
文章目录
前言
之前有个项目需要用到消息队列;经过项目组的讨论下消息中间件选用Kafka。秉承着缺啥补啥的原则,只能临时抱佛脚学习一下。现在有点时间就把这个学习过程记录一下。
一、Kafka概述
1、定义
kafka是一个分布式的基于发布/订阅模式的消息队列。
2、消息队列
1) MQ传统应用场景
- 异步处理场景说明:用户注册后,需要发注册邮件和注册短信。传统的做法有两种 a.串行的方式;b.并行方式。 a) 串行方式:将注册信息写入数据库成功后,发送注册邮件,再发送注册短信;
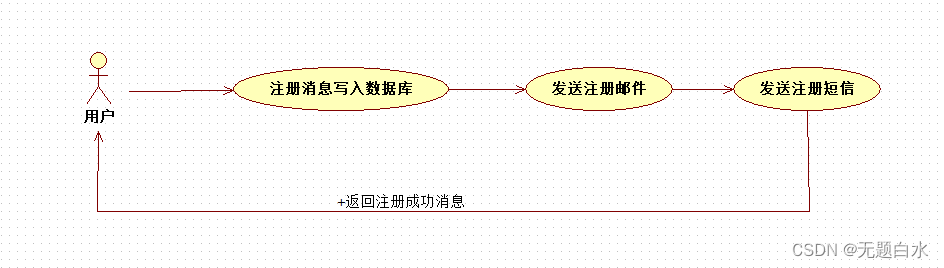 总耗时 = 注册消息写入数据库耗时 + 发送注册邮件耗时 + 发送注册短信耗时; b) 并行方式:将注册信息写入数据库成功后,发送注册邮件的同时发送注册短信,以上三个任务完成后,返回给客户端。与串行的差别是,并行的方式可以提高处理的时间。
总耗时 = 注册消息写入数据库耗时 + 发送注册邮件耗时 + 发送注册短信耗时; b) 并行方式:将注册信息写入数据库成功后,发送注册邮件的同时发送注册短信,以上三个任务完成后,返回给客户端。与串行的差别是,并行的方式可以提高处理的时间。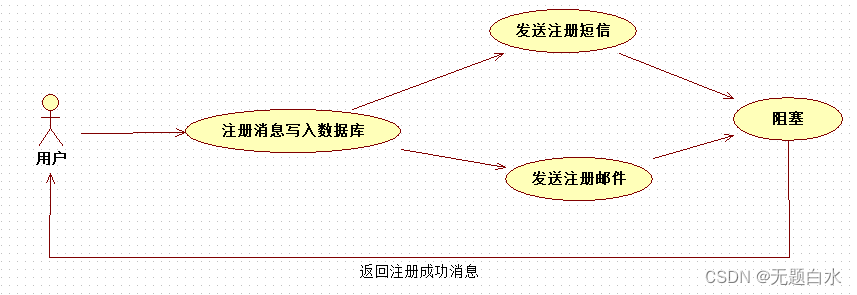 总耗时 = 注册消息写入数据库耗时 + MAX(发送注册邮件耗时 + 发送注册短信耗时) 小结:如以上案例描述,传统的方式系统的性能(并发量,吞吐量,响应时间)会有瓶颈。 c)引入消息队列,将不是必须的业务逻辑,异步处理
总耗时 = 注册消息写入数据库耗时 + MAX(发送注册邮件耗时 + 发送注册短信耗时) 小结:如以上案例描述,传统的方式系统的性能(并发量,吞吐量,响应时间)会有瓶颈。 c)引入消息队列,将不是必须的业务逻辑,异步处理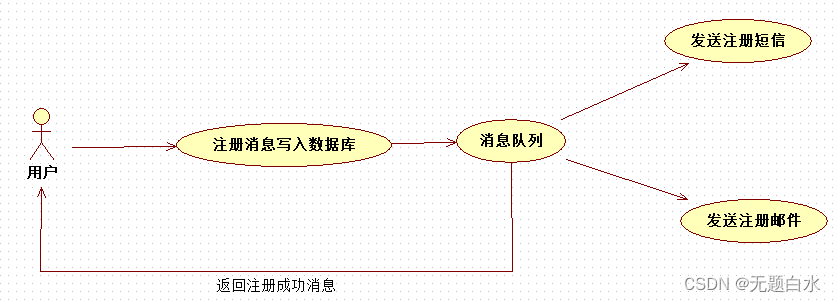 总耗时 = 注册消息写入数据库耗时 + 消息队列耗时(基本可以忽略) 因此架构改变后,系统的吞吐量提高到每秒20 QPS。比串行提高了3倍,比并行提高了两倍。
总耗时 = 注册消息写入数据库耗时 + 消息队列耗时(基本可以忽略) 因此架构改变后,系统的吞吐量提高到每秒20 QPS。比串行提高了3倍,比并行提高了两倍。 - 应用解耦场景说明:电商平台用户下单后,订单系统需要通知库存系统。 架构设计:
 一旦库存系统无法访问,则订单减库存将失败,从而导致订单失败,订单系统与库存系统耦合。 引入应用消息队列后: 架构设计:
一旦库存系统无法访问,则订单减库存将失败,从而导致订单失败,订单系统与库存系统耦合。 引入应用消息队列后: 架构设计: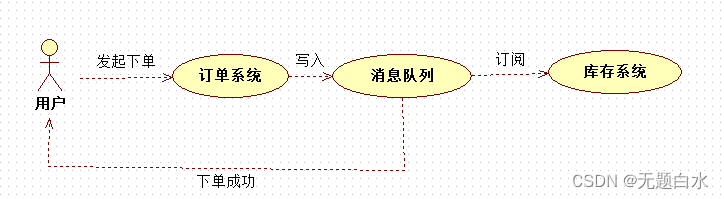 订单系统:用户下单后,订单系统完成持久化处理,将消息写入消息队列,返回下单成功; 库存系统:订阅下单的消息,订阅下单信息,库存系统根据下单信息,进行库存操作; 假如:在下单时库存系统不能正常使用。也不影响正常下单,因为下单后,订单系统写入消息队列就不再关心其他的后续操作了。实现订单系统与库存系统的应用解耦。
