
关于CNN的一些思考-2022
前言
今年(2022)CVPR有两篇关于CNN的论文让我印象深刻,因为它们不约而同的使用了更大的卷积核:
之前我在自己的研究方向上也尝试了大卷积核,确实效果很好,当然,不能无脑大 – 得调参
回顾卷积,简单点说像是一种多核加权的自适应滤波(是传统图像滤波算法的延伸),核里的参数是通过反向传播进行慢慢调整的。近几年CNN发展太快了,有偶数核的卷积(2 x 2而不是3 x 3)、深度可分离卷积、shift移位卷积、重参数化的卷积、门控卷积等等。随着Transformers的兴起,还有使用卷积进行位置编码的操作。 这里就不一一列举了,有兴趣的百度即可 - -
我之前写了一篇关于重参数化的思考 关于重参数化的一些思考-2022 很有启发性的工作
本博主列举了几篇文章,并进行一定讨论 (友情提示:本文对初学者不是很友好)
疑问1:为什么之前很少有论文用大卷积核?疑问2:大卷积核为什么这么work?
CNN (Neural Computation 1989)
论文: Backpropagation applied to Handwritten zip code recognition
核心思想
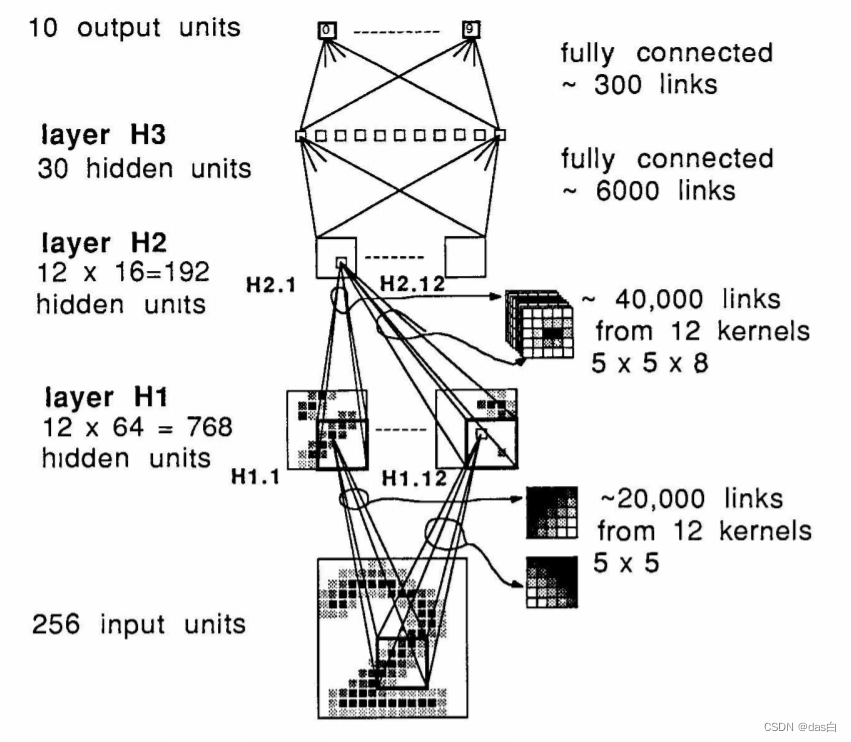
最早提出卷积的文章,最原始的卷积。
以现在的角度来看(2022年)其实就是空间域和通道域的加权求和
博客 (ICLR 2022) :Deep Neural Nets: 33 years ago and 33 years from now
特斯拉AI总监发表的博客,很有意思,复现了LeCun 33年前的神经网络。
这篇文章给我的感觉:现代深度学习技术最work的还是数据增强(dropout)和更深更宽的网络
并不是说其它技术没用,而是不具备普适性 有些只对特定数据集有效 –
个人观点,不喜勿喷
当然,有些网络或者技术并就是针对某一类问题的
MobileNets (CVPR 2017) DConv
论文: MobileNets: Efficient Convolutional Neural Networks for Mobile Vision
核心思想
与原始的卷积不同,深度可分离的卷积只是通道域的加权求和,使用点积来对空间域特征进行交互
深度可分离的卷积应用的很广,因为真的可以涨点
很可惜的是速度慢了点(
在GPU上
),因为原始的一个卷积被替换成了至少两个卷积(DConv + 点积)
Shift (CVPR 2018) SConv
论文: Shift: A Zero FLOP, Zero Parameter Alternative to Spatial Convolutions
核心思想
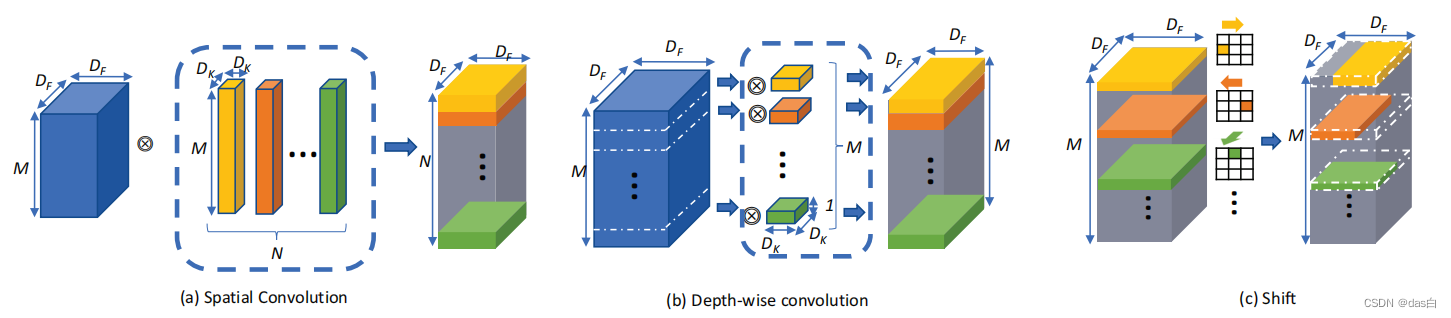
在深度可分离的基础上,使用简单的图像移位来进行空间域特征的交互(具体实现涉及到底层编程)
可以说是深度可分离卷积的加强版,确实把参数消减了很多,但是准确率也不可避免的下降了
