
文章目录

OverView
消息在通过 send()方法发往 broker 的过程中,有可能需要经过拦截器(Interceptor)、序列化器(Serializer)和分区器(Partitioner)的一系列作用之后才能被真正地发往 broker。拦截器一般不是必需的,而序列化器是必需的。消息经过序列化之后就需要确定它发往的分区,如果消息 ProducerRecord 中指定了 partition 字段,那么就不需要分区器的作用,因为 partition 代表的就是所要发往的分区号。
如果消息 ProducerRecord 中没有指定 partition 字段,那么就需要依赖分区器,根据 key这个字段来计算 partition 的值。分区器的作用就是为消息分配分区。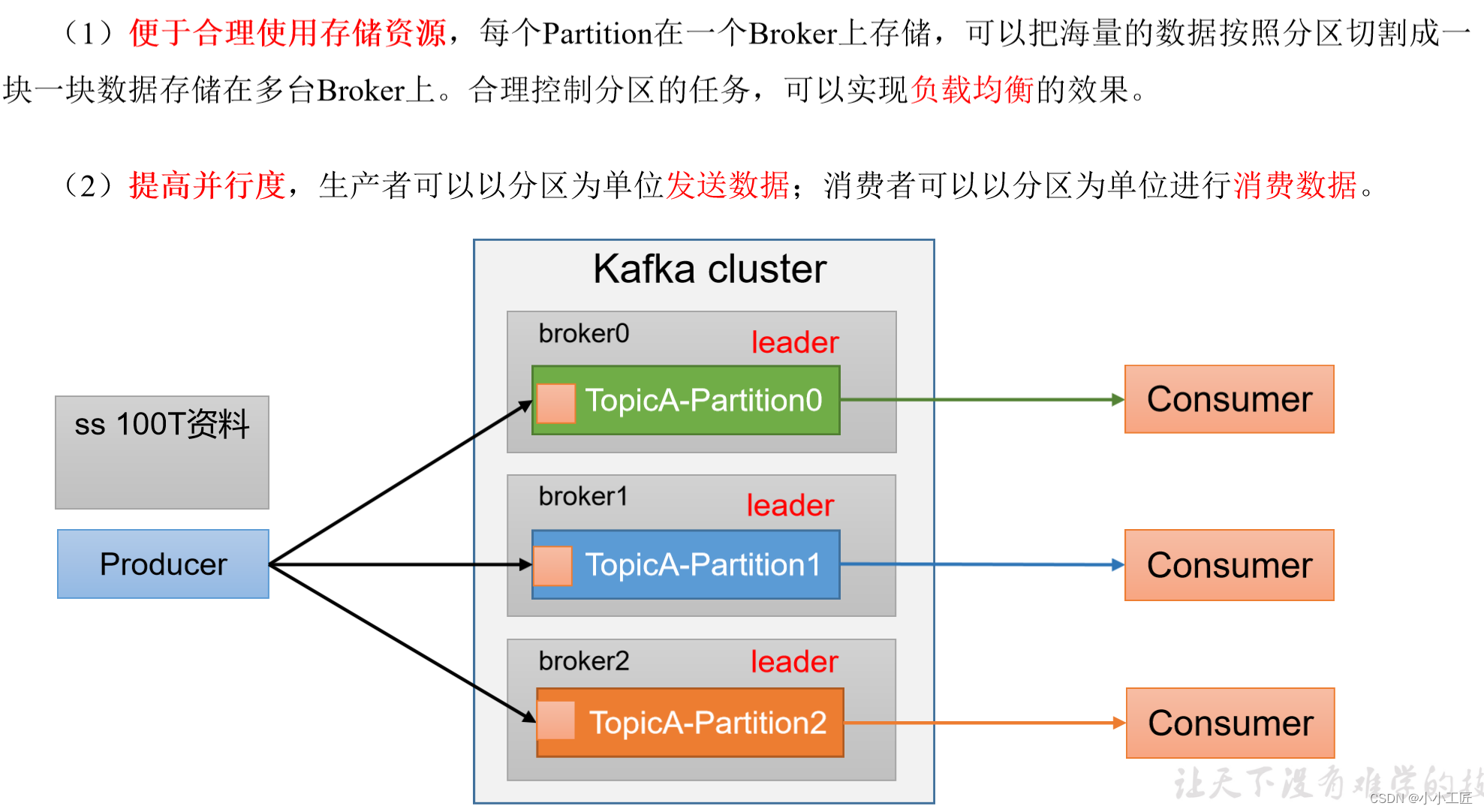
默认分区器DefaultPartitioner
Kafka 中提供的默认分区器是 org.apache.kafka.clients.producer.internals.DefaultPartitioner,它实现了
org.apache.kafka.clients.producer.Partitioner
接口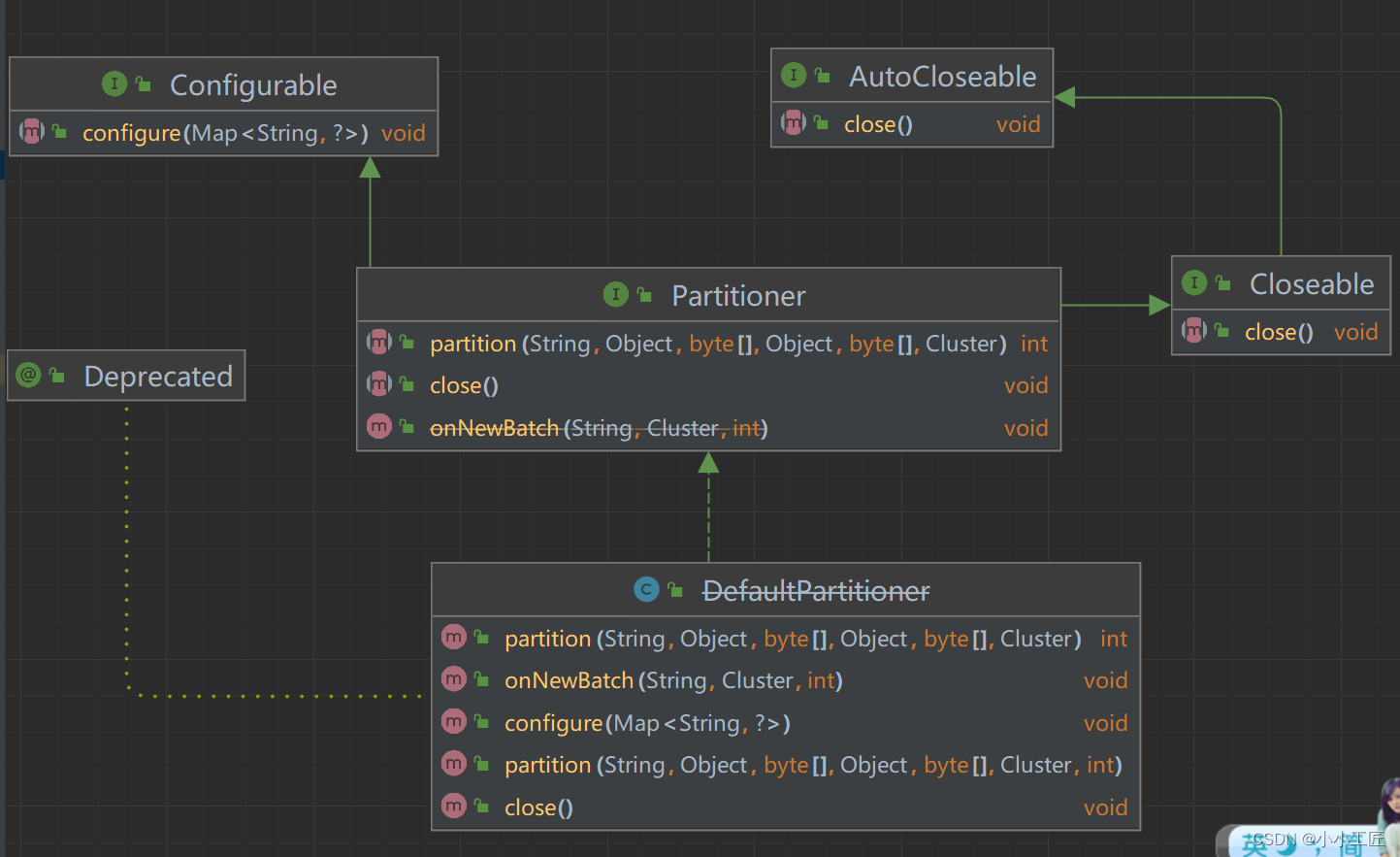
具体如下所示
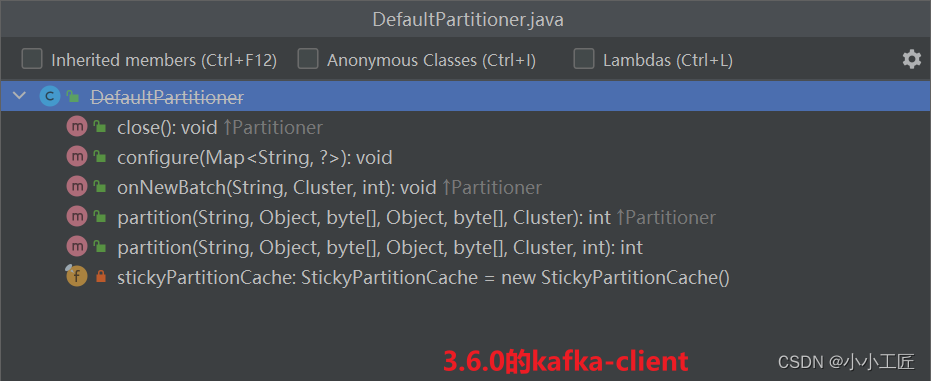
其中 partition()方法用来计算分区号,返回值为 int 类型。partition()方法中的参数分别表示主题、键、序列化后的键、值、序列化后的值,以及集群的元数据信息,通过这些信息可以实现功能丰富的分区器。
close()方法在关闭分区器的时候用来回收一些资源。
Partitioner 接口还有一个父接口 org.apache.kafka.common.Configurable,这个接口中只有一个方法:
void configure(Map<String, ?> configs);
Configurable 接口中的 configure()方法主要用来获取配置信息及初始化数据。
在默认分区器 DefaultPartitioner 的实现中,close()是空方法,而在 partition()方法中定义了主要的分区分配逻辑。