订单系统:用户下单后,订单系统完成持久化处理,将消息写入消息队列,返回下单成功; 库存系统:订阅下单的消息,订阅下单信息,库存系统根据下单信息,进行库存操作; 假如:在下单时库存系统不能正常使用。也不影响正常下单,因为下单后,订单系统写入消息队列就不再关心其他的后续操作了。实现订单系统与库存系统的应用解耦。 - 流量削锋 应用场景:一般在秒杀或团抢活动中使用广泛。秒杀活动,一般会因为流量过大,导致流量暴增,应用挂掉。为解决这个问题,一般需要在应用端加入消息队列。 a) 可以控制活动的人数 b) 可以缓解短时间内高流量压垮应用
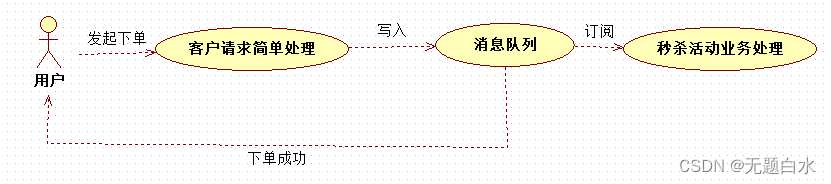
用户的请求,服务器接收后,做简单的逻辑判断 然后写入消息队列。假如消息队列长度超过最大数量,则直接抛弃用户请求或跳转到错误页面。
秒杀业务根据消息队列中的请求信息,再做后续处理。
- 消息通讯 应用场景:消息通讯是指,消息队列一般都内置了高效的通信机制,因此也可以用在纯的消息通讯。比如实现点对点消息队列,或者聊天室等。
2) 消息队列的两种模式
- 点对点模式: 一对一,消费者主动拉取数据,消息收到后消息清除。点对点模式原理图:
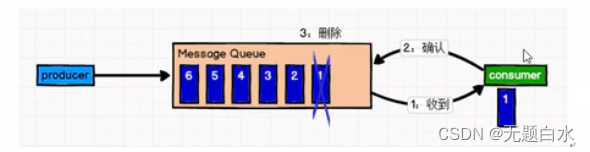 消息队列原理: 消息生产者生产消息发送到Queue中,然后消费者从Queue中取出并消费消息。消费被消费后,Queue中不再存储,所以消费者不可能消费到已经被消费的消息。Queue支持存在多个消费者,但是对一个消息而言,只会有一个消费者可以消费。
消息队列原理: 消息生产者生产消息发送到Queue中,然后消费者从Queue中取出并消费消息。消费被消费后,Queue中不再存储,所以消费者不可能消费到已经被消费的消息。Queue支持存在多个消费者,但是对一个消息而言,只会有一个消费者可以消费。 - 发布/订阅模式: 一对多,消费者消费数据之后不会清除消息。发布/订阅模式原理图:
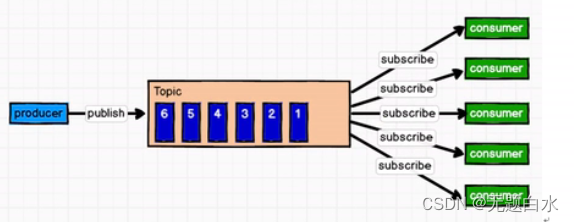 消息队列原理: 消息生产者(发布)将消息发布到Topic中,同时有多个消息消费者(订阅)消费该消息。和点对点方式不同,发布到topic的消息 会被所有订阅者消费。发布/订阅模式分为两种: a)消费者主动拉取数据(kafka) 好处:可以根据消费者消费能力去拉取数据; 缺点:队列长时间没有消息添加进来,消费者需要保持轮询机制,浪费资源。 b)Topic(队列)主动推动数据给消费者
