
HDFS集群搭建-HA模式概念,伪分布式到完全分布式,HDFS- Federation解决方案等知识点的讲解。

HDFS集群搭建-HA模式概念
前言
博主语录:一文精讲一个知识点,多了你记不住,一句废话都没有
经典语录:你要灭一个人,一是骂杀,一是捧杀
一、伪分布式到完全分布式
回顾:
伪分布式: 在一个节点启动所有的角色: NN,DN,SNN
基础环境
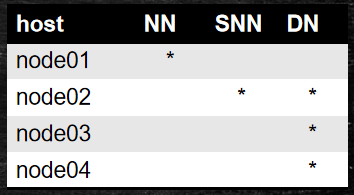
部署配置
1)角色在哪里启动
NN: core-site.xml: fs.defaultFS hdfs://node01:9000
DN: slaves: node01
SNN: hdfs-site.xml: dfs.namenode.secondary.http.address node01:50090
2) 角色启动时的细节配置:
dfs.namenode.name.dir
dfs.datanode.data.dir
- 初始化&启动
- 格式化
- Fsimage
- VERSION
- start-dfs.sh
- 加载我们的配置文件
- 通过ssh 免密的方式去启动相应的角色
伪分布式到完全分布式:角色重新规划
首先把node01停止,运行stop-dfs.sh
**ssh 免密是为了什么? **
为了免密启动start-dfs.sh
注意:在哪里启动,那台就要对别人公开自己的公钥
这一台有什么特殊要求吗?
没有
免密配置:
node02~node04:
rpm -i jdk-8u181-linux-x64.rpm
node01:
scp /root/.ssh/id_dsa.pub node02:/root/.ssh/node01.pub
scp /root/.ssh/id_dsa.pub node03:/root/.ssh/node01.pub
scp /root/.ssh/id_dsa.pub node04:/root/.ssh/node01.pub
node02:
cd ~/.ssh
cat node01.pub >> authorized_keys
node03:
cd ~/.ssh
cat node01.pub >> authorized_keys
node04:
cd ~/.ssh
cat node01.pub >> authorized_keys
完全分布式配置部署