如果 key 不为 null,那么默认的分区器会对 key 进行哈希(采用MurmurHash2 算法,具备高运算性能及低碰撞率),最终根据得到的哈希值来计算分区号,拥有相同 key 的消息会被写入同一个分区。如果 key 为 null,那么消息将会以轮询的方式发往主题内的各个可用分区。
注意:如果 key 不为 null,那么计算得到的分区号会是所有分区中的任意一个;如果 key为 null,那么计算得到的分区号仅为可用分区中的任意一个,注意两者之间的差别。
在不改变主题分区数量的情况下,key 与分区之间的映射可以保持不变。不过,一旦主题中增加了分区,那么就难以保证 key 与分区之间的映射关系了。
使用
1) 我们需要将producer发送的数据封装成一个
ProducerRecord
对象。
2) 上述的分区策略,我们在
ProducerRecord
对象中进行配置。
策略实现
代码****解释
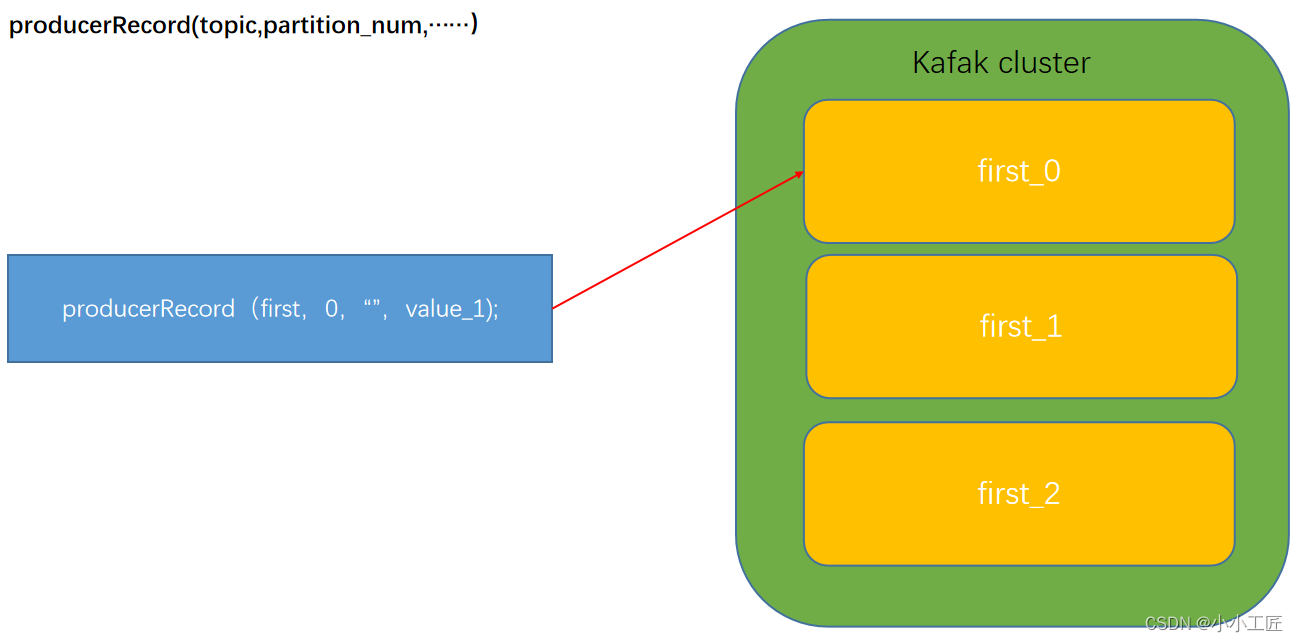
ProducerRecord(topic, partition_num, …)
指明 partition 的情况下直接发往指定的分区,key 的分配方式将无效
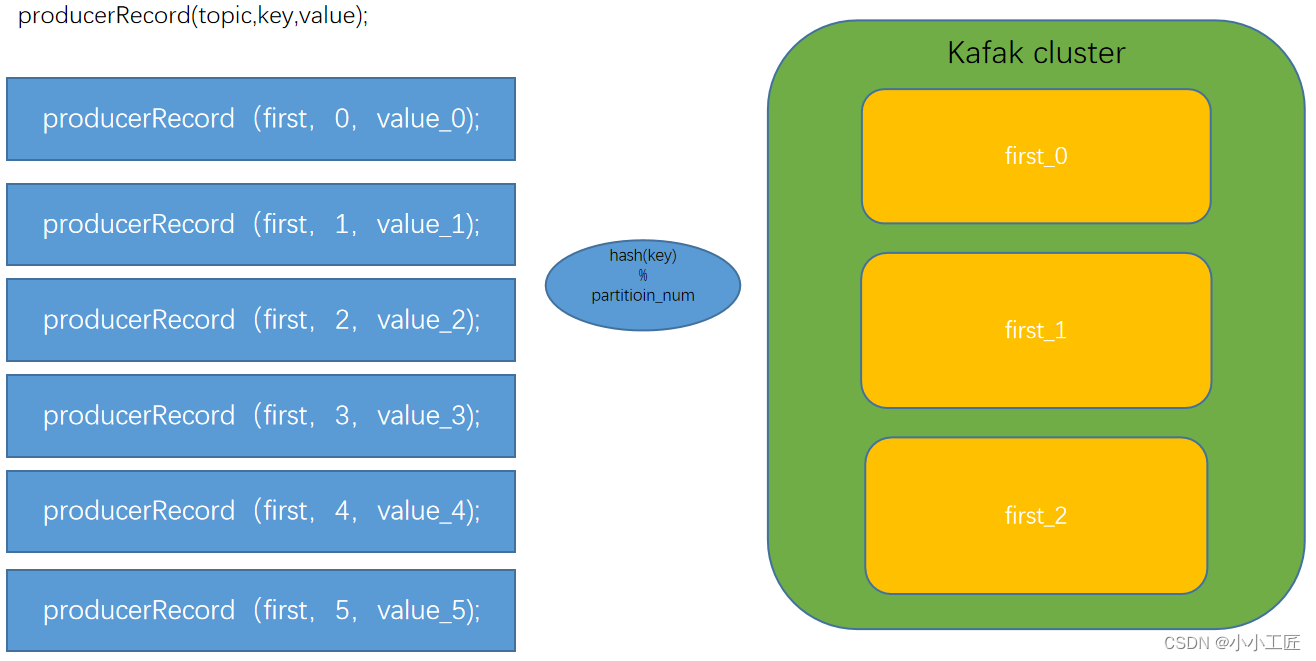
ProducerRecord(topic, key, value)
没有指明 partition 值但有 key 的情况下:将 key 的 hash 值与 topic 的 partition 个数进行取余得到分区号
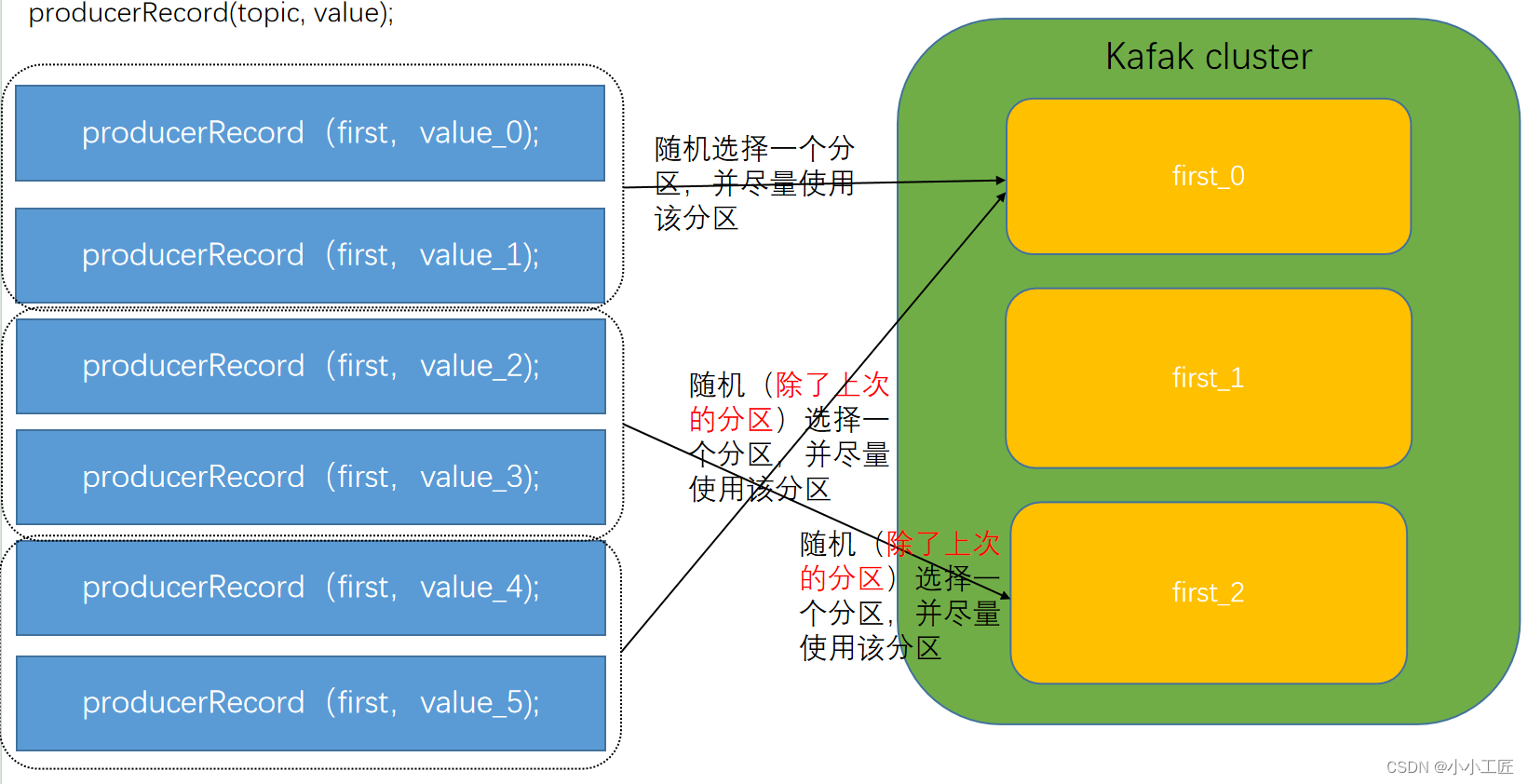
ProducerRecord(topic, value)
既没有 partition 值又没有 key 值的情况下: Kafka 采用 Sticky Partition (黏性分区器),会随机选择一个分区,并尽可能一直使用该分区,待该分区的 batch 已满或者已完成,Kafka 再随机选择一个分区(绝对不会是上一个)进行使用。
Code
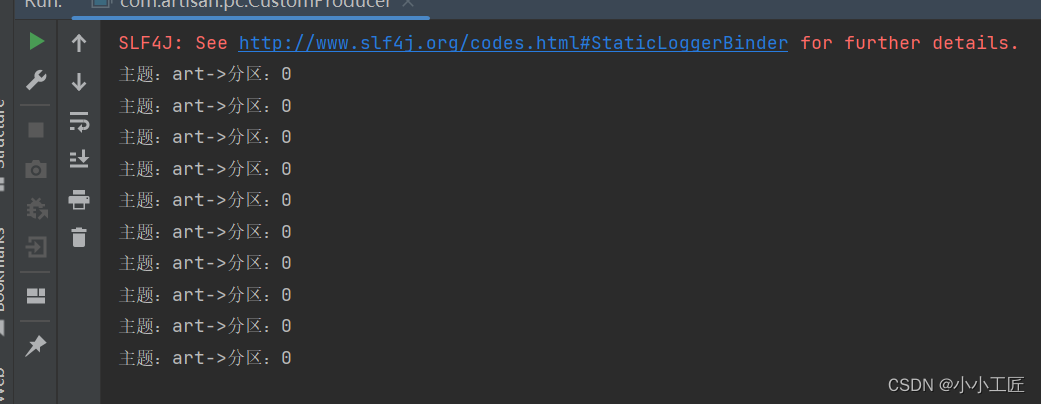
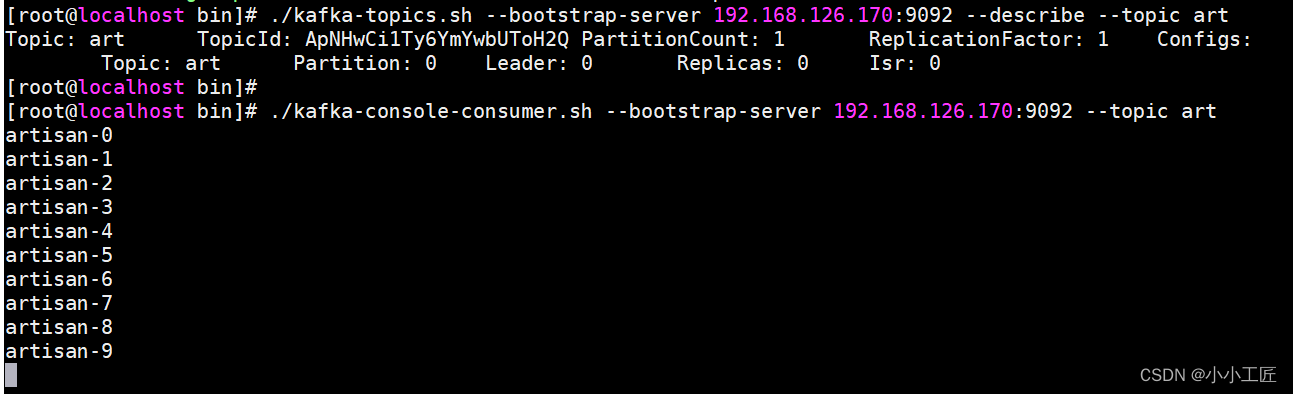
将数据发送到指定partition的情况下,如:将所有消息发送到分区0中。