消息队列原理: 消息生产者(发布)将消息发布到Topic中,同时有多个消息消费者(订阅)消费该消息。和点对点方式不同,发布到topic的消息 会被所有订阅者消费。发布/订阅模式分为两种: a)消费者主动拉取数据(kafka) 好处:可以根据消费者消费能力去拉取数据; 缺点:队列长时间没有消息添加进来,消费者需要保持轮询机制,浪费资源。 b)Topic(队列)主动推动数据给消费者
3、kafka基础架构
- kafka架构图:
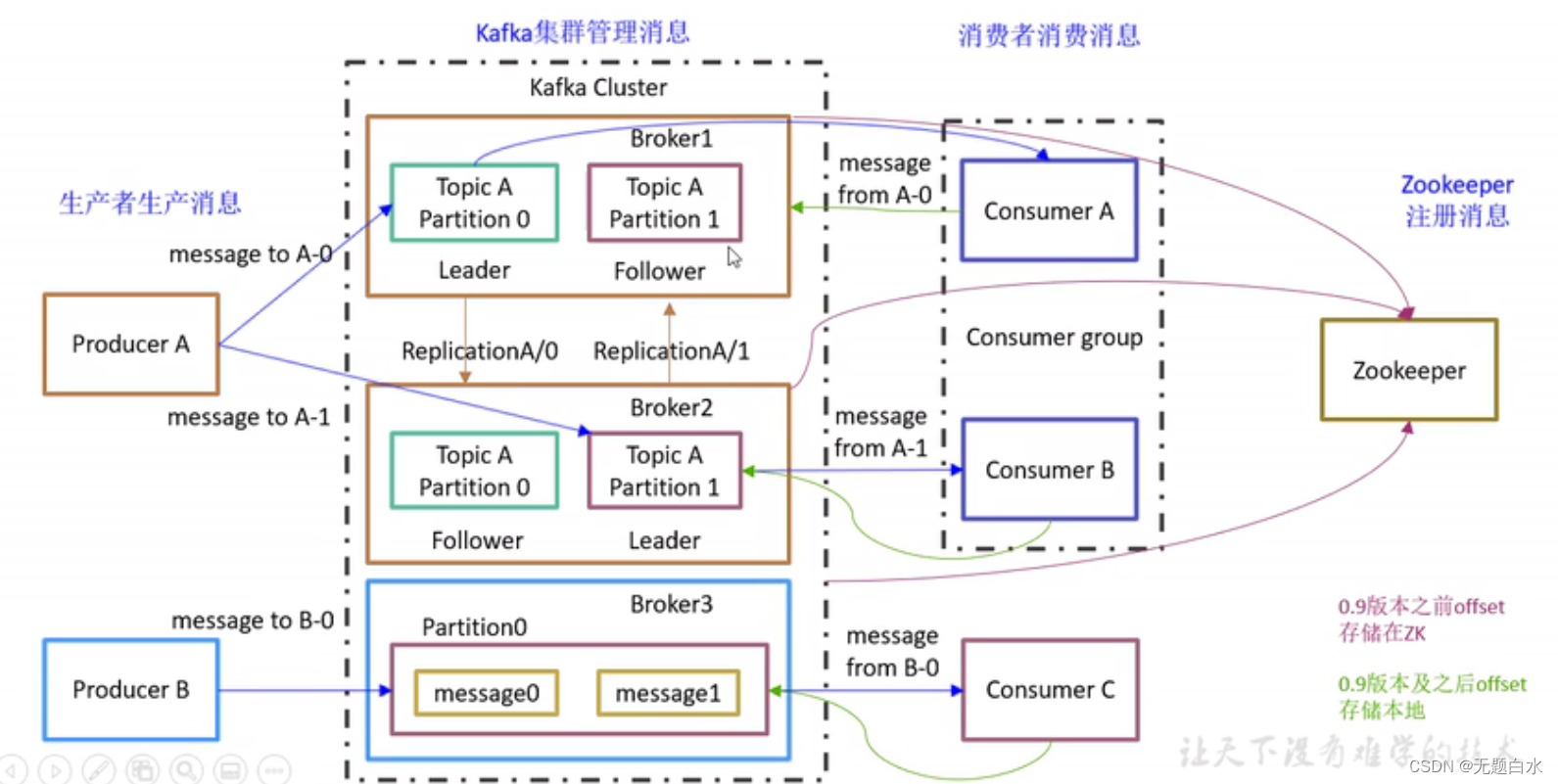
- Producer: 消息生产者,就是向kafka broker发消息的客户端。
- Consumer: 消息消费者,向kafka broker取消息的客户端。
- Topic: 可以理解为一个队列,生产者和消费者面向的都是一个topic。
- partition: 为了实现扩展性,一个非常大的topic可以分布到多个broker(服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列。
- Replice:副本: 为了保证集群中的某个节点发生故障时,该节点上的partition数据不丢失,且kafka仍然能够继续工作,kafka提供了副本机制,一个topic的每个分区都有若干个副本,一个leader和若干个follower。
- leader: 每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数据的对象都是。leader
- follower: 每个分区多个副本中的“从”,实时从leader中同步数据,保持和leader数据的同步。leader发生故障时,某个follwer会成为新的follwer。
- Consumer Group(CG): 消费者组,由多个consumer组成.。
二、Kafka安装部署
1、集群规划
hadoop102hadoop102hadoop1023zkzkzkkafkakafkakafka
2、kafka集群部署
1) Kafka安装包下载地址: https://kafka.apache.org/downloads
2) 解压安装包:
终端输入: tar -zxvf kafka_2.11-0.11.0.0.tgz -C /opt/module
3) 修改解压后的文件名称:
终端输入: mv kafka_2.11-0.11.0.0/ kafka
4) 在opt/module/kafka目录下创建logs文件夹:
终端输入: mkdir logs
5) 修改配置文件:
终端输入: cd config/
终端输入: vi server.properties
修改内容如下:
a) broker.id = 0 (全局唯一编号,不能重复且为数字);
