dependencies
sudo apt install -y libglew-dev libassimp-dev libboost-all-dev libgtk-3-dev libopencv-dev libglfw3-dev libavdevice-dev libavcodec-dev libeigen3-dev libxxf86vm-dev libembree-dev
#Project setup
cd SIBR_viewers
cmake -Bbuild . -DCMAKE_BUILD_TYPE=Release # add -G Ninja to build faster
cmake --build build -j32 --target install #j32使用系统最大内核数32,可以按需要分配内核数执行
报错:
找到:/home/wyc/sera_ws/gaussian-splatting/SIBR_viewers/extlibs/CudaRasterizer/subbuild/CMakeLists.txt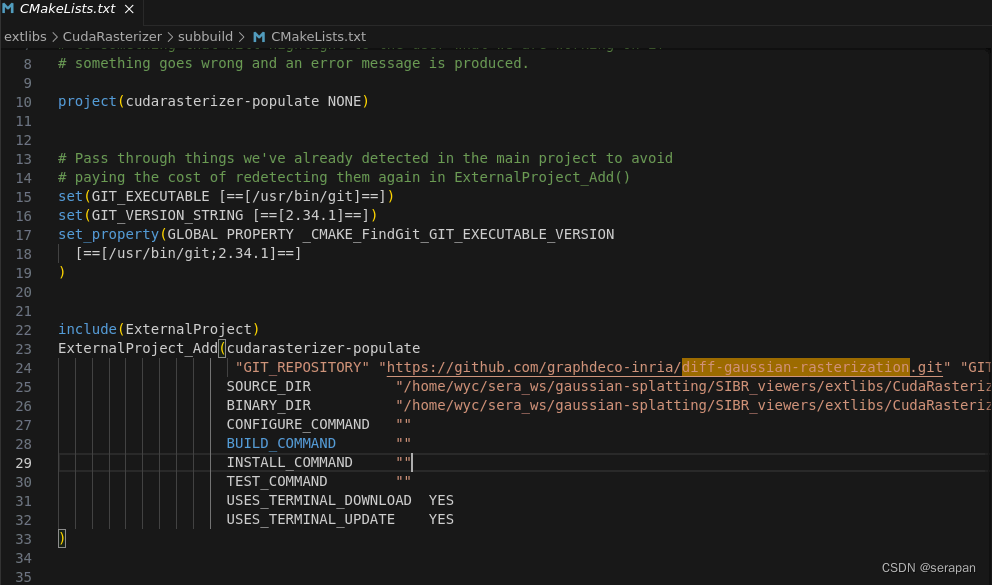
更改为本地路径
include(ExternalProject)
ExternalProject_Add(cudarasterizer-populate
URL "/home/wyc/sera_ws/gaussian-splatting/submodules/diff-gaussian-rasterization"
SOURCE_DIR "/home/wyc/sera_ws/gaussian-splatting/SIBR_viewers/extlibs/CudaRasterizer/CudaRasterizer"
BINARY_DIR "/home/wyc/sera_ws/gaussian-splatting/SIBR_viewers/extlibs/CudaRasterizer/build"
CONFIGURE_COMMAND ""
BUILD_COMMAND ""
INSTALL_COMMAND ""
TEST_COMMAND ""
USES_TERMINAL_DOWNLOAD YES
USES_TERMINAL_UPDATE YES
)
罪魁祸首,下面的内容删掉/home/wyc/sera_ws/gaussian-splatting/SIBR_viewers/extlibs/CudaRasterizer/subbuild/cudarasterizer-populate-prefix/src/cudarasterizer-populate-stamp/cudarasterizer-populate-gitinfo.txt
再执行
cmake -Bbuild . -DCMAKE_BUILD_TYPE=Release
,执行成功!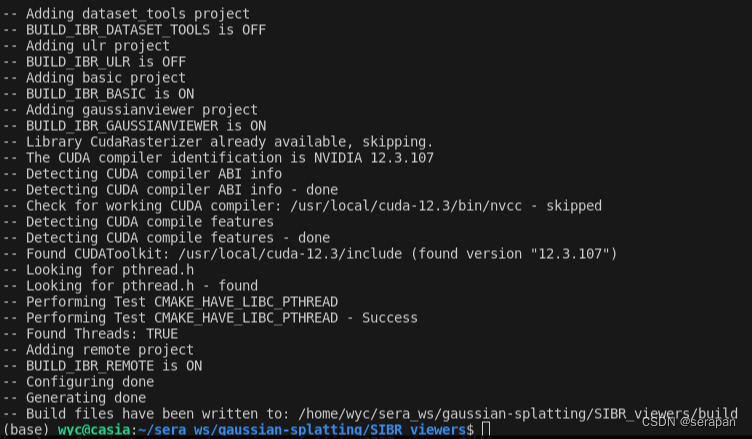
执行
cmake --build build -j32 --target install
,成功!
