
文章目录
一、增
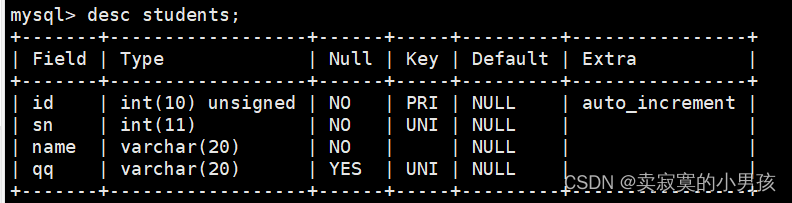
首先我们来创建一张表:
mysql>createtable students(-> id intunsignedprimarykeyauto_incrementcomment'用户主键',-> sn intnotnulluniquekeycomment'学号',-> name varchar(20)notnull,-> qq varchar(20)unique->);
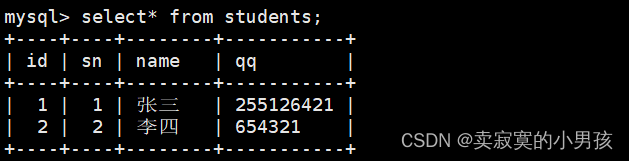
1.单行全列插入
当全列插入的时候,插入哪个位置可以进行省略:
mysql>insertinto students (id,sn,name,qq)values(1,1,'张三','255126421');//不省略插入
mysql>insertinto students values(2,2,'李四','654321');//不省略插入
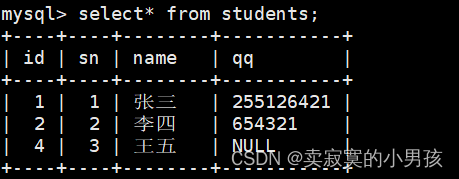
2.选择列插入
如果是选择列插入,必须要带插入的位置:
mysql>insertinto students (sn,name)values(3,'王五');
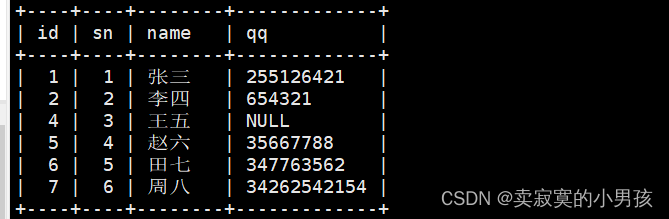
3.一次插多条记录
可以使用逗号隔开,从而实现一次插入多条记录:
mysql>insertinto students (sn,name,qq)values(4,'赵六','35667788'),(5,'田七','347763562'),(6,'周八','34262542154');
4.冲突则更新
不冲突则插入,由于主键或者唯一键对应的值而导致插入失败,冲突不希望报错,冲突就修改,如果修改的也有问题,则报错。
mysql>insertinto students (id,sn,name,qq)values(8,125,'关羽','255126421')onduplicatekeyupdate qq='2356555',name='武九';//qq冲突了
mysql>insertinto students (id,sn,name,qq)values(8,2,'关羽','255126421')onduplicatekeyupdate qq='23565554',name='吕蒙';//与李四sn冲突了