packagecom.artisan.pc;importorg.apache.kafka.clients.producer.*;importorg.apache.kafka.common.serialization.StringSerializer;importjava.util.Properties;importjava.util.concurrent.ExecutionException;/**
* @author 小工匠
* @version 1.0
* @mark: show me the code , change the world
*/publicclassCustomProducer{publicstaticvoidmain(String[] args)throwsExecutionException,InterruptedException{// 1. 创建kafka生产者的配置对象Properties properties =newProperties();// 2. 给kafka配置对象添加配置信息
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.126.170:9092");// key,value序列化
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());// 3. 创建kafka生产者对象KafkaProducer<String,String> kafkaProducer =newKafkaProducer<String,String>(properties);// 4. 调用send方法,发送消息for(int i =0; i <10; i++){
kafkaProducer.send(newProducerRecord<>("art",0,"","artisan-"+ i),newCallback(){@OverridepublicvoidonCompletion(RecordMetadata metadata,Exception e){if(e ==null){System.out.println("主题:"+ metadata.topic()+"->"+"分区:"+ metadata.partition());}else{
e.printStackTrace();}}});}// 5. 关闭资源
kafkaProducer.close();}}
没有指明partition但是有key的情况下的消费者分区分配

packagecom.artisan.pc;importorg.apache.kafka.clients.producer.*;importorg.apache.kafka.common.serialization.StringSerializer;importjava.util.Properties;importjava.util.concurrent.ExecutionException;/**
* @author 小工匠
* @version 1.0
* @mark: show me the code , change the world
*/publicclassCustomProducer{publicstaticvoidmain(String[] args)throwsExecutionException,InterruptedException{// 1. 创建kafka生产者的配置对象Properties properties =newProperties();// 2. 给kafka配置对象添加配置信息
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.126.170:9092");// key,value序列化
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
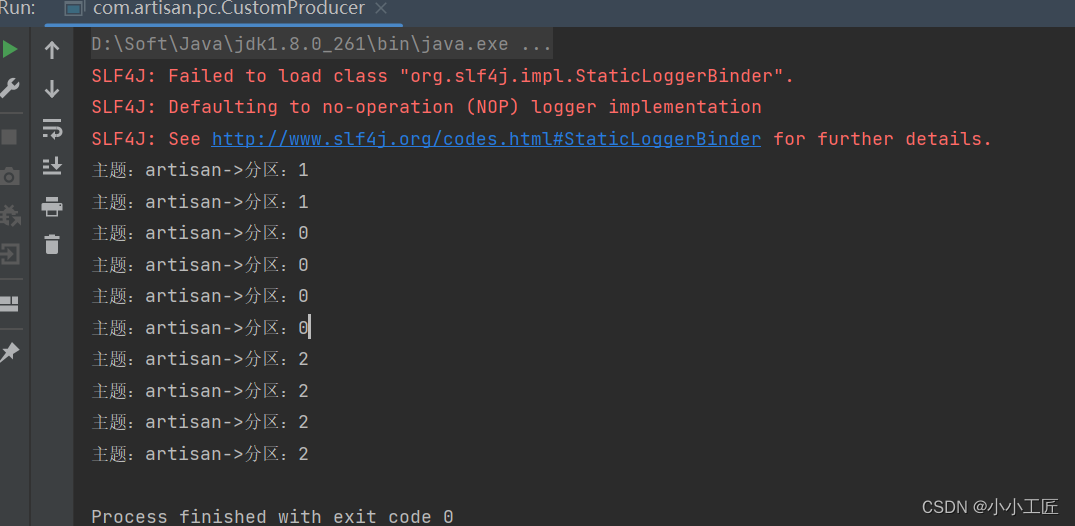
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());// 3. 创建kafka生产者对象KafkaProducer<String,String> kafkaProducer =newKafkaProducer<String,String>(properties);// 4. 调用send方法,发送消息for(int i =0; i <10; i++){