经过试验发现,远程可视化软件只能连接正在训练的模型文件,才可以运行远程可视化:
python train.py -s data/truck/ -m data/output #调用GPU进行训练
./SIBR_remoteGaussian_app -s /home/wyc/sera_ws/gaussian-splatting/data/output #对正在训练的模型文件进行可视化

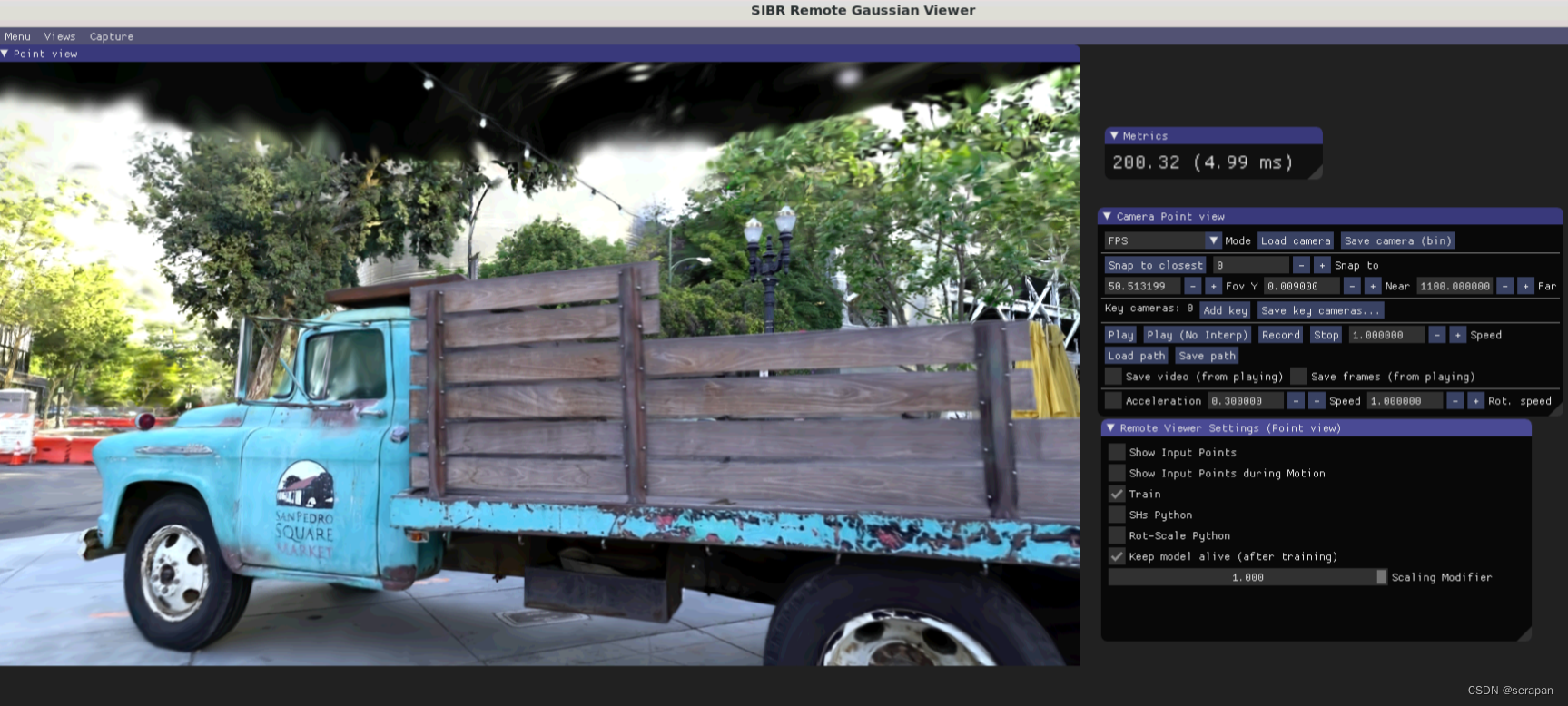
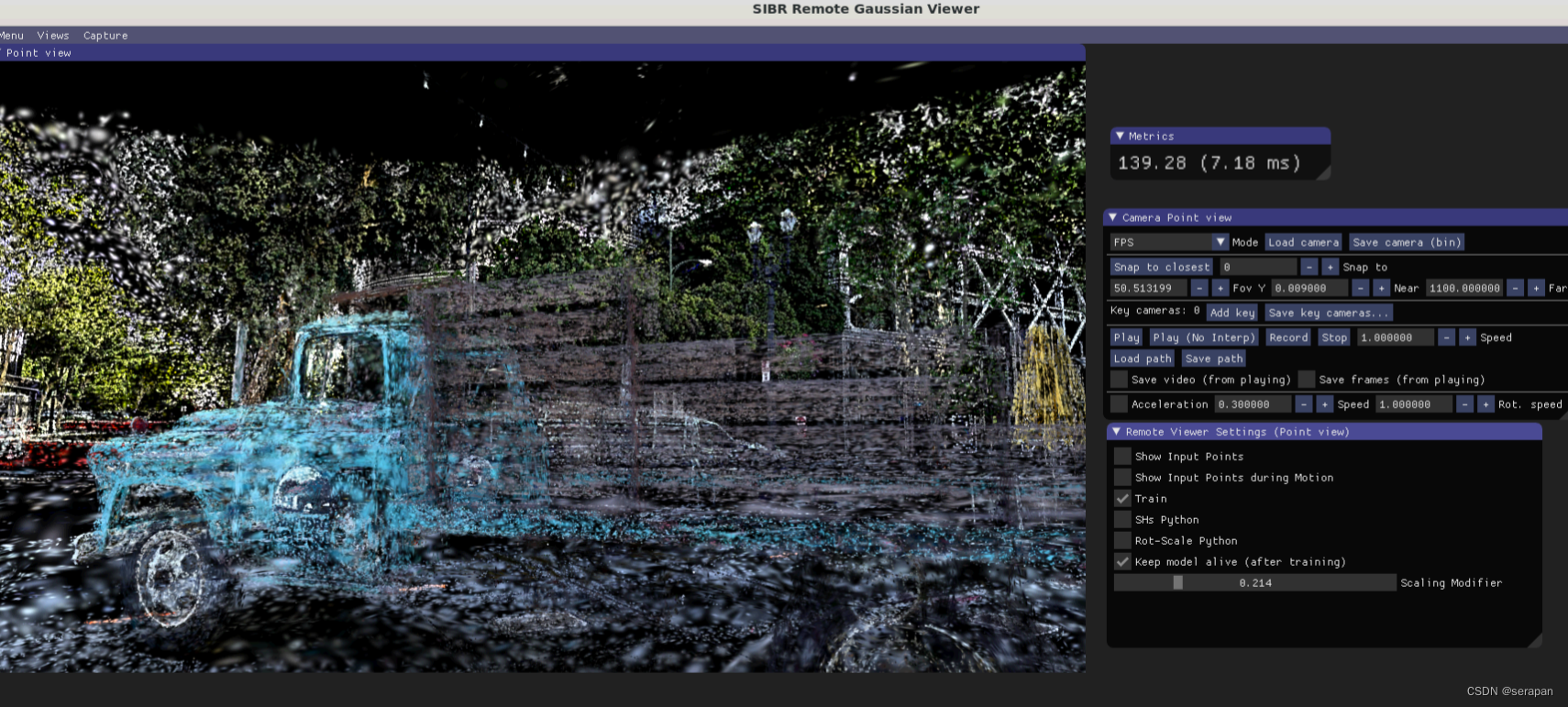
准备自己的数据
需要软件:COLMAP、FFMPEG
参考博客:
3D Gaussian Splatting复现-CSDN博客
Linux 编译安装colmap_linux colmap-CSDN博客
- FFMPEG安装:
// 删除所有安装的 ffmpeg
sudo apt-get remove ffmpeg
sudo apt-get purge ffmpeg
// 删除 Anaconda ffmpeg 模块
conda remove ffmpeg
重新安装
sudo apt-get install ffmpeg
2. COLMAP安装:
安装依赖:
sudo apt-get install \
git \
cmake \
ninja-build \
build-essential \
libboost-program-options-dev \
libboost-filesystem-dev \
libboost-graph-dev \