发现是张三的qq和它冲突了,因此将张三更新为武九的内容,但是注意,因为我们只指定了名字和qq,因此主键和学号依然使用的是张三原来的。李四的同理。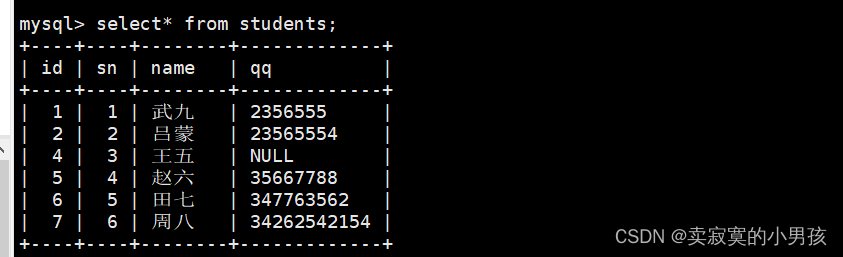
当和不同行的列冲突的时候:
mysql>insertinto students (id,sn,name,qq)values(4,4,'刘备','2356555')onduplicatekeyupdate id='8',qq='245254535',name='刘备',sn=10;//与王五的id,赵六的sn,武九的qq冲突
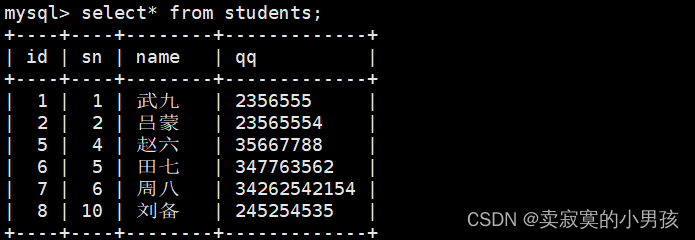
此时更新的是最先发生冲突的那一个即王五。
5.替换
没有冲突则插入,有冲突则全部替换。
mysql>replaceinto students (sn,name,qq)values(9,'曹操','56789039');//无冲突插入
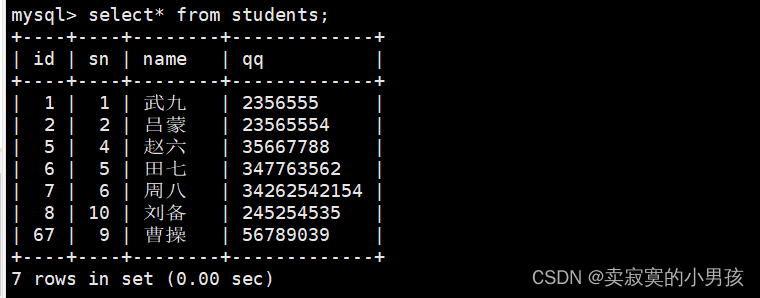
mysql>replaceinto students (id,sn,name,qq)values(1,4,'张飞','347763562');//id与武九,sn与赵六,qq与田七冲突
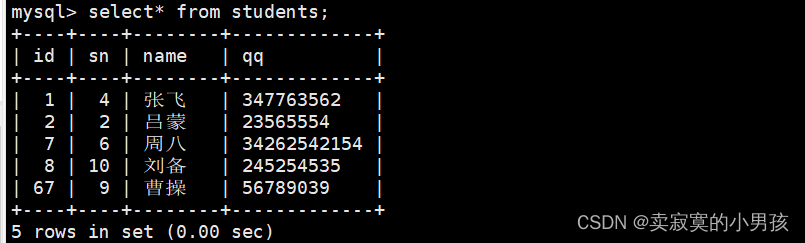
此时我们发现这三行都被替换了。replace是强制替换,而on duplicate key update是冲突后将冲突的改成我们指定的一个。
二、查
重新建立一张表:
mysql>createtable exam_result(-> id intunsignedprimarykeyauto_increment,-> name varchar(20)notnullcomment'同学姓名',-> chinese floatdefault0.0comment'语文成绩',-> math floatdefault0.0comment'数学成绩',-> english floatdefault0.0comment'英语成绩'->);
向其中插入一些数据:
mysql>insertinto exam_result (name,chinese,math,english)values->('钢铁侠',67,98,56),->('美队',87,78,77),->('雷神',88,98,90),->('绿巨人',82,84,67),->('黑寡妇',55,85,45),->('鹰眼',70,73,78),->('死侍',75,65,30)->;