kafkaProducer.send(newProducerRecord<>("artisan",String.valueOf(i),// 依次指定key值为i"artisan-p-"+ i),(metadata, e)->{if(e ==null){System.out.println("主题:"+ metadata.topic()+"->"+"分区:"+ metadata.partition());}else{
e.printStackTrace();}});}// 5. 关闭资源
kafkaProducer.close();}}
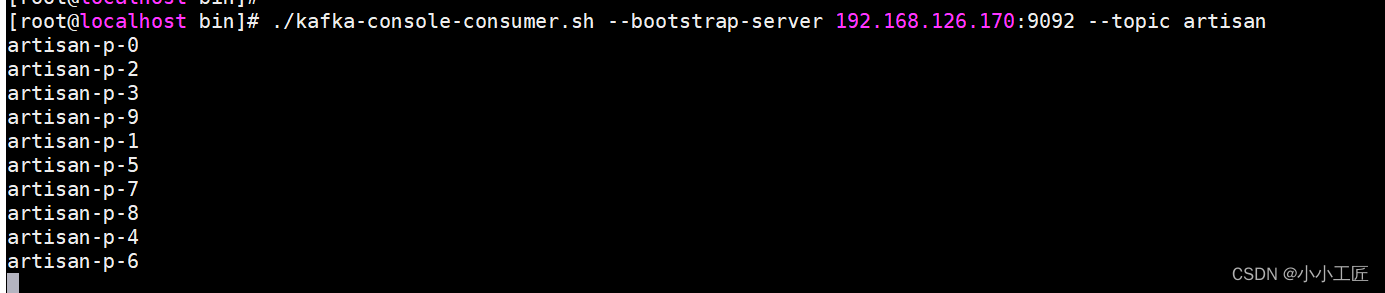
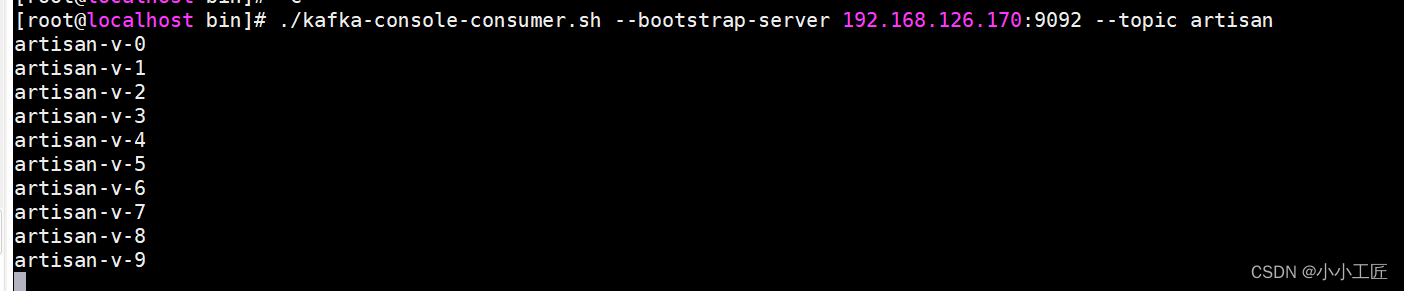
不指明Partition 也不指明分区key
packagecom.artisan.pc;importorg.apache.kafka.clients.producer.*;importorg.apache.kafka.common.serialization.StringSerializer;importjava.util.Properties;importjava.util.concurrent.ExecutionException;/**
* @author 小工匠
* @version 1.0
* @mark: show me the code , change the world
*/publicclassCustomProducer{publicstaticvoidmain(String[] args)throwsExecutionException,InterruptedException{// 1. 创建kafka生产者的配置对象Properties properties =newProperties();// 2. 给kafka配置对象添加配置信息
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.126.170:9092");// key,value序列化