libboost-system-dev \
libeigen3-dev \
libflann-dev \
libfreeimage-dev \
libmetis-dev \
libgoogle-glog-dev \
libgtest-dev \
libsqlite3-dev \
libglew-dev \
qtbase5-dev \
libqt5opengl5-dev \
libcgal-dev \
libceres-dev
配置和编译 COLMAP:
git clone https://github.com/colmap/colmap.git
cd colmap
mkdir build
cd build
cmake .. -GNinja #CMake预处理,生成Ninja构建系统所需的文件
ninja #默认使用系统最大可用cpu核心数进行编译,如果系统cpu有32个核,等效与ninja -j32
sudo ninja install
ninja
报错: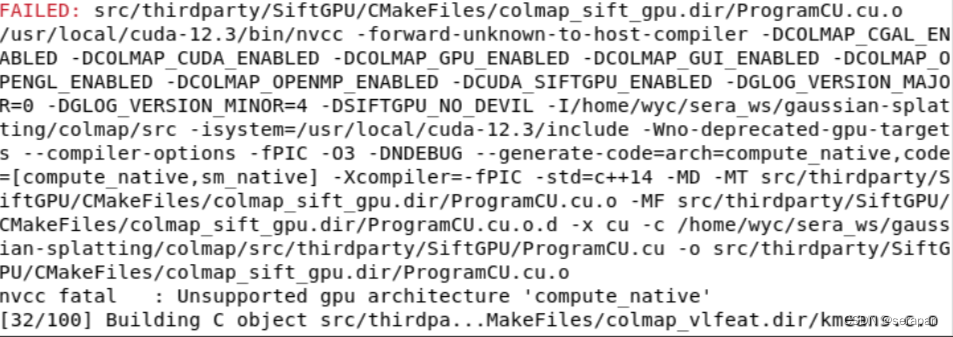
解决记录:
写个cuda程序,查询自己gpu架构版本
#include <iostream>
#include <cuda_runtime.h>
int main() {
cudaDeviceProp prop;
cudaGetDeviceProperties(&prop, 0); // Assumes one GPU device