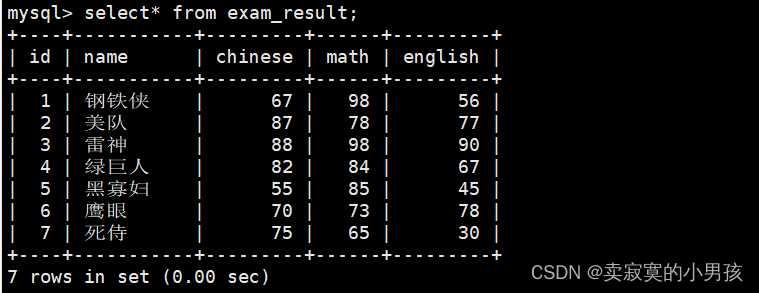
1.查看表中所有数据
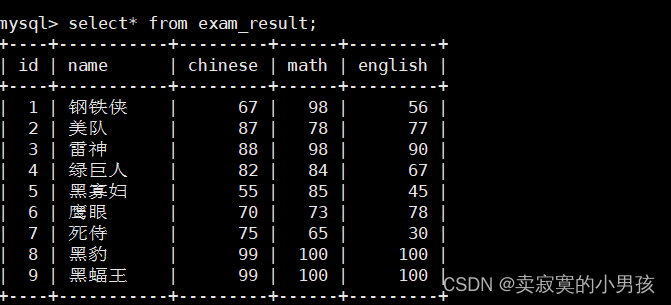
mysql>select*from exam_result;
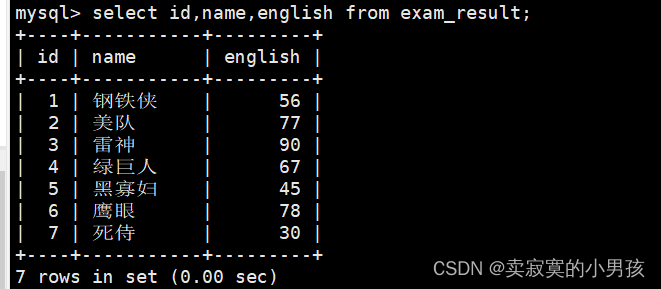
2.所有行指定列查询
mysql>select id,name,english from exam_result;//查询所有行以及id,name,english列
3.增加表达式列
注意只能是表达式,字符串不行:
mysql>select id,name,english,10+10,english+10from exam_result;//增加表达式10+10
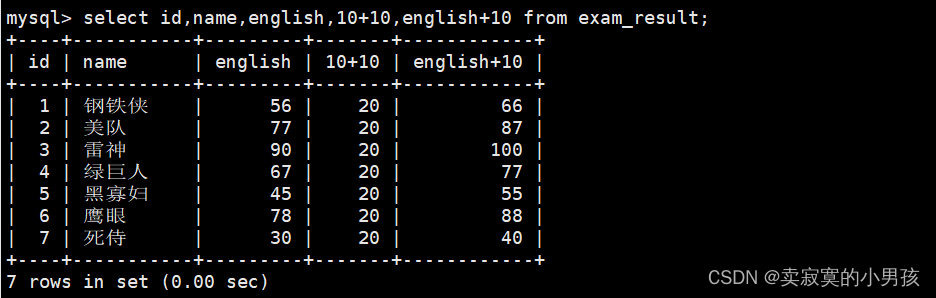
注意,对english+10并不影响表中的数据,可以把查询操作理解成拷贝。
在查询的时候,显示的列名太丑了,我们还可以进行重命名操作,注意其实每一个列都可以当成一个表达式:
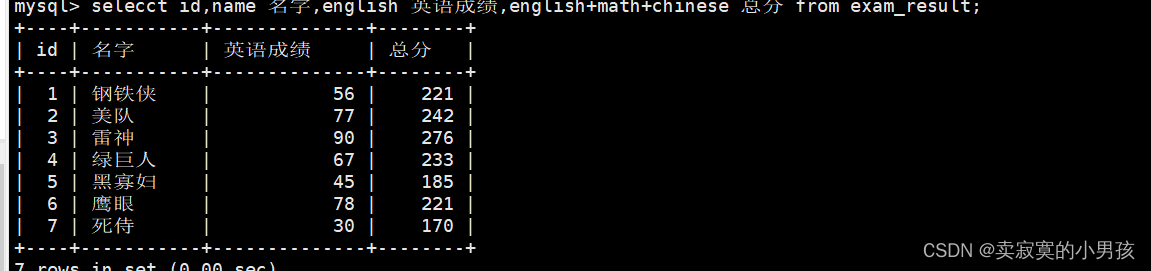
mysql> selecct id,name 名字,english 英语成绩,english+math+chinese 总分 from exam_result;
4.查询结果去重
mysql>selectdistinct math from exam_result;//去重数学成绩
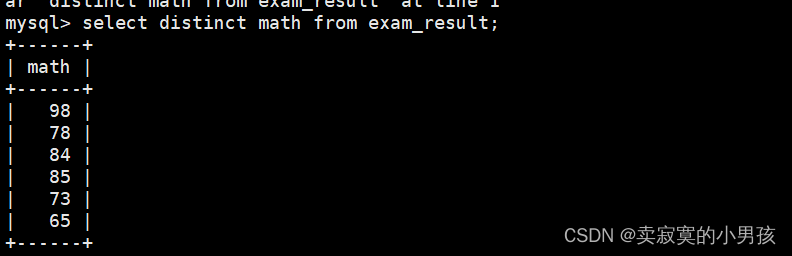
如果在math后加上id等信息,则这些信息都不一样才会发生去重。
5.条件筛选:where条件
where条件是在select语句执行之前执行的,因为要先进行筛选。
(1)运算符概述
比较运算符:
比较运算符说明>,>=,<,<=大于,大于等于,小于,小于等于=等于,NULL不安全,例如NULL=NULL的结果是NULL<=>等于,NULL安全,例如NULL<=>NULL的结果就是TRUE(1)!=,<>不等于between a0 and a1范围匹配,[a0,a1],如果a0<=value<=a1,返回TRUE(1)in(option,…)如果是option中的任意一个,返回TRUE(1)is null是NULLis not null不是NULLlike模糊匹配。%表示任意多个(包括0个)任意字符,_表示任意一个字符
逻辑运算符:
运算符说明and多个条件必须都为TRUE(1),结果才是TRUE(1)or任意一个条件为TRUE(1),结果为TRUE(1)not条件为TRUE(1),结果为FALSE(0)