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());// 3. 创建kafka生产者对象KafkaProducer<String,String> kafkaProducer =newKafkaProducer<String,String>(properties);// 4. 调用send方法,发送消息for(int i =0; i <10; i++){
kafkaProducer.send(newProducerRecord<>("artisan","artisan-v-"+ i),(metadata, e)->{if(e ==null){System.out.println("主题:"+ metadata.topic()+"->"+"分区:"+ metadata.partition());}else{
e.printStackTrace();}});}// 5. 关闭资源
kafkaProducer.close();}}
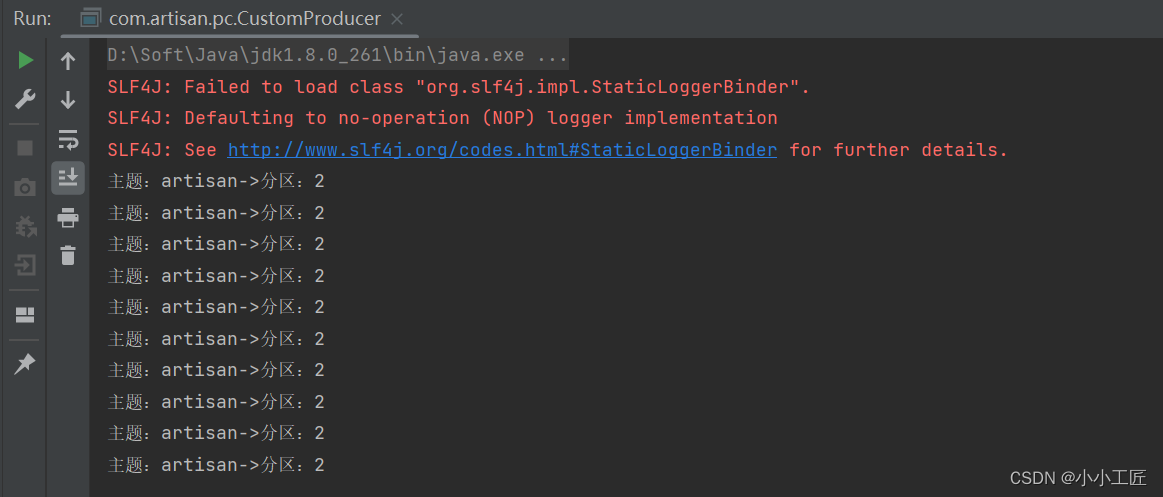
既没有 partition 值又没有 key 值的情况下: Kafka 采用 Sticky Partition (黏性分区器),会随机选择一个分区,并尽可能一直使用该分区,待该分区的 batch 已满或者已完成,Kafka 再随机选择一个分区(绝对不会是上一个)进行使用。
可能是任意一个分区,并尽量一直使用该分区。
自定义分区器
除了使用 Kafka 提供的默认分区器进行分区分配,还可以使用自定义的分区器,只需同DefaultPartitioner 一样实现 Partitioner 接口即可。
默认的分区器在 key 为 null 时不会选择非可用的分区, 我们可以通过自定义的分区器 来打破这一限制,具体的实现可以参考下面的示例代码,
实现步骤:
① 定义类,实现Partitioner接口
② 重写partition()方法
packagecom.artisan.pc;importorg.apache.kafka.clients.producer.Partitioner;importorg.apache.kafka.common.Cluster;importorg.apache.kafka.common.PartitionInfo;importorg.apache.kafka.common.utils.Utils;importjava.util.List;importjava.util.Map;importjava.util.concurrent.atomic.AtomicInteger;/**
