
一、Zookeeper概述
1.Zookeeper概念
Zookeeper 是一个 分布式协调服务 的开源框架。主要作用是为分布式系统提供协调服务,包括但不限于:分布式锁、统一命名服务、配置管理、负载均衡、主控服务器选举以及主从切换等。
ZooKeeper本质上是一个分布式的小文件存储系统。提供类似与文件系统目录树方式的数据存储,并且可以对树中的节点进行有效管理。从而用来维护和监控存储的数据的状态变化。通过监控这些数据状态的变化,实现基于数据的集群管理。
2.Zookeeper = 文件系统 + 监听通知机制 + ACL
①文件系统
Zookeeper维护一个类似文件系统的数据结构(如下示意图),每一个子目录项(如app1)都被称作为znode(目录节点),和文件系统一样,我们能够自由的对一个znode进行CRUD(增加(Create)、读取查询(Retrieve)、更新(Update)和删除(Delete)),也可以在znode下进行子znode的CRUD,唯一不同的是,znode是可以存储数据的。
补充:znode类型
PERSISTENT:持久化节点
一旦客户端(client)在zookeeper服务器(server)上创建了一个持久化节点,只要客户端(client)不删除该节点,不论客户端(client)与zookeeper(server)断开/重连多少次,该节点依然存在。
PERSISTENT_SEQUENTIAL:持久化顺序编号目录节点
一旦客户端(client)在zookeeper服务器(server)上创建了一个持久化节点,只要客户端(client)不删除该节点,不论客户端(client)与zookeeper(server)断开/重连多少次,该节点依然存在。只是zookeeper给该节点名多追加了一个编号(例如:/app123456,这个编号是zookeeper给的)
EPHEMERAL:临时目录节点
客户端(client)在zookeeper(server)上创建了一个节点,但是,当客户端(client)与zookeeper(server)断开连接之后,该节点就会被zookeeper(server)删除。
EPHEMERAL_SEQUENTIAL:临时顺序编号目录节点
客户端(client)在zookeeper(server)上创建了一个节点,但是,当客户端(client)与zookeeper(server)断开连接之后,该节点就会被zookeeper(server)删除。只是zookeeper给该节点名多追加了一个编号
②监听通知机制
简单来说:client 注册监听它所关心的目录节点,当该目录节点发生变化(节点被改变、被删除、其子目录节点有增删改情况)时,ZK server会通过watcher监听机制将消息推送给client。(详情请看 四、Zookeeper Watch )
③ACL(access control list 访问控制列表)
zookeeper在分布式系统中承担中间件的作用,它管理的每一个节点上都可能存储着重要的信息,因为应用可以读取到任意节点,这就可能造成安全问题,ACL的作用就是帮助zookeeper实现权限控制。
zookeeper的权限控制基于节点,每个znode可以有不同的权限。
子节点不会继承父节点的权限,访问不了该节点,并不代表访问不到其子节点。
结构:schema :id :permission
一个 ACL 权限设置通常可以分为 3 部分,分别是:权限模式(Scheme)、授权对象(ID)、权限信息(Permission)。最终组成一条例如“scheme :id :permission”格式的 ACL 请求信息。下面我们具体看一下这 3 部分代表什么意思:
补充:ACL命令用法
Schema: 鉴权策略
schema描述world默认方式,相当于全世界都能访问digest即: “用户名+密码” 这种认证方式,也是业务中常用的ip使用IP认证的方式auth代表已经认证通过的用户(cli中可以通过addauth digest user:pwd 来添加当前上下文中的授权用户)
授权对象 ID
权限模式授权对象world只有一个ID:“anyone”digest自定义,通常是用户名:密码,在ACl中使用时,表达式将是username:base64编码的SHA1.例如"admin:u53OoA8hprX59uwFsvQBS3QuI00="(明文密码为123456)IP通常是一个Ip地址或者是Ip段, 例如192.168.xxx.xxx或者 192.168.xxx.xxx/xxxsuper与digest模式一样
权限Permission