注意,在mysql中,赋值符号和等于符号都是=,没有==符号。
(2)英语成绩小于60的同学
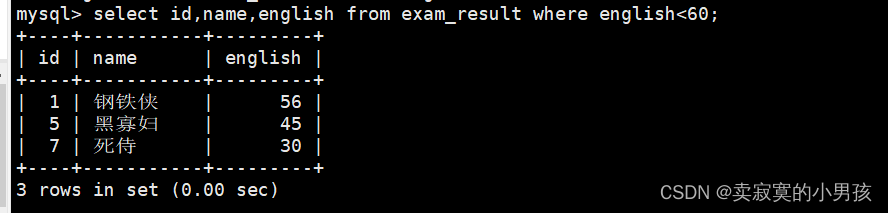
mysql>select id,name,english from exam_result where english<60;
(3)语文成绩在[80,90]之间的同学
mysql>select id,name,chinese from exam_result where chinese between80and90;

(4)数学成绩是58,59或者98,99的同学
mysql>select id,name,math from exam_result where math=58or math=59or math=98or math=99;//可以使用or相连,但是非常的麻烦
mysql>select id,name,math from exam_result where math in(58,59,98,99);//使用in语句解决这一问题

(5)查找姓黑的同学以及查找黑某同学
先插入俩人:
mysql>insertinto exam_result values(8,'黑豹',99,100,100);
mysql>insertinto exam_result values(9,'黑蝠王',99,100,100);
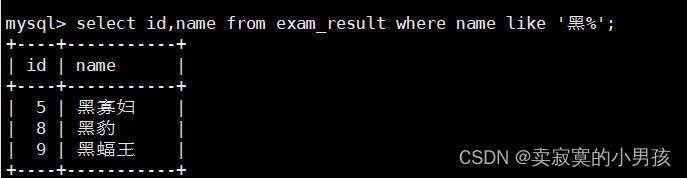
mysql>select id,name from exam_result where name like'黑%';//查找姓黑的同学
mysql>select id,name from exam_result where name like'黑_';
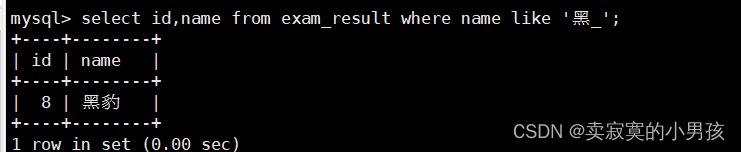
查找黑某同学,某表示名字是一个字。
(6)总分在200以下的同学
mysql>select id,name,math+chinese+english 总分 from exam_result where math+chinese+english<200;
注意,由于先筛选再重命名,因此where是在select之前就执行了的,where语句是不认识总分这个别名的,因此如果将where语句中的math+chinese+english改成总分会发生报错。
(7)语文成绩>80并且不姓黑的同学
