
Flink是什么
Flink是一款支持有状态运算的流计算引擎。
支持有状态运算是指数据的计算过程中可以保存计算的中间过程状态,比如我们要计算一个整数数据流的求和,那么我们就需要一个中间变量把数据流中的每一项数据加到这个变量上。而这个变量就是计算的中间状态。Flink框架会帮你管理状态的保存和复原。
流计算是指我们要针对一个数据流进行源源不断的计算,产出实时的结果。比如说我们曾经看到过天猫淘宝的双11大屏,上面有当前的GMV成交量的数据,这个数字在屏幕上疯狂的跳动。这就是通过流计算产出的实时GMV成交量数据。
Flink有以下特性:
- 应用场景丰富:支持事件驱动的应用
- 计算结果准确:支持Exactly-Once的语义,确保数据一致性。能正确处理延迟达到的数据。
- API用法灵活:提供了分层次的API,有高层次使用方便的API也有低层次灵活扩展的API。
- 运维操作方便:部署灵活,支持高可用。
- 支持大规模扩容:支持水平扩容的架构。支持数量大的数据状态。支持增量检查点。
- 计算性能优秀:数据处理的延迟量低,吞吐量高,在内存中完成所有的计算过程。
Flink适用场景
事件驱动型应用
事件驱动应用指的是这个应用程序从一个地方获取到事件之后,触发一些动作,或者把这些数据更新到数据库里面,这种就是事件驱动型应用。下图就是传统应用和事件驱动型应用的差别。

事件驱动型应用有什么样的优势?传统的应用中,当我们收到一个请求之后,我们需要查询数据库得到一些数据,然后执行业务逻辑,再把数据加工结果存到DB中。这就导致了一个问题,就是我们每次的请求都要查询数据库。而查询数据库是一个开销比较大的操作,因此这种方式它的响应速度吞吐量都不会太高。而在事件驱动型应用当中,当我们收到一个数据的请求之后,我们可以在内存中对这个数据进行加工和处理,然后直接把这个处理结果也是放在内存里面,这样的话,整个的数据处理过程都是在内存里面瞬间完成,因此事件驱动型应用的数据处理性能和吞吐量都会非常高。
Flink为事件驱动型应用带来了哪些好处?Flink可以帮助事件驱动型应用管理好事件处理的中间状态,以及处理好消息乱序、数据延迟等问题。因此可以实现事件驱动型应用的大规模使用。
应用场景举例:
- 欺诈风险检测
- 异常检测
- 基于规则的告警
- 业务流程监控
- 社交应用
数据分析应用
什么是数据分析应用?数据分析应用就是得到一批数据之后,我们针对这一批数据进行加工,传统上我们会通过批处理的方式,把这些数据加工成我们需要看的报表,但是在Flink里面数据加工是通过数据流的方式进行的,数据进入到Flink系统之后马上能够在最终的报表中体现出结果。
应用场景举例:
- Telco移动网络质量监控
- 手机用户体验监控
- 大规模图数据分析
数据加工流程
数据加工流程就是指传统的ETL数据处理过程。在传统的ETL处理过程中,我们会通过批处理的方式来周期性的加工原始数据,得到最终的数据产出。而在流计算的应用里面,ETL这个过程是实时进行的,也就是说原始数据源源不断的从输入端进入,然后立刻就把这些数据加工成最终的产物。
应用场景举例:
- 电商场景实时构建搜索引擎
- 电商场景实时ETL
Flink技术原理
执行过程
下图展现了Flink执行过程:
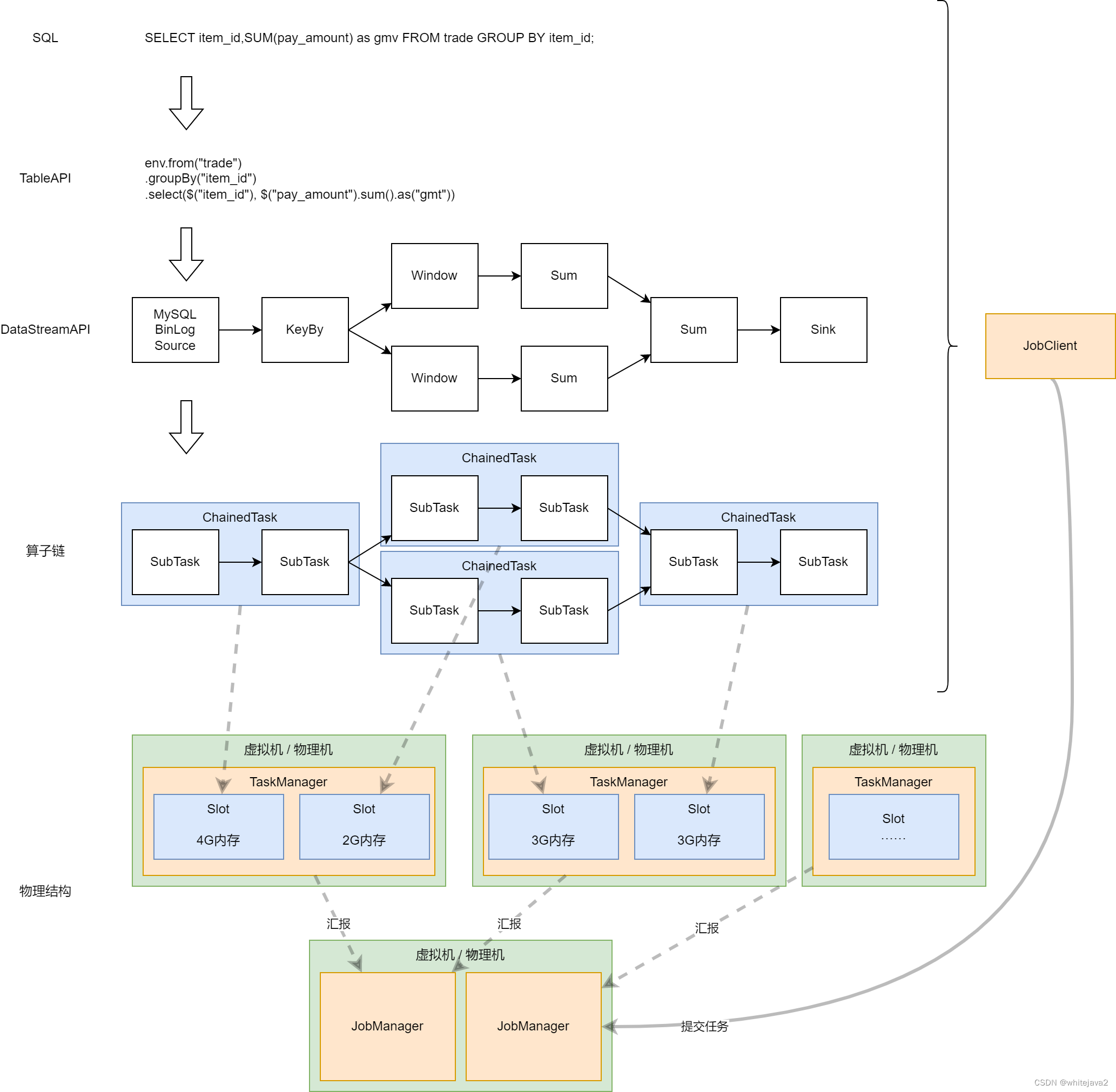
接下来我们来详细的描述一下,当一个SQL提交之后,整个数据处理过程将会是什么样的。
第一步JobClient提交SQL。我们通过Flink提供的一个API,将我们的SQL作为参数传递到API中,然后这时候我们的程序会创建JobClient,然后尝试连接Flink集群。JobClient负责解析这个SQL,根据这个SQL生成我们所需要的计算过程,正如上面这个图形的结构,它会一步一步的把这个SQL拆分成需要的计算步骤。然后我们会发现这个计算步骤里面有一些步骤是上下游之间是一定在同一台机器上运行的,那么这时候我们就会把这两个任务组合成一个链式的任务,这样的话就能够避免同一个数据流在多个机器之间做数据交换导致性能低下。
第二步当我们把执行计划提交到JobManager之后。它会负责这个SQL的整个生命周期。JobManager会将具体的任务分发到对应的TaskManager。这个TaskManager里面它又有多个slot。每个Slot负责一个链式任务。
状态管理
在计算的过程中,每一个算子都有自己的计算状态,那么这个状态是如何保存下来以及如何去恢复的?