权限简写描述createc创建权限,授予权限的对象可以在数据节点下创建子节点;readr读取权限,授予权限的对象可以读取该节点的内容以及子节点的信息;writew更新权限,授予权限的对象可以更新该数据节点;
delete
d删除权限,授予权限的对象可以删除该数据节点的子节点;admina管理者权限,授予权限的对象可以对该数据节点体进行 ACL 权限设置。
这5种权限中,delete是指对子节点的删除权限,其它4种权限指对自身节点的操作权限。每个节点都有维护自身的 ACL 权限数据,即使是该节点的子节点也是有自己的 ACL 权限而不是直接继承其父节点的权限
3.session会话机制
client请求和服务端建立连接,服务端会保留和标记当前client的session,包含 session过期时间、sessionId ,然后服务端开始在session过期时间的基础上倒计时,在这段时间内,client需要向server发送心跳包,目的是让server重置session过期时间。
4、Zookeeper特性
①全局数据一致性(<—最重要的一个特性)
在一个ZK集群中,有可能有多台ZK server,但每台server保存的数据副本都是相同的,client无论连接到哪个server,获得的数据都是一样的。
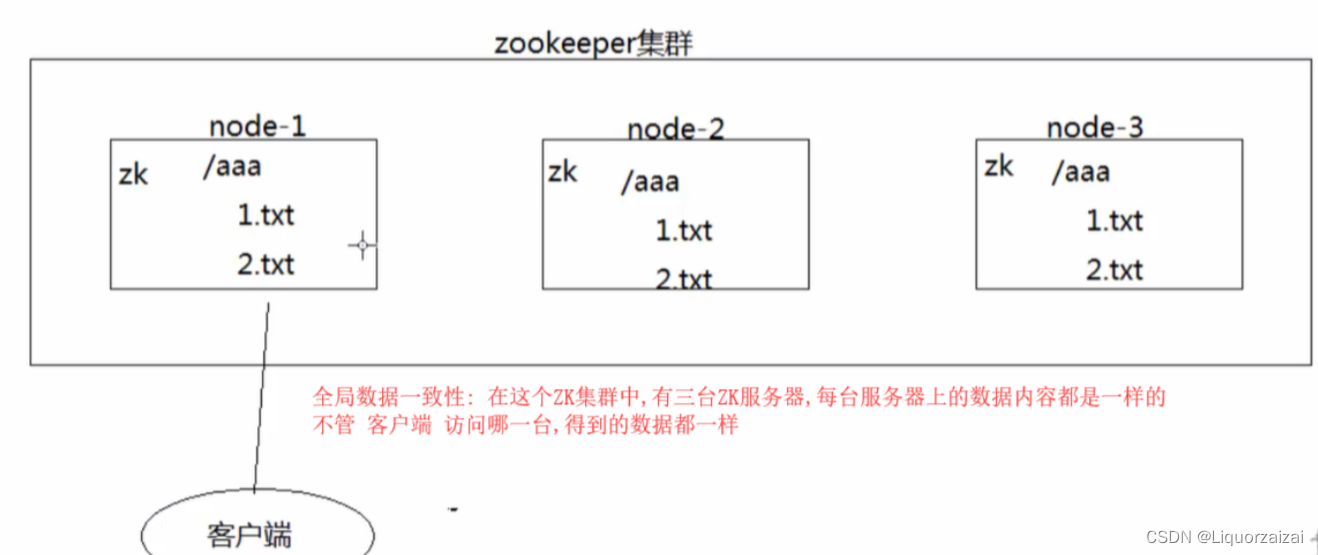
ZK提供的一致性是弱一致性;ZK对数据的复制(将其中某一server最新的数据更新同步到其他server中)有一个规则:zookeeper确保每一次对znode树的修改都会复制到集群中的其他server对应的znode上,当半数以上的server成功复制、统一数据之后,zookeeper其实就已经默认本次的数据同步是成功的。那么也就可能产生一个问题:在某一时间段下,有些server的数据更新失败,此时该server数据不是最新的,恰巧又被client访问了,就会产生脏读。也就是说,ZK只是保证数据的最终一致性,但实时的一致性不保障。但用户也可以通过调用sync()来保证实时数据一致性
②可靠性
如果client对某一台server上的数据进行了CUD,那么zookeeper集群会对其他所有的server数据进行统一,这也保证了ZK的全局数据一致性。
③顺序性
若在一台server上,消息b在消息a之后发布,则其他所有的server中,消息b都将在消息a之后发布。
④数据更新原子性
联想事务原子性,一次数据更新要么都成功,要么都失败。在ZK中,对一次数据的更新,只有当半数以上节点都更新成功,才算本次数据更新成功,否则就是失败,不会有中间状态(一半成功一半失败)。
⑤实时性
在特定的一段时间内,client看到的server状态都是实时的,在此时间段内,sercer做任何的改变,都会推送到client。
5.Zookeeper集群角色
①Leader(主节点、领导)
Leader是整个ZK集群的核心,负责响应所有对Zookeeper状态变更的请求。它会将每个状态更新请求进行排序和编号,以便保证整个集群内部消息处理的FIFO(First Input First Output的缩写,先入先出队列)。
a.处理事务请求(CUD)和非事务请求。PS:Leader是ZK中唯一一个有权对事务请求进行调度和处理的角色,能够保证集群事务处理的顺序。如果client发送事务请求到其他从节点server上,最终这个事务请求也会被从节点转发至Leader节点处理,由Leader决定该事务编号、执行的操作。
b.集群内部各服务器的调度者
举个例子:
现有 Zookeeper集群:一个Leader,两个Follower(甲、乙),两个client(a、b)
client-a向follower-甲发送一个事务请求(删除znode-a节点),同一时刻client-b向follower-乙发送了一个事务请求(修改znode-a节点信息)。(所谓的事务请求就是一些create、update、delete等与写有关的操作)
如果这两个事务请求让follower处理,就有可能造成follower-甲先删除znode-a节点,然后follower-乙去修改已经被删除的znode-a节点。
当follower将事务请求转发给leader时,leader根据接收到请求先后原则将事务请求进行编号、执行,就能有效避免
②Follower(从节点、跟随者、下属)
a.处理client非事务请求,如果client发出的请求是事务请求,会转发给Leader。
b.参与集群对Leader选举投票(ZK中leader是通过投票选举出来的)。
c.参与事务请求 Proposal 的投票(leader发起的提案,要求follower投票,需要半数以上follower节点通过,leader才会commit数据);