mysql>select id,name,chinese from exam_result where chinese>80and name notlike'黑%';//使用and来进行一些复合查询

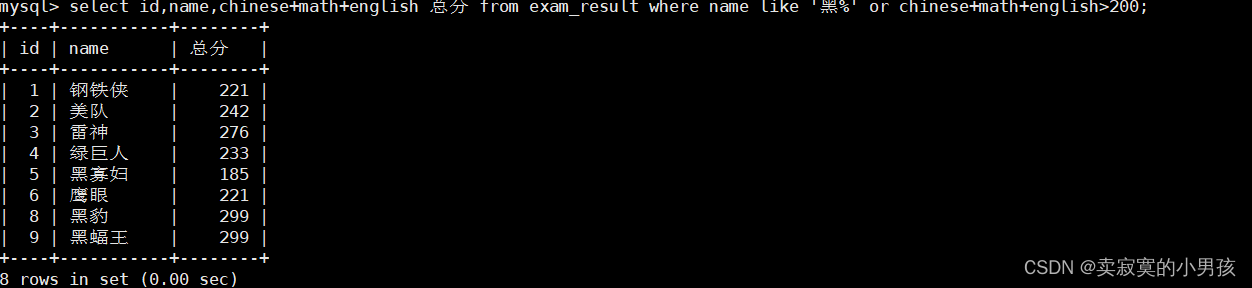
(8)孙某同学,否则总成绩>200
mysql>select id,name,chinese+math+english 总分 from exam_result where name like'黑%'or chinese+math+english>200;
6.NULL查询
在进行NULL查询的时候,不建议使用<=>而建议使用is null和is not null。
我们使用students表来举例,可以向其中插入一些空值。
mysql>insertinto students (id,sn,name)values(4,4,'吕布');
mysql>insertinto students values(3,3,'黄盖');
向其中插入两个值,不指定qq,此时默认为空: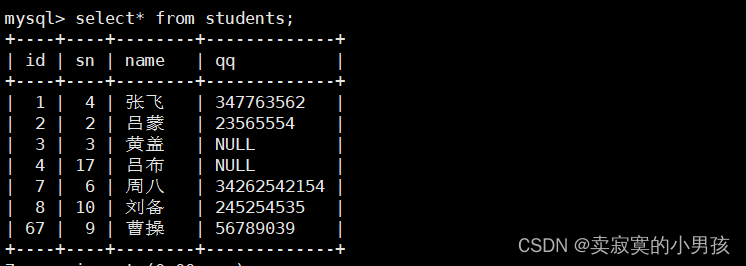
mysql>select id,name from students where qq isnull;//查询qq是空的人
mysql>select id,name from students where qq isnotnull;//查询qq不是空的人。
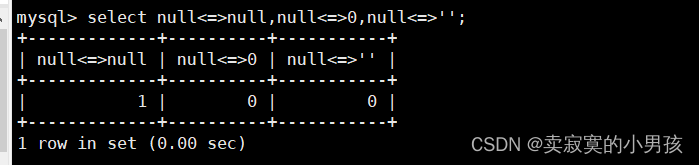
NULL与任何值运算都为NULL,null只和null等价。
mysql>selectnull<=>null,null<=>0,null<=>'';
7.查询结果排序
使用order by语句asc表示升序,desc表示降序。
mysql>select id,name,math from exam_result orderby math desc;//数学成绩按降序排序
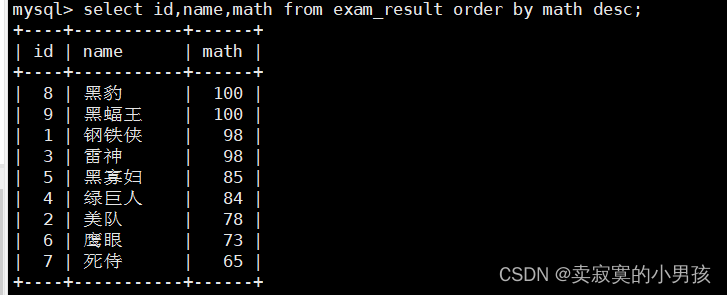
如果有null出现,把null当做最小值。
mysql>select*from exam_result orderby math desc,english asc,chinese asc;//按数学降序,英语升序,语文升序显示
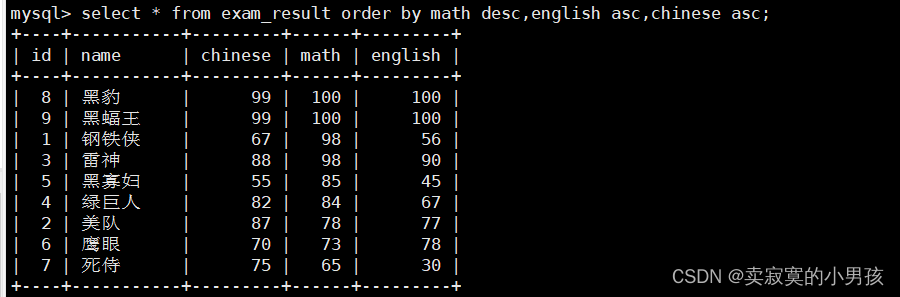
排序的结果是,按数学降序排序,如果数学成绩相同则再按语文升序排序。