node01:
cd $HADOOP/etc/hadoop
vi core-site.xml
不需要改
vi hdfs-site.xml
<property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/var/bigdata/hadoop/full/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/var/bigdata/hadoop/full/dfs/data</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>node02:50090</value> </property> <property> <name>dfs.namenode.checkpoint.dir</name> <value>/var/bigdata/hadoop/full/dfs/secondary</value> </property>
vi slaves
node02
node03
node04
** 分发:**
cd /opt
scp -r ./bigdata/ node02:`pwd`
scp -r ./bigdata/ node03:`pwd`
scp -r ./bigdata/ node04:`pwd`
格式化启动
hdfs namenode -format
start-dfs.sh
二、思路
**主从集群:结构相对简单,主与从协作 **
**主:单点,数据一致好掌握 **
**问题: **
单点故障,集群整体不可用 压力过大,内存受限
三、HDFS解决方案
**单点故障: **
高可用方案:HA(High Available) 多个NN,主备切换,主压力过大,内存受限:
** **联帮机制: Federation(元数据分片)
多个NN,管理不同的元数据
- HADOOP 2.x 只支持HA的一主一备
四、HDFS-HA解决方案
**Namenode元数据: **
1、cli交互操作mkdir /a
2、dn提交的block
HA:数据同步(cli的操作)
分布式:强一致性破坏可用性
ZK:
1、目录树结构:x节点B抢锁
2、事件机制-》call back watch监控
3、临时节点
注意:在HA模式中没有SNN,Standby角色滚动Fsimage,通过SNN滚动是非HA模式