PS:在ZooKeeper的实现中,每一个事务请求都需要集群中过半机器投票认可才能被真正应用到ZooKeeper的内存数据库中去,这个投票与统计过程被称为“Proposal流程”。
③Observer(从节点、观察者、下属)
Observer除了不参与Leader选举投票外,与Follower作用相同。
PS:通常用于在不影响集群事务处理能力的前提下,提升集群的非事务处理能力。简单来说,observer可以在不影响集群写(CUD)性能的情况下,提升集群读(R)性能,并且因为它不参与投票,所以他们不属于ZooKeeper集群的关键部位,即使他们failed,或者从集群中断开,也不会影响集群的可用性。
6.Zookeeper集群搭建
Zookeeper集群搭建指的是Zookeeper分布式模式安装(多台机器上安装多个zookeeper服务,并将这些服务互相注册互相关联,形成一个集群)。通常由 奇数 台servers组成。这是因为为了保证Leader选举(基于Paxos算法的实现)能够得到多数的支持,所以Zookeeper集群的server数量一般为奇数。
PS:为什么是奇数台servers,之前介绍中经常有说到一个关键词(半数以上)。在zookeeper中,半数以上机制比较重要。例如:半数以上服务器存活,该集群才可正常运行;半数以上投票,本次事务请求才可通过等。
简单举例:
假如现在有一个集群,集群中有6台server,现在要进行一个投票,根据zookeeper投票机制:必须要 半数以上 的服务投票才算成功。由此可知,必须要有4台机器参与投票才可成功,剩余两台机器可以不参与投票。
假如现在又有一个集群,这个集群中有5台server,现在要进行一个投票,根据zookeeper投票机制:必须要 半数以上 的服务投票才算成功。在这个集群中,只需要3台机器参与投票就可成功,剩余两台机器可以不参与投票。这两个集群对比,经济上来说5台server比6台花钱更少,运行投票速度上来说,都是剩余两台机器不参与投票,而5台服务集群的只需要投票3次即可得结果,6台服务集群的需要投票4次。
①Zookeeper集群搭建步骤
Zookeeper运行需要java环境,所以需要提前安装jdk。对于安装 Leader+follower 模式集群,大致步骤如下:
配置主机名称及IP地址映射配置
准备jdk环境
安装Zookeeper
修改Zookeeper配置文件
设置myid
启动Zookeeper集群
②环境准备
服务器类型 系统和IP地址 需要安装的组件
Zookeeper服务器1 CentOS7.4(64 位) 192.168.40.10 jdk
Zookeeper服务器2 CentOS7.4(64 位) 192.168.40.20 jdk
Zookeeper服务器3 CentOS7.4(64 位) 192.168.40.30 jdk
③防火墙都已关闭、三台服务器之间都能ping通

Xshell 输入一次命令,同时操作多态服务器小技巧

④配置主机名和IP映射
打开 /etc/hosts文件: vim /etc/hosts
⑤安装 JDK
#非最小化安装一般自带
yum install -y java-1.8.0-openjdk java-1.8.0-openjdk-devel
java -version
yum install -y java-1.8.0-openjdk java-1.8.0-openjdk-devel
java -version
⑥下载安装包
官方下载地址:Index of /dist/zookeeper
cd /opt/
rz -E
tar zxvf apache-zookeeper-3.5.7-bin.tar.gz
mv apache-zookeeper-3.5.7-bin /usr/local/zookeeper-3.5.7##########或者在官方下载安装包##############
cd /opt
wget https://archive.apache.org/dist/zookeeper/zookeeper-3.6.3/apache-zookeeper-3.6.3-bin.tar.gz
⑦修改配置文件(所有节点)
cd /usr/local/zookeeper-3.5.7/conf/
cp zoo_sample.cfg zoo.cfgvim zoo.cfg
tickTime=2000 #通信心跳时间,Zookeeper服务器与客户端心跳时间,单位毫秒
initLimit=10 #Leader和Follower初始连接时能容忍的最多心跳数(tickTime的数量),这里表示为102s