std::cout << "GPU Architecture: " << prop.major << "." << prop.minor << std::endl;
return 0;
}
编译并运行
nvcc query_gpu_arch.cu -o query_gpu_arch
./query_gpu_arch

在CMakeList文件中添加一句设置gpu架构版本也没用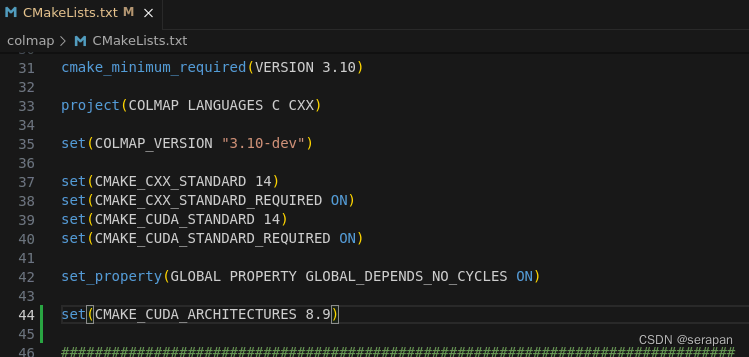
set(CMAKE_CUDA_ARCHITECTURES 8.9)
猜测分支3.10-dev太新不太支持自己的cuda,
git checkout 3.9
切换分支到3.9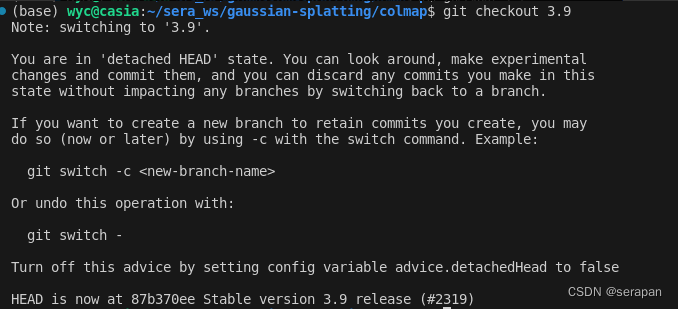
继续
cmake .. -GNinja
,报错:
添加
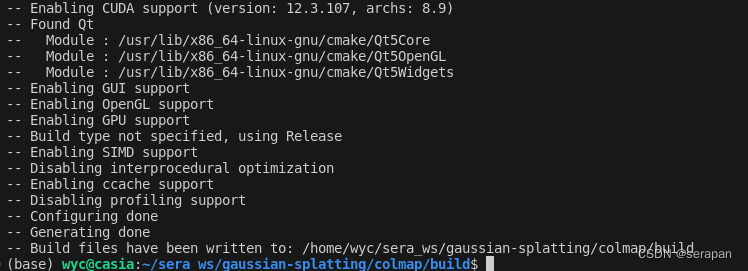
set(CMAKE_CUDA_ARCHITECTURES 8.9)
后继续
cmake .. -GNinja
,
ninja
编译失败,跟3.10-dev一样的报错,转而猜想gpu架构设置的格式不对,结合报错中出现的提示,将
8.9
改成
70,80,89,90
后,
cmake .. -GNinja
然后
ninja
都编译成功,反推之前3.10-dev也是这个原因,经过测试,正是gpu架构设置的格式的问题,不能带小数点。官方文档也给出了提示哈哈没看到:
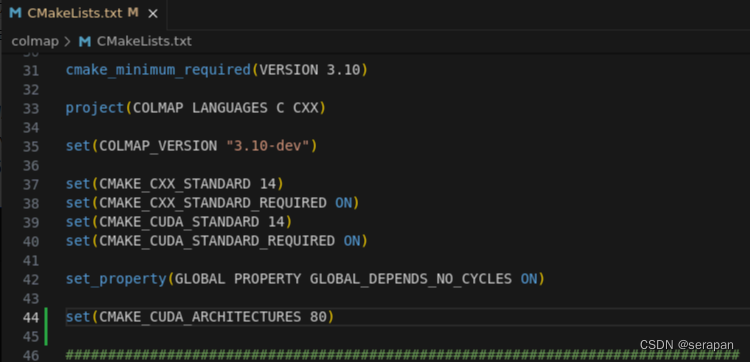
然后
sudo ninja install
安装colmap成功!