mysql>select id,name,chinese+math+english 总分 from exam_result orderby 总分 desc;//按总分排序
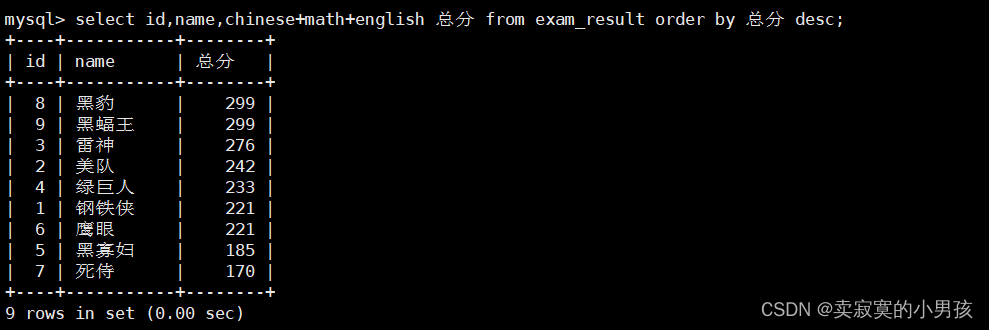
注意,order就可以使用总分了,因为数据的筛选和求和都由select做完,之后再进行排序,所以order的执行顺序在select之后,它知道总分这个定义。
8.筛选分页结果
即找到排名前几的同学:
mysql>select name,english+math+chinese total from exam_result orderby total desclimit3;
筛选总成绩排名前三名的同学: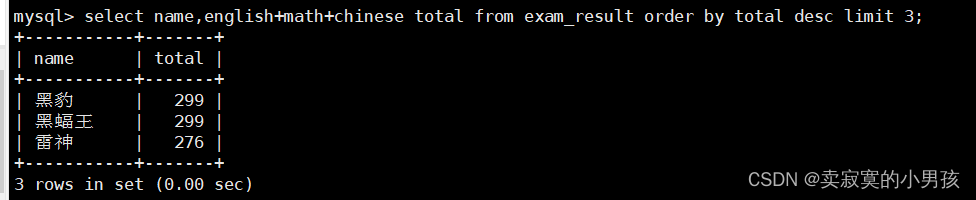
注意,limit关键字永远放在最后面。
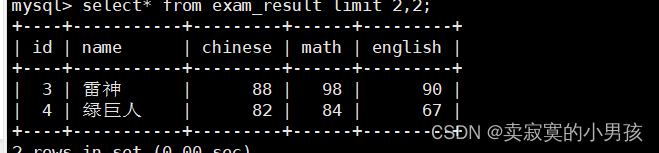
mysql>select*from exam_result limit2,2;//选出表中,从第二行开始的后两行,即第3,4行。
mysql>select*from exam_result limit4offset0;//筛选出从0开始偏移量在4之内的所有行
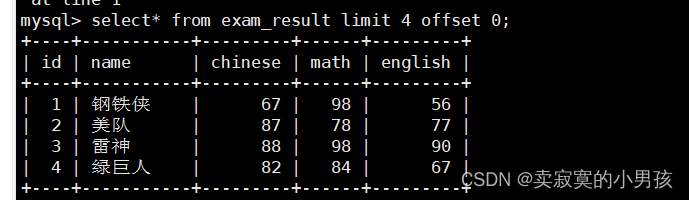
通常使用offset的方式进行筛选。
三、改
1.将钢铁侠数学成绩改为80分
update…set用来进行表中数据的更新。更新或者删除之前一定要先做好备份。
mysql>update exam_result set math=80where name='钢铁侠';
将钢铁侠的数学成绩改为80分。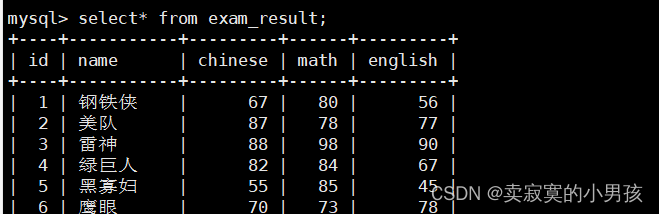
2.将总成绩倒数前三的同学的数学成绩加30分
mysql>update exam_result set math=math+30orderby math+english+chinese asclimit3;
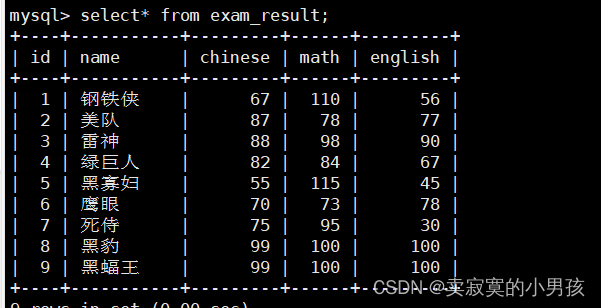
注意,这里没有where子句,但是limit限制了范围。
四、删
1.删除全部数据
deletefrom exam_result;
2.删除钢铁侠
mysql>deletefrom exam_result where name='钢铁侠';
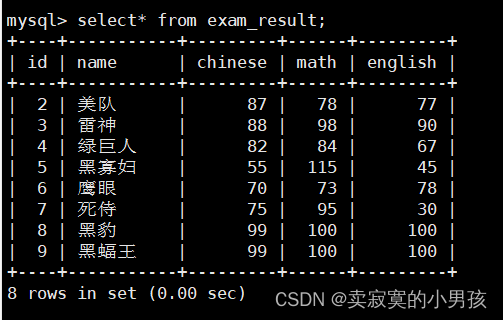
对表格中数据进行删除一定记得要先备份!!!