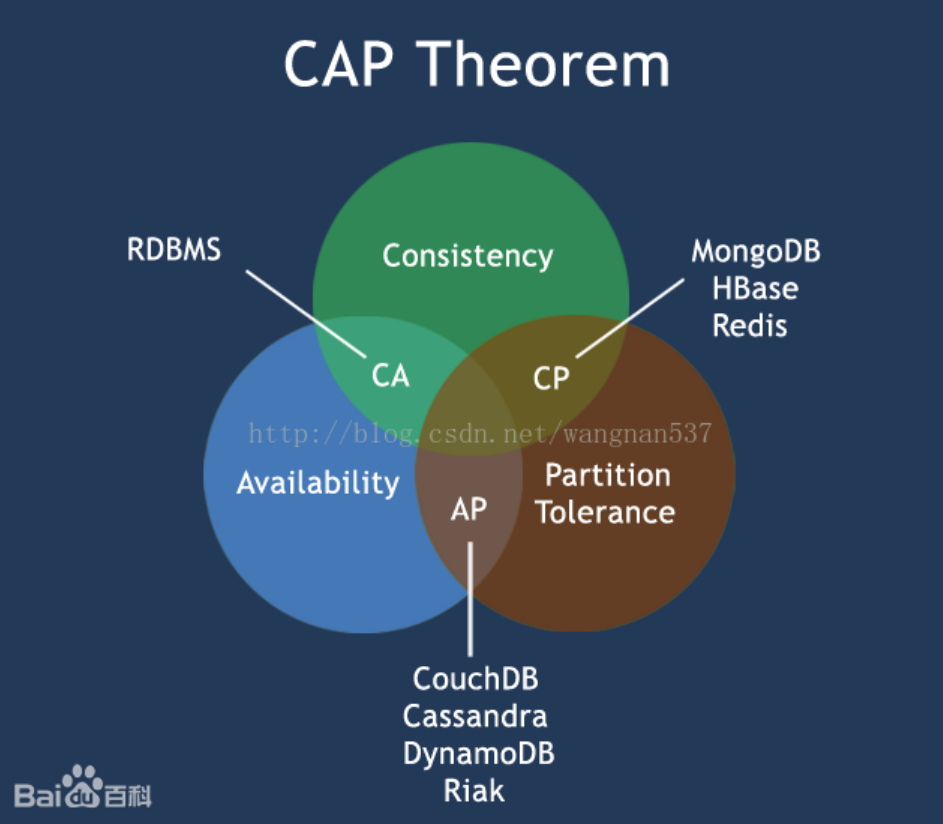
**CAP原则: **
- Consistency:一致性
- Availability:可用性
- Partition tolerance:分区容忍性
Paxos 算法
- Paxos算法是莱斯利·兰伯特于1990年提出的一种基于消息传递的一致性算法。
- 这个算法被认为是类似算法中最有效的。
- 该算法覆盖全部场景的一致性。
- 每种技术会根据自己技术的特征选择简化算法实现。
- 传递:NN之间通过一个可靠的传输技术,最终数据能同步就可以
- 我们一般假设网络等因素是稳定的
- 类似一种带存储能力的消息队列
简化思路:
- 分布式节点是否明确
- 节点权重是否明确
- 强一致性破坏可用性
- 过半通过可以中和一致性和可用性
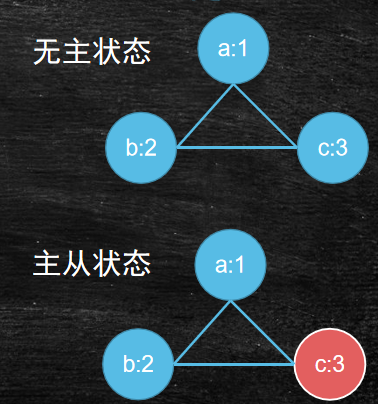
最简单的自我协调实现:主从
主的选举:明确节点数量和权重
主从的职能:
- 主:增删改查
- 从:查询,增删改传递给主
- 主与从:过半数同步数据
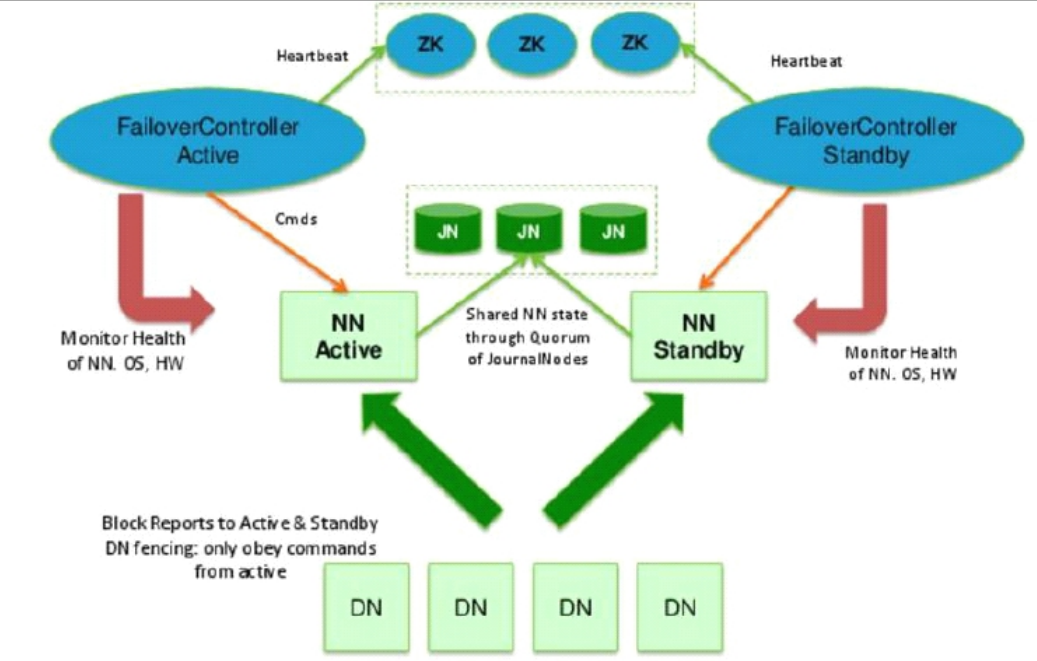
**HA方案: **
多台NN主备模式,Active和Standby状态
- **Active对外提供服务 **
**增加journalnode角色(>3台),负责同步NN的editlog **
- **最终一致性 **
**增加zkfc角色(与NN同台),通过zookeeper集群协调NN的主从选举和切换 **
- **事件回调机制 **
DN同时向NNs汇报block清单
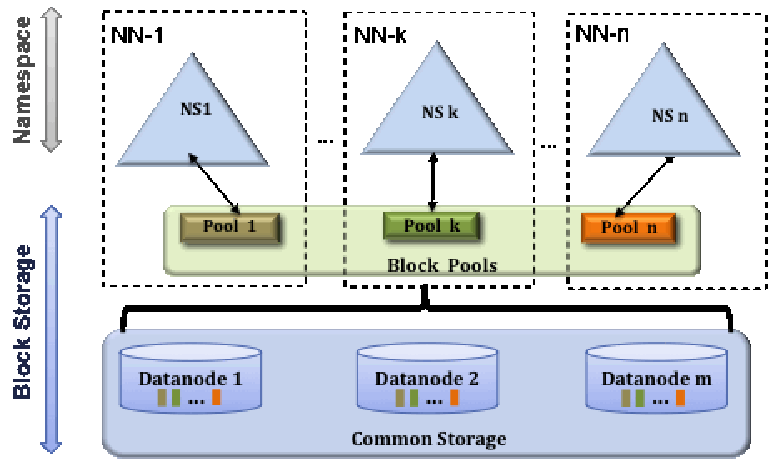
五、HDFS- Federation解决方案

- NN的压力过大,内存受限问题:
- 元数据分治,复用DN存储
- 元数据访问隔离性
- DN目录隔离block
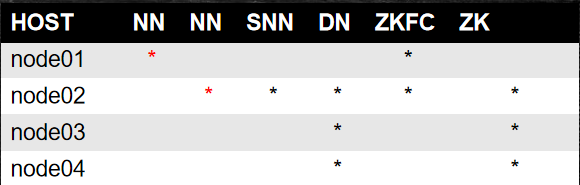
5.1、基础环境
- 增加NNs的ssh免密
5.2、应用搭建
- zookeeper
- 格式化NN
- 格式化ZK
5.3、启动集群
- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨
版权归原作者 Lansonli 所有, 如有侵权,请联系我们删除。