状态的保存
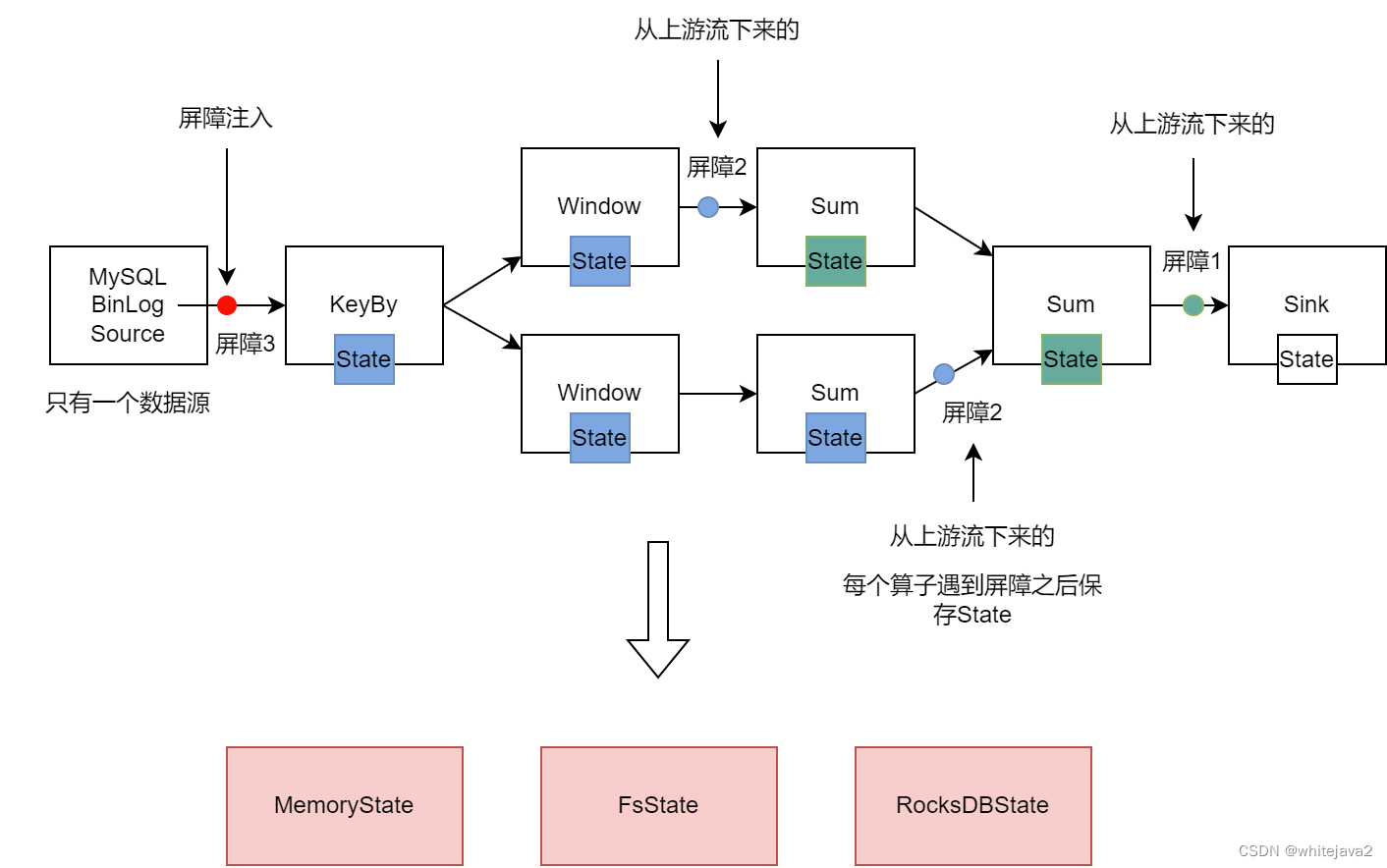
Flink提供了快照的保存间隔设置,每当这个间隔时间到达了之后, Flink会在所有的数据源里面插入一个屏障。
ABS(异步屏障快照)。首先看只有一个数据源的情况。当我们需要保存快照的时候,Flink会在数据源里面加入屏障信号。这个屏障信号会跟随数据流转到下游。那么下游的算子看到这个屏障信号之后,它就会把自身算子的状态保存下来。整个过程不会出现任何阻塞。
屏障对齐。假如说我们现在的一个数据流程里面有多个数据源,那么这时候就需要涉及到屏障对齐。什么意思呢?假如说我们现在要去保存整个流的一个快照,那么这时候我们会在这多个数据源里面同时插入一个屏障信号。等到下游算子接收到其中一个数据源的屏障时,这个算子会停止数据处理,直到集齐所有的屏障信号之后,才会保存快照,然后继续处理后续数据流。这就是Flink为了实现Exactly-once带来的代价,对性能造成了一点点的影响。
那么快照里面保存了什么样的内容,主要是几个信息:
- 时间,它代表了这个快照截止到那一个时间点的状态
- UID:算子的编号。用于恢复时每个算子找到自己的快照数据
- 具体内容,这就跟每个算子的类型有关系了
状态的保存介质目前支持三种。支持保存到内存、文件系统、RocksDB。
状态的恢复
当我们想要恢复状态的时候,那么需要做什么事情呢?
首先从这个保存的介质中找出最新的有效的快照。这个快照里面包含了每个算子的计算状态。从这些状态里面我们可以知道快照的截止时间。恢复状态之后,我们让数据源释放快照时间点之后的数据。
前面我们讲过,通过屏障机制使得每个快照的截止时间点都是一致的。然后状态恢复之后,数据源也从这个时间点之后释放数据,这样就实现了每一项数据都被精确的处理一次,不会被重复处理,也就实现了Exactly-once的数据精确性。
版权归原作者 whitejava2 所有, 如有侵权,请联系我们删除。