syncLimit=5 #Leader和Follower之间同步通信的超时时间,这里表示如果超过52s,Leader认为Follwer死掉,并从服务器列表中删除Follwer
dataDir=/usr/local/zookeeper-3.5.7/data ●修改,指定保存Zookeeper中的数据的目录,目录需要单独创建
dataLogDir=/usr/local/zookeeper-3.5.7/logs ●添加,指定存放日志的目录,目录需要单独创建
clientPort=2181 #客户端连接端口
#添加集群信息
server.1=192.168.40.10:3188:3288
server.2=192.168.40.20:3188:3288
server.3=192.168.40.30:3188:3288
#集群节点通信时使用端口3188,选举leader时使用的端口3288
server.A=B:C:D
●A是一个数字,表示这个是第几号服务器。集群模式下需要在zoo.cfg中dataDir指定的目录下创建一个文件myid,这个文件里面有一个数据就是A的值,Zookeeper启动时读取此文件,拿到里面的数据与zoo.cfg里面的配置信息比较从而判断到底是哪个server。
●B是这个服务器的地址。
●C是这个服务器Follower与集群中的Leader服务器交换信息的端口。●D是万一集群中的Leader服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
[root@zookeeper1 opt]# cd /usr/local/zookeeper-3.5.7/conf
[root@zookeeper1 conf]# cp zoo sample.cfg zoo.cfg
[root@zookeeperl conf]# vim zoo.cfg

⑧创建数据目录和日志目录(所有节点)
mkdir /usr/local/zookeeper-3.5.7/data
mkdir /usr/local/zookeeper-3.5.7/logs
所有节点都需要做,此处只演示了节点1的操作

⑨在 dataDir 指定目录下创建一个 myid 的文件(所有节点)
echo 1 > /usr/local/zookeeper-3.5.7/data/myid #zookeeper服务器1上添加
echo 2 > /usr/local/zookeeper-3.5.7/data/myid #zookeeper服务器2上添加
echo 3 > /usr/local/zookeeper-3.5.7/data/myid #zookeeper服务器3上添加

⑩配置 Zookeeper 启动脚本(所有节点)
vim /etc/init.d/zookeeper
#!/bin/bash
#chkconfig:2345 20 90
#description: Zookeeper Service Control Script
ZK_HOME='/usr/local/zookeeper-3.5.7'
case $1 in
start)
echo "-----zookeeper启动-----"
$ZK_HOME/bin/zkServer.sh start
;;
stop)
echo "----zookeeper停止-------"
$ZK_HOME/bin/ zkServer.sh stop
;;
restart)
echo "----zookeeper重启-------"
$ZK_HOME/bin/zkServer.sh restart
;;
status)
echo "-----zookeeper状态------"
$ZK_HOME/bin/zkServer.sh status
;;
*)
echo "Usage: $0 {start|stop|restart|status}"
esac
11.启动、设置开机自启、查看服务状态
#设置开机自启
chmod +x /etc/init.d/zookeeper
chkconfig --add zookeeper#分别启动 Zookeeper
service zookeeper start#查看当前状态
service zookeeper status

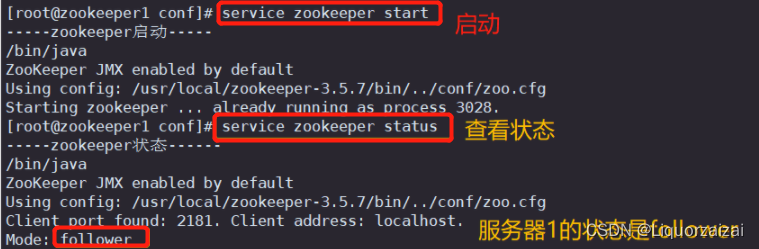
服务器1状态:follower 服务器2状态:follower 服务器3状态:leader
版权归原作者 Liquorzaizai 所有, 如有侵权,请联系我们删除。