3.删除表数据与auto_increment
我们在这里新建立一个表专门来用于删除:
mysql>createtable for_delete( id intunsignedprimarykeyauto_increment, name varchar(16)notnull);
mysql>insertinto for_delete (name)values('a'),('b'),('c');
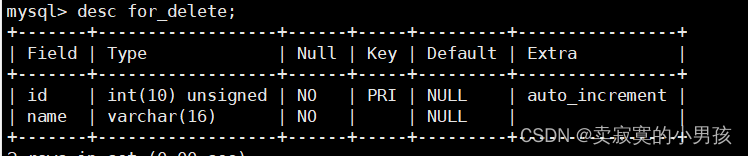
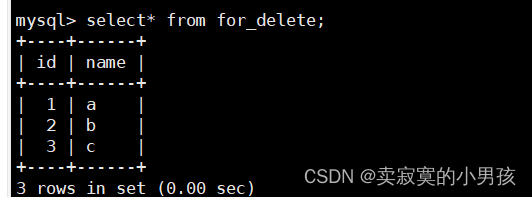
然后我们删除这个表中的数据,并重新插入a,b,c
mysql>deletefrom for_delete;
mysql>insertinto for_delete (name)values('a'),('b'),('c');
此时我们会发现auto_increment没有对id进行更新,而是从4开始赋值id: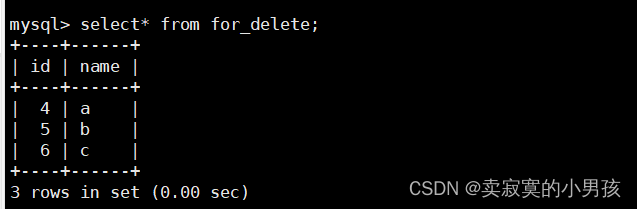
4.截断表
为了避免上述使用delete删除的情况,引入了truncate来进行删除:
mysql>truncatetable for_delete;//使用truncate删除
mysql>insertinto for_delete (name)values('a'),('b'),('c');//重新插入a,b,c
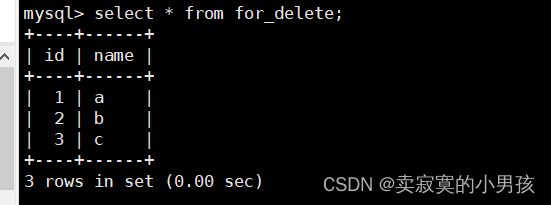
此时可以看到id从1开始赋值了。
五、去重
建立一个表,并向其中插入一些重复性数据:
mysql>createtable duplicate_tb(-> id int,-> name varchar(16)->);
mysql>insertinto duplicate_tb (id,name)values(100,'aaa');
mysql>insertinto duplicate_tb (id,name)values(100,'aaa');
mysql>insertinto duplicate_tb (id,name)values(200,'bbb');
mysql>insertinto duplicate_tb (id,name)values(200,'bbb');
mysql>insertinto duplicate_tb (id,name)values(200,'bbb');
mysql>insertinto duplicate_tb (id,name)values(300,'ccc');
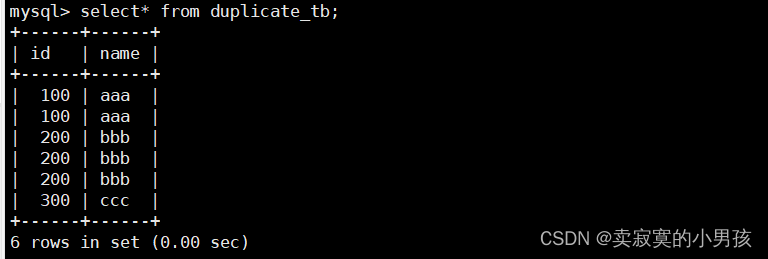
创建一个和duplicate_tb属性相同的表,并将duplicate查询去重之后的数据插入该表中:
mysql>createtable duplicate_tb_bak like duplicate_tb;