实际部署的话应该会更有用(如果可以接受下降的准确率) 最近看的论文很少用Shift ,大多是DConv
详情可参考:紧致卷积网络设计——Shift卷积算子
ConvNet (CVPR 2022)
论文: A ConvNet for the 2020s
核心思想
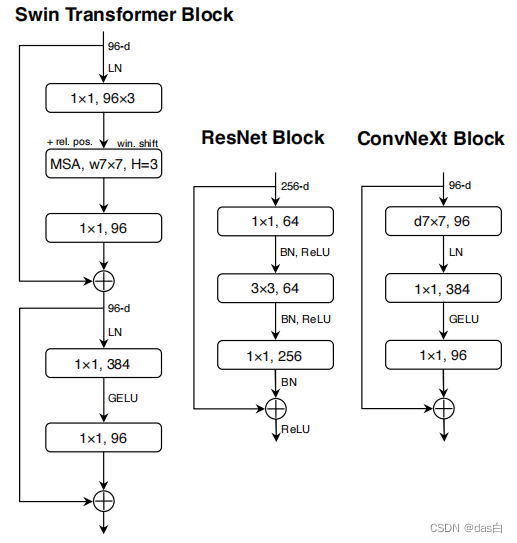
将最新的技术(数据增强、归一化、DConv等等)添加到了ResNet,也可以达到很好的效果
具体的改动只放Block,亲测涨点明显,这篇文章给卷积党带来了很大信心
Large Kernel:31x31(CVPR 2022)
论文: Scaling Up Your Kernels to 31x31: Revisiting Large Kernel Design in CNNs
核心思想
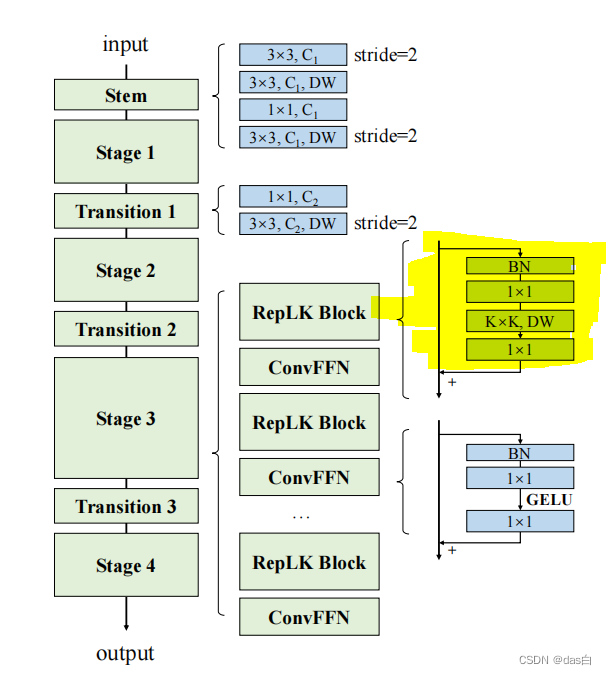
在Stage3里使用的大卷积核(也是DConv),同样加入GELU激活函数
这么大的卷积核暂未亲测,应该效果不会太差
总结
不得不说 :Money is all you need 是正解,越深入研究,越感觉好的设备是真香 可以快速验证自己的想法
最近关于MLP的文章也很多 本质上还是加权求和(参数共享) 感觉使用卷积也能实现 –
个人感觉
- 比如:MLP-Mixer 里隐藏的卷积
- 再比如:谷歌提出MAXIM模型刷榜多个图像处理任务,代码已开源
还有一些自注意力与卷积结合的文章
- 比如:ACmix:自注意力和卷积的融合 等等
嘴强王者到此结束
疑问猜想
疑问1:为什么之前很少有论文用大卷积核?`
- 跑过的都知道,实在是占GPU,而且速度慢,效果也不一定好(可能调参没到位)
- 先进的硬件设备是大卷积核的xxx土壤,目前使用大卷积核也是在池化之后的 因为这样GPU内存占的少
也许从一开始使用大卷积核效果也不错?也可能在大图像上(不池化)用大的卷积核较难拟合一个稳定函数?
疑问2:大卷积核为什么这么work?
- 说实话,不懂!!!!!!!!!!!
- 感觉Transformers本身的自注意力使用到图像上就很奇怪,确定每一个图像注意力权重大的地方是人们真正关心的地方吗?炼丹 - 玄学 倒是点云使用自注意力就很流畅,毕竟只有位置编码
- 只能是基于前人的实验经验,做出假设和推理 我记得VIT是使用了预训练效果才上去的,所以也许对于很大的数据量来说,卷积(小的核)是一种限制 使用大的卷积核可以进一步解放这个限制 (
传统图像滤波处理使用大的窗口效果好一点) - 私以为加权求和还有潜力可挖,怎么赋予其更可解释性的求和方式是未来发展的一大趋势 –
个人感觉
题外话:不可否认池化的作用,亲测确实很有效
但是以后随着卷积的发展会不会把池化给抛弃呢,池化对图像是很方便的操作,但是池化对于其他数据结构并不友好 - -
参考链接
版权归原作者 das白 所有, 如有侵权,请联系我们删除。