* @author 小工匠
* @version 1.0
* @mark: show me the code , change the world
*/publicclassArtisanPartitionerimplementsPartitioner{privatefinalAtomicInteger counter =newAtomicInteger(0);@Overridepublicintpartition(String topic,Object key,byte[] keyBytes,Object value,byte[] valueBytes,Cluster cluster){List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);int numPartitions = partitions.size();if(null== keyBytes){return counter.getAndIncrement()% numPartitions ;}else{returnUtils.toPositive(Utils.murmur2(keyBytes))% numPartitions;}}@Overridepublicvoidclose(){}@Overridepublicvoidconfigure(Map<String,?> configs){}}
实现自定义的 类之后,需要通过配置参数 partitioner.class 来显式指定这个分区器
packagecom.artisan.pc;importorg.apache.kafka.clients.producer.*;importorg.apache.kafka.common.serialization.StringSerializer;importjava.util.Properties;importjava.util.concurrent.ExecutionException;/**
* @author 小工匠
* @version 1.0
* @mark: show me the code , change the world
*/publicclassCustomProducer{publicstaticvoidmain(String[] args)throwsExecutionException,InterruptedException{// 1. 创建kafka生产者的配置对象Properties properties =newProperties();// 2. 给kafka配置对象添加配置信息
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.126.170:9092");// key,value序列化
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());// 自定义分区器
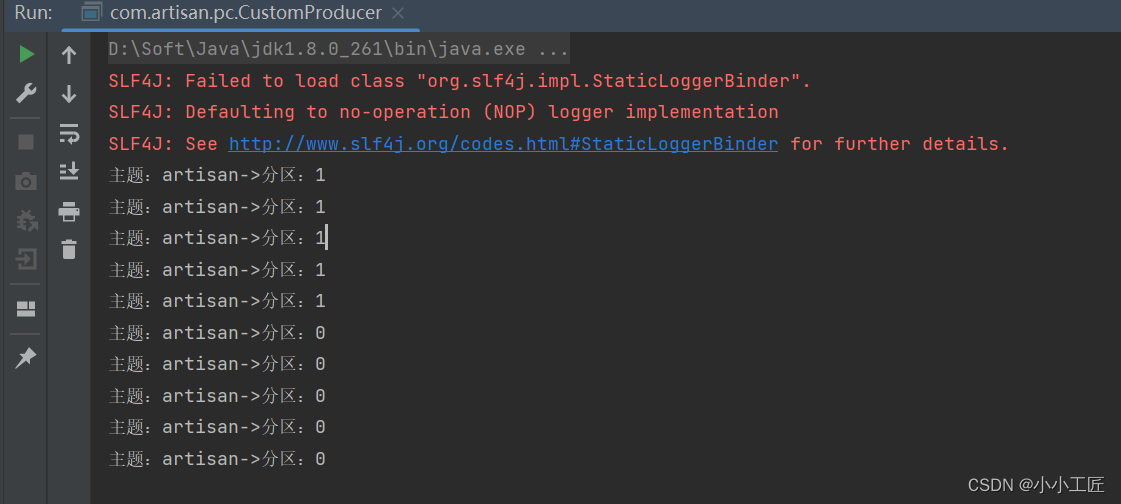
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,ArtisanPartitioner.class.getName());// 3. 创建kafka生产者对象KafkaProducer<String,String> kafkaProducer =newKafkaProducer<String,String>(properties);// 4. 调用send方法,发送消息for(int i =0; i <10; i++){
kafkaProducer.send(newProducerRecord<>("artisan","artisan-cp-"+ i),(metadata, e)->{if(e ==null){System.out.println("主题:"+ metadata.topic()+"->"+"分区:"+ metadata.partition());}else{
e.printStackTrace();}});}// 5. 关闭资源
kafkaProducer.close();}}

这个自定义分区器的实现比较简单,读者也可以根据自身业务的需求来灵活实现分配分区的计算方式,比如一般大型电商都有多个仓库,可以将仓库的名称或 ID 作为 key 来灵活地记录商品信息。

版权归原作者 小小工匠 所有, 如有侵权,请联系我们删除。