mysql>insertinto duplicate_tb_bak selectdistinct*from duplicate_tb;
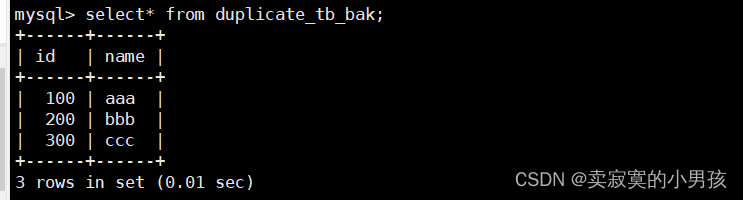
由于要向duplicate_tb中插入,因此还需要进行重命名操作:
mysql>renametable duplicate_tb to old_duplicate_tb;
mysql>renametable duplicate_tb_bak to duplicate_tb;
六、分组聚合
分组聚合主要使用的是group by和having子句。分组聚合需要注意的是要先进行分组,然后再聚合。这里我们使用了oracle 9i的经典测试表来进行测试:
一共有三张表:
1.EMP:员工表
2.DEPT:部门表
3.SALGRADE:工资等级表
下图是三张表的结构: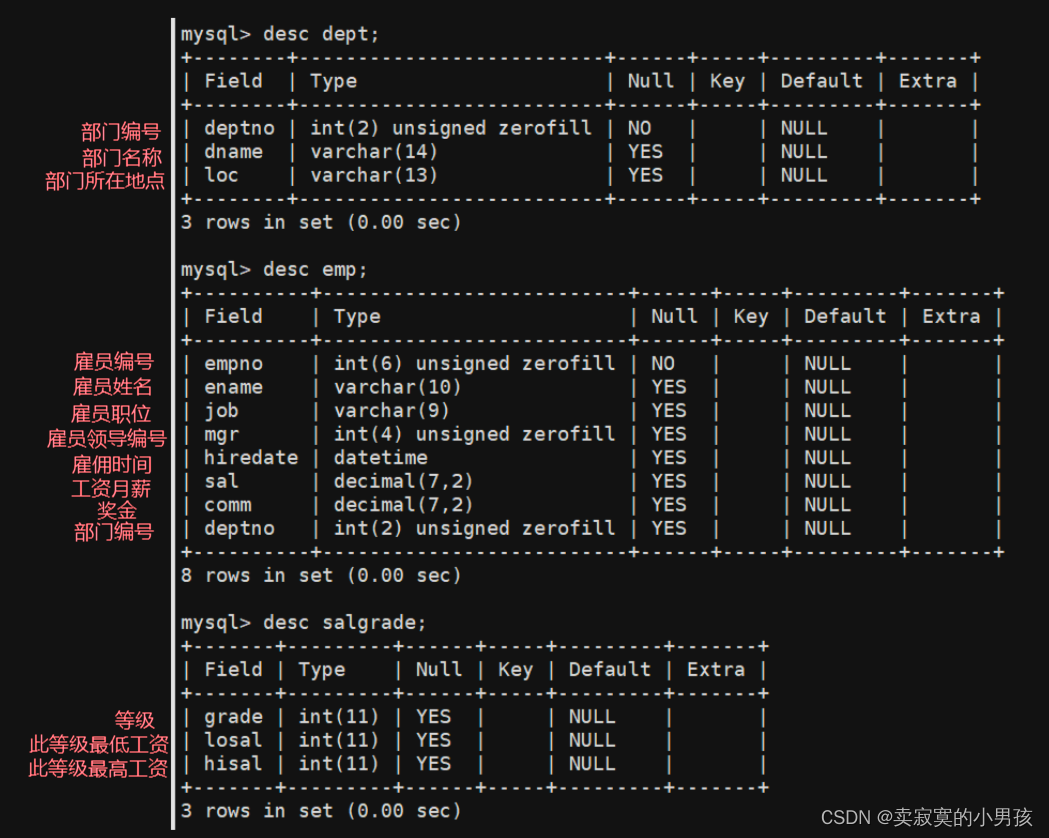
1.显示每一个部门的平均工资与最高工资
首先对部门进行分组,然后再在组内进行聚合:
mysql>select deptno,avg(sal),max(sal)from emp groupby deptno;
执行的顺序就是先将部门按组号分组,然后select再在每个组中执行select deptno,avg(sal),max(sal),称该过程为聚合。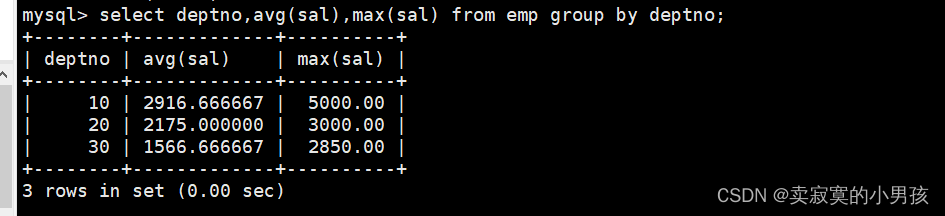
2.显示每个部门的每种岗位的平均工资和最低工资
mysql>select deptno,job,avg(sal),min(sal)from emp groupby deptno,job;
此时以两个标准进行分组,即deptno和job,将deptno相同的排列在一起,对其中的job进行聚合。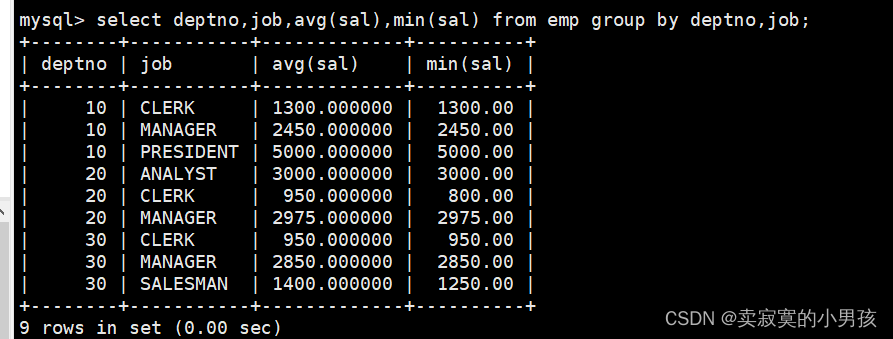
3.显示平均工资低于2000的部门和它的平均工资
having和group配合使用,可以对group的结果进行过滤:
mysql>select deptno,avg(sal)from emp groupby deptno whereavg(sal)<2000;//失败
mysql>select deptno,avg(sal)from emp groupby deptno havingavg(sal)<2000;//成功

我们发现where和having都是进行筛选的语句,它们有什么区别呢?
其中where是在整个表格里做筛选的语句,它的执行是在group by之前,而having是在筛选之后执行是在group的后面。
where是过滤表中数据的,而having是过滤分组数据的。在分组之前需要先通过where来拿到所要用到的数据。整体的执行顺序是:where->group by->select聚合->having
版权归原作者 卖寂寞的小男孩 所有, 如有侵权,请联系我们删除。