b) delete.topic.enable = true (设置是否可以删除topic);
c) log.dirs = /opt/module/kafka/data (kafka 暂存数据的文件夹);
d) log.retrntion.hours = 168 (暂存数据的时间(小时))
e) zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181
(zookeeper连接的集群)
6) 配置环境变量:
终端输入: sudo vi /etc/profile
末行输入:
#KAFKA_HOME
export KAFKA_HOME=/opt/module/kafka
export PATH=$PATH:$KAFKA_HOME/bin
重新加载配置文件:
终端输入: source /etc/profile
7) 分发安装包:
终端输入: xsync kafka/
注意:分发之后记得配置其他机器的环境变量,server.properties中的broker.id的值,不可重复
8) 启动集群:
- 启动zookeeper集群:
三台节点终端都输入: zkServer.sh start
方案一:
- 启动kafka服务:
三台节点终端都输入: bin/kafka-server-start.sh -daemon config/server.propertieds
方案二:
- kafka群起/群关脚本
#!/bin/bash
case $1 in
"start"){for i in hadoop102 hadoop103 hadoop104
doecho"**********$i**********"
ssh $i"/opt/module/kafka/bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.propertieds"
done
};;"stop"){for i in hadoop102 hadoop103 hadoop104
doecho"**********$i**********"
ssh $i"/opt/module/kafka/bin/kafka-server-top.sh -daemon /opt/module/kafka/config/server.propertieds"
done
};;
esac
启动/关闭脚本:
终端输入(启动): kk.sh start
终端输入(关闭): kk.sh stop
Kafka集群到此搭建完成!
本文转载自: https://blog.csdn.net/qq_34424698/article/details/135740859
版权归原作者 无题白水 所有, 如有侵权,请联系我们删除。
版权归原作者 无题白水 所有, 如有侵权,请联系我们删除。