运行 COLMAP:
colmap -h
colmap gui
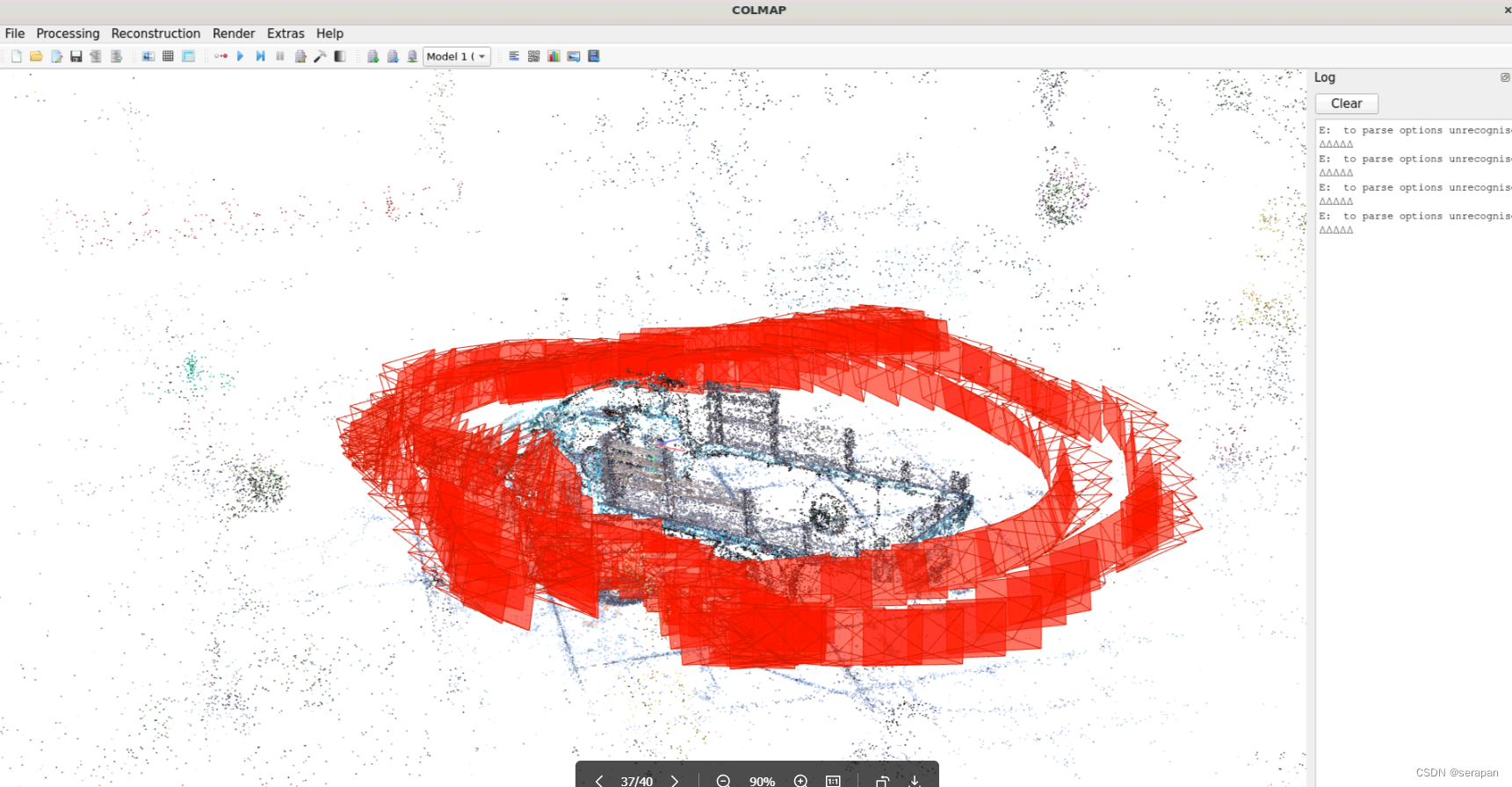
打开官方数据看看点云和计算的相机位姿,File->Import model->data->truck->spase->0
使用ffmpeg和colmap从视频准备数据:
参考视频:3D Gaussian Splatting本地部署【windows系统免环境配置】_哔哩哔哩_bilibili + [网盘code]
准备自己的视频,放在data文件夹下,
写一个脚本/home/wyc/sera_ws/gaussian-splatting/train_video.py:
import os
import subprocess
# 视频绝对路径
video_path = r"/home/wyc/sera_ws/gaussian-splatting/data/mouse.mp4"
# 切分帧数,每秒多少帧
fps = 2
# 获取视频文件名(不包含扩展名)
video_name = os.path.splitext(os.path.basename(video_path))[0]
