
python DataFrame数据格式化
文章目录

参考:
python数据分析从入门到精通 明日科技编著 清华大学出版社
1.设置小数位数
1.1 数据框设置统一小数位数
以保留小数点后两位小数为例:
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.random([5,5]), columns=['A1','A2','A3','A4','A5'])print(df)print("==================================")print(df.round(2))

1.2 数据框分别设置不同小数位数
以A1列保留小数点后一位、A2列保留小数点后两位为例
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.random([5,5]), columns=['A1','A2','A3','A4','A5'])print(df)print("==================================")print(df.round({'A1':1,'A2':2}))

1.3 通过Series设置DataFrame小数位数
通过Series对象设置df小数位数,A1一位,A2零位,A3二位小数
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.random([5,5]), columns=['A1','A2','A3','A4','A5'])print(df)print("==================================")
s1 = pd.Series([1,0,2], index=['A1','A2','A3'])print(df.round(s1))

1.4 applymap(自定义函数)
通过自定义函数设置小数位数,返回类型为object,以设置为二位小数为例
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.random([5,5]), columns=['A1','A2','A3','A4','A5'])print(df)print("==================================")print(df.applymap(lambda x:'%.2f'%x))

- 用于对DataFrame的 每一个数据操作使用**applymap()**方法
- 用于对DataFrame中的数据进行按行或者按列 操作 apply() 方法
- 用于对Series中的每一个数据 操作 使用**map()**方法 更详细可以点击访问blog:python数据分析apply(),map(),applymap()用法归纳
2. 设置百分比
学习以下代码:
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.random([5,5]), columns=['A1','A2','A3','A4','A5'])print(df)print("==================================================================")
df['百分比']= df['A1'].apply(lambda x:format(x,'.0%'))# 整列保留0位小数print(df)print("==================================================================")
df['百分比']= df['A1'].apply(lambda x:format(x,'.2%'))# 整列保留两位小数print(df)print("==================================================================")
df['百分比']= df['A1'].map(lambda x:'{:.0%}'.format(x))# 整列保留0位小数,也可以使用map函数print(df)

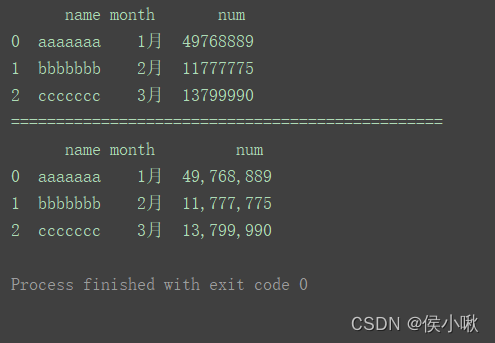
3. 设置千分位分隔符
import pandas as pd
data =[['aaaaaaa','1月',49768889],['bbbbbbb','2月',11777775],['ccccccc','3月',13799990]]
columns =['name','month','num']
df = pd.DataFrame(data=data, columns=columns)print(df)print("================================================")
df['num']= df['num'].apply(lambda x:format(int(x),','))print(df)
本文转载自: https://blog.csdn.net/weixin_48964486/article/details/123329042
版权归原作者 侯小啾 所有, 如有侵权,请联系我们删除。
版权归原作者 侯小啾 所有, 如有侵权,请联系我们删除。