# 获取视频文件所在目录
folder_path = os.path.dirname(video_path)
# 数据保存路径
data_path = os.path.join(folder_path, video_name)
os.makedirs(data_path, exist_ok=True)
# 图片保存路径
images_path = os.path.join(data_path, 'input')
os.makedirs(images_path, exist_ok=True)
# 模型保存路径
model_path = os.path.join(data_path, 'output')
os.makedirs(model_path, exist_ok=True)
# 脚本运行
# 视频切分脚本
command = f'ffmpeg -i {video_path} -qscale:v 1 -qmin 1 -vf fps={fps} {images_path}/%05d.jpg'
subprocess.run(command, shell=True)
# COLMAP估算相机位姿
command = f'python convert.py -s {data_path}'
subprocess.run(command, shell=True)
# 模型训练脚本,模型会保存在output路径下
command = f'python train.py -s {data_path} -m {model_path}'
subprocess.run(command, shell=True)
SIBR_remoteGaussian在线远程可视化
执行脚本,会得到如下目录结构,并执行可视化:
python train_video.py
./SIBR_remoteGaussian_app -s /home/wyc/sera_ws/gaussian-splatting/data/mouse/output
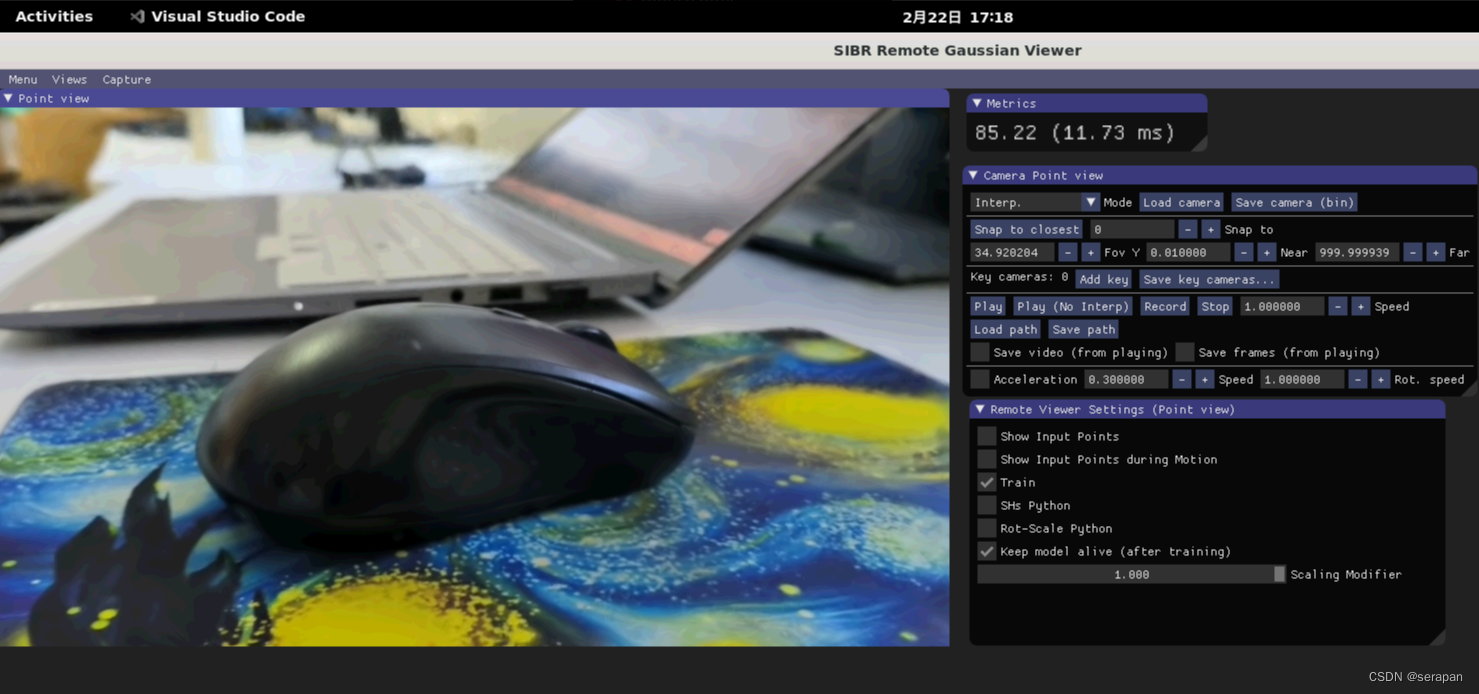
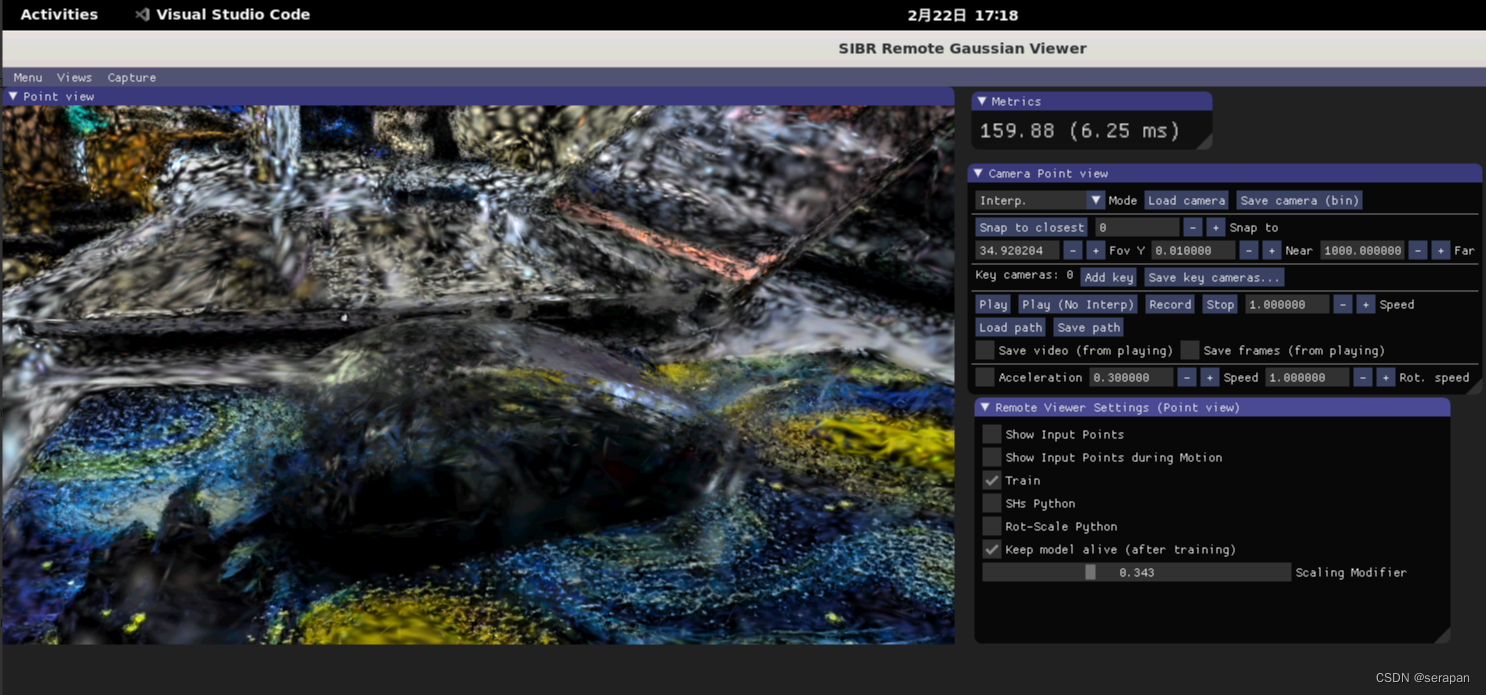
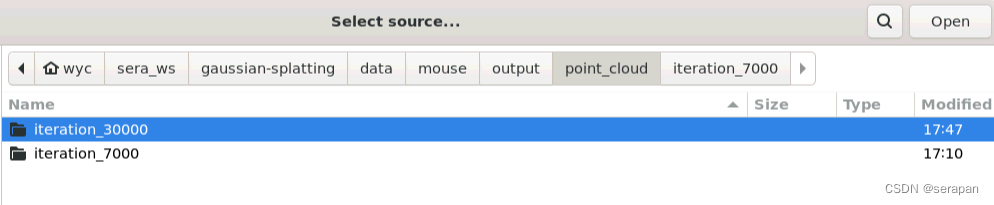
训练完毕,打开colmap gui选择Import model from查看7000步点云和30000步点云:
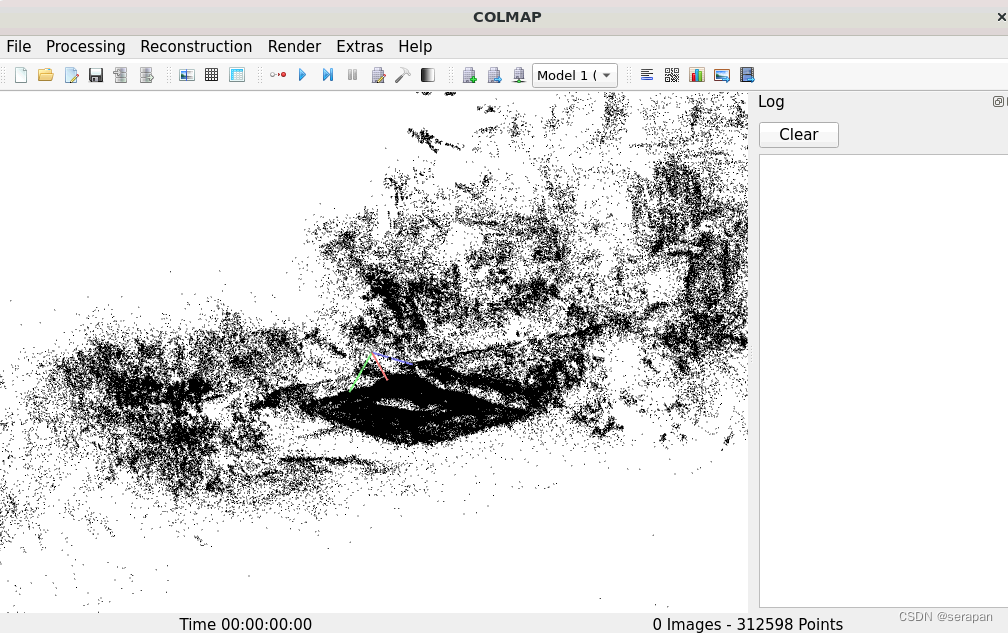
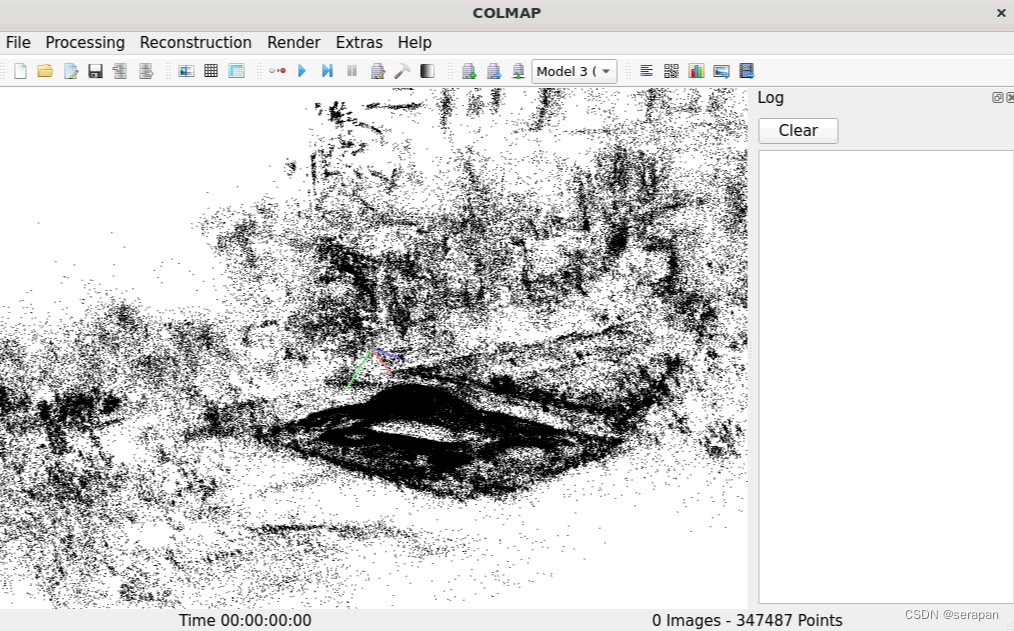
补充:sibr_3Dgaussian离线可视化训练好的模型
后面发现SIBR_gaussianViewer这个离线可视化程序也是可以运行的,跟SIBR_gaussianViewer windows版本是一样的,我之前以为只能使用sibr_remoteGaussian在线远程可视化程序呢。

执行,-m参数带的是训练好的模型:
./SIBR_gaussianViewer_app -m /home/wyc/sera_ws/gaussian-splatting/data/mouse/output

版权归原作者 serapan 所有, 如有侵权,